一种神经网络终端部署微调训练方法与流程
本发明属于计算机技术领域,尤其是神经网络训练技术领域,具体涉及一种神经网络终端部署微调训练方法,具体是神经网络在设备端部署微调准确率的训练方法。
背景技术:
近些年来随着神经网络算法的发展,其准确率在诸多领域已经大幅超过传统算法。但是由于神经网络算法对部署系统的算力以及带宽有非常高的要求。因此神经网络算法的运行功耗也会较高。在部署到设备端时一般需要进行大幅度的优化,以此降低神经网络算法在部署时对算力,带宽和功耗的消耗。常见的优化包括量化,剪枝,压缩,算子合并,激活函数拟合,动态数据剪枝等。这些优化手段中比如量化,剪枝,激活函数拟合,动态数据剪枝等都是对神经网络计算精度有损的方法。但这对于需要高准确率,高精度场合就较难直接采用这些优化手段。
通过微调重训练提升部署模型的准确率的方法,与部署设备神经网络算子实现方式紧密相关。举例而言,如果部署设备支持的激活函数的实现方式和训练平台中的实现方式有差异从而导致最终结果准确率下降,那么就需要在对这种情况进行微调训练。由于这种微调训练的实现由于涉及硬件实现的细节,一般需要有设备设计者提供训练工具。但这种训练工具的设计有几个设计难点:
一、现在算法设计人员所采用的神经网络训练平台种类繁多。比如tensorflow,pytorch,keras,mxnet等。设备提供商需要设计不同的平台的微调部署工具。对平台底层代码改动较多的话还很可能会涉及到各训练平台不同版本的兼容性问题。这会带来巨大的工作量和维护成本。
二、需要修改的算子类型较多。一般神经网络设备会支持几十个以上的算子。如果这些算子都涉及精度问题,则需要的修改工作量非常大。
三、微调工具需要较好的易用性。易用性的目的是方便算法人员快速搭建微调重训练的工程,降低算法从训练平台到设备端的移植的成本。
技术实现要素:
本发明的目的就是为了解决上述难点,提供一种神经网络终端部署微调训练方法。
本发明方法具体是:
s0.神经网络训练平台生成原始高精度神经网络训练模型;
s1.去除原始高精度神经网络训练模型中推断无关算子,生成原始高精度神经网络推断模型;
s2.编译生成部署神经网络模型;其第一次运行载入的模型为原始高精度神经网络推断模型,之后运行载入的模型为步骤s7生成的新高精度神经网络推断模型;
s3.在部署平台上运行部署神经网络模型,计算结果的准确率,其输入为测试集;
s4.如果准确率达到设定目标则结束训练过程;如果准确率未达到目标则继续训练,执行步骤s5;
s5.在部署平台上运行部署神经网络模型,得到部署神经网络模型结果,其输入数据为训练输入样本;
s6.在神经网络训练平台对高精度神经网络训练模型进行训练,其输入数据为训练输入样本;第一次训练时载入的模型为原始高精度神经网络训练模型,之后训练时载入的模型为前一轮生成新高精度神经网络训练模型;修改训练结果用部署神经网络模型结果进行替代。
s7.训练完成后得到新高精度神经网络训练模型,去除推断不相关算子,生成新高精度神经网络推断模型,执行步骤s2。
各模型和平台具体是:
原始高精度神经网络推断模型:神经网络训练平台训练得到原始高精度神经网络训练模型删除推断不相关的算子得到的高精度推断模型。
新高精度神经网络推断模型:神经网络训练平台训练得到新高精度神经网络训练模型删除推断不相关的算子得到的高精度推断模型。
部署神经网络模型:高精度神经网络模型通过编译优化后得到的用于部署的神经网络模型,该模型的输出相对于高精度模型输出具有误差。
神经网络训练平台:指可以通过梯度反向传播算法训练神经网络的平台。
部署平台:指可以运行神经网络推断过程的平台,部署平台支持编译优化后的部署神经网络模型的运行。例如:专用神经网络加速芯片平台,神经网络加速芯片仿真平台,神经网络加速fpga平台等。
进一步,步骤s5和s6中的训练输入样本在同一轮部署微调训练过程中采用相同的训练输入样本,在不同轮之间采用相同或不同的训练输入样本。
进一步,步骤s6中修改训练结果用部署神经网络模型结果进行替代的方法是:在训练开始前修改高精度神经网络训练模型,在高精度神经网络模型输出节点和损失函数之间添加一个替换算子,替换算子在神经网络推断过程中,直接使用部署神经网络模型的结果替代高精度神经网络模型训练结果;替换算子的反向梯度传播过程为直通前级算子的梯度到下一级算子,即前级梯度输入等于后级梯度输出。
同一轮部署微调训练过程是以步骤s7为界,执行完步骤s7后为下一轮微调过程。
在高精度神经网络模型输出节点和损失函数之间加入一种新的算子不属于推断相关算子,该算子不包含在步骤s7所生成的高精度神经网络推断模型中。
本发明方法和训练平台之间的耦合度较低,通用性较强并且简单易用。从而大幅降低了设计微调工具的工作量,维护成本以及微调训练工程的搭建难度。
本发明方法有益效果在于:
1、修改简单,只需要在原高精度神经网络训练工程中进行两处修改就可以基本完成了微调训练工程搭建,大幅降低算法设计人员搭建微调训练工程的难度和工作量。
2、通用性强,对于大多数部署优化导致的精度损失原理上都适用。
附图说明
图1为本发明方法的框架图;
图2为本发明方法的流程图。
具体实施方案
下面结合附图,借助实施例详细描述本发明。但应注意到:除非另外特殊说明,否则在实施例中阐述涉及的相对设置、数字表达式、字母表达式和数值不限定本发明的范围,提供这写实施例仅为了让相关人员更便于理解本发明。对相关领域的技术人员公知的技术方法可能不做过多描述。但一定条件下,本发明所述技术、方法和系统应当被视为说明书的一部分。
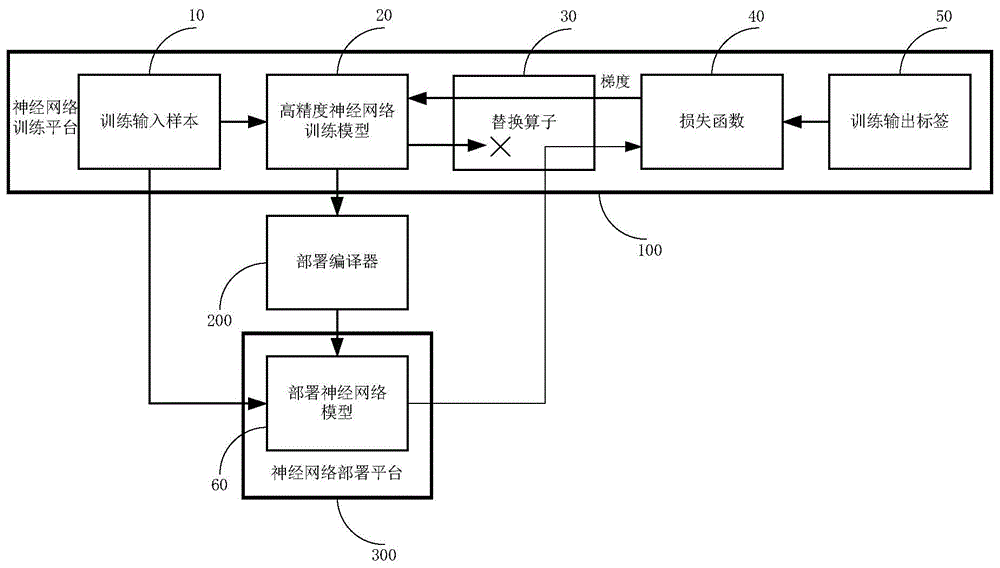
如图1所示,一种神经网络终端部署微调训练方法的框架,其涉及的主要元素有神经网络训练平台100、部署编译器200,神经网络部署平台300。
神经网络训练平台100中包含神经网络训练所需要的必要元素,包括训练输入样本10,高精度神经网络模型20,替换算子30,损失函数40,训练输出标签50。在神经网络部署平台300中包含部署神经网络模型60。
神经网络训练平台100是指可以通过梯度反向传播算法训练神经网络的平台。例如:tensorflow,pytorch,keras,mxnet等神经网络训练平台;
训练输入样本10在训练过程中输出给高精度神经网络训练模型和部署神经网络模型。输出给两者的样本完全相同。
高精度神经网络训练模型20是指该模型包含了训练所需的算子,在输出到部署编译器时需要去除推断不相关的算子。
替换算子30也是一个训练相关算子,一般可训练的算子需要包括推断实现和梯度反向传播实现两部分。该算子的推断实现是把前级高经典神经网络训练模型的输出,替换成部署神经网络模型的输出。该算子的梯度反向传播实现是,把后级算子输入给该算子的梯度反向传播的值不进行任何修改直接传递给前级算子。在图2中所示的是一种常见的结构,即后级损失函数40将梯度反向传播给替换算子30,而替换算子30直接把梯度不加修改的传递给高经典神经网络训练模型。
损失函数40是神经网络训练中计算前级模型结果和训练输出标签50之间误差的算子。该算子也是推断不相关算子,计算完成误差后将生成损失梯度反向传播到前级算子。
部署编译器200的输入为高精度神经网络训练模型去除推断不相关的算子得到的高精度神经网络推断模型。在编译器中一般会对该模型进行优化,这种优化会导致模型的计算精度下降,比如量化,剪枝,激活函数拟合等。通过编译之后把高精度神经网络推断模型转换层可以在神经网络部署平台300上运行的部署神经网络模型60。
神经网络部署平台300,是指可以运行神经网络推断过程的平台。部署平台支持编译优化后的部署神经网络模型的运行。例如:专用神经网络加速芯片平台,神经网络加速芯片仿真平台,神经网络加速fpga平台等。在运行过程中由于权重,数据,计算过程等与神经网络训练平台的实现有差异,导致最终结果与神经网络训练平台得到的结果有差异。该差异可能会导致部署模型的准确率下降。
图1中省略了测试部署神经网络模型60准确度的部分,只描述了训练相关的。测试准确度的过程在图2中进行描述。
图2为神经网络终端部署微调训练方法的流程图,其流程包括生成原始训练模型s0、生成原始推断模型s1、编译优化s2、计算准确率s3、是否达到目标判断s4、运行部署模型s5、原始模型进行训练,结果用部署模型结果替代s6、生成新模型s7组成。
步骤s0:神经网络训练平台生成原始高精度神经网络训练模型。由于神经网络训练过程一般耗时较长,通常的做法是训练好一个原始模型,在这个原始模型基础上进行微调训练,这样可以加速该训练过程。但也可以是未经训练的模型。
步骤s1:去除原始高精度神经网络训练模型中推断无关算子,生成原始高精度神经网络推断模型。这个步骤和具体编译器有关,如果编译器支持自动去除这些算子,那么该步骤将在编译器中完成。如果编译器不支持,则需要算法人员手动去除。这里所述的训练平台是指例如:tensorflow,pytorch,keras,mxnet等神经网络训练平台;
步骤s2:编译生成部署神经网络模型。其第一次运行载入的模型为原始高精度神经网络推断模型,之后运行载入的模型为步骤s7生成的新高精度神经网络推断模型。在编译过程中一般会采用各种优化算法,比如量化,剪枝,激活函数拟合等。
步骤s3:在部署平台上运行部署神经网络模型,并计算结果的准确率,其输入为测试集。
步骤s4:如果准确率达到目标则结束训练过程,如果未达到目标则继续训练执行步骤s5。比如设定目标是准确率下降百分之1以内。
步骤s5:在部署平台上运行部署神经网络模型,其输入数据为训练输入样本。
步骤s6:在神经网络训练平台对高精度神经网络训练模型进行训练,其输入数据为训练输入样本。第一次训练时载入的模型为原始高精度神经网络训练模型,之后训练时载入的模型为前一轮生成新高精度神经网络训练模型。修改训练结果用部署神经网络模型结果进行替代;
步骤s7:训练完成后得到新高精度神经网络训练模型,去除推断不相关算子,生成新高精度神经网络推断模型,执行步骤s2。
训练原理是:在步骤s6中把部署模型的结果的误差作为一种噪声加入到训练输出中,这种误差的来源是由于编译优化模型以及部署平台计算过程与训练平台不一致导致的,例如量化,剪枝,激活函数拟合,计算顺序差异或者实时动态数据剪枝等操作导致。
该方法把训练输入样本分发给神经网络部署平台上的部署神经网络模型进行推断,并回传结果到训练平台上;在高精度神经网络训练模型的输出节点后加一个替换算子。替换算子和样本分发和回传结果的接口一般由微调工具设计者提供,这些算子和接口结构简单和训练平台耦合度低,大幅减少设计者的工作量和维护成本。
高精度神经网络训练模型通过训练,将得到新的权值解以降低这种噪声对训练准确率的影响,从而提高部署神经网络模型输出结果的准确率。
- 还没有人留言评论。精彩留言会获得点赞!