一种基于深度学习的微表情识别方法与流程
本发明涉及图像处理技术领域,尤其涉及一种基于深度学习的微表情识别方法。
背景技术:
情绪识别技术随着仪器设备的更新与人工智能的发展而日趋成熟,其广泛应用于临床医学、情绪智力、国家安全以及政治心理学等各个领域。现有情绪识别方法主要包括以下两种,一是基于精密仪器的体征检测,通过检测人体脑电、心电、脉搏波等生理信号达到情绪的识别分类,二是基于机器学习的面部情绪智能识别检测,其主要通过捕捉人脸面部肌肉的运动状况,例如开心的时候嘴角上扬,以此实现情绪识别。
前者经常需要较为昂贵和复杂的设备,虽然其检测结果准确度高,但检测费用高、且均属于接触式,数据的采集过程较为复杂,也耗费人力,容易给被试者带来不适,因此在实际应用中具有一定的局限性,不适宜大规模推广,常用于一些特殊场景,例如航天员情绪检测、参与重大救援后军人情绪检测;后者是目前常用的一种识别检测手段,这种方法无需昂贵设备,同时操作简单。但其不能保证所检测识别情绪的准确性,虽然面部表情看起来可以直观地显示情感的变化,但是许多内在的情感变化过程并没有伴随视觉的面部活动被感知,人们可以掩饰和隐藏他们的情感体验,使观察者误会表情的含义,从而影响情绪识别精度。
微表情是人类自发的、难以控制的一种传递情绪的方式。除了我们日常见到的普通的宏表情,在某些特定的场合中,微表情也传达着人类的各种情绪,并且简短、不易察觉、不易掩饰。人可以通过对于情感的控制来掩盖内心真实想法,但是微表情不可能通过控制来掩盖情感。因此微表情可以被参考用来判断人们内心真实想法。基于这一特点,微表情研究在智能医疗、公共安全、司法刑侦等领域有广泛的应用价值。人的脸部是传输信息的媒介,脸部的表情可以表达人类的情绪,所以面部表情在人们日常生活中扮演着非常重要角色。
通常在日常生活中,我们所指的面部表情是“宏表情”,其容易被察觉且持续时间一般为0.5~4s之间。在表达人类感情时,“宏表情”通常能够掩饰真实情感的流露。而与“宏表情”相对的“微表情”,不容易被注意且持续时间约为1/25~1/5s。由于微表情有不受控制,持续时间短且活动幅度小的特点,所以它可以泄露性地表达了人们压抑或试图隐藏的真实情绪。
目前基于深度学习的微表情识别遇到的问题主要有数据集没有足够大,网络结构不够完善所导致的识别率不高的问题和目前识别所采用复杂、昂贵的设备而导致的采集复杂费用过高的问题。
技术实现要素:
为解决上述问题,申请人经过深入研究,发明了一种基于深度学习的微表情识别方法,其技术方案包括以下几个步骤:
步骤1:对含有表情动作的视频数据裁剪,裁剪后的视频要求统一时长为3秒,将裁剪好的视频分帧,提取表情开始到结束的表情图片序列;
步骤2:对提取的表情序列进行人脸对齐,人脸裁剪,以及归一化,均衡化,白化等预处理;
步骤3:将得到的数据集进行数据增强的操作,扩充数据集的大小;
步骤4:搭建神经网络模型;
步骤5:将所有人脸表情数据分成训练集和测试集,使用训练集经过网络进行模型训练;
步骤6:使用测试集对模型进行测试,输出识别准确率,识别时间,误差等信息,当识别率达到要求,选择当前模型;
进一步地,前述步骤4中搭建神经网络模型还包括如下操作:
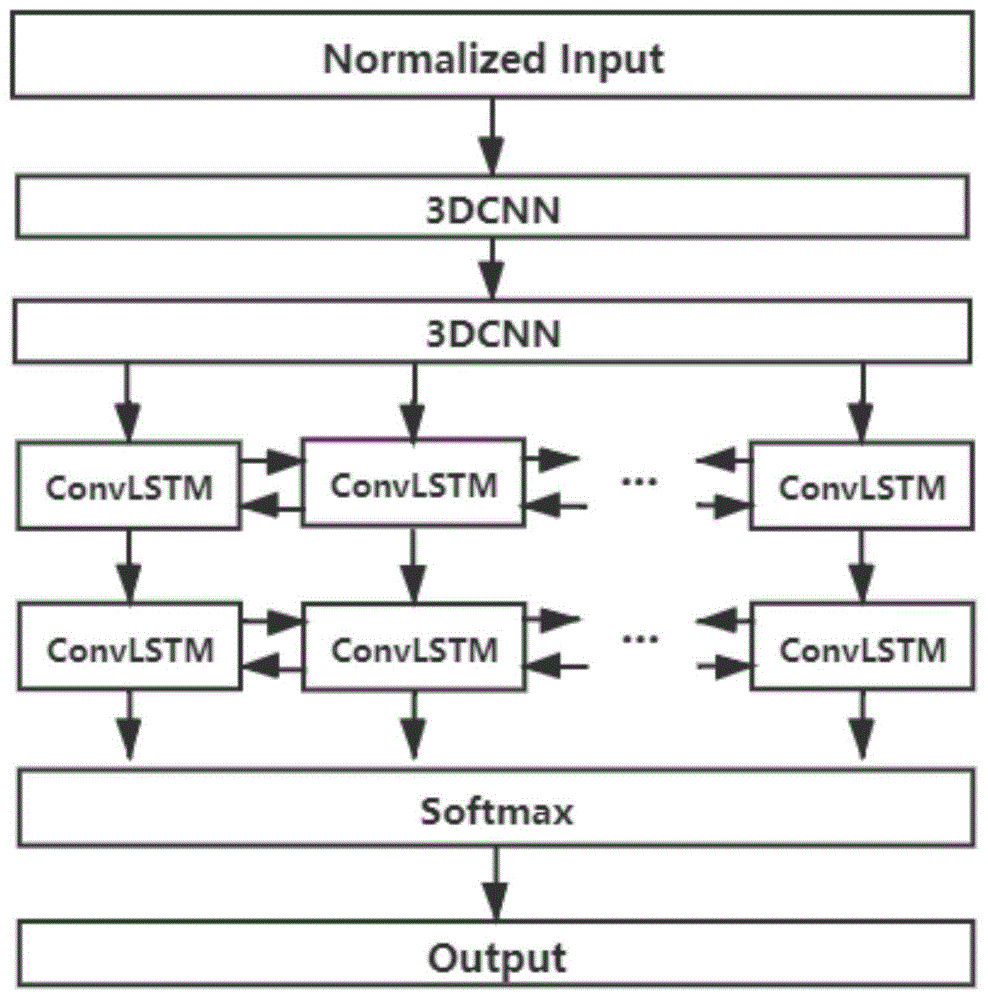
(1):建立包括两层3dcnn和两层convlstm的卷积神经网络结构的卷积神经网络模型:卷积神经网络结构包含输入层、卷积层、最大池化层、全连接层、convlstm层和最后的softmax分类层以及输出层;
(2):将两层3dcnn卷积神经网络结构串联在一起,得到包括两层3dcnn的卷积神经网络结构的卷积神经网络模型,即卷积神经网络模型包括两路卷积神经网络结构,每个3dcnn由32个3*3*15的卷积核构成;
(3):在两层3dcnn之后串联两层convlstm结构,每层由40个lstm并联得到;最后将之前得到的特征向量接入softmax层进行分类;将分类结果连接最后的输出层。
进一步地,前述步骤5中将所有人脸表情数据按照80%与20%的比例分成训练集和测试集,以便对网络模型进行训练和测试。
进一步地,前述步骤6中还包括具体如下操作:
(1):设置网络的超参数,设置超参数可以使网络更加快速地收敛,从而缩短训练时间。
(2):利用训练集中的训练样本对神经网络进行训练,不断优化神经网络中各个参数,使之不断收敛到最优值,从而得到所要的模型
(3):利用测试集中测试样本对得到的模型进行测试,得到上一步模型的准确率,识别时间,误差等结果。
本发明相比于传统的微情绪识别技术,本发明无需使用穿戴设备,我们提出仅需录制包含有不同情绪的视频即可;本发明通过非接触的方式来识别人脸微表情,极大地降低了系统复杂度和提升了系统的便捷性;本发明将采用3dcnn与convlstm的网络结构,避免了因人为故意掩饰情绪或人脸无明显表情变化而导致识别精度低的问题;具有简单、高效、成本低廉、经济实用等特点。
附图说明
图1为整体神经网络结构图;
图2为3dcnn网络结构图;
图3为本发明方法的流程图;
图4为微表情视频片段预处理流程。
具体实施方式
以下将结合附图,对本发明方案作进一步说明。
一种基于深度学习的微表情识别方法,其具体步骤如图3所示:
在本实施实例中,我们选择所发布的casmei和casmeii数据集,由于该数据库各类表情数据量差异较大,最终选择55个anger数据、74个disgust数据、131个happiness数据、36个surprise数据和21个fear数据,共计317个数据。
步骤一:视频数据裁剪;因为微表情不容易被注意且持续时间约为1/25~1/5s,所以我们对含有表情动作的视频数据裁剪,裁剪后的视频要求统一时长为3秒,将裁剪好的视频分帧,提取表情开始到结束的表情图片序列,由于casmeii表情数据库中最短的样本包含4帧,最长的样本包含118帧,通过线性插值将所有样本的帧数归一化为120。
步骤二:提取预处理:对提取的表情序列进行人脸对齐,人脸裁剪,以及归一化,均衡化,白化等预处理,如图4所示:
(1)对于预处理中前两个模块,采取数据库的建议,得到对齐后和裁剪后的人脸区域图像序列。在该过程中,首先根据aam算法对每个微表情片段样本检测出其自然表情状态下人脸图像的68个特征点ψ(mi),随后利用局部加权平均方法对每个微表情片段中的第一帧图像进行如下变换:
ti=lwm(ψ(mi),ψ(fi,1)),i=1,2,...,n
其中ψ(fi,1)为第i个视频片段中第一帧图像的68个特征点。接着在求得每个视频片段的变换矩阵ti之后,采用如下公式进行图像对齐操作:
f′i,j=ti×fi,j,j=1,2,...,k
其中fi,j为第i个视频片段中第j帧对齐后的人脸图像。最后,根据每个视频片段第一帧的人脸眼部坐标裁剪出矩形区域人脸。
为了适应本文方法的数据输入,在以上数据处理的基础上,还需要依次对裁剪好的微表情样本进行视频归一化、数据集扩充和计算光流图像序列处理。现分别介绍这几个预处理模块
(2)由于微表情持续时间的不同和被试个体之间的差异,不同的微表情片段样本经过裁剪后得到的人脸图像序列在图像尺寸和帧数上均有差别,实际上,对casmei数据集,裁剪后图像尺寸大约在150×190左右,视频帧数最短的为10帧,最长为68帧;对casmeii数据集,图像尺寸大约在280×340左右,视频帧数最短为24帧,最长为146帧。因此,在数据进行特征分析前,需要在视频的帧数和图像尺寸上归一化。
在视频帧数归一化上,最常用的模型就是时间内插模型(tim)。对于一个图像尺寸为m×n,帧数为n的视频进行归一化时,首先得到其在时间轴上的离散化向量t,
接着对视频中任意一像素点i,j,其对应位置的像素值向量ii,j,建立时间内插模型,
tim=curve(it,j,t)
其中curve(ii,j,t)表示以ii,j为横轴,t为纵轴拟合得到的曲线。本文采用直线拟合方式,即两点之间的线段采取直线连接。模型若需要将视频归一化到n′帧,则在tim模型上取离散点t’={0,1/(n’-1),2/(n’-1),…,1}处的像素值。
上述帧数归一化中需要注意的是,由于原始图像序列为rgb模式,因此在实际中采取分别对每个通道进行帧数归一化操作。文中所用数据样本来自两个数据库(casmei、casmeii),即将两个数据库合在一起作为一个样本集,随后对全体数据集分别进行65帧、129帧归一化操作,归一化大小主要考虑到以下两个因素:1.消除数据库在视频帧数上的差异(casmei:60fps、casmeii:200fps);2.方便卷积神经网络的处理,帧长度保持为2的整数倍(后续经过光流处理后,帧数分别变为64和128)。
在图像尺寸归一化上,本文将所有图像数据归一化到112×96像素。图像尺寸归一化大小主要考虑到以下两个因素:1.尽可能少的影响微表情的动态特征,图像归一化后的尺寸比例尽量与原来相同(casmei中150×190、casmeii中280×340);2.方便卷积神经网络的处理,图像大小保持为2的整数倍。
经过视频帧数尺寸归一化后,对全体微表情样本(casmei/ii共444个视频片段),共得到了两组数据集。其中,一组包含444个视频片段,视频帧数和图像尺寸大小分别是65和112×96;另一组同样包含444个视频片段,视频帧数和图像尺寸大小分别是129和112×96。
步骤三:数据集扩充:
若从每类中按照一定比例选取微表情视频片段组成训练集,该训练集除了样本量小之外,还存在数据类别极其不均衡的现象,因此在训练后续的卷积神经网络中除了容易出现过拟合现象外,学习到的特征在很大程度偏向于数据量多的样本类。
对于训练数据集扩充,卷积神经网络中常用方法包括图像裁剪、拉伸、添加噪声等。但就微表情图像序列而言,由于微表情运动极其微小且持续时间短,拉伸、添加噪声等均有可能改变微表情的运动信息,且大幅度的裁剪操作也可能损失微表情某部分的动态信息。故本节在数据扩充中仅采取小幅度裁剪,翻转,旋转方式。
本次训练数据集扩充按照如下步骤进行:
(1)定义视频采样方法。对于一段图像尺寸为m×n的视频片段,随机选取图像的上、下、左、右、中部及四个对角处截取一个大小为(m-2)×(n-2)像素的区域,随后归一化到m×n。
(2)对训练集中每类微表情视频样本,随机选取一个样本进行(1)操作,产生一个新的视频片段。
(3)重复操作(2)若干次,直到该类样本数量达到5000个即可。经过上述数据扩充方式,消除了样本的不均衡现象同时还保证了训练集中每类样本都具有一定量的数目,进而在卷积神经网络训练上,保证了训练类别的无偏性以及缓解了训练过程中过拟合现象的产生。
步骤四:构建神经网络:
(1)如图1所示,建立包括两层3dcnn和两层convlstm的卷积神经网络结构的卷积神经网络模型:卷积神经网络结构包含输入层、卷积层、最大池化层、全连接层、convlstm层和最后的softmax分类层以及输出层,将两层3dcnn卷积神经网络结构串联在一起,得到包括两层3dcnn的卷积神经网络结构的卷积神经网络模型,即卷积神经网络模型包括两路卷积神经网络结构,每个3dcnn由32个3*3*15的卷积核构成;在两层3dcnn之后串联两层convlstm结构,每层由40个lstm并联得到;最后讲之前得到的特征向量接入softmax层进行分类;将分类结果连接最后的输出层。
(2)如图2所示,3dcnn的第一层由一个大小为2*2*2,步长为2*2*2的最大池化层构成;第二层是一个relu的激活函数;第三层是batchnorm,没有它之前,需要小心的调整学习率和权重初始化,但是有了bn可以放心的使用大学习率,但是使用了bn,就不用小心的调参了,较大的学习率极大的提高了学习速度,batchnorm本身上也是一种正则的方式,可以代替其他正则方式如dropout等,另外,batchnorm降低了数据之间的绝对差异,有一个去相关的性质,更多的考虑相对差异性,因此在分类任务上具有更好的效果;第四层由32个3*3*15的卷积核组成,其步长为1*1*1;第五层是大小为2*2*2,步长为2*2*2的最大池化层;第六层为relu层激活函数;第七层是第二个3dcnn卷积层,大小为3*3*15,步长为1*1*1。
步骤五:训练、测试;将所有人脸表情数据按照80%与20%的比例分成训练集和测试集,以便对网络模型进行训练和测试。
步骤六:测试、选择、确定模型;使用测试集对模型进行测试,输出识别准确率,识别时间,误差等信息,当识别率达到要求,选择当前模型。要想实现前述步骤6,还包括如下具体操作:(1):设置网络的超参数,设置超参数可以使网络更加快速地收敛,从而缩短训练时间;(2):利用训练集中的训练样本对神经网络进行训练,不断优化神经网络中各个参数,使之不断收敛到最优值,从而得到所要的模型;(3):利用测试集中测试样本对得到的模型进行测试,得到上一步模型的准确率,识别时间,误差等结果。
通过上述几个步骤,成功实现了本发明的技术目的,即通过一种基于深度学习的微表情识别方法实现了对人脸的情绪识别。
上述技术方案仅体现了本发明技术方案的优选技术方案,本技术领域的技术人员对其中某些部分所可能做出的一些变动均体现了本发明的原理,属于本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!