一种基于眼动数据的修正型实时情感识别方法及系统与流程
本发明涉及情感识别领域,具体涉及一种基于眼动数据的修正型实时情感识别方法及系统。
背景技术:
随着虚拟现实技术应用的普及,人机交互越发受到重视。vr环境中的人机交互,例如眼动交互、语音交互、手势交互以及姿势交互等交互技术的研究都逐渐走向成熟。目前在情感交互方面,国内外大多数是基于表情或心率、脑电等生理参数的研究,而vr中基于眼动的情感交互研究却不多见,相关研究方法也存在着明显不足。但事实上,根据心理学研究,眼睛最能反映一个人的心理状态和情感。
在虚拟现实环境中,计算机能实时量化地理解人的情感,可以根据人的情感及时做出响应,这将给用户带来更舒适的体验感。目前,情感识别主要是依据脑电,如音频、图像、文本等材料。而脑电信号相对较微弱,抗干扰性小。人的情感是多种感觉、思想和行为综合产生的心理和生理状态,且存在着情绪唤醒效应,不能准确识别情感。
技术实现要素:
为了克服现有技术存在的缺点与不足,本发明提供一种基于眼动数据的修正型实时情感识别方法及系统。本发明充分利用眼动数据和虚拟场景信息在vr环境中进行情感识别,提高人类情感识别的准确率。
本发明采用如下技术方案:
一种基于眼动数据的修正型实时情感识别方法,包括如下步骤:
实时采集用户在vr环境中的眼动数据;
通过当前的眼动数据得到当前注视点区域图
通过当前的眼动数据得到当前视场图
利用眼动情感预测模块得到情感状态e2;
利用e2对e1进行修正,得到最终情感状态e3。
进一步地,在实时采集用户在vr环境中的眼动数据步骤之前,还包括采集用户在vr环境的历史眼动数据,并通过历史眼动数据得到历史注视点,并采用lstm网络对历史注视点坐标进行编码。
进一步地,将当前注视点的编码特征及显著性编码特征送入预先训练好的注视点区域预测模型,得到下一帧的注视点区域图
通过当前的眼动数据得到当前注视点区域图
考虑下一帧的注视点与当前注视点、当前注视点运动状态、用户观看习惯以及下一帧360°全景图像有关,利用cnn对
将提取的特征和经过编码的历史注视点坐标作为注视点区域预测模型的输入,得到下一帧的注视点的轨迹位移值,注视点区域预测模型的损失函数为:
其中t为当前时刻往后的t个帧的时间段,f(·,·,·)为网络模型函数,输出为注视点轨迹位移值,cur为特定帧数;
预测的下一帧注视点坐标为
进一步地,所述通过当前的眼动数据得到当前视场图
利用cnn模型对
利用svm得到初步情感状态e1,其中e1∈{1,2,3,4,5,6},
进一步地,所述利用眼动情感预测模块得到情感状态e2步骤,具体为:
提取前t帧时间段的眼动数据,得到眼动数据的时间序列
眼动情感预测模块输入信号为眼动数据x2,输出为情感分布向量e2,[e1,e2,e3,e4,e5,e6],emax为情感分布向量中的最大值,ei为情感分布向量中的第i个元素,每个元素为分别对应愤怒、厌恶、恐惧、愉快、悲伤、惊讶这6种情感的概率值,且
其中y2=[y1,y2,…yn-1,yn]为训练样本标签的定量值,yi为训练样本标签的情感分布向量,yi=[e1,e2,e3,e4,e5,e6],ei为情感分布向量中的第i个元素,每个元素为分别对应愤怒、厌恶、恐惧、愉快、悲伤、惊讶这6种情感的概率值,且
进一步地,利用e2=[e1,e2,e3,e4,e5,e6]对e1进行修正,得到最终情感状态e3[e′1,e′2,e′3,e′4,e′5,e′6,],具体为:
进一步地,所述cnn模型为5个卷积(5*5)池化层(2*2maxpooling),两个全连接层fc_1,fc_2。
进一步地,所述眼动数据包括瞳孔直径、注视点坐标、眼皮张合度、眼跳及注视时间。
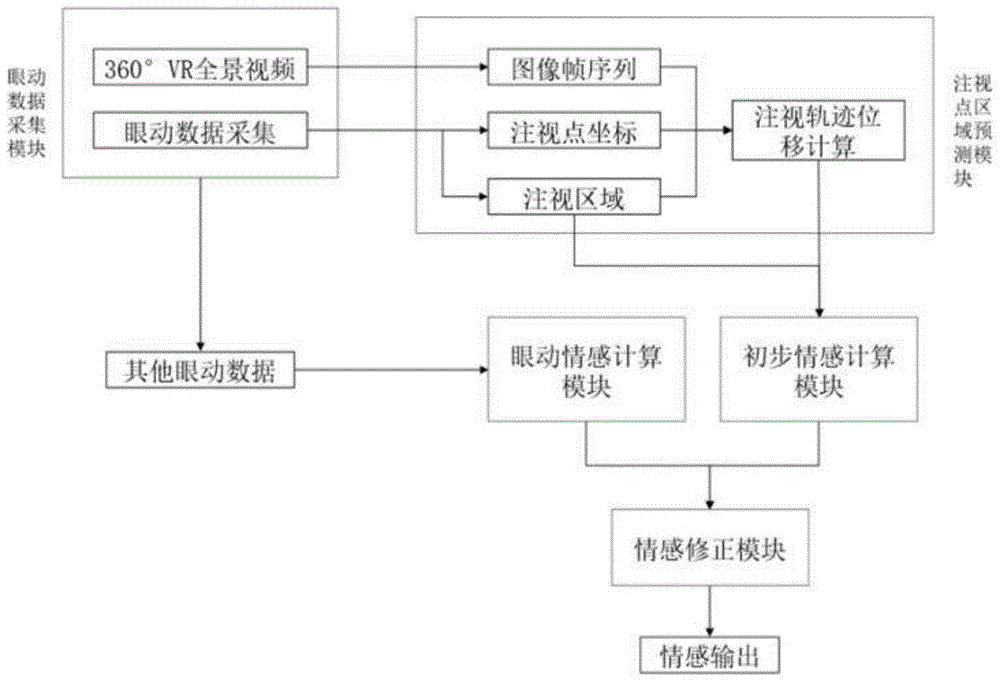
一种修正型实时情感识别方法的系统,包括:
眼动数据采集模块,通过在头戴式vr设备中集成眼动仪的镜片实现采集眼动数据;
注视点区域预测模块,通过当前的眼动数据得到当前注视点区域图
初步情感计算模块,通过当前的眼动数据得到当前视场图
眼动情感计算模块,历史眼动数据进行特征提取,作为眼动情感预测模块的输入,得到情感状态e2;
情感修正模块,利用e2对e1进行修正,得到最终情感状态e3。
本发明的有益效果:现有的基于生理信号的情感识别研究中,多以脑电信号为主,但在实际应用中,脑电信号的采集方式复杂,并且脑电信号强度弱,抗干扰能力低,基于非生理信号的情感识别,在实际应用中,难以排除用户刻意隐瞒的现象,而本发明采用在眼动仪集成在vr眼镜上,使得眼动信号易于采集;
本发明基于眼动信号及场景图像的识别,不仅能识别用户的真实情感状态,,采集方式简单,信号抗干扰性强,提取的特征对情绪表征能力强。
附图说明
图1为本发明方法总体示意图;
图2为本发明方法步骤s2流程示意图;
图3为本发明方法步骤s3、s4、s5流程示意图。
具体实施方式
下面结合实施例及附图,对本发明作进一步地详细说明,但本发明的实施方式不限于此。
实施例
如图1所示,一种基于眼动数据的修正型实时情感识别方法,包括如下步骤:
s1在头戴式vr设备中集成眼动数据采集模组,用户佩戴vr设备,自主探索360°全景视频中的内容,实时采集用户在此过程中的眼动数据,同时获得视频帧序列;
本实施例中的眼动数据采集模组具体为眼动片,眼动数据包括包含眼图、瞳孔半径,瞳孔在图像中的位置、上下眼皮距离、注视点(平滑与非平滑)等。
采用上述方案的有益效果为:vr沉浸式的体验感让用户更加身临其境,用户不易受到外界环境的干扰,集成眼动模组在vr头显中,采集到的数据实时且更可靠
如图2所示,s2通过当前的眼动数据得到当前注视点区域图
具体为:
s2.1通过历史眼动数据得到历史注视点坐标
利用lstm网络对历史眼动数据进行编码。
s2.2采集当前眼动数据得到当前注视点区域图
s2.3考虑到下一帧的注视点与当前注视点、当前注视点运动状态、用户观看习惯以及下一帧360°全景图像有关,利用cnn模型对
本实施例中采用的cnn模型为5个卷积(5*5)池化层(2*2maxpooling),两个全连接层fc_1,fc_2。
s2.4将提取的图片特征和经过lstm网络编码的历史注视点坐标特征作为深度神经网络的输入,得到下一帧的注视点的轨迹位移值。深度神经网络的损失函数为:
其中t为当前时刻往后的t个帧的时间段,f(·,·,·)为网络模型函数,输出为注视点轨迹位移值,cur为特定的帧数;
s2.5预测的下一帧注视点坐标为
采用上述方案的有益效果为:历史注视点坐标能反映用户注视区域的变化,进一步体现用户兴趣区域的变化。用户第一注视区域可能是由图像显著性导致,而用户注视区域的转换,则更多是用户主观能动的转移,其中的信息能体现用户情感的变化。用户注视区域一般与图像显著性、物体的运动状态以及用户本身的实现探索习惯相关,因此历史注视点坐标中包含着用户注视点转移信息。采用lstm网络提取注视点坐标特征,更能从时间上反映这一注视点转移信息。采用下一帧图像和当前注视区图像是考虑图像显著性和物体运动状态对注视视线的影响。这样能更准确预测下一帧的注视点。
如图3所示,s3通过当前的眼动数据得到当前视场图
s3.1、利用cnn对
s3.2、利用svm得到初步情感状态e1,其中e1∈{1,2,3,4,5,6}。
本发明采用cnn进行特征提取,cnn对图像特征提取有着显著的效果。经过多次试验,svm采用高斯核分类效果最佳。定性得到用户情感状态。
s4将历史眼动数据进行特征提取,作为眼动情感预测模块的输入,得到情感状态e2;
进一步方案,s4具体包括:
s4.1、对眼动设备采集到的原始数据进一步分析处理,得到瞳孔直径、注视点坐标、眼皮张合度、眼跳、注视时间等眼动数据,提取前t帧时间段的眼动数据,得到眼动数据的时间序列
s4.2眼动情感预测网络是基于大规模带情感分布向量的眼动数据训练的cnn,网络的输入为s4.1提取的眼动数据x2,输出为情感分布向量e2[e1,e2,e3,e4,e5,e6],emax为情感分布向量中的最大值,ei为情感分布向量中的第i个元素,每个元素为分别对应愤怒、厌恶、恐惧、愉快、悲伤、惊讶这6种情感的概率值,且
其中y2=[y1,y2,…yn-1,yn]为训练样本标签的定量值,yi为训练样本标签的情感分布向量,yi=[e1,e2,e3,e4,e5,e6],ei为情感分布向量中的第i个元素,每个元素为分别对应愤怒、厌恶、恐惧、愉快、悲伤、惊讶这6种情感的概率值,且
采用上述进一步方案的有益效果为:通过vr场景信息定性得到用户情感状态,利用用户眼动变化数据定量得到用户的真实情感状态。根据心理学研究表明,眼动信息对情感识别有着重要的作用,眼动特征向量能反映用户的细微情感变化,定量分析情感变化。
s5利用e2对e1进行修正,得到最终情感状态e3[e′1,e′2,e′3,e′4,e′5,e′6,]。其中:
利用e2对e1进行修正,定性定量的得到用户情感状态,有效提高了vr环境中情感识别的准确率。
一种基于眼动数据的修正型实时情感识别系统,包括:
眼动数据采集模块,用于vr环境中眼动数据的采集,获取用户在探索360°全景视频时的注视点、注视轨迹、瞳孔、眼皮张合度等数据;
注视点区域预测模块,包括注视点坐标特征提取模块、图像特征提取模块和注视轨迹位移预测模块。注视点坐标特征提取模块,用于获取注视点时间上的显著信息。图像特征提取模块,用于获取注视区域空间显著信息。注视轨迹位移预测模块,用于获取注视点的位移值,从而最终获得下一帧的注视点坐标和注视点区域;
初步情感计算模块,包括特征提取模块和情感定性分析模块。特征提取模块用于获取注视区域空间显著信息。情感定性分析模块用于对提取的空间显著信息进行定性分析,获得初步情感状态e1;
眼动情感计算模块,用于从眼动特征向量定量的获得用户的情感状态e2;
情感修正模块,动态地将e2按照一定比例对e1进行修正,得到最终情感状态分布向量e3。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受所述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!