基于自适应空间监督的动态手势识别方法与流程
本发明涉及视频分析与模式识别领域,具体涉及一种动态手势识别方法。
背景技术:
伴随着人机交互方式的快速革新,手势识别以其广泛的应用性使得其有着重要的研究意义,近年来基于计算机视觉的手势识别逐渐成为了研究热点。手势识别作为一种新型的人机交互方式,可以取代原有的传统触摸交互方式,在家庭娱乐、智能驾驶、教学应用、智能穿戴等多个领域都有着重要的应用前景。
手势识别是通过数学算法来识别人类手势动作的一个议题,手势可以分为静态手势和动态手势。静态手势识别往往考虑某一时刻手的姿态信息,多利用单帧图片中的手的形状或关键点的静态坐标,无法考虑时序问题,在实际应用场景中有很大的局限性。而动态手势识别考虑手势的时序关系,结合帧与帧之间的相关性,多采用模型参数空间的轨迹信息,应用面广,可识别的手势类别丰富,实际应用性高。
技术实现要素:
针对传统的动态手势识别中手势跟踪算法在目标短暂丢失情况下跟踪效果差的缺点以及长序列模型依赖问题,本发明提出一种基于空间监督的动态手势识别算法,利用双流lstm网络模型,以视觉特征对识别结果进行识别监督,有效的提高手势区域跟踪效果,提高识别率。
本发明的目的可以通过以下技术方案实现:
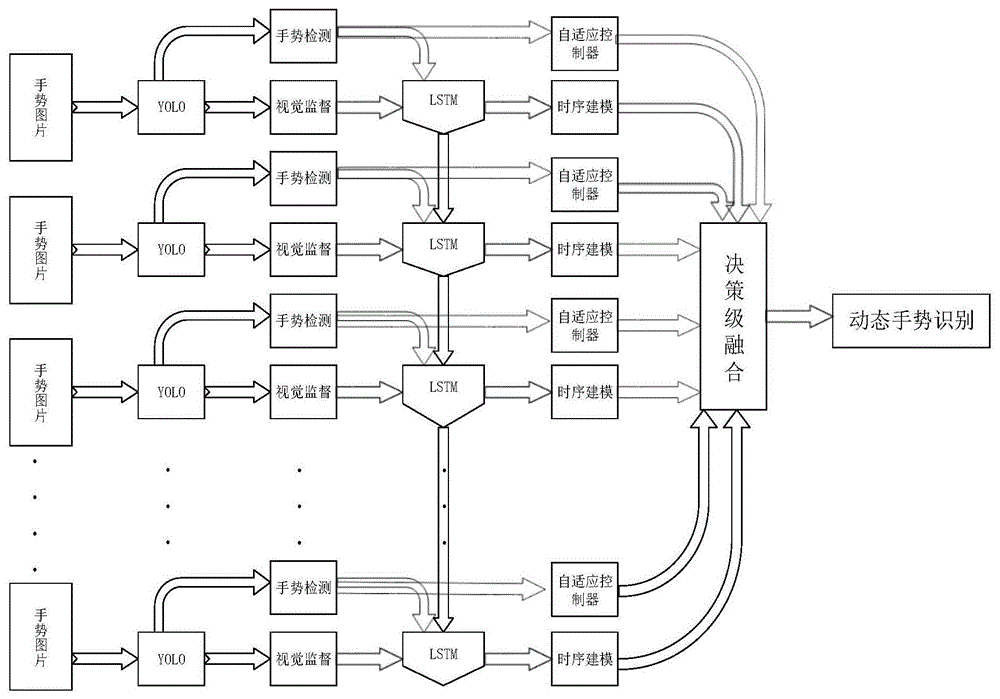
一种基于自适应空间监督的动态手势识别方法,该方法首先通过卷积网络模型对视频序列进行高层视觉特征提取,并通过yolo模型得到手势区域的位置信息,将位置信息转化为特征向量后,将手势位置特征和高层视觉特征分别输入到双流长短期记忆网络模型(lstm)对手势轨迹进行时序模型跟踪,以手势位置特征作为主要跟踪环节,高层视觉特征对识别结果进行空间监督,并利用yolo输出结果中的平均置信度作为自适应融合控制器参数,实现自适应融合权重调节,促进跟踪网络的回归,实现手势快速跟踪识别。
进一步地,具体包括以下步骤:
步骤1:读取动态手势视频序列;
步骤2:基于卷积层神经网络模型,分别提取视频序列中每帧图像的高层视觉特征,通过第一个全连接层输出一组视觉特征特征向量u用来训练lstm模型;
步骤3:利用手势检测器对视频序列中的标志手势区域进行检测定位;
步骤4:将步骤3中得到的手势区域特征转化为一组新的特征特征向量v用来训练新的lstm模型;
步骤5:设计一个自适应融合控制器m用来控制决策级融合权重,并提取步骤4中得到的特征向量v中的置信度信息p作为自适应控制器控制参数;
步骤6:将步骤3、步骤4得到的两组特征向量输入到双流lstm模型,结合前后帧特征信息,建立时序模型,对手势区域进行跟踪识别;
步骤7:利用步骤5得到的自适应控制器控制双流lstm模型做决策级融合;
步骤:8:根据lstm网络的融合结果得到动态手势的识别结果。
进一步地,所述步骤1中需要预先定义一个静态标签手势“point”作为动态手势跟踪器的启用手势。
进一步地,所述步骤2中的卷积层神经网络模型以视频作为输入来进行特征学习训练,通过yolov2的第一个全连接层生成整幅图像的4096维向量u作为视觉特征的密集表示,完成对可视手势的广义理解。
进一步地,在步骤3中选择yolov2网络结构作为手势检测器,在卷积层的基础上,通过全连接层将特征表示回归到区域预测,得到手势区域标签特征向量v,其中v包含五维信息[xywhp],其中(xy)为手势区域中心坐标,(wh)为手势区域尺寸,p为手势置信度。
进一步地,在步骤5中,自适应融合控制器是与lstm模型等步长的控制模块m,初始时,m=[00…00],将每帧图像的特征向量v中的置信度p依次按位输入到控制器m中,此时m=[plpl-1…p3p2p1];自适应控制率公式:
进一步地,在步骤7中,将特征向量u、v分别输入双流lstm网络做时序建模,两个lstm模型分别得到手势识别结果后在自适应融合控制器控制下做决策级融合,其中以手势区域特征v为输入的lstm模型的融合权重为η,另一个lstm模型权重为1-η。
本发明的有益效果:
本发明将yolo模型与lstm模型相结合,保留yolo对特定物体快速检测的优点的同时,利用lstm神经网络对手势区域进行时序模型跟踪,有效的解决动态手势存在的长序列模型依赖问题,达到在短暂时间序列手势丢失情况下跟踪的目的,有效的提高动态手势的识别率。
附图说明
为了便于本领域技术人员理解,下面结合附图对本发明作进一步的说明。
图1是本发明基于空间监督的动态手势识别方法的算法流程图;
图2是本发明中基于yolo模型的特征提取流程图;
图3是本发明中lstm模型中基础结构图;
图4是本发明中决策级融合框图;
图5是本发明中定义的6种动态手势轨迹示意图;
图6为本发明中动态手势识别率混淆矩阵。
具体实施方式
本发明主要关注动态手势识别,利用深度学习网络融合来识别6种动态手势,yolo模型预先检测起始标志手势,再提取的手势区域特征训练lstm模型做时序模型跟踪,卷积层提取的全局视觉特征训练lstm模型对最终结果进行监督,通过双流lstm模型的做决策级融合对动态手势进行识别。
一种基于自适应空间监督的动态手势识别方法,包括以下步骤:
步骤1:读取动态手势视频序列;预先定义一个静态标签手势“point”作为动态手势跟踪器的启用手势。
步骤2:基于卷积层神经网络模型,分别提取视频序列中每帧图像的高层视觉特征,通过第一个全连接层输出一组视觉特征特征向量u用来训练lstm模型;传统卷积层网络以视频作为输入来进行特征学习训练,通过yolov2的第一个全连接层生成整幅图像的4096维向量u作为视觉特征的密集表示,完成对可视手势的广义理解。
步骤3:利用手势检测器对视频序列中的标志手势区域进行检测定位;
步骤4:将步骤3中得到的手势区域特征转化为一组新的特征特征向量v用来训练新的lstm模型;选择yolov2网络结构作为手势检测器,在卷积层的基础上,通过全连接层将特征表示回归到区域预测,得到手势区域标签特征向量v,其中v包含五维信息[xywhp],其中(xy)为手势区域中心坐标,(wh)为手势区域尺寸,p为手势置信度。
步骤5:设计一个自适应融合控制器m用来控制决策级融合权重,并提取步骤4中得到的特征向量v中的置信度信息p作为自适应控制器控制参数;自适应融合控制器用来控制后期特征融合,控制器是与lstm模型等步长的控制模块m,初始时,m=[00…00],将每帧图像的特征向量v中的置信度p依次按位输入到控制器m中,此时m=[plpl-1…p3p2p1];自适应控制率公式:
步骤6:将步骤3、步骤4得到的两组特征向量输入到双流lstm模型,结合前后帧特征信息,建立时序模型,对手势区域进行跟踪识别;
步骤7:利用步骤5得到的自适应控制器控制双流lstm模型做决策级融合;将特征向量u、v分别输入双流lstm网络做时序建模,两个lstm模型分别得到手势识别结果后在自适应融合控制器控制下做决策级融合,其中以手势区域特征v为输入的lstm模型的融合权重为η,另一个lstm模型权重为1-η。
步骤:8:根据lstm网络的融合结果得到动态手势的识别结果。
为了进一步说明本发明,下面结合附图对本发明进行详细地描述,但不能将它们理解为对本发明保护范围的限定。
如图1所示,本发明提供一种基于空间监督的动态手势识别方法,包括以下步骤:
步骤1:读取动态手势视频序列;
步骤2:基于卷积层神经网络模型,分别提取视频序列中每帧图像的高层视觉特征,通过第一个全连接层输出一组视觉特征特征向量u;
步骤3:利用手势检测器对视频序列中的标志手势区域进行检测定位;
步骤4:将步骤3中得到的手势区域特征转化为一组新的特征特征向量v;
步骤5:设计一个自适应融合控制器m用来控制决策级融合权重,并提取步骤4中得到的特征向量v中的置信度信息p作为自适应融合控制器参数;
步骤6:将步骤3、步骤4得到的两组特征向量输入到双流lstm模型,结合前后帧特征信息,分别建立两组时序模型,对手势区域进行跟踪识别;
步骤7:利用步骤5得到的自适应控制器控制双流lstm时序模型做决策级融合;
步骤:8:根据lstm网络的融合结果得到动态手势最终的识别结果。
在步骤2中的特征向量u为整幅图像的高层视觉特征的集合,是通过yolo模型的前端卷积层提取的全局视觉特征表示,用来对手势图像进行全局时序建模。受限于yolov2模型的全连接层尺寸,输入图像的尺寸为448×448,经过卷积层提取特征得到4096维特征表示,与传统的yolo模型所不同的是,本发明将yolov2的第一个全连接层整合的特征集合不仅仅用于区域预测,还通过该特征向量训练新的学习网络用于后期的跟踪网络监督来促进跟踪模型的快速回归。如图2所示为本实施例基于yolo模型的特征提取流程图。
在特征集合u的基础上,再通过全连接层将特征表示回归到区域预测,预测编码为s×s×(b×5+c)维张量,其中s表示输入图片的分割规格,b表示每个格子输出的边界框个数,c为分类类别。本发明中遵循原始yolov2架构,设置s=7,b=2,但分类类别c=1,将图像分割为7×7个cell,输出7×7×(2×5+1)=539维特征向量v,用来对手势中心位置进行跟踪。特征向量中每个边界框包含的特征向量[xywhp],其中(xy)为手势区域相对中心点坐标,(wh)为手势相对边界框尺寸,每个边界框的中心点坐标均为相对于其对应的cell左上点坐标的偏移,此时即保证每个边界框的中心点均落在其对应的cell中。其计算公式如下:
x=σ(tx)+cx
y=σ(ty)+cy
其中(cx,cy)表示为cell的左上角坐标,pwph是是先验框的宽度与长度,txtytwth为边界框预测的4个偏置补偿。p为置信度分数,包含最终属于哪个类别的权重,又包含了边界框位置的准确度;其公式如下:
p=p(object)*iou
其中:若边界框对应格子包含物体,则p(object)=1,否则p(object)=0;iou表示当前检测与其有效检测历史均值之间的相交-过并距离,其公式为:
步骤5中,设计一种自适应融合控制器,用来控制步骤6中的双流lstm的融合,该控制器是与lstm模型等步长的控制模块m,初始时,m=[00…00],然后将每帧图像的特征向量在输入到lstm模型的同时,同步将v中的置信度p单独作为控制器参数依次按位输入到控制器m中,此时m=[plpl-1…p3p2p1],通过计算周期内平均置信度进而控制双流lstm的特征融合权重,自适应控制率公式:
在现有的以yolo模型与lstm模型结合做跟踪的相关研究中,大多将置信度特征舍弃,在本发明中,则通过置信度参数控制后期融合权重,可以在yolo存在手势检测效果不好甚至在未检测到手势区域时,可以自动调节后期融合的权重,将空间监督的融合权重提高,降低中心区域坐标跟踪所占的融合权重,可以更好的完成监督学习。如图3所示为本实施例中lstm模型中的基础结构图;
在所述的步骤6中所用到的长短期记忆网络模型(lstm)是循环神经网络(rnn)的一种变体,在传统的rnn网络中加入了遗忘和保存机制,模型可以选择性忘掉一些用不上的长期记忆信息,学习新输入中值得使用的信息,然后存入长期记忆中;把长期记忆聚焦到工作记忆中,对时间维度更加敏感,而且不需要一直使用完整的长期记忆,可以解决时序模型中的长时间模型依赖问题。lstm基础结构图如图4所示。
该结构单元在隐层中加入了输入门、遗忘门、输出门和输入调制门,通过门结构将各层间信号和某一时刻的输入信号结合起来,其各门结构的输出公式如下:
inputgate输出公式:
forgetgate公式:
cell输出公式:
outputgate输出公式:
最终celloutput输出公式:
其中:xt为当前时刻input作为输入,
网络的最终输出我们利用softmax方程计算结果属于某一类的概率。多分类问题的概率函数公式如下:
对于网络输出a1,a2...对应我们可以得到p(c1|x),p(c2|x)…,即给定输入x输出类别为c1,c2,...的概率。其损失函数为:
在本发明中将两组特征u、v分别输入到双流lstm模型进行时序建模跟踪,利用不同的两种特征对动态手势进行建模识别,在lstm网络的softmax层分别输出动态手势识别的结果。
在步骤7中:在自适应融合控制器m的控制下,将两个lstm模型的输出结果做决策级融合,融合的规则按照自适应控制器输出的平均置信度进行。该方法可以自动调节两种结果的融合权重,可以在yolo检测效果不佳的情况下,将另一流lstm的结果权重调高,提高最后的识别结果。
本发明在自建的动态手势数据库进行测试,测试主要目的在于测试本发明设计的解决方法对于动态手势识别系统的有效性。该数据库包含“rectangle”“circle”“triangle”“line”“down”“correct”6类动态手势动作,每类动作下包含有200个动作视频,其中170个作为训练样本,30个作为测试样本。测试结果的最高识别率为100%,平均识别率可达到94.8%。图6为识别率的混淆矩阵。混淆矩阵的主对角线代表正确的识别率。
- 还没有人留言评论。精彩留言会获得点赞!