一种基于异质网络表示学习的链路预测方法与流程
本发明属于网络分析领域,涉及一种链路预测方法,尤其涉及一种基于异质网络表示学习的链路预测方法。
背景技术:
现实世界中存在大量的复杂系统都可以抽象成网络形式来体现,所以近些年对网络的研究成为多个学科和领域的研究热点。而在大数据时代,随着大量社交网络和信息网络的出现,使得链路预测的研究与网络的结构与演化紧密联系起来。与此同时,链路预测的研究也可以从理论上帮助认识复杂网络演化的机制。所以,链路预测已经成为数据挖掘研究的一个重要方向。
但当前对于链路预测的研究存在一些问题。一方面,当前研究主要针对同质信息网络,这种网络只含一类节点和一类连接即所有节点类型是相同的。现实中大多数网络是异质的,包括社交网络在内,网络中包含了多种类型的节点,不同类型的节点组成了不同类型的连接。这些不同类型的节点和连接构成了一个富含语义信息和结构特征的网络。显然对异质网络的链路预测对于链路预测本身以及复杂网络研究的理论基础的建立和完善,可以起到推动和借鉴的作用。另一方面,大多链路预测方法基于邻域局部信息和结构特征,对网络的聚集系数要求较高,稀疏网络预测效果较差,且复杂度较高对大规模网络不友好。
本发明是基于异质网络表示学习的一种链路预测方法。这种方法既解决了当下多数链路预测方法无法获取异质网络不同节点类型和连接类型所蕴含的丰富信息,又通过网络表示的方式获取网络整体结构,降低了算法的复杂性。
技术实现要素:
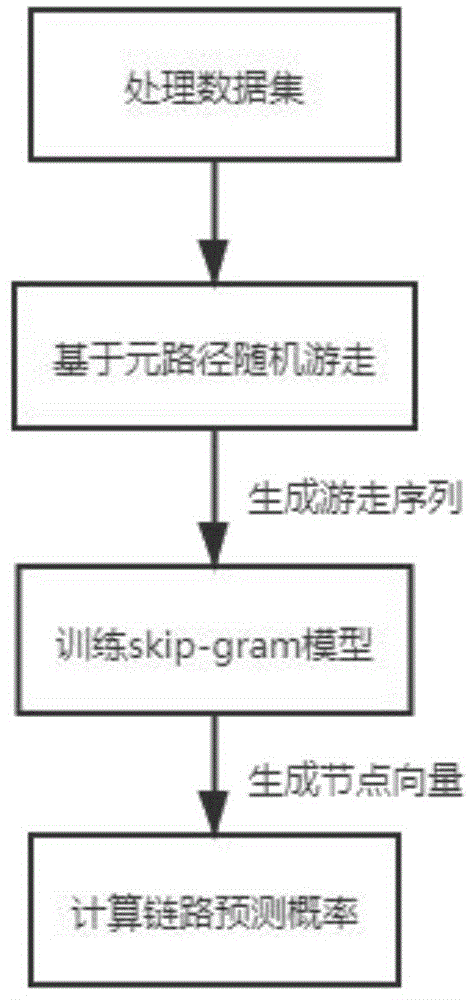
本发明的目的在于提出一种基于异质网络表示学习的链路预测方法,该方法主要分为三个部分:通过基于元路径的随机游走捕获异质网络的结构和语义,生成训练序列;应用训练序列训练skip-gram模型以此来学习网络特征,将网络节点映射到低维向量;通过对节点向量的相识度处理得到链路预测结果,实验使用dbis(databaseandinformationsystems)数据集。具体步骤如下:
步骤(1)提取节点建立标识;
从数据集中提取作者,文章,会议三种节点类型,并分别建立id用于标识。在处理连接关系和随机游走时把id作为唯一标识,获取具体内容需要查询映射表。
步骤(2)提取连接边和隐藏关系;
从数据集网络中提取作者与论文的关系,论文与会议的关系作为构建网络的基本关系。根据基本网络关系提取出两种隐藏关系,定义多名作者共同发表同一篇文章为作者和作者之间的关系,作者是否在某一会议上发表过文章为作者与会议的关系。在此基础上选择90%的连接作为训练集,将剩余的10%的连接作为测试集。
步骤(3)通过基于元路径的随机游走生成序列;
选取作者-论文-会议-论文-作者作为元路径。按转移概率在经步骤(1)、(2)处理得到的网络中进行随机游走产生游走序列。通过walk-length参数来调整产生序列的长度。
步骤(4)训练skip-gram模型;
直接将步骤(3)中通过随机游走产生的序列输入到skip-gram模型进行训练,获取每个节点的向量表示,通过dimensions参数调整向量维度。
步骤(5)节点相似性分析;
经过步骤(3)、(4)两步得到网络节点的向量表示,计算节点间的相似度。因为在步骤(2)中分类别定义了不同类型的连接关系,故只需按关系类型计算其连接概率。
与现有技术相比较,本发明的技术优势主要体现在:
(1)本发明解决了当前多数链路预测算法无法应用在异质网络的情况,可以获取异质网络不同节点所蕴含的丰富信息。
(2)大多预测基于邻域局部信息和结构特征,对网络的聚集系数要求较高,稀疏网络预测效果较差,本发明基于元路径的随机游走,可用于稀疏网络。
(3)现有算法需对每对节点的连接概率都需要单独计算,复杂度较高,对大规模网络不太友好。本发明通过对网络整体学习统一建立节点向量,简化了计算
附图说明
图1发明框架图。
图2位skip-gram模型图。
具体实施方式
以下结合附图和实施例对本发明进行详细说明。
如图1-2所示,本发明采用的技术方案为一种基于异质网络表示学习的链路预测方法,该方法包括如下步骤:
步骤1:处理数据
实验使用dbis(databaseandinformationsystems)数据集。该数据集包含了60447名作者,72902篇文章以及463个出处。从该数据集中提取出三种类型的节点:作者(a),文章(p)和出处(v);以及两种连接关系:作者和论文即发表与被发表的关系(a-p)以及论文和出处即出版与被出版的关系(p-v),以此来构建出实验所需的基本网络。在此基础上,抽离出了两种不能在网络中直接体现的关系:作者和作者即作者之间的合作关系(a-a);作者和出处的关系即作者在此会议/期刊是否发表文章的关系(a-v)。用这两种关系来验证算法的正确率。选择90%的连接作为训练集,将剩余的10%的连接作为测试集。
步骤2:生成随机游走序列
随机游走方法多是在同质网络中的表示学习方法,并不能直接应用到异质网络。比如并不能解决多种类型节点的“word-context”对的问题。本发明借鉴metapath2vec的模型,该模型跟经典的deepwalk模型是类似的,也是通过随机游走的方式保留网络结构,不同的是自由游走的序列是基于元路径。
元路径是定义在网络概要图tg(a,r)上的路径,
与同质网络的随机游走不同,在异质网络中,决定游走下一步的条件概率不能像deepwalk那样,直接在节点vi的所有邻居上做标准化。如果这样做忽略了节点的类型信息。异质网络上的随机游走生成的路径,偏向于高度可见的节点类型(具有优势/主导数量的路径的节点)和集中的节点(即:具有指向一小组节点路径的大部分百分比)。如电影网,电影的数量高于电影种类的数量多个数量级。因而,提出了基于元路径的随机游走,捕获不同类型节点之间的语义和结构相关性。定义一个异质网络g=(v,e,t),v是网络的节点集合,e是边集合,t是类型集合,且存在映射关系φ:v→tv,ψ:e→te,tv和te分别代表相应类型的集合,且|tv|+|te|>2。给定一条元路径
其中
步骤3:训练模型向量化节点
在得到步骤2的序列后就使用模型进行训练学习。选用skip-gram模型对网络进行学习,并将网络节点转换成低维向量。skip-gram是用于自然语言处理的一种常见模型,最早被应用于快速学习词向量表示,其基本思想是利用神经网络通过训练,将文本中的单词转换到低维、稠密的实数向量空间中,通过向量空间中的向量运算来简化文本内容上的处理。例如文本的语义相似度可以通过向量空间上的相似度来衡量,可以用于自然语言处理中的很多工作中,包括同义词寻找、词性分析等,运用此模型对网络进行表示学习。
此模型多数情况下运用在同质网络的学习中,为了使其可以运用在异质网络需要对其参数进行以下修改。给定一个异质网络g=(v,e,t),通过在节点v的邻域上最大化条件概率来表征学习该网络:
其中t∈tv,nt(v)代表类型为t的节点的邻域节点集合,p(ct|v;θ)表示为在给定节点v的情况下,节点ct的条件概率,并将其定义为softmax函数:
其中xv是矩阵x的第v行矩阵,表示顶点v的嵌入向量。为了提升参数更新效率,采用了负采样进行参数迭代更新,给定一个负采样的大小m,参数更新过程如下:
其中
步骤4:计算链路预测概率
在经过上述步骤1、2后,完成对异质信息网络的表示学习,得到各个节点的向量,就可以将计算网络中节点间相似性的问题转化为计算节点对应的向量相似性问题。节点的相似程度越高,节点间产生链接的概率也越高。故通过计算节点向量之间的相似性来量化节点间链路连接的概率。
本方法采用两种方法来计算节点向量间的相似性。一种是选择较为通用的余弦相似性算法来计算网络中节点间的相似度。给定两节点x,y的表征向量vx,vy,其余弦相似度为:
另一种是利用各节点在多维空间上的欧氏距离来表征各节点在潜在网络结构上的相似度。给定两节点x,y,生成维度为d的表征向量vx,vy,其欧氏距离定义为:
步骤5:度量指标
为了验证本发明方法的准确性,使用auc作为主要度量指标。auc可以理解为在测试集中的边的分数值有比随机选择的一个不存在的边的分数值高的概率,也就是说,每次随机从测试集中选取一条边与随机选择的不存在的边进行比较,如果测试集中的边的分数值大于不存在的边的分数值,就加1分;反之加0分;如果两个分数值相等,就加0.5分。独立地比较n次,如果有n'次测试集中的边的分数值大于不存在的边的分数,有n”次两分数值相等,则auc定义为:
显然,如果所有分数都是随机产生的,auc=0.5。因此auc大于0.5的程度衡量了算法在多大程度上比随机选择的方法精确。
同时作为对比,选用了四个常用指标作为对比,各算法相似性指标定义描述如下。
cn指标:对于网络中的节点x,定义其邻居集合为γ(x),则两个节点x和y的相似性就定义为它们共同的邻居数,即
aa指标:优化的cn指标,将不同的权重分配给该公共邻居集合中的不同节点,每个节点的权重等于该节点的度的对数分之一,即
lp指标:该指标通过利用节点x和y之间具有长度为2和3的不同路径的数量的信息,来表征节点之间的相似性,即
rwr指标:重启随机游走算法,是一种网页排序算法的扩展。根据转移概率选择走向下一节点还是返回初始节点,以此来捕获两节点间的多方面关系。qxy表示从节点x出发的粒子最终以多少概率走到节点y即
- 还没有人留言评论。精彩留言会获得点赞!