一种基于数据库乐观锁的并发IP分配方法与流程
本发明创造属于互联网技术领域,尤其是涉及一种基于数据库乐观锁的并发ip分配方法。
背景技术:
ip地址是ip协议提供的一种统一的地址格式,它为互联网上的每一个网络和每一台主机分配一个逻辑地址,以此来屏蔽物理地址的差异。用户在自己的vpc内创建虚拟机,要想具备与vpc内其他虚拟机互相通信的能力需要在虚拟机的网卡中分配ip。用户申请ip地址时需要指定所属的子网。从而从子网中随机或指定分配ip。分配ip时需要保证同一个子网内ip不能重复分配,支持预留ip不会被分配给用户。现有的流程中会将用户的请求进行串行排队(单进程内),每次会计算出子网的网段内的所有的ip地址,随机取10个,在数据库中进行匹配是否已经存在,若存在则继续重复上述步骤,否则则返回一个ip。
但是现有的逻辑在保障分配ip地址的基础上,存在比较多的问题:1、不支持高并发分配ip,同一个进程内只能串行申请ip;2、因为会将子网所有的ip地址都计算出来并且存放在内存中,会占用比较多的内存;3、不支持递增申请,在用户申请多个ip之后释放其中的一个,下次申请时还会继续返回已经被释放的ip,若底层硬件(交换机、虚拟机)配置没有清除掉,则会出现冲突。
技术实现要素:
有鉴于此,本发明创造旨在克服上述现有技术中存在的缺陷,提出一种基于数据库乐观锁的并发ip分配方法。
为达到上述目的,本发明创造的技术方案是这样实现的:
一种基于数据库乐观锁的并发ip分配方法,包括:
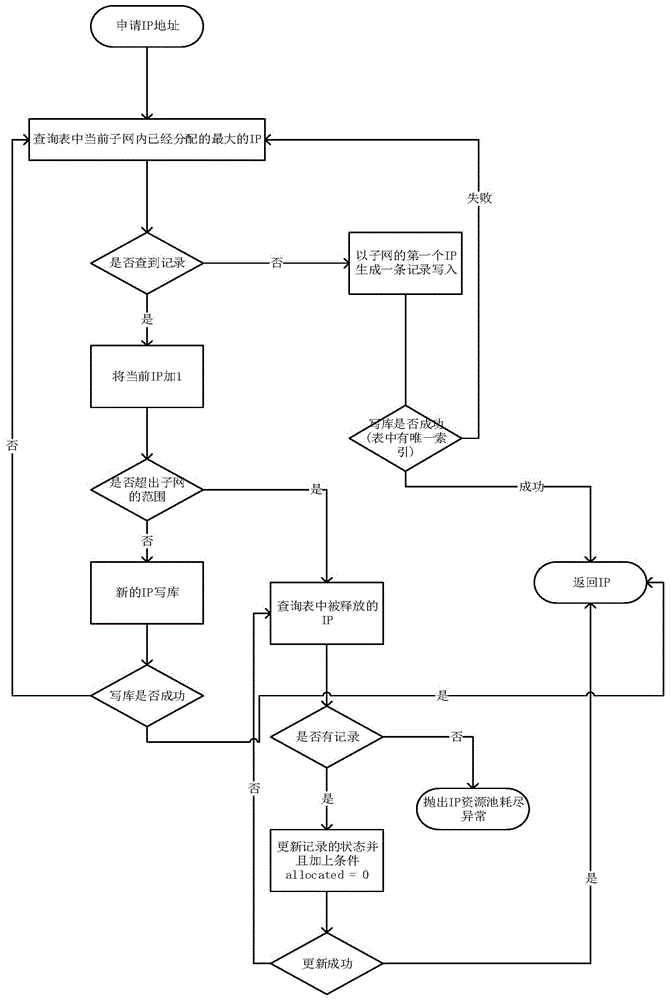
s1、在数据库中建立ipallocations数据表;用于存储每个子网被分配与释放的ip;
s2、申请ip地址,查询ipallocations数据表中当前子网内是否存在已分配的最大ip;
s3、若存在最大ip,则将当前ip加1形成新ip,并判断新ip是否超出子网的范围,若新ip未超范围,则将新ip写入数据库,返回ip;若新ip超范围,则查询ipallocations数据表中是否存在被释放的ip,若ipallocations数据表中存在被释放的ip,则更新被释放的ip,返回ip结束,若不存在被释放的ip,则抛出ip资源池耗尽异常;
s4、若不存在最大ip,则以子网的第一个ip生成一条记录写入数据库,写入成功则返回第一个ip给用户,申请ip流程结束;写入不成功,则重新进行步骤s2。
进一步的,所述ipallocations数据表的结构包括:
id;字段描述为varchar(64),非null,主键;
ip_address;字段描述为varchar(64),非null;
subnet_id;字段描述为varchar(64),非null,subnet_id与ip_address组成唯一索引;
allocated;字段描述为int(2),非null;1代表已经被分配,0代表未被分配;
ip_index;字段描述为bigint(20),非null;用于记录subnet内部ip的索引顺序。
进一步的,所述步骤s2中,查询最大ip的具体方法如下:查询ipallocations数据表中subnet_id=@subnet_idandallocated=1andip_index>0的数据,按照ip_index倒序取最大的记录。
进一步的,所述步骤s3中,新ip写入数据库的具体步骤如下:
s31、从ipallocations数据表subnet_id对应的记录a,将从ipallocations表中查询到数据的ip_address加1,校验新的ip地址是否在记录a的first_ip与last_ip范围之内;
s32、若记录a不在范围之内,则查询ipallocations表中subnet_id=@subnet_idandallocated=0的数据取一条,若查询到数据则执行数据更新,更新数据的allocated状态为1,并且条件加上allocated=0,若执行数据更新成功,则返回ip结束,不成功则抛出ip耗尽异常;
s33、将新生成的ip存储在表ipallocations中,若成功则返回ip结束,否则执行步骤s2。
进一步的,所述步骤s4中,生成记录写入数据库的具体步骤如下:
s41、从ipallocations数据表中查询subnet_id对应的记录进行写入,若数据库ip集合内没有对应的记录,则自动生成一条ip地址对应的数据记录,并去除保留的ip;
s42、将步骤s41中查询结果的first_ip作为结果存储到表ipallocations(allocated=1,ip_index=1,ip_address=@first_ip)中,若数据保存成功,则返回first_ip给用户,申请ip流程结束。
相对于现有技术,本发明创造具有以下优势:
本发明创造支持高并发分配ip,可以更好的满足用户需求,同时通过采用数据库乐观锁与唯一索引,确保了ip的唯一性,同时本方法还有利于节省内存空间,支持连续自增ip申请,可以有效防止配置冲突问题;本发明创造可以满足单线程每秒生成100+记录,多线程情况下支持5000+记录,有利于减少内存的使用,优化程序。
附图说明
构成本发明创造的一部分的附图用来提供对本发明创造的进一步理解,本发明创造的示意性实施例及其说明用于解释本发明创造,并不构成对本发明创造的不当限定。在附图中:
图1为本发明创造实施例所述基于数据库乐观锁的并发ip分配方法流程图;
图2为本发明创造实施例所述的ipallocations数据表结构示意图。
具体实施方式
需要说明的是,在不冲突的情况下,本发明创造中的实施例及实施例中的特征可以相互组合。
在本发明创造的描述中,需要理解的是,术语“中心”、“纵向”、“横向”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明创造和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明创造的限制。此外,术语“第一”、“第二”等仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。由此,限定有“第一”、“第二”等的特征可以明示或者隐含地包括一个或者更多个该特征。在本发明创造的描述中,除非另有说明,“多个”的含义是两个或两个以上。
在本发明创造的描述中,需要说明的是,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以通过具体情况理解上述术语在本发明创造中的具体含义。
下面将参考附图并结合实施例来详细说明本发明创造。
一种基于数据库乐观锁的并发ip分配方法,如图1和图2所示,包括:
s1、在数据库中建立ipallocations数据表;用于存储每个子网被分配与释放的ip;
s2、申请ip地址,查询ipallocations数据表中当前子网内是否存在已分配的最大ip;
s3、若存在最大ip,则将当前ip加1形成新ip,并判断新ip是否超出子网的范围,若新ip未超范围,则将新ip写入数据库,返回ip;若新ip超范围,则查询ipallocations数据表中是否存在被释放的ip,若ipallocations数据表中存在被释放的ip,则更新被释放的ip,返回ip结束,若不存在被释放的ip,则抛出ip资源池耗尽异常;
s4、若不存在最大ip,则以子网的第一个ip生成一条记录写入数据库,写入成功则返回第一个ip给用户,申请ip流程结束;写入不成功,则重新进行步骤s2;具体的,写入成功则表明第一个ip即为申请成功的ip(因为在数据库中加了唯一索引,只有第一次写入才会成功,写入成功则表明之前没有人申请过),申请ip流程结束,返回该ip给用户
所述ipallocations数据表的结构包括:
id;字段描述为varchar(64),非null,主键;
ip_address;字段描述为varchar(64),非null;
subnet_id;字段描述为varchar(64),非null,subnet_id与ip_address组成唯一索引;
allocated;字段描述为int(2),非null;1代表已经被分配,0代表未被分配;
ip_index;字段描述为bigint(20),非null;用于记录subnet内部ip的索引顺序。
所述步骤s2中,查询最大ip的具体方法如下:查询ipallocations数据表中subnet_id=@subnet_idandallocated=1andip_index>0的数据,按照ip_index倒序取最大的记录。
所述步骤s3中,新ip写入数据库的具体步骤如下:
s31、从ipallocations数据表subnet_id对应的记录a,将从ipallocations表中查询到数据的ip_address加1,校验新的ip地址是否在记录a的first_ip与last_ip范围之内;
s32、若记录a不在范围之内,则查询ipallocations表中subnet_id=@subnet_idandallocated=0的数据取一条,若查询到数据则执行数据更新,更新数据的allocated状态为1,并且条件加上allocated=0,若执行数据更新成功,则返回ip结束,不成功则抛出ip耗尽异常;
s33、将新生成的ip存储在表ipallocations中,若成功则返回ip结束,否则执行步骤s2。
所述步骤s4中,生成记录写入数据库的具体步骤如下:
s41、从ipallocations数据表中查询subnet_id对应的记录进行写入,若数据库ip集合内没有对应的记录,则自动生成一条ip地址对应的数据记录,并去除保留的ip;具体的,保留ip指的是一个子网中有一部分是预留的不能分配给用户的ip,例如172.168.0.255/24作为广播地址,是不能分配给用户使用的。
s42、将步骤s41中查询结果的first_ip作为结果存储到表ipallocations(allocated=1,ip_index=1,ip_address=@first_ip)中,若数据保存成功,则返回first_ip给用户,申请ip流程结束;具体的,保存的是新ip,这个ip是子网的第一ip,例如172.168.0.0/24这个网段中的第一个ip(即first_ip)为172.168.0.1。
具体的,申请ip步骤如下:
1.1、查询ipallocations表中subnet_id=@subnet_idandallocated=1andip_index>0的数据,按照ip_index倒序取最大的记录,若没有查询到记录,则执行步骤1.2,若查询到数据则执行步骤1.3
1.2、从ipallocations表中查询subnet_id对应的记录,若没有,则自动生成一条对应的记录,去除保留ip。
1.2.1、将1.2中的查询结果的first_ip作为结果存储到表ipallocations(allocated=1,ip_index=1,ip_address=@first_ip)中。
1.2.2、数据保存成功,则返回ip结束,否则执行步骤1.2
1.3、从ipallocations表中查询subnet_id对应的记录a,将从ipallocations表中查询到数据的ip_address加1,校验新的ip地址是否在记录a的first_ip与last_ip范围之内,若不在范围之内,则执行1.5,否则执行步骤1.4
1.4、将新生成的ip存储在表ipallocations中,若成功则返回ip结束,否则执行步骤1.2
1.5、查询ipallocations表中subnet_id=@subnet_idandallocated=0的数据取一条,若查询到数据则执行1.6步骤,否则抛出ip耗尽异常
1.6、更新数据的allocated状态为1,并且条件加上allocated=0,若执行成功,则返回ip结束,否则继续执行步骤1
本发明创造支持高并发分配ip,可以更好的满足用户需求,同时通过采用数据库乐观锁与唯一索引,确保了ip的唯一性,同时本方法还有利于节省内存空间,支持连续自增ip申请,可以有效防止配置冲突问题;本发明创造可以满足单线程每秒生成100+记录,多线程情况下支持5000+记录,有利于减少内存的使用,优化程序。
以上所述仅为本发明创造的较佳实施例而已,并不用以限制本发明创造,凡在本发明创造的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明创造的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!