一种基于多指标的知识图谱生成方法与流程
本发明涉及计算机文本处理技术领域,特别是一种知识图谱的生成方法。
背景技术:
知识图谱是通用的知识可视化和存储工具。由于知识的复杂性和多样性,制作知识图谱需要耗费大量的人力。自动生成的知识图谱一般只针对存在大量数据的领域,针对数据较少特定的领域效果较差。因此需要一种方法,在少量人工参与或无人工参与的情况下,提高特定领域知识图谱质量的方法。
技术实现要素:
本发明针对上述问题,提供一种基于多指标的知识图谱生成方法,具体包括以下步骤:
s001,定义数据库数据结构,定义的数据结构包括实体、关系、实体属性和关系属性四种类型;所述实体最少包含名称、别称、文档id三个属性;所述关系为两个实体之间的有向链接,链接从起始实体出发,指向结束实体,并最少包含名称属性;所述实体属性对应到具体的实体,为该对应实体中的键值对信息;关系属性对应到具体的关系,为该对应关系中的键值对信息;
s002,输入信息;所述信息为实体、关系、实体属性和关系属性中的一种或多种;
s003,对输入的信息分别逐一进行匹配,匹配成功直接执行步骤s007,匹配失败执行步骤s004;
s004,信息匹配:根据匹配失败信息的数据结构类型,相应生成处理方案;
s005,以多指标参数计算各个处理方案的置信度;
s006,根据所述置信度选择该匹配失败信息的处理方案;
s007,以匹配成功的输入信息或者选择的处理方案更新所述数据库的数据,即更新知识图谱,后续再次进行信息输入更新知识图谱时从步骤s002开始。
作为本发明的进一步说明,所述步骤s002中输入为实体、关系、实体属性和关系属性信息由人工标注或者数据模型预测得到。
更进一步地,所述步骤s002到步骤s003之间还包括信息过滤步骤,通过输入信息的声量参数和设定声量阈值进行过滤,将声量小于所述声量阈值的输入信息过滤掉。
更进一步地,所述步骤s003的信息匹配中,根据所述输入信息类型相应生成的处理方案不同,后续步骤s005计算相应处理方案置信度的方法也不相同。
更进一步地,所述输入信息类型为实体且信息匹配失败时,相应生成的处理方案包括融合到某个数据库实体中、融合到某个新实体中、新增实体和废弃四种;所述融合到某个数据库实体中和融合到某个新实体中两种处理方案的置信度由编辑距离、文本句向量和声量三个指标计算,计算公式为:置信度=(声量指标+编辑距离指标+句向量指标)/3。
更进一步地,所述输入信息类型为关系且信息匹配失败时,相应生成的处理方案包括新增关系和废弃两种;所述新增关系处理方式的置信度由起始实体和结束实体的共现声量和关系声量两个指标计算,计算公式为:置信度=(共现声量指标+声量指标)/2。
更进一步地,所述输入信息类型为实体属性且信息匹配失败时,相应生成的处理方案包括修正或新增属性和废弃两种;所述修正或新增属性处理方式的置信度由实体属性的编辑距离、声量两个指标计算,计算公式为:置信度=(编辑距离指标+声量指标)/2。
更进一步地,所述输入信息类型为关系属性且信息匹配失败时,相应生成的处理方案包括修正或新增属性和废弃两种;所述修正或新增属性处理方式的置信度由实体属性的编辑距离、声量两个指标计算,计算公式为:置信度=(编辑距离指标+声量指标)/2。
更进一步地,所述步骤s006中选择处理方案的方式包括人工选择和机器自动执行选择。
更进一步地,所述机器自动执行选择包括输入一个置信度阈值,所有类别的处理方案中,置信度最大的方案大于所述置信度阈值时,自动执行置信度最大的处理方案,否则选择废弃。
本发明的有益效果:
本发明的基于多指标的知识图谱生成方法针对数据较少特定的领域具有良好的效果,在少量人工参与或无人工参与的情况下,提高特定领域知识图谱质量的方法,输入信息的识别和更新知识图谱的准确性高,能提高知识自动生成知识图谱的准确率,当需要人工介入时也可以降低人工工作量。
附图说明
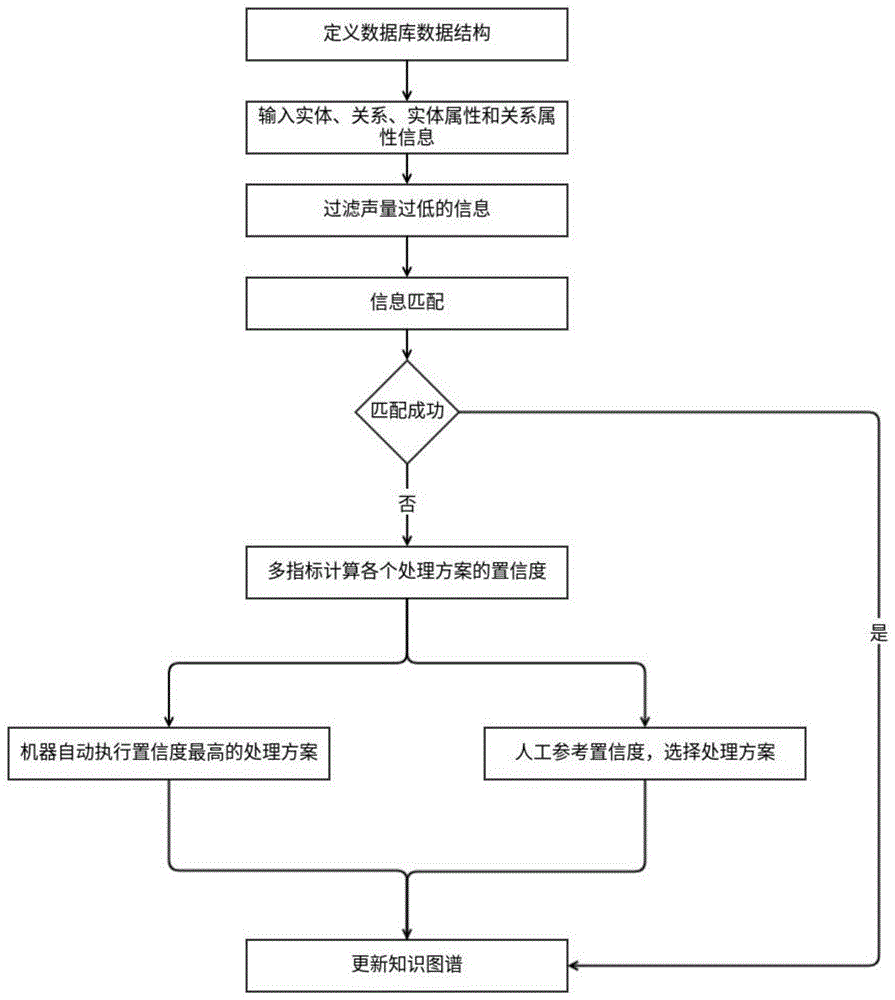
图1为本发明方法的整体流程图;
图2为本发明知识图谱数据库结构示例;
图3为本发明知识图谱实体生成方法流程图;
图4为本发明知识图谱关系生成方法流程图;
图5为本发明知识图谱实体属性生成方法流程图;
图6为本发明知识图谱关系属性生成方法流程图。
具体实施方式
下面结合附图对本发明的具体实施例详细的说明,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
如图1所示的一种基于多指标的知识图谱生成方法的整体流程图,包括以下步骤:
s001,定义数据库数据结构。数据库可以是空数据库,也可以是非空数据库。若数据库非空,其中的每个实体应该最少包含名称、别称、文档id三个属性。名称为最能代表该实体的名字,别称为实体除名称外的其他称呼,文档id为出现过该实体的文档的id列表。关系是指两个实体之间的有向链接,链接从起始实体出发,指向结束实体。关系最少包含名称属性。附图2为此数据结构的一个例子。
s002,输入实体、关系、实体属性和关系属性信息。
其中,关系必须对应到具体的起始实体和具体的结束实体,实体属性必须对应到具体的实体,关系属性必须对应到具体的关系。
其中,这些信息可以来源于人工整理,亦可以来源于算法识别结果。
其中,输入信息应该包含信息所在的文档的id列表。
以表1为本实施例输入实体、关系、实体属性和关系属性信息的具体实例。
表1输入样例:
s003,过滤声量过低的信息。所述声量为实体、关系、实体属性或关系属性在原始文档中出现的次数。分别输入实体、关系、实体属性和关系属性的声量阈值,将声量小于声量阈值的输入信息过滤掉,不做任何处理。
s004,信息匹配和处理方案生成流程,包含实体、关系、实体属性和关系属性四种匹配处理流程,四种匹配处理流程的流程图分别对应于附图3-6所示。具体地:
实体匹配处理流程包括实体匹配和实体处理方案生成。
实体匹配:对所有输入实体逐一进行处理。首先,确认数据库是否存在该实体。具体方法是搜索数据库,如果数据库中有且只有一个实体的名称或别称等于输入实体,则匹配成功,表明该数据库中存在该实体,否则数据库不存在该实体,输入实体为新实体。
针对表1的输入和附图2中的数据库,实体“小明”匹配成功,实体“明明”没有匹配成功。
其中,若输入实体匹配成功,则将输入实体的文档id加入到数据库对应实体的文档id中。
其中,若输入实体匹配失败,则输入实体为新实体,进行下一步操作。
实体处理方案生成:对于新实体,有4类处理方案,分别为:融合到某个数据库实体中、融合到某个新实体中、新增实体、废弃。前两类方案可能会包含多于一种处理方案。不同处理方案需要分别计算。
其中,“融合到某个数据库实体中”,此类方案需要遍历所有数据库实体,计算融合到其中的置信度。
该置信度指标由三个指标的平均值组成
置信度=(声量指标+编辑距离指标+句向量指标)/3(1)
公式(1)中,声量指标、编辑距离指标、句向量指标通过下列方式计算:
声量指标=输入实体声量/文档总数(2)
公式(2)中,文档总数为此次信息输入涉及到的文档总数。
公式(3)中,分别取数据库实体的名称和别称计算,取最大值作为编辑距离指标
句向量指标=余弦相似性(输入实体所在文本句向量,数据库实体所在文本句向量)(4)
公式(4)中,通过文本id可以找到实体所在的文本,将这些文本合并,再计算句向量,即可得到公式(4)的结果。
其中,“融合到某个新实体中”,此类方案需要遍历所有已知的新实体,计算融合到其中的置信度。计算置信度的方法与“融合到某个数据库实体中”类方法一致。
其中,“新增实体”,此类方案中只包含一种处理方案,为在数据库中新增一个以输入实体名称为名称的实体,该方案的置信度为1-(“融合到某个数据库实体中”类方案中置信度的最大值)
其中,“废弃”,此类方法只包含一种处理方案,为放弃该输入实体,该方案不会输出置信度。
关系匹配处理流程包括关系匹配和关系处理方案生成。
关系匹配:对所有输入关系逐一进行处理,首先,确认数据库中是否存在该关系,若输入关系的起始实体和结束实体均匹配成功,同时数据库中起始实体和结束实体之间存在该关系,表明该数据库中存在该关系,否则数据库不存在该关系,输入关系为新关系。
针对表1的输入和附图2中的数据库,小明到小红的关系“兄妹”匹配成功,明明到小兰的关系“朋友”没有匹配成功。
其中,若输入关系匹配失败,则输入关系为新关系,进行下一步操作。
关系处理方案生成:对于新关系,有2类处理方案,分别为新增关系、废弃。
其中,“新增关系”,此类方案的置信度指标由两个指标平均值组成:
置信度=(共现声量指标+声量指标)/2(5)
公式(5)中,共现声量指标通过下列方式计算:
声量指标通过下列方式计算
其中,“废弃”,此类方法只包含一种处理方案,为放弃该输入实体,该方案不会输出置信度。
实体属性匹配处理流程包括实体属性匹配和实体属性处理方案生成。
实体属性匹配:对所有输入实体属性逐一进行处理,首先确认数据库是否存在该实体属性,若输入实体属性对应实体匹配成功,且数据库中该实体存在此属性,则匹配成功,否则匹配失败。
其中,属性由两部分组成的键值对,分别为属性键和值。
针对表1的输入和图2中的数据库,实体属性“身高:170cm”匹配失败。
其中,若匹配失败,则该输入实体属性为新实体属性,进行下一步操作。
实体属性处理方案生成:对弈新实体属性,有两类处理方案,分别为修正或新增属性和废弃。
其中,“修正或新增属性”,此类方案的置信度指标由两个指标平均值组成:
置信度=(编辑距离指标+声量指标)/2(8)
公式(8)中,编辑距离指标通过下列方式计算:
公式(9)中,找到数据库中存在同一属性键的实体,分别进行计算,取最大值作为编辑距离指标。
声量指标通过下列方式计算
其中,“废弃”,此类方法只包含一种处理方案,为放弃该输入实体属性,该方案不会输出置信度。
关系属性匹配处理流程包括关系属性匹配和关系属性处理方案生成。
关系属性匹配:对所有输入关系属性逐一进行处理,首先确认数据库是否存在该关系属性,若输入关系属性对应关系匹配成功,且数据库中该关系存在此属性,则匹配成功,否则匹配失败。
针对表1的输入和图2中的数据库,实体属性“亲密度:低”匹配失败。
其中,若匹配失败,则该输入关系属性为新关系属性,进行下一步操作。
关系属性处理方案生成:对于新关系属性,有两类处理方案,分别为修正或新增属性和废弃。
其中,“修正或新增属性”,此类方案的置信度指标由两个指标平均值组成:
置信度=(编辑距离指标+声量指标)/2(8)
公式(8)中,编辑距离指标通过下列方式计算:
公式(9)中,找到数据库中存在同一属性键的关系,分别进行计算,取最大值作为编辑距离指标。
声量指标通过下列方式计算
其中,“废弃”,此类方法只有一种处理方案,为放弃该输入关系属性,该方案不会输出置信度。
s005,处理方案选择,包括人工选择和机器自动执行选择两种方式。若选择人工处理,根据方案的置信度和个人经验对各个输入的方案进行选择。若选择机器自动执行置信度最高的方案,则输入一个置信度阈值,若所有类别的处理方案中,置信度最大的方案大于置信度阈值时,自动执行置信度最大的处理方案,否则选择废弃。
其中,必须按照实体、关系、实体属性、关系属性的顺序进行选择。
其中,进行处理方案选择的过程中,当关系对应的起始实体或结束实体处理方案被选择到融合到某个实体时,关系对应的起始实体或结束实体随之改变。当实体属性对应的实体被选择到融合到某个实体时,实体属性对应的实体随之改变。当关系属性对应的关系被选择到融合到某个关系时,关系属性对应的关系随之改变。
s006,知识图谱更新,根据处理方案修改知识图谱。当输入实体被选择到融合到某个实体方案时,在数据库实体的别称属性中加入输入实体名称、在文档id属性中加入输入实体的文档id。当输入实体被选择到新增实体方案时,在数据库新建实体被输入实体信息。当输入关系被选择到新建关系方案时,在数据库新建关系。当输入实体属性被选择到修改目前属性方案时,在数据库对应实体中修改或新建该属性。当输入关系属性被选择到修改目前属性方案时,在数据库对应关系中修改或新建该属性。
以上仅就本发明较佳的实施例作了说明,但不能理解为是对权利要求的限制。本发明不仅局限于以上实施例,其具体结构允许有变化,总之,凡在本发明独立权利要求的保护范围内所作的各种变化均在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!