一种湿垃圾中垃圾袋目标检测方法及检测系统与流程
本发明涉及一种属于计算机视觉技术领域的图像目标检测方法,具体涉及一种湿垃圾中垃圾袋目标检测方法。
背景技术:
计算机视觉是一门研究如何使机器“看”的科学,更进一步的说,就是指用摄影机和电脑代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图形处理,使电脑处理成为更适合人眼观察或传送给仪器检测的图像。作为一个科学学科,计算机视觉研究相关的理论和技术,试图建立能够从图像或者多维数据中获取‘信息’的人工智能系统。
垃圾分类是对垃圾收集处置传统方式的改革,是对垃圾进行有效处置的一种科学管理方法。人们面对日益增长的垃圾产量和环境状况恶化的局面,如何通过垃圾分类管理,最大限度地实现垃圾资源利用,减少垃圾处置的数量,改善生存环境状态,是当前世界各国共同关注的迫切问题。垃圾分类的好处是显而易见的,垃圾分类后被送到工厂而不是填埋场,既省下了土地,又避免了填埋或焚烧所产生的污染,还可以变废为宝。
湿垃圾是居民日常生活及食品加工、饮食服务、单位供餐等活动中产生的垃圾,包括丢弃不用的菜叶、剩菜、剩饭、果皮、蛋壳、茶渣、骨头、动物内脏、鱼鳞、树叶、杂草等,其主要来源为家庭厨房、餐厅、饭店、食堂、市场及其他与食品加工有关的行业。有机垃圾具有易腐烂、热值低、有机质含量丰富等特点,常规的填埋和焚烧难以妥善处理,所以综合利用的途径有:制作有机肥料、燃料油、酒精、活性炭、九二〇(赤霉菌素)、糠醛、菲汀、角蛋白、甲壳质、鱼鳞胶、化学浆糊等。
垃圾袋给人们的生活带来了方便,但一时的方便却带来长久的危害。垃圾袋回收价值较低,在使用过程中除了散落在城市街道、旅游区、水体中、公路和铁路两侧造成视觉污染外,还存在着潜在的危害。塑料结构稳定,不易被天然微生物降解,在自然环境中长期不分离。这就意味着废塑料垃圾如不加以回收,将在环境中变成污染物长期存在并不断累积,会对环境造成极大危害。据统计,全球一年使用2.6亿吨塑料,其中1.7亿吨属于一次性使用。
目前,垃圾分类与回收处理工作面临着许多的问题和挑战。其中最重要的一点就是垃圾产生数量巨大,而且现有的地区垃圾分类收集、分类运输、分类处理设施不够完备甚至没有,仅靠大量的拾荒人员在垃圾里翻找,但这样的翻找零星、随机、粗放。鲜有地方实行工厂化的人工集中分拣和无害化处理。所以,有限的人工处理能力远远匹配不了每日剧增的垃圾产量。同时,湿垃圾作为垃圾类别中一个大类,同样面临着严峻的挑战。湿垃圾的利用价值较高,但是实际情况中湿垃圾里总会混杂一些其他垃圾导致增加分类难度和工作量,其中最常见的就是垃圾袋。所以,如何代替主要以人工方式为主,效率不高、自动化程度低的现状,是我们一直关注的问题。
技术实现要素:
本发明提供一种湿垃圾中垃圾袋目标检测方法,代替人工识别湿垃圾中垃圾袋的方式,提高效率,实现垃圾识别自动化。
为实现上述目的,本发明提供一种湿垃圾中垃圾袋目标检测方法,其特点是,该方法包含:
s1、采集含有垃圾袋的湿垃圾图像形成湿垃圾图像库;
s2、湿垃圾图像标注垃圾袋的位置和类别信息,并分为训练集、验证集和测试集;
s3、搭建深度学习神经网络,将湿垃圾图像的训练集输入深度学习神经网络中进行训练;
s4、根据深度学习神经网络输出训练输出的结果,调整训练网络模型参数优化网络模型,直到输出的结果达到预期的阈值;
s5、将测试集中的湿垃圾图像输入训练完成的深度学习神经网络进行测试,若场景使用里深度学习神经网络模型的正确率和漏检率符合场景使用的阈值范围,则将训练好的深度学习神经网络本地化保存。
上述s2包含:
s2.1、湿垃圾图像库中的湿垃圾图像重命名和序列化;
s2.2、对湿垃圾图像中的垃圾袋图像进行标注;
s2.3、将标注完成的湿垃圾图像库的标注数据统一储存;
s2.4、将湿垃圾图像库及其标注数据拆分为训练集、验证集和测试集,生成对应的训练集文件夹、验证集文件夹和测试集文件夹中等待训练。
上述训练集、验证集和测试集的拆分比例为:8:1:1。
上述s3包含:
s3.1、搭建深度学习神经网络模型;
s3.2、设置深度学习神经网络模型的训练参数;
s3.3、执行深度学习神经网络模型训练脚本。
上述s4中,深度学习神经网络输出的损失率训练采用损失计算函数,损失计算函数基于交叉熵计算公式改进方法,交叉熵计算公式如式(1):
式(1)中,y表示图片标注时label属性,正类为1,表示有垃圾袋,负类为0,表示无垃圾袋;p表示样本预测为正的概率;
式(1)进一步泛化为式(2):
式(2)中,pt表示式(1)的泛化,当y=1时,pt=p,当y为其他值时,pt=1-p;
式(2)的交叉熵损失公式如式(3):
ce(p,y)=ce(pt)=-log(pt)(3)
式(3)加上一用来平衡类别不均的参数权重参数αt∈[0,1],如式(4):
ce(pt)=-αtlog(pt)(4)
损失计算函数就是ce(pt)的基础上再加上一个权重(1-pt)γ,如式(5):
fl(pt)=-αt(1-pt)γlog(pt)(5)
式(5)中,γ≥0是可调节的聚焦参数。
上述at取值0.25,γ取值2。
上述s5中,若场景使用里深度学习神经网络模型的正确率和漏检率不符合场景使用的阈值范围,则跳转到s3重新训练深度学习神经网络。
上述场景使用的阈值范围为:正确率大于85%,漏检率小于15%。
当场景使用里深度学习神经网络模型的正确率和漏检率不符合场景使用的阈值范围时,判断损失率是否大于0.1且一直没有下降的趋势,若是则跳转到s3重新训练深度学习神经网络,若否则跳转到s4调整模型以提升模型的能力。
一种适用于上述湿垃圾中垃圾袋目标检测方法的湿垃圾中垃圾袋目标检测系统,该系统包含:
图像采集设备,采集含有垃圾袋的湿垃圾图像;
湿垃圾图像库,其通信连接图像采集设备,存储采集的湿垃圾图像,并对湿垃圾图像标注和拆分为训练集、验证集和测试集;
深度学习神经网络,其通信连接湿垃圾图像库,深度学习神经网络接收湿垃圾图像库的湿垃圾图像及其标注数据进行训练,根据训练输出进行优化,完成优化后本地化保存;
垃圾袋目标检测模块,其通过图像采集设备采集检测目标,经过训练的深度学习神经网络对检测目标进行垃圾袋检测。
本发明湿垃圾中垃圾袋目标检测方法及检测系统和现有技术相比,其优点在于,本发明采用retinanet深度学习网络进行湿垃圾图像中的垃圾袋的检测识别,实现在湿垃圾量巨大的情况下,自动化识别垃圾袋,替代人工方式识别垃圾袋,提高识别效率,提高垃圾再利用率。
附图说明
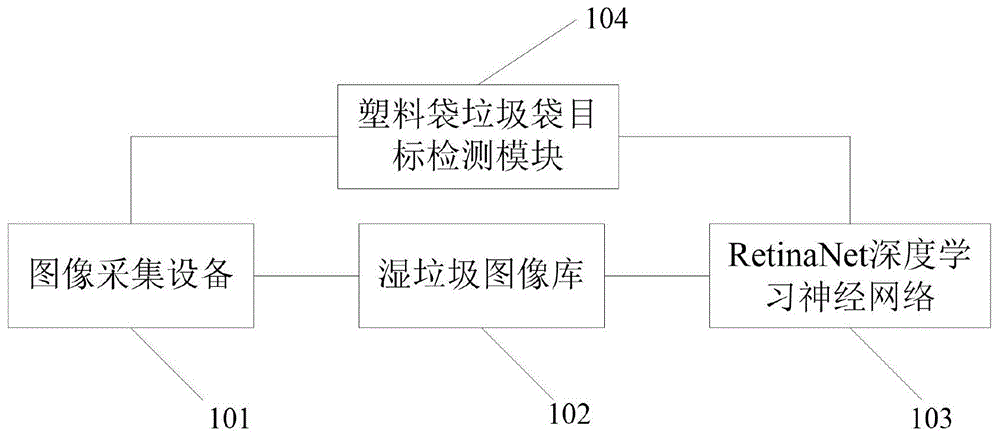
图1为本发明一种基于retinanet深度学习算法的湿垃圾中垃圾袋目标检测系统的实施例的系统图;
图2为一种基于retinanet深度学习算法的湿垃圾中垃圾袋目标检测方法的流程图;
图3为本发明中retinanet的网络框架图;
图4为本发明中resnet网络中residual-block的原理图;
图5为本发明中不同深度resnet的具体结构图;
图6为本发明中resnet网络最浅层conv1的结构图;
图7为本发明中resnet50网络layer1的结构图;
图8为本发明中resnet50网络layer2的结构图;
图9为本发明中fpn网络中多层特征信息局部细节结构图;
图10为本发明中resnet和fpn结合部分网络结构图;
图11为本发明中fcn网络中子网络框架图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,在本文中,诸如“第一”、“第二”、“第三”等关系术语如果存在仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。应该理解这样使用的术语在适当情况下可以互换,以便这里描述的本发明的实施例,例如能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”、“包含”、“具有”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者终端设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者终端设备所固有的要素。在没有更多限制的情况下,由语句“包括……”或“包含……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者终端设备中还存在另外的要素。此外,在本文中,“大于”、“小于”、“超过”等理解为不包括本数;“以上”、“以下”、“以内”等理解为包括本数。
如图1所示,为一种基于retinanet深度学习算法的湿垃圾中垃圾袋目标检测系统的实施例,该系统包含:图像采集设备101、通信连接图像采集设备101的湿垃圾图像库102、通信连接湿垃圾图像库102的retinanet深度学习神经网络103、以及连接图像采集设备101和retinanet深度学习神经网络103的垃圾袋目标检测模块104。
图像采集设备101用于采集含有垃圾袋的湿垃圾图像,包含图片采集模块和图形处理模块,图像采集模块包含且不限于网络图片采集模块、摄像设备;图形处理模块对采集的湿垃圾图像进行数据增强,增加训练数据量和模型泛化能力。
湿垃圾图像库102用于存储采集的湿垃圾图像,并对湿垃圾图像重命名和序列化,并进行标注,将湿垃圾图像库及其标注数据按拆分为训练集、验证集和测试集,并且生成对应的类别映射文件(即训练集文件夹、验证集文件夹和测试集文件夹),将拆分的湿垃圾图像库及其标注数据放入对相应的训练集文件夹、验证集文件夹和测试集文件夹中等待用于retinanet深度学习神经网络103训练。
retinanet深度学习神经网络103接收湿垃圾图像库102的湿垃圾图像及其标注数据进行训练,并根据数据进行优化。完成优化的数据本地化保存。
垃圾袋目标检测模块104其通过图像采集设备采集检测目标,经过训练的深度学习神经网络对检测目标进行垃圾袋检测。
如图2所示,为本发明一种基于retinanet深度学习算法的湿垃圾中垃圾袋目标检测方法的一种实施例,具体包括以下步骤:
s1、采集含有垃圾袋的湿垃圾图像,其中湿垃圾图像采集数量设定为大于等于两万张,采集的湿垃圾图像进行存储并形成湿垃圾图像库。
优选的,采集目标图像的方式包含:
1)在网络上通过爬虫获取;2)通过相机设备拍摄图像;3)寻找别人已经整理好的图像库进行使用。
2)然后对收集到的图像做数据增强,这样做有2个好处:1)增加训练的数据量,提高模型的泛化能力;2)增加噪声数据,提升模型的鲁棒性。
s2、将湿垃圾图像库中每张湿垃圾图像标注垃圾袋的位置信息和类别信息,并按照8:1:1的比例将湿垃圾图像分为训练集、验证集和测试集。其中训练集、验证集和测试集可以根据实际操作调整。
其中,湿垃圾图像标注的数据集格式包括以下种类:pascalvoc、mscoco、openimagesdataset(oid)和kitti,可根据实际操作中使用的格式种类增加或减少标注信息,在实际运用中,每种格式的基本信息都包括有位置信息和类别信息。
s2.1、将湿垃圾图像库中存储的湿垃圾图像进行重命名和序列化。实际操作中重命名和序列化可以根据具体要求编写对应的脚本批量完成。
进一步的,重命名和序列化可采用以下方式:样本英文名称(小驼峰命名法)+自增标记数字(数字根据图片数量设置为6位及以上的数字,例如000000至999999:),例如:plasticbag000001。
s2.2、对湿垃圾图像进行标注。
进一步的,标注工具可以选择labelimg,将湿垃圾图像库的湿垃圾图像文件导入labelimg软件中,对每一张湿垃圾图像上出现的一个或者若干个目标物体全部进行标注并添加类名,这里目标物体为垃圾袋。
s2.3、将标注完成的湿垃圾图像库的标注(label)数据统一储存。label数据根据实际操作中训练模型的需求,可以选择为xml或者txt格式的文件保存,生成的xml文件遵循pascalvoc格式。
s2.4、将湿垃圾图像库及其标注数据按照8:1:1的比例拆分为训练集、验证集和测试集,并且生成对应的类别映射文件,放入对相应的训练集文件夹、验证集文件夹和测试集文件夹中等待训练。生成的类别映射文件可以通过编写脚本批量完成。
s3、搭建retinanet深度学习神经网络,将图像数据集(例如训练集)输入搭建好的retinanet网络中进行训练。
s3.1、搭建retinanet模型。retinanet模型有多种平台的版本,包括keras(tensorflow)、caffe和pytorch等深度学习平台。在这里使用keras-retinanet版本来训练。retinanet模型的结构可以归纳为resnet(backbone)+fpn+fcn,并且结合focalloss损失计算函数的组合应用,在单阶段目标检测网络中成功使用,并最终能以更快的速率实现与双阶段目标检测网络近似或更优的效果。
如图3所示,为本发明的retinanet的网络框架图,模型结构大概可以分为4个部分:a)resnet作为backbone;b)采用特征金字塔网络(fpn、featurepyramidnetwork)进行不同scale的采样;c)采用全卷积神经网络(fcn、fullyconvolutionalnets)对于每个尺度(scalelevel),都有一个分类子网络(classsubnet)和预测框子网络(boxsubnet)。将最终预测的锚框(anchor)进行合并(merge),使用非极大值抑制算法(nms)进行筛选得到最后的结果。
如图4所示,resnet使用恒等映射(identitymapping)在不额外增加参数的情况下,可以使收敛速度更快在网络中某一位置添加一条shortcutconnection,将前层的特征直接传递过来,这个新连接称为identitymapping。
如图5和图6所示,本实施例中,resnet共有5种不同深度的结构,深度分别为18、34、50、101、152(各种网络的深度指的是“需要通过训练更新参数”的层数,如卷积层,全连接层等)。是给出每种resnet的具体结构:其中,根据block类型,可以将这五种resnet分为两类:(1)一种基于basicblock,浅层网络resnet18,34都由basicblock搭成;(2)另一种基于bottleneck,深层网络resnet50,101,152乃至更深的网络,都由bottleneck搭成。block相当于积木,每个layer都由若干block搭建而成,再由layer组成整个网络。每种resnet都是4个layer(不算一开始的7×7卷积层和3×3maxpooling层),conv2_x对应layer1,conv3_x对应layer2,conv4_x对应layer3,conv5_x对应layer4。方框中的“×2”、“×3”等指的是该layer由几个相同的结构组成。
首先说明,为了便于理解,本发明所有网络图只包含卷积层和pooling层,而bn层和relu层等均未画出。然后说明图中部分符号的含义:
(1)输入输出用椭圆形表示,中间是输入输出的尺寸:channel×height×width
(2)直角矩形框指的是卷积层或pooling层,如“3×3,64,stride=2,padding=3”指该卷积层kernelsize为3×3,输出channel数为64,步长为2,padding为3。矩形框代表的层种类在方框右侧标注,如“conv1”。
如图6所示,和basicblock不同的一点是,每一个bottleneck都会在输入和输出之间加上一个卷积层,只不过在layer1中还没有downsample,这点和basicblock是相同的。至于一定要加上卷积层的原因,就在于bottleneck的conv3会将输入的通道数扩展成原来的4倍,导致输入一定和输出尺寸不同。layer1的3个block结构完全相同,所以图中以“×3”代替。
如图7所示,尺寸为256×56×56的输入进入layer2的第1个block后,首先要通过conv1将通道数降下来,之后conv2负责将尺寸降低(stride=2,图8第1个虚线框中标注)。到输出处,由于尺寸发生变化,需要将输入downsample,同样是通过stride=2的1×1卷积层实现。
之后的3个block(layer2有4个block)就不需要进行downsample了(无论是residual还是输入),如图8第2个虚线框中红圈标注,stride均为1。因为这3个block结构均相同,所以图8中用“×3”表示。layer3和layer4结构和layer2相同,无非就是通道数变多,输出尺寸变小,所以不再赘述。
使用特征金字塔(fpn)作为retinanet的主干网。fpn给标准的卷积神经网络增加一个自顶向下的路径和侧向连接,来从图片的单一分辨率构建一个丰富的、多尺度的特征金字塔。金字塔的每一层以不同尺寸检测对象,fpn改善了全卷积网络的多尺寸预测。
fpn由自下而上和自上而下路径组成。其中自下而上的路径是用于特征提取的常用卷积网络。空间分辨率自下而上地下降。当检测到更高层的结构,每层的语义值增加。通过结合多层的特征信息,网络能够更好的处理小的目标;同时融合了深层语义信息和浅层的图片细节(局部特征,目标定位等)信息,网络的准确性得到进一步提升,具体结构如图9所示。
图10详细说明了自下而上和自上而下的路径。其中p2、p3、p4和p5是用于目标检测的特征图金字塔。fpn不单纯是目标检测器,还是一个目标检测器和协同工作的特征检测器,分别传递到各个特征图(p2到p5)来完成目标检测。
class-subnet分类子网络预测每个anchor上k个类别的概率。子网络是附加在fpn的每一层的一个小的fcn;参数共享,网络设计简洁(见图11):对于给定的金字塔层级输出的c个通道的featuremap,子网络使用4个3×3的卷积层,每层的通道数任然是c,接着是一个relu激活层;然后跟一个通道数位ka(k是类别数,a是anchor数)的3×3的卷积层;最后使用sigmoid激活函数。与rpn相比,分类子网络更深,并且只使用了3×3卷积;没有和边框回归子网络共享参数。
与分类子网络并行的box-subnet,在fpn的每一层附加一个小的fcn用于边框回归。边框回归子网络和分类子网络设计是一样的(见图11),唯一不同最后一层通道数是4a个。边框回归的方法与rcnn的边框回归一样。不同于大多数设计,使用类别无关的边框归回,参数更少,同样有效。分类子网络和边框回归子网络共享结构,参数独立。
s3.2、设置retinanet模型的训练参数。模型在训练之前需要对一些参数进行设置和初始化,比如:epochs训练轮数,默认值50;batch-size一批训练个数,默认值1;steps一轮训练步数,默认10000,需按照自己数据集size大小计算,steps=size/batch-size;包括backbone主干网络的选择。
s3.3、执行retinanet模型训练脚本。将一系列的参数设置完成后,即可运行训练脚本等待训练结果。
s4、根据训练输出结果的损失率(loss)、召回率(recall)、准确率(accuracy)参数,调整训练网络模型参数,优化网络模型,直到输出的结果达到预期的阈值。
进一步的,调优方法包含如下:
a、随机采集样本,避免学习偏差。(作用:这样能够避免模型训练时候的过拟合现象。方法:每次训练时,送入训练的图片要确保是打乱随机的。)
b、样本的归一化。(作用:这样能够使模型更快的收敛,尤其是梯度下降法,方便初始化解,同时学习率的设置也更方便合理,加速收敛和迭代的过程。方法:min-max标准化(min-maxnormalization)、z-score0均值标准化(zero-meannormalization)、非线性归一化)
c、batchsize(一次训练所选取的样本数)的选择。(作用:batch的上限受制于gpu的显存,小的batch效率太低训练慢;然而batchsize并非越大越好,不同大小的batch表示每一步模型需要拟合的样本数,最终导致不同的拟合结果,所以size会影响模型的训练结果;同时给出了通过调节不同的batchsize可以看到有时候模型会卡在鞍点,有时则能快速收敛。方法:尝试放大2倍或者缩小0.5倍来对比训练的效果,看看是否会有更优的训练结果。)
d、学习速率的调整。(作用:通常不同的学习速率会很大程度上影响模型的收敛结果和效率;往往模型刚开始训练的时候学习率需要稍微大一些,帮助模型快速收敛,而在迭代了一定的次数之后,梯度也会慢慢降低,搜索极小值的过程需要学习率较低。方法:指数衰减学习率,将学习率设定为与训练的迭代次数相关,迭代次数越多,学习率衰减的越多。)
进一步的,输出结果的预期阈值为:准确率(accuracy)大于等于87%;损失率(loss)小于等于0.05;召回率(recall)大于等于80%。
根据本发明优选的,所述s4中,损失率训练(trainingloss)采用的是新提出的focalloss损失计算函数。focalloss损失计算函数是基于crossentropy(ce)交叉熵计算公式改进方法,crossentropy(ce)的计算公式如式(1):
式(1)中,y表示图片标注时label属性,正类(是垃圾袋)为1,负类(不是垃圾袋)为0;p表示样本预测为正的概率。
式(1)进一步泛化为式(2):
式(2)中,pt表示式(1)的泛化,当y=1时,pt=p,当y为其他值时,pt=1-p。
式(2)的交叉熵损失公式如式(3):
ce(p,y)=ce(pt)=-log(pt)(3)
一个常用的平衡类别不均的方法是,加上一个用来平衡类别不均的参数权重参数αt∈[0,1],如式(4):
ce(pt)=-αtlog(pt)(4)
focalloss就是ce(pt)的基础上再加上一个权重(1-pt)γ,如式(5):
fl(pt)=-αt(1-pt)γlog(pt)(5)
式(5)中,γ≥0是可调节的聚焦参数。
本发明的实施例,可将参数设置为αt=0.25,γ=2能到较佳的效果。
模型的参数都需要根据实际反馈的情况进行修改,损失率(loss)必须要收敛并且要到达一个比较低的值,准确率(accuracy)、召回率(recall)越高越好,这反应模型识别的准确程度,直到输出的结果达到预期的阈值。
retinanet是一个fcn有resnet-fpn主干网和两个子网络组成(见图2)。预测过程就是简单的前向传播。为了提升速度,通过置信度阈值0.05,仅仅对每个fpn层最多top1k的anchor做边框回归;然后使用阈值0.5做nms产生最终结果。
s5:将测试集中的湿垃圾图像输入训练完成的retinanet网络进行测试,判断图像误差,即深度学习神经网络模型,是否符合要求;若是,则跳转到s6;若否,则跳转到s3重新训练retinanet网络。
根据本发明优选的,所述s5中,判断深度学习神经网络模型是否符合要求,主要看使用的场景里模型的正确率和漏检率,是否符合场景使用的阈值范围,若是,符合场景使用的阈值范围,则跳转到s6;若否,不符合场景使用的阈值范围,则根据情况选择跳转到s3重新训练,或者跳转到s4调整模型以提升模型的能力。
其中,正确率为:根据模型使用测试集测试时,输出的map值即为正确率;漏检率的定义为:1-召回率(recall)。其中符合场景使用的阈值范围为:map值大于85%;漏检率小于15%。
进一步的,在不符合场景使用的阈值范围时,判断损失率(loss)是否大于0.1且一直没有下降的趋势,若是则跳转到s3重新训练,若否则跳转到s4调整模型以提升模型的能力。
当输出的map值小于65%且没有上升的趋势,此时需要调整模型。
s6:将训练好的retinanet网络本地化保存,或者应用到现实进行湿垃圾中垃圾袋识别的场景。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分步骤是可以通过程序来指令相关的硬件完成,所述的程序可以存储于一种计算机可读存储介质中,如rom/ram、磁碟或光盘等。
尽管本发明的内容已经通过上述优选实施例作了详细介绍,但应当认识到上述的描述不应被认为是对本发明的限制。在本领域技术人员阅读了上述内容后,对于本发明的多种修改和替代都将是显而易见的。因此,本发明的保护范围应由所附的权利要求来限定。
- 还没有人留言评论。精彩留言会获得点赞!