针对法务信息的大数据仓库存储、分析、提取系统的制作方法
本发明涉及法律服务领域,具体涉及一种针对法务信息的大数据仓库存储、分析、提取系统。
背景技术:
随着人们的法律意识逐渐增强,公检法机构都出台了各种法务咨询、查询系统,以便于公众能够及时获取最新的法律动态。文件cn110059193a,公开了一种基于法律语义件与文书大数据统计分析的法律咨询系统,涉及司法技术领域,具体是一种面向司法领域的可以与用户进行多轮自然语言交互,动态生成咨询报告,解决用户法律问题的系统;基于海量机器预标注裁判文书数据集,通过引入神经网络模型来为用户提供了一个可以通过口语化问答的方式描述自身所遇到的法律问题的交互方式,通过自然文本信息抽取的技术使得可以为用户提供基于不断新增的法律文本而生成的定制化咨询报告。摆脱了以往基于专家系统的只能提供事先录入的固定的问卷与答案组合的法律咨询,更加贴近人工咨询的效果。
由于我国幅员辽阔、人数众多,服务器在用户对法律服务的需求高峰期需要对海量的数据进行提取、分析以及备份等处理,这会占用服务器很大的cpu使用率,降低服务器的响应速度,同时影响用户的体验。
技术实现要素:
本发明在于提供一种针对法务信息的大数据仓库存储、分析、提取系统,解决了现有法律服务系统在用户对法律服务的需求高峰期时,服务器cpu使用率占用高、响应速度低、用户体验差的技术问题。
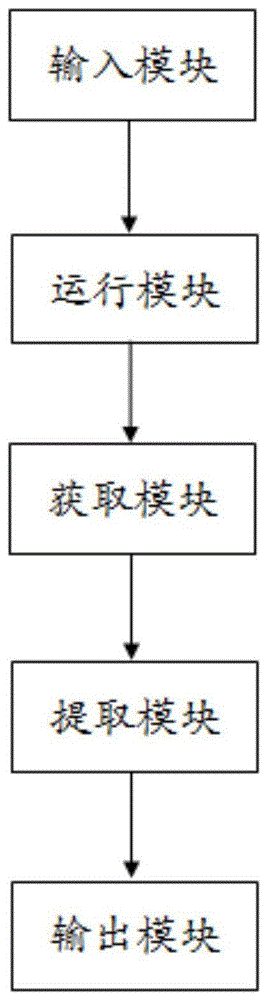
本发明提供的基础方案为一种针对法务信息的大数据仓库存储、分析、提取系统,包括:输入模块,用于发送用户的法律需求的数据请求;运行模块,用于接收用户的法律需求的数据请求并进行运行;获取模块,用于获取具有条件信息的数据请求,并发送条件信息;提取模块,用于接收条件信息,并根据条件信息提取运行的结果;输出模块,用于实时输出提取的运行结果。
本发明的工作原理在于:服务器首先判断用户访问量是否超过预设的阈值,若超过预设的阈值,则为高峰期。当用户访问处于高峰期时,服务器根据用户的法律需求数据请求进行模拟运行,运行完毕后不直接提取运行结果。而是先提取数据请求中的条件信息,然后根据条件信息分批、先后提取运行结果,这样就降低了服务器cpu的占用率。本发明的优点在于:在高峰期时能够降低服务器的cpu的占用率,防止系统卡死、崩溃,从而提高用户的体验。
本发明通过根据数据请求的条件信息分批次、先后提取运行结果,而不是同时提取运行结果,缓解了系统运行的压力,提高了运行的速率。
进一步,运行模块还用于获取服务器cpu的即时性使用率,若获取的服务器cpu的即时性使用率大于第一阈值,则分批运行数据请求;保证每批数据请求运行时,服务器cpu的即时性使用率小于等于第一阈值。这样可以保证服务器cpu的使用率总是保持在第一阈值以下,而且第一阈值可以人为设定。比如,在平时将第一阈值设为较低的值,在高峰期将第一阈值设为较高的值,这样可以尽可能提高系统的响应速率。
进一步,运行模块还用于获取用户的法律需求的数据请求中的即时性数据,并将数据请求按照其即时性要求的高低进行排序。这样便于系统根据即时性要求按序进行处理,缓解运行压力。
进一步,运行模块还用于识别用户的法律需求对应的法律领域与具体类别。根据我国的法律体系,案件可分为民事、刑事与行政三个法律领域,不同的法律领域处理的程序与规则存在极大的不同。另一方面,每个法律领域又包含若干个具体类别。比如民事法律领域就包括合同、侵权、物权、婚姻等多个具体类别,每个具体类别的案件又有其独特的规则。因此,有必要进行区分,便于系统有条不紊、高效地运行。
进一步,运行模块还用于对用户的法律需求的数据请求进行聚类。对于每个具体类别的案件,虽然用户的需求各异、种类繁多,但某些用户的需求在本质上存在极大的共同点。采用聚类算法分出的同一个类型的用户有很大的相似性,相似的用户皆被并入到同一类型中。这样可以减少每个具体类别中用户的种类,便于对这些用户的法律需求集中进行处理,从而提高效率、降低服务器的压力。
进一步,运行模块还用于检测用户法律需求的所包含的行为目标。这样便于深入分析用户需求,提炼出对用户真正有指导作用的信息。
进一步,还包括储存模块,用于储存用户的法律需求的数据请求和运行结果数据。这样可以收集大量的用户需求信息,从而为系统的优化提供大样本的数据。
进一步,还包括学习模块,用于优化系统的算法。这样便于系统根据用户的法律需求的数据请求和运行结果数据获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
进一步,还包括反馈模块,用于追问用户,并根据用户的回答进行反馈。这样便于尽可能获取解答用户问题所需的各项信息,从而对运行结果进行修正。
进一步,还包括评价模块,用于收集用户对系统的评价、建议与意见。通过了解用户的评价、建议与意见,便于对系统进行改进,从而提高用户的体验。
附图说明
图1为本发明针对法务信息的大数据仓库存储、分析、提取系统实施例一的系统结构框图。
图2为本发明针对法务信息的大数据仓库存储、分析、提取系统实施例二的系统结构框图。
具体实施方式
下面通过具体实施方式进一步详细的说明。
实施例一
本发明针对法务信息的大数据仓库存储、分析、提取系统实施例基本如附图1所示,包括输入模块、运行模块、获取模块、提取模块和输出模块。
在某个时刻,有很多用户(如说,有20000人)同时在法律智能服务机器人的输入端输入各自的法律需求,该输入端可以是输入界面。然后这些法律需求的数据请求被发送到运行模块,该运行模块为一台服务器。
服务器接收到这20000人的法律需求的数据请求后,首先通过数据请求中的关键词识别这20000用户的法律需求对应的法律领域与具体类别。比如说,服务器识别出这20000个用户中有15000个属于民事案件,有4000个属于刑事案件,有1000个属于行政案件。在这15000个民事案件中有7000个属于合同纠纷,有3000个属于侵权纠纷,有2000个属于婚姻纠纷,还有3000个属于物权纠纷。在4000个刑事案件中,危害公共安全的有500个,破坏社会主义市场经济的500个,侵犯公民人身权利、民主权利的1000个,财产犯罪的2000个。
然后,对每个具体类别中用户的法律需求的数据请求进行聚类。本实施例采用k均值聚类算法(k-meansclusteringalgorithm)进行聚类。在进行聚类前,需要提取每个用户需求的数据请求中的关键词,本实施例采用tf-idf算法,具体详细步骤可参考现有技术。关键词提取完毕后,就可进行聚类。第一步,随机选取k个关键词作为初始的聚类中心;第二步,把每个对象分配给距离它最近的聚类中心;第三步,重新计算聚类中心;第四步,若收敛,输出聚类结果;若不收敛,执行第一步。关于聚类算法的具体详细过程,也可参考现有技术。比如说,在7000个合同纠纷中提取出的关键词有“材料”、“货物”、“交付”、“利息”、“贷款”、“担保”、“租金”、“续租”、“转租”…聚类算法会把含有“材料”、“货物”、“交付”等关键词的合同纠纷归入买卖合同纠纷之列,一共有4000个;会把含有“利息”、“贷款”、“担保”等关键词的合同纠纷归入借款合同纠纷之列,一共有1000个;会把含有“租金”、“续租”、“转租”等关键词的合同纠纷归入租赁合同纠纷之列,一共有2000个。
接下来,获取用户的法律需求的数据请求中的即时性数据,并将数据请求按照其即时性要求的高低进行排序。本实施例中即时性是指诉讼时效期间的剩余期限,具体而言,剩余期限越短,即时性要求越高。因为我国的民法规定,公民在没有正当理由的情况下,没有及时行使权利导致诉讼时效期间已过,债务就变成自然债务,该债务的执行力会下降。具体来说,对4000个买卖合同纠纷而言,获取其中的时间关键词,通过这些时间关键词计算相应的诉讼期间的剩余期限,将剩余期限较短的排在前面,将剩余期限较长的排在后面。比如说,张三与李四均在2018年7月1日输入法律需求的数据请求,张三的纠纷发生在2017年7月1日,李四的纠纷发生在2016年7月1日。根据2017年10月1日开始实施的民法总则,买卖合同的诉讼时效期间为3年,张三的诉讼时效期间的剩余期限为2年,李四的诉讼时效期间的剩余期限为1年。因此,李四的情况相对张三比较紧急,应当优先处理,那么李四的数据请求就应当排在张三前面。类似地,可对4000个买卖合同纠纷全部进行排序。
最后,获取服务器cpu的即时性使用率。如果这4000人的买卖合同纠纷法律需求的数据请求录入服务器后,服务器cpu使用率显示大于第一阈值,那么这些数据请求就分批运行;保证每批数据请求运行时,服务器cpu的即时性使用率小于等于第一阈值。比如说,第一阈值人为设定为85%,若同时运行4000人的数据请求,cpu的使用率显示为95%。这时,就按照前述顺序分批运行,减少本次运行的数据请求量,先处理前3500个:若cpu的使用率降到85%以下,则可直接运行这3500人的数据请求;若cpu的使用率没有降到85%以下(比如为90%),则再次减少本次运行的数据请求量,直到cpu的使用率降到85%以下才开始运行。每一批数据请求的运行都采用类似的方式保证cpu的使用率在85%以下。另外,在平时可将第一阈值设为较低的值,比如70%,这样可以尽可能提高系统的响应速率。在运行时,还检测用户法律需求的所包含的行为目标。比如用户是简单咨询,还是了解诉讼风险,还是真的要起诉。
接着,获取这些数据请求中的条件信息,然后根据条件信息提取运行的结果。这些条件信息包括用户的年龄、身体状况、文化程度等,优先提取年长、身体状况差的用户的运行结果,这样可以减少等待时间。在提取运行结果的同时,实时将运行结果输出。输出的方式可以是纸质形式,也可以是电子形式;还可以是二维码形式,用户只需要扫描二维码即可查看结果。
实施例二
与实施例一不同之处仅在于:如附图2所示,还包括储存模块、学习模块、反馈模块和评价模块。
当服务器运行完毕后,将用户的法律需求的数据请求和运行结果数据储存起来。这就为系统的优化提供大样本的数据。学习模块根据储存的大样本数据采用机器学习算法对系统进行优化,这样便于系统根据用户的法律需求的数据请求和运行结果数据获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
在输出运行结果前,先追问用户对结果是否满意。如果不满意则提示用户修改、增加或者删减法律需求的数据请求,然后根据用户的回答进行反馈,将用户修改、增加或者删减后的数据请求放入下一序列重新运行。另外,在输出运行结果前还提示用户对系统的工作做出评价,并收集用户对系统的评价、建议与意见。通过了解用户的评价、建议与意见,便于对系统进行改进,从而提高用户的体验。
实施例三
与实施例一不同之处仅在于,运行模块还用于日常语言的识别。本实施例中,用户李四与张三存在合同纠纷,内容大致这样:“…张三于2010年6月1日向李四购买河沙5吨,于当日签订了河沙买卖合同,合同约定15日内李四将河沙保质保量运到张三家附近的石坝处,张三收到河沙时一次性付款。2010年6月16日,李四将河沙运到张三家附近的石坝处时,要求张三支付河沙价款2万元。”而且,李四提到了“ding金”,这时候就要区别是定金,还是订金。
首先,进行前置判断:若包含不超过20%或者一次性付清的信息,则输出定金;若包含超过20%或者多次付清的信息,则输出订金。比如说,张三和李四约定“ding金”为3500元,该“ding金”小于价款的20%(20000×0.2=4000),“ding金”应当为定金;反之,若张三和李四约定“ding金”为4500元,该“ding金”大于价款的20%(20000×0.2=4000),“ding金”应当为订金。又比如说,张三和李四约定“ding金”一次性交清,该“ding金”应当为定金;反之,若张三和李四约定“ding金”两次或者三次付清,该“ding金”就应当为订金。
事实上,由于当事人法律知识有限,弄不清楚定金与订金的区别:①、交付定金的合同是从合同,依约定应交付定金而未付的,不构成对主合同的违反;而交付订金的合同是主合同的一部分,依约定应交付订金而未交付的,即构成对主合同的违反。②、交付和收受订金的当事人一方不履行合同债务时,不发生丧失或者双倍返还预付款的后果,订金仅可作损害赔偿金。③、定金数额不超过主合同标的额的20%;而订金的数额依当事人之间自由约定,法律一般不作限制。④、定金具有担保性质,而订金只是单方行为,不具有明显的担保性质。
因此,当事人可能出现这样的约定,“定金为5000元”,这样超过了合同标的额的20%,超过部分在法律上不发生定金的效力。这时,前置判断就不能确定这5000元是订金还是定金。接着,就需要进行后续判断,输出“定金”、“订金”和“不知道”三个选项供用户选择,若用户选择定金或者订金,则直接输出结果。倘若用户选择不知道,则需要根据张三和李四约定的信息进行进一步的判断。比如说,如果李四提到“如果我把河沙拉来,你不付尾款,这5000块我就不退了”,可见这5000块具有担保的性质。那么张三和李四约定的就应当是“定金”,而超过价款的20%的那1000块则没有定金的效力。又比如,如果张三提到“如果你把河沙拉来,这5000块抵销5000块,我只付款15000元”,那么这5000块具有预付款的作用,张三和李四约定的就应当是“订金”。
以上所述的仅是本发明的实施例,方案中公知的具体结构及特性等常识在此未作过多描述,所属领域普通技术人员知晓申请日或者优先权日之前发明所属技术领域所有的普通技术知识,能够获知该领域中所有的现有技术,并且具有应用该日期之前常规实验手段的能力,所属领域普通技术人员可以在本申请给出的启示下,结合自身能力完善并实施本方案,一些典型的公知结构或者公知方法不应当成为所属领域普通技术人员实施本申请的障碍。应当指出,对于本领域的技术人员来说,在不脱离本发明结构的前提下,还可以作出若干变形和改进,这些也应该视为本发明的保护范围,这些都不会影响本发明实施的效果和专利的实用性。本申请要求的保护范围应当以其权利要求的内容为准,说明书中的具体实施方式等记载可以用于解释权利要求的内容。
- 还没有人留言评论。精彩留言会获得点赞!