一种人工智能开发平台的监控管理方法及系统与流程
本发明属于服务器技术领域,尤其涉及一种人工智能开发平台的监控管理方法及系统。
背景技术:
人工智能开发平台aistation,将为用户提供更加智能的ai容器化部署以及更具效率的分布式训练。监控管理模块作为aistation的重要模块,需要实时监控整个集群中节点的运行情况和资源的使用情况,有效的提高计算资源的利用率和生产率;并且需要具有处理大规模集群产生的监控数据,保证监控数据的安全性和数据价值性的能力。
但是,人工智能开发平台在数据采集以及数据存储方面存在如下缺陷:
(1)数据抓取过程中,数据采集场景单一,采集时间粒度无法控制在纳秒级,而且采集模块内存数据容易丢失,而且自身占据内存过大,影响采集数据的存储;
(2)当存储节点故障时,无法正常提供监控管理业务,给用户造成较大损失。
技术实现要素:
针对现有技术中的缺陷,本发明提供了一种人工智能开发平台的监控管理方法,旨在解决现有技术中数据采集场景单一,采集时间粒度无法控制在纳秒级,而且采集模块内存数据容易丢失,同时当存储节点故障时,无法正常提供监控管理业务的问题。
本发明所提供的技术方案是:一种人工智能开发平台的监控管理方法,所述方法包括下述步骤:
对数据采集模块进行源码优化,并利用优化的数据采集模块进行数据采集,其中采集到的数据为包括集群、存储节点和gpu卡在内的各个资源的使用数据;
将采集到的数据写入多节点部署的时间序列数据库,所述时间序列数据库处于高可用状态;
根据用户选取的聚合分析的时间节点,从所述时间序列数据库中采集包括集群、存储节点和gpu卡在内的各个资源的使用数据,同时对采集到的使用数据进行聚合分析,并通过ui界面展示聚合分析结果。
作为一种改进的方案,所述数据采集模块的源码优化内容包括自定义数据采集脚本、数据采集方式的修改和数据采集模块内存管理方式的修改;
其中,修改后的数据采集方式满足指定场景的数据采集和纳米级时间粒度的采集,所述自定义数据采集脚本所采集的数据包括节点中cpu的温度、gpu卡的性能数据以及容器相关的性能数据,所述指定场景包括gpu存在不可用情况的场景和由于网络问题导致gpu卡训练速度不足的场景;
内存管理方式的修改包括在所述数据采集模块内增加一个中间文件,所述中间文件用来存储数据采集模块中的内存数据;
所述时间序列数据库为influxdb。
作为一种改进的方案,所述利用优化的数据采集模块进行数据采集的步骤具体包括下述步骤:
采集符合源码优化的数据采集模块内存结构的数据;
通过对所述数据采集模块内存管理方式的修改,在将采集的数据写入时间序列数据库influxdb之前,将所述数据采集模块的内存数据写入预先配置的中间文件。
作为一种改进的方案,所述时间序列数据库influxdb的高可用状态的设置步骤具体包括:
配置多个用于冗余的存储节点,并将所述数据采集模块采集到的数据同时写入多个存储节点的时间序列数据库influxdb中;
对服务器集群中的存储节点进行增加或删除,同时,通过自动修改目前集群中所有存储节点中数据采集模块写入数据的目标信息,并且把集群中所有的时间序列数据库influxdb的配置信息维护到配置中心中;
在linux操作系统上增加对所述时间序列数据库influxdb的可用性检测脚本,用于对所述时间序列数据库influxdb的可用性进行检测;
在linux操作系统上增加用于重启恢复所述时间序列数据库influxdb的恢复脚本,用于对当检测到所述时间序列数据库influxdb不可用时,通过重启服务以及清理内存的方式进行服务恢复;
在linux操作系统上增加存储节点切换脚本,用于当时间序列数据库influxdb恢复失败时,将工作状态切换到备用的存储节点上。
作为一种改进的方案,所述根据用户选取的聚合分析的时间节点,从所述时间序列数据库influxdb中采集包括集群、存储节点和gpu卡在内的各个资源的使用数据,同时对采集到的使用数据进行聚合分析,并通过ui界面展示聚合分析结果的步骤具体包括下述步骤:
选取聚合分析的时间节点,所述时间节点包括24小时、7天以及30天;
根据选取的聚合分析的时间节点,按照与所述时间节点相匹配的时间频率在所述数据采集模块采集的包括集群、存储节点和gpu卡在内的各个资源的使用数据中采集一次数据;
将所有次采集到数据做聚合分析,生成聚合分析结果,并存储在时间序列数据库influxdb中;
接收用户输入的页面展示命令,从所述时间序列数据库influxdb中查找与所述页面展示命令相匹配的聚合分析结果,并通过ui界面展示。
本发明的另一目的在于提供一种人工智能开发平台的监控管理系统,其特征在于,所述系统包括:
源码优化模块,用于对数据采集模块进行源码优化;
数据采集控制模块,用于利用优化的数据采集模块进行数据采集,其中采集到的数据为包括集群、存储节点和gpu卡在内的各个资源的使用数据;
数据写入模块,用于将采集到的数据写入多节点部署的时间序列数据库,所述时间序列数据库处于高可用状态;
聚合展示模块,用于根据用户选取的聚合分析的时间节点,从所述时间序列数据库中采集包括集群、存储节点和gpu卡在内的各个资源的使用数据,同时对采集到的使用数据进行聚合分析,并通过ui界面展示聚合分析结果。
作为一种改进的方案,所述数据采集模块的源码优化内容包括自定义数据采集脚本、数据采集方式的修改和数据采集模块内存管理方式的修改;
其中,修改后的数据采集方式满足指定场景的数据采集和纳米级时间粒度的采集,所述自定义数据采集脚本所采集的数据包括节点中cpu的温度、gpu卡的性能数据以及容器相关的性能数据,所述指定场景包括gpu存在不可用情况的场景和由于网络问题导致gpu卡训练速度不足的场景;
内存管理方式的修改包括在所述数据采集模块内增加一个中间文件,所述中间文件用来存储数据采集模块中的内存数据;
所述时间序列数据库为influxdb。
作为一种改进的方案,所述数据采集控制模块具体包括:
采集模块,用于采集符合源码优化的数据采集模块内存结构的数据;
中间文件写入模块,用于通过对所述数据采集模块内存管理方式的修改,在将采集的数据写入时间序列数据库influxdb之前,将所述数据采集模块的内存数据写入预先配置的中间文件。
作为一种改进的方案,所述系统还包括:
冗余存储节点配置模块,用于配置多个用于冗余的存储节点;
多存储节点存储模块,用于将所述数据采集模块采集到的数据同时写入多个存储节点的时间序列数据库influxdb中;
存储节点修改模块,用于对服务器集群中的存储节点进行增加或删除;
修改匹配模块,用于通过自动修改目前集群中所有存储节点中数据采集模块写入数据的目标信息,并且把集群中所有的时间序列数据库influxdb的配置信息维护到配置中心中;
可用性检测脚本增加模块,用于在linux操作系统上增加对所述时间序列数据库influxdb的可用性检测脚本;
可用性检测模块,用于对所述时间序列数据库influxdb的可用性进行检测;
恢复脚本增加模块,用于在linux操作系统上增加用于重启恢复所述时间序列数据库influxdb的恢复脚本;
恢复模块,用于对当检测到所述时间序列数据库influxdb不可用时,通过重启服务以及清理内存的方式进行服务恢复;
储存节点切换脚本增加模块,用于在linux操作系统上增加存储节点切换脚本;
切换模块,用于当时间序列数据库influxdb恢复失败时,将工作状态切换到备用的存储节点上。
作为一种改进的方案,所述聚合展示模块具体包括下述步骤:
时间节点选取模块,用于选取聚合分析的时间节点,所述时间节点包括24小时、7天以及30天;
分频采集模块,用于根据选取的聚合分析的时间节点,按照与所述时间节点相匹配的时间频率在所述数据采集模块采集的包括集群、存储节点和gpu卡在内的各个资源的使用数据中采集一次数据;
聚合分析模块,用于将所有次采集到数据做聚合分析,生成聚合分析结果,并存储在时间序列数据库influxdb中;
匹配查找模块,用于接收用户输入的页面展示命令,从所述时间序列数据库influxdb中查找与所述页面展示命令相匹配的聚合分析结果;
界面展示模块,用于将所述匹配查找模块查找到的聚合分析结果通过ui界面展示。
在本发明实施例中,对数据采集模块进行源码优化,并利用优化的数据采集模块进行数据采集;将采集到的数据写入多节点部署的时间序列数据库,所述时间序列数据库处于高可用状态;根据用户选取的聚合分析的时间节点,从所述时间序列数据库中采集包括集群、存储节点和gpu卡在内的各个资源的使用数据,同时对采集到的使用数据进行聚合分析,并通过ui界面展示聚合分析结果,从而不仅解决了监控数据安全性和监控数据价值性问题,并且可以通过ui交互实时提供给用户整个集群资源的使用情况,有效的提高计算资源的利用率和生产率,减少业务成本,提高了ai平台在同类产品中的竞争力。
附图说明
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍。在所有附图中,类似的元件或部分一般由类似的附图标记标识。附图中,各元件或部分并不一定按照实际的比例绘制。
图1是本发明提供的人工智能开发平台的监控管理方法的实现流程图;
图2是本发明提供的利用优化的数据采集模块进行数据采集的实现流程图;
图3是本发明提供的时间序列数据库的高可用状态的设置流程图;
图4是本发明提供的对所述数据采集模块采集到的包括集群、存储节点和gpu卡在内的各个资源的使用数据进行聚合分析,并通过ui界面展示给用户的实现流程图;
图5是本发明提供的聚合分析示意图;
图6是本发明提供的人工智能开发平台的监控管理系统的结构框图;
图7是本发明提供的聚合展示模块的结构框图。
具体实施方式
下面将结合附图对本发明技术方案的实施例进行详细的描述。以下实施例仅用于更加清楚地说明本发明的、技术方案,因此只作为示例,而不能以此来限制本发明的保护范围。
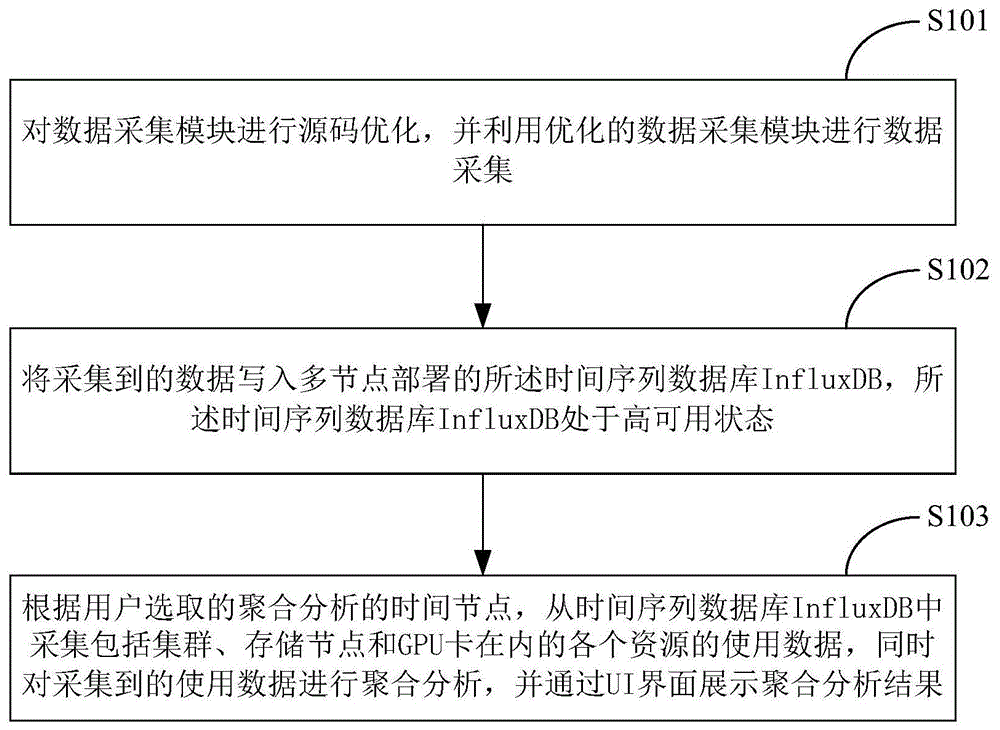
图1是本发明提供的人工智能开发平台的监控管理方法的实现流程图,其具体包括下述步骤:
在步骤s101中,对数据采集模块进行源码优化,并利用优化的数据采集模块进行数据采集,其中采集到的数据为包括集群、存储节点和gpu卡在内的各个资源的使用数据;
在该步骤中,该数据采集模块可以是telegraf,其部署在集群的每个主机上,通过不同的inputplugin采集不同的资源的监控信息,将监控信息输出到数据库influxdb。
在步骤s102中,将采集到的数据写入多节点部署的时间序列数据库influxdb,所述时间序列数据库influxdb处于高可用状态;
在步骤s103中,根据用户选取的聚合分析的时间节点,从所述时间序列数据库influxdb中采集包括集群、存储节点和gpu卡在内的各个资源的使用数据,同时对采集到的使用数据进行聚合分析,并通过ui界面展示聚合分析结果。
在该实施例中,数据采集模块的源码优化内容包括自定义数据采集脚本、数据采集方式的修改和数据采集模块内存管理方式的修改;
修改后的数据采集方式满足指定场景的数据采集和纳米级时间粒度的采集,所述自定义数据采集脚本所采集的数据包括节点中cpu的温度、gpu卡的性能数据以及容器相关的性能数据,通过该设置,精简数据采集模块采集数据的整个过程,直接采集生成符合数据采集模块内存结构的数据;
内存管理方式的修改包括在所述数据采集模块内增加一个中间文件,所述中间文件用来存储数据采集模块中的内存数据;而且该中间文件的设置,既可快速的释放数据采集模块占用的内存,又可以解决数据采集模块内存数据丢失的问题。
其中,上述指定场景包括gpu存在不可用情况的场景和由于网络问题导致gpu卡训练速度不足的场景,其具体为:
(1)检测gpu卡的可用性:用户在大规模训中,经常会遇到由于gpu温度过高或gpu供电不足导致gpu丢失,以致影响整个训练;该实施例可以提前获取gpu的温度和gpu供电信息反馈给用户,降低gpu不可用的概率;
(2)提高训练效率:在多gpu卡训练过程中经常会由于网络问题导致训练速度不足,该实施例通过抓取gpu卡拓扑信息(gpu卡之间的最短路径),快速分配最短路径的gpu卡给用户,提高训练效率。
在该实施例中,通过调整cpu和gpu内部的物理结构实现数据采集粒度精确到纳米级,提升采集效率,在此不再赘述。
在本发明实施例中,如图2所示,利用优化的数据采集模块进行数据采集的步骤具体包括下述步骤:
在步骤s201中,采集符合源码优化的数据采集模块内存结构的数据;
在步骤s202中,通过对所述数据采集模块内存管理方式的修改,在将采集的数据写入时间序列数据库influxdb之前,将所述数据采集模块的内存数据写入预先配置的中间文件。
在本发明实施例中,如图3所示,时间序列数据库influxdb的高可用状态的设置步骤具体包括:
在步骤s301中,配置多个用于冗余的存储节点,并将所述数据采集模块采集到的数据同时写入多个存储节点的时间序列数据库influxdb中;
在步骤s302中,对服务器集群中的存储节点进行增加或删除,同时,通过自动修改目前集群中所有存储节点中数据采集模块写入数据的目标信息,并且把集群中所有的时间序列数据库influxdb的配置信息维护到配置中心中;
在步骤s303中,在linux操作系统上增加对所述时间序列数据库influxdb的可用性检测脚本,用于对所述时间序列数据库influxdb的可用性进行检测;
在该步骤中,该可用性检测的内容包括influxdb本身系统级别状态检测(通过systemctlstatusinfluxdb即可获取状态)、influxdb本身数据库读写性能(通过influxdb本身监控接口直接获取)以及influxdb写入和查询数据服务状态检测(通过插入和查询一条数据即可获取)。
获取以上数据进行故障判断:如果状态为stop或者读写性能太低都会被判定为不可用;判断不可用之后系统会通过重启服务、清理内存的方式完成服务恢复,如果恢复失败则开发服务切换功能。
在步骤s304中,在linux操作系统上增加用于重启恢复所述时间序列数据库influxdb的恢复脚本,用于对当检测到所述时间序列数据库influxdb不可用时,通过重启服务以及清理内存的方式进行服务恢复;
在步骤s305中,在linux操作系统上增加存储节点切换脚本,用于当时间序列数据库influxdb恢复失败时,将工作状态切换到备用的存储节点上。
在该步骤中,如果自动切换失败则需要通知管理员来进行手动切换,在此不再赘述。
在本发明实施例中,该时间序列数据库influxdb的高可用性的设置,考虑了各种场景的应用,保证数据安全,防止数据丢失,给用户较好的体验。
在本发明实施例中,结合图4和图5所示,根据用户选取的聚合分析的时间节点,从所述时间序列数据库influxdb中采集包括集群、存储节点和gpu卡在内的各个资源的使用数据,同时对采集到的使用数据进行聚合分析,并通过ui界面展示聚合分析结果的步骤具体包括下述步骤:
在步骤s401中,选取聚合分析的时间节点,所述时间节点包括24小时、7天以及30天,如图5中的上述判断框中的时间节点,当然也可以设置为其他时间节点;
在步骤s402中,根据选取的聚合分析的时间节点,按照与所述时间节点相匹配的时间频率在所述数据采集模块采集的包括集群、存储节点和gpu卡在内的各个资源的使用数据中采集一次数据,对应上述的时间节点该采集频率对应为15分钟、2个小时、8个小时以及24小时;
在步骤s403中,将所有次采集到数据做聚合分析,生成聚合分析结果,并存储在时间序列数据库influxdb中,对每一个单位的时间频率采集的数据进行聚合分析,生成供用户查看的界面数据;
在步骤s404中,接收用户输入的页面展示命令,从所述时间序列数据库influxdb中查找与所述页面展示命令相匹配的聚合分析结果,并通过ui界面展示;
结合图5中的展示内容,对应上述时间节点、时间频率给出相应的24小时内的采集数据、7天内的采集数据、30天内的采集数据、180内的采集数据以及其他,在此不再赘述。
在该实施例中,通过上述设置,可供用户直观的了解整个人工智能开发平台aistation的状态。
图6示出了本发明提供的人工智能开发平台的监控管理系统的结构框图,为了便于说明,图中仅给出了与本发明实施例相关的部分。
人工智能开发平台的监控管理系统包括:
源码优化模块11,用于对数据采集模块进行源码优化;
数据采集控制模块12,用于利用优化的数据采集模块进行数据采集,其中采集到的数据为包括集群、存储节点和gpu卡在内的各个资源的使用数据;
数据写入模块13,用于将采集到的数据写入多节点部署的时间序列数据库influxdb,所述时间序列数据库influxdb处于高可用状态;
聚合展示模块14,用于根据用户选取的聚合分析的时间节点,从所述时间序列数据库influxdb中采集包括集群、存储节点和gpu卡在内的各个资源的使用数据,同时对采集到的使用数据进行聚合分析,并通过ui界面展示聚合分析结果。
在该实施例中,数据采集模块的源码优化内容包括自定义数据采集脚本、数据采集方式的修改和数据采集模块内存管理方式的修改;
其中,修改后的数据采集方式满足指定场景的数据采集和纳米级时间粒度的采集,所述自定义数据采集脚本所采集的数据包括节点中cpu的温度、gpu卡的性能数据以及容器相关的性能数据;
内存管理方式的修改包括在所述数据采集模块内增加一个中间文件,所述中间文件用来存储数据采集模块中的内存数据。
结合图6所示,数据采集控制模块12具体包括:
采集模块15,用于采集符合源码优化的数据采集模块内存结构的数据;
中间文件写入模块16,用于通过对所述数据采集模块内存管理方式的修改,在将采集的数据写入时间序列数据库influxdb之前,将所述数据采集模块的内存数据写入预先配置的中间文件。
在本发明实施例中,结合图6所示,所述系统还包括:
冗余存储节点配置模块17,用于配置多个用于冗余的存储节点;
多存储节点存储模块18,用于将所述数据采集模块采集到的数据同时写入多个存储节点的时间序列数据库influxdb中;
存储节点修改模块19,用于对服务器集群中的存储节点进行增加或删除;
修改匹配模块20,用于通过自动修改目前集群中所有存储节点中数据采集模块写入数据的目标信息,并且把集群中所有的时间序列数据库influxdb的配置信息维护到配置中心中;
可用性检测脚本增加模块21,用于在linux操作系统上增加对所述时间序列数据库influxdb的可用性检测脚本;
可用性检测模块22,用于对所述时间序列数据库influxdb的可用性进行检测;
恢复脚本增加模块23,用于在linux操作系统上增加用于重启恢复所述时间序列数据库influxdb的恢复脚本;
恢复模块24,用于对当检测到所述时间序列数据库influxdb不可用时,通过重启服务以及清理内存的方式进行服务恢复;
储存节点切换脚本增加模块25,用于在linux操作系统上增加存储节点切换脚本;
切换模块26,用于当时间序列数据库influxdb恢复失败时,将工作状态切换到备用的存储节点上。
在本发明实施例中,如图7所示,聚合展示模块14具体包括:
时间节点选取模块27,用于选取聚合分析的时间节点,所述时间节点包括24小时、7天以及30天;
分频采集模块28,用于根据选取的聚合分析的时间节点,按照与所述时间节点相匹配的时间频率在所述数据采集模块采集的包括集群、存储节点和gpu卡在内的各个资源的使用数据中采集一次数据;
聚合分析模块29,用于将所有次采集到数据做聚合分析,生成聚合分析结果,并存储在时间序列数据库influxdb中;
匹配查找模块30,用于接收用户输入的页面展示命令,从所述时间序列数据库influxdb中查找与所述页面展示命令相匹配的聚合分析结果;
界面展示模块31,用于将所述匹配查找模块查找到的聚合分析结果通过ui界面展示。
在本发明实施例中,对数据采集模块进行源码优化,并利用优化的数据采集模块进行数据采集;将采集到的数据写入多节点部署的时间序列数据库influxdb,所述时间序列数据库influxdb处于高可用状态;根据用户选取的聚合分析的时间节点,从所述时间序列数据库influxdb中采集包括集群、存储节点和gpu卡在内的各个资源的使用数据,同时对采集到的使用数据进行聚合分析,并通过ui界面展示聚合分析结果,从而不仅解决了监控数据安全性和监控数据价值性问题,并且可以通过ui交互实时提供给用户整个集群资源的使用情况,有效的提高计算资源的利用率和生产率,减少业务成本,提高了ai平台在同类产品中的竞争力。
以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围,其均应涵盖在本发明的权利要求和说明书的范围当中。
- 还没有人留言评论。精彩留言会获得点赞!