一种基于孪生神经网络及平行注意力模块的目标跟踪方法与流程
本发明属于机器视觉领域,特别涉及一种基于孪生神经网络及平行注意力模块的目标跟踪方法。
背景技术:
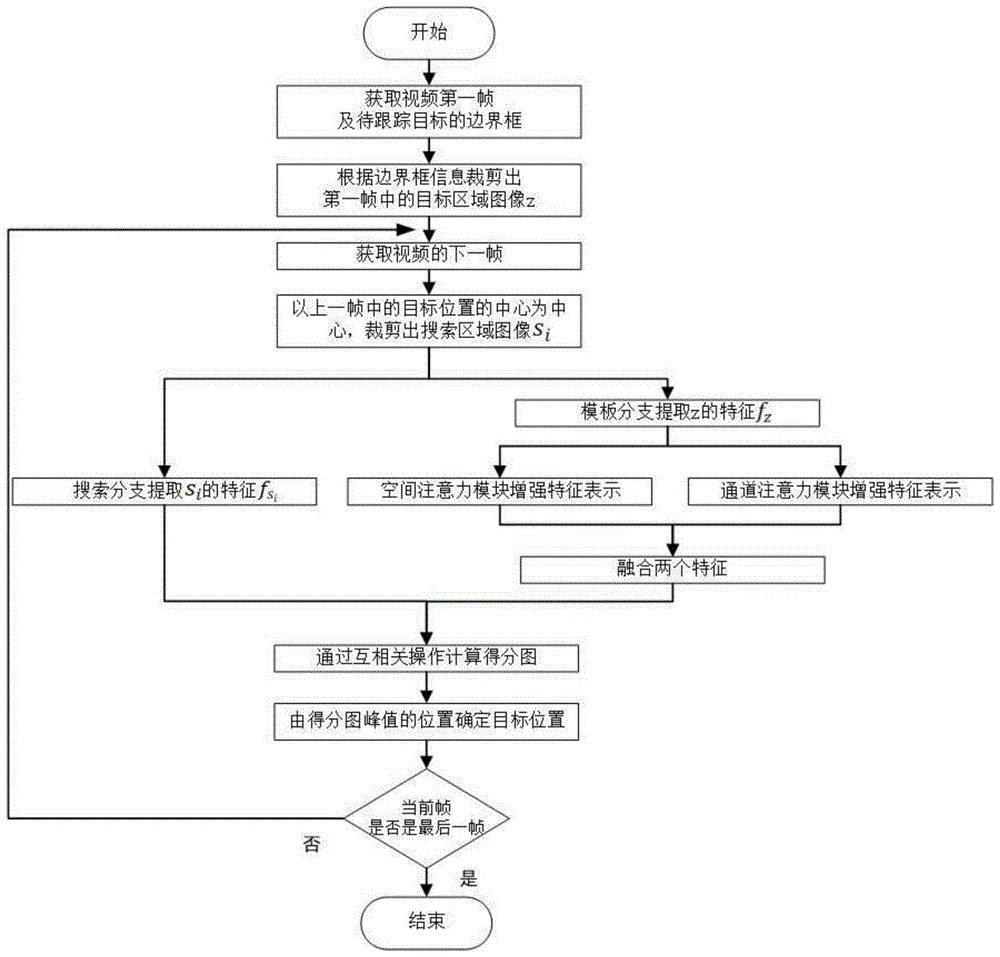
:随着机器视觉在理论上和实践上的广泛研究,目标跟踪逐渐成为其中基础但至关重要的一个分支。目标跟踪的任务是仅根据第一帧中目标的边界框,计算得出后续每一帧中该目标的具体位置,因此各种客观因素诸如物体形变、遮挡、快速运动、模糊、光照变化等问题使得跟踪面临着挑战。目前,目标跟踪主要可分为基于相关滤波的方法和基于深度学习的方法。在深度学习还未流行的很长一段时间内,大多数目标跟踪算法都是基于相关滤波的,尽管该类算法通过快速傅里叶变换大大减少了计算代价,提供可观的跟踪速度,但是其依靠手工特征对目标进行跟踪,在物体形变和背景杂乱等情况下,通过传统的手工特征对目标进行跟踪并不容易。相较而言,基于深度学习的目标跟踪算法可以有效学习到目标的深度特征,跟踪的鲁棒性较高。而基于孪生神经网络的方法,在保持较高的跟踪精度前提下,跟踪速度也高于其他多数基于深度学习的跟踪方法,可以满足跟踪的实时性。孪生网络结构通过两个分支中共享权重的特征提取网络对目标及搜索区域分别进行特征提取,并通过对特征的相似性计算来确定目标的最终位置。孪生网络的双分支结构较为巧妙,但仍有以下几个问题有待改善:(1)原始的孪生网络特征提取部分中,浅层的神经网络特征表达能力较弱,没有充分发挥出深度学习的优势;(2)训练过程中采用的损失函数易受简单样本的影响。基于以上考虑,本发明提出一个基于孪生神经网络并带有平行注意力模块的方法用于目标跟踪。首先,采用微调后的残差网络resnet作为特征提取网络,提取深层次的特征。其次,将平行注意力模块嵌入到网络的模板分支中,强化提取到的特征的表达能力。最后,在训练阶段通过自适应焦点损失函数对不同样本进行加权,以减少简单样本对训练过程的影响。技术实现要素:本发明的主要目的是提出一种基于孪生神经网络及平行注意力模块的目标跟踪方法。在训练阶段,通过引入自适应焦点损失函数减小简单样本对训练的负面影响;在跟踪阶段,通过提取深度特征,学习更加深层次的语义信息,并通过注意力模块对有效信息进行增强,同时抑制干扰信息的影响,以进行高效的目标跟踪。为了实现上述目的,本发明提供如下技术方案:步骤1、根据训练集视频序列图片中目标的位置及尺寸,裁剪出对应的目标区域z和搜索区域s,并以此图像对(z,s)为训练数据,构成训练数据集;步骤2、构建孪生网络及平行注意力模块,所述孪生网络包括模板分支和搜索分支,所述模板分支用于提取步骤1中所述目标区域z的特征,所述搜索分支用于提取步骤1中所述搜索区域s的特征,它们共享特征提取网络的权重。平行注意力模块作用于模板分支提取得到的特征,经过平行注意力模块强化的特征与搜索分支提取的特征做互相关运算,得到最终的得分图;步骤3、基于所述训练数据集,训练所述孪生神经网络,获得训练收敛的孪生网络模型;步骤4、利用训练得到的孪生网络模型进行在线跟踪。具体地,步骤1的操作包括裁剪目标区域和裁剪搜索区域图片对。根据视频序列中每一帧图片的边界框标注信息,获取目标的中心位置及尺寸(x,y,w,h),其中(x,y)代表目标的中心位置坐标,w,h分别代表边界框的宽和高。在裁剪目标区域图片时,首先计算扩充参数在边界框四周分别扩充q个像素,若超出图片边界,则超出部分用图片的平均像素值进行填充,将扩充后的边界框裁剪出来并将尺寸重置为127×127,即可得到目标区域图片。类似地,在裁剪搜索区域图片时,采用相同的扩充参数q,在边界框四周分别扩充2q个像素,若超出图片边界,则用图片的平均像素值进行填充,将扩充后的边界框裁剪出来并将尺寸重置为255×255,即可得到搜索区域图片。具体地,步骤2中所述孪生网络两个分支的特征提取网络均为微调后的resnet,删除了原始resnet的全连接层,仅保留了conv1,conv2,conv3三个阶段。将步骤1中所述图像对(z,s)分别输入搜索分支和模板分支得到对应的特征fz和fs,并将fz分别输入平行注意力模块的通道注意力强化模块和空间注意力强化模块,得到通道强化后的特征表示和空间强化后的特征表示将和以对应元素相加的方式进行特征融合,得到最终增强后的模板特征对和fs进行互相关操作,得到最终的得分图scoremap,对应公式为:为互相关运算。具体地,步骤3在训练过程中构建的自适应焦点损失函数公式为:其中,lafl为所述自适应焦点损失函数,p∈[0,1]代表样本被判定为正样本的概率,α∈[0,1]为平衡正负样本的参数,k∈{+1,-1}代表正负样本的标签,方便起见将p和α根据k的值分别记为pt和αt。是损失函数中的自适应参数,γinitial和γend分别为γ的起始值和终止值,i表示当前是训练过程的第i轮,epochnum为总的训练轮数。具体地,步骤4中所述在线跟踪过程包括以下步骤:1)读取待跟踪视频序列的第一帧图片frame1,获取其边界框信息,根据步骤1中所述裁剪目标区域图片的方法,裁剪出第一帧的目标模板图像z,将z输入步骤3中所述训练收敛的孪生网络的模板分支,提取模板图像的特征fz,并将特征输入平行注意力模块,得到经过强化的特征表示置t=2;2)读取待跟踪视频第t帧framet,并根据第t-1帧中确定的目标位置,按照步骤1中所述裁剪搜索区域图片的方法,裁剪出framet的搜索区域图像st,将st输入进步骤3中所述训练收敛的孪生网络的搜索分支,提取模板图像的特征3)对1)中的和2)中的进行互相关操作:scoremap为尺寸为17×17的相似性得分图,根据双三次插值上采样将scoremap映射为255×255,设u为scoremap中任一点的值,由argmaxu(scoremap)确定目标最终的位置;4)置t=t+1,判断t≤n是否成立,其中n为待测视频序列的总帧数。若成立则执行步骤2)—3),否则待测视频序列跟踪过程结束。与现有的技术相比,本发明具有以下有益效果:1、步骤2中的特征提取环节,本发明采用微调后的残差网络作为特征提取器。与原始的孪生网络采用的alexnet相比,resnet可以更加充分地发挥深度网络在提取深度特征上的优势,使得网络学习到更具判别性的特征。同时,特征提取网络保留了原始孪生网络结构中alexnet不采用全连接层和padding的措施,此举有利于保证网络的全卷积性和后面的scoremap计算环节。2、步骤2中,在提取到模板特征fz后,本发明利用空间特征以及通道特征对其进行强化。通过对应元素相加的特征融合操作,利用空间特征和通道特征之间的互补性,极大地提高了目标特征的鲁棒性。3、步骤3所述训练阶段,本发明引入了自适应焦点损失函数adaptivefocalloss(afl),该损失函数与原始算法中的逻辑回归损失函数相比,可以有效地抑制简单样本和困难样本不平衡对训练造成的负面影响。它综合考虑了对训练样本正确分类的置信度和当前的训练进度,对不同训练样本设置不同的权重,使得模型更加侧重于困难样本,从而不会被大量的简单样本影响到训练效果。4、与基础孪生网络跟踪系统相比,本发明构建的孪生网络结构的跟踪精度更高,同时依然可以满足跟踪的实时性要求。附图说明图1为本发明步骤4流程图;图2为目标区域图像和模板区域图像示意图;其中,(a)、(b)、(c)分别为不同目标的目标模板图像,(d)、(e)、(f)分别为不同目标的搜索区域图像。图3为本发明的算法模型图;图4为通道注意力模块;图5为空间注意力模块;图6为第一视频序列跟踪结果;其中,(a)为对第一视频序列lemming进行目标跟踪的第287帧;(b)对第一视频序列lemming进行目标跟踪的第338帧;(c)对第一视频序列lemming进行目标跟踪的第370帧。图7为第二视频序列跟踪结果;其中,(a)为对第二视频序列skiing进行目标跟踪的第10帧;(b)为对第二视频序列skiing进行目标跟踪的第30帧;(c)为对第二视频序列skiing进行目标跟踪的第39帧。图8为第三视频序列跟踪结果。其中,(a)为对第三视频序列soccer进行目标跟踪的第10帧;(b)为对第三视频序列soccer进行目标跟踪的第79帧;(c)为对第三视频序列soccer进行目标跟踪的第215帧。具体实施方式为了更好地理解上述技术方案,下面将结合说明书附图及具体的实施方式对上述技术方案进行详细的说明。本实施例提供了一种基于孪生神经网络及平行注意力模块的目标跟踪方法,包括以下步骤:(1)根据训练集中视频序列每帧图片的标注信息,裁剪出每帧对应的目标区域图像和搜索区域图像,所有裁剪得到的目标区域和搜索区域图像对构成训练数据集。本实施例的训练数据集为从got-10k中裁剪得到的图像对。目标区域的裁剪方法为:在边界框四周分别扩充q个像素,是根据边界框的宽和高计算得到的扩充参数。以标注的边界框的中心为目标中心,以边长截取出一个正方形区域,若该区域超出图片的边界,则用图片的像素平均值填充超出的部分。将此正方形区域的尺寸重置为127×127,即得到所述目标区域。搜索区域的裁剪方法为:在边界框四周分别扩充2q个像素,是根据边界框的宽和高计算得到的扩充参数。以标注的边界框的中心为目标中心,以边长截取出一个正方形区域,若该区域超出图片的边界,则用图片的像素平均值填充超出的部分。将此正方形区域的尺寸重置为255×255,即得到所述目标区域。图2为本实施例裁剪得到的目标模板图像和搜索区域图像的示意图。其中第一行为目标模板图像,第二行为搜索区域图像。所述裁剪操作是线下进行的,避免了训练过程中进行裁剪带来的计算代价。(2)构建孪生网络及平行注意力模块。图3为本发明实施例提供的算法模型示意图。特征fz∈rc*h*w,在h*w维度上分别对其进行最大池化和平均池化操作,得到c*1*1的特征表示,这两个特征表示经过全连接层和激活函数relu的作用。对应公式为:w0和w1分别对应权重共享部分两个全连接层的操作,avgpool和maxpool分别代表平均池化和最大池化。然后将得到的结果进行相加,最后通过sigmoid函数(σ)激活得到c*1*1的通道注意力权重fc:将fc与原特征fz的对应通道进行逐元素相乘得到最终的通道强化特征表示采用通道注意力强化特征的优点是:在跟踪不同的目标时,不同的特征通道有着不同的重要性,因此,在跟踪时计算出不同通道的权重可以有效增强有益信息,同时抑制无关信息的影响,在一定程度上改善跟踪的结果。空间注意力强化模块如图5所示:如图5所示,记输入为特征fz∈rc*h*w,将特征沿通道维度进行分组,假设分为m组(本实施例中m被设为64),则每组特征图的维度为由于每组特征图所进行的操作一致,这里仅讨论第i组fiz,图5中虚线代表相同操作被省略。在该组中,特定语义特征的位置具有较高的响应,而其他位置则响应值较低。通过对h*w维度的最大池化和平均池化以及把它们的结果相加,得到维度为的该语义特征的近似表示,用vectori来代表该特征表示。vectori=avgpool(fiz)+maxpool(fiz)。的特征图可以看成是h*w个位置上不同的向量,将它们分别与vectori点乘,得到的标量值即为该位置的响应。如图5,对响应图进行标准化normalization和激活函数sigmoid的操作后得到该组对应的空间注意力掩码最终的空间强化特征表示其中concate表示级联操作。采用空间注意力强化特征的优点是:空间注意力关注特征图的具体位置对区分目标和背景的影响。整个特征图中包含了特定目标各个不同部分的语义信息,因此,空间注意力模块旨在找出关键性的位置并分别增强其特征表示,从而可以得到更好的跟踪结果。将通道强化特征表示和空间强化特征表示融合后,得到的结果即为模板分支输出的增强特征表示(3)针对训练过程中简单样本带来的负面影响,构建自适应焦点损失函数。由于原始孪生网络所采用的损失函数没有针对简单样本做出对应处理,在训练的后期,大量的简单样本会影响到参数更新,因此通过对简单样本赋予低权重可以弱化其影响。本发明提出自适应焦点损失函数:其中i代表当前训练的轮数,epochnum代表总的训练轮数,γinitial,γend分别是人为设定的γ的起始值和终止值(本实施例中分别设为2和10-8)。在训练前期,应该是一个足够大的值,以保证简单样本的负面影响被抑制,随着训练进行,则需要不断衰减以降低后期模型所受的影响。由于小于1,随着训练的进行,会相应地不断衰减以适应当前训练过程,从而在一定程度上抑制不同训练阶段的简单样本对训练的影响。以在imagenet上预训练的网络进行参数初始化,采用梯度下降法进行训练,得到收敛的孪生网络模型。(4)利用所述训练得到的孪生网络进行在线跟踪。如图1所示为在线跟踪的流程图。首先,读取待跟踪视频序列的第一帧图片frame1,由于frame1中目标的位置及大小是已知的,根据步骤1中所述裁剪目标区域图片的方法,裁剪出第一帧的目标模板图像z,将z输入进步骤3中所述训练收敛的孪生网络的模板分支,提取模板图像的特征fz,并将特征输入平行注意力模块,得到经过强化的特征表示置t=2;其次,读取待跟踪视频第t帧,并根据第t-1帧中确定的目标位置,按照步骤1中所述裁剪搜索区域图片的方法,裁剪出搜索区域图像st,将st输入进步骤3中所述训练收敛的孪生网络的搜索分支,提取模板图像的特征然后,对和进行互相关操作:scoremap为尺寸为17×17的相似性得分图,根据双三次插值上采样将scoremap映射为255×255,设u为scoremap中任一点的值,由argmaxu(scoremap)确定目标最终的位置;最后,置t=t+1,判断t≤n是否成立,其中n为待测视频序列的总帧数。成立则继续执行上述两个步骤,否则待测视频序列跟踪过程结束。图6中的(a)为本发明实施例提供的使用本发明方法对第一视频序列lemming进行目标跟踪的第287帧,(b)和(c)分别对应第338帧和第370帧。可以看出,本发明提出的目标跟踪方法可以有效地跟踪到有遮挡干扰的目标。图7中的(a)为本发明实施例提供的使用本发明方法对第二视频序列skiing进行目标跟踪的第10帧,(b)和(c)分别对应第30帧和第39帧。可以看出,本发明提出的目标跟踪方法可以有效地跟踪到有低分辨率和快速运动干扰的目标。图8中的(a)为本发明实施例提供的使用本发明方法对第三视频序列soccer进行目标跟踪的第10帧,(b)和(c)分别对应第79帧和第215帧。可以看出,本发明提出的目标跟踪方法可以有效地跟踪到有背景杂乱和相似背景干扰的目标。为了对本发明进行更好的说明,下面以公开的目标跟踪数据集otb2013为例进行阐述。本发明在公开的otb2013数据集上进行了实验。它包含50个视频序列,是跟踪领域较为常用的数据集。otb2013中的视频序列包含11种不同属性的干扰因素,它们分别是尺度变化(sv)、光照变化(iv)、平面内旋转(ipr)、快速移动(fm)、背景杂乱(bc)、遮挡(occ)、平面外旋转(opr)、形变(def)、离开视野(ov)、运动模糊(mb)、低分辨率(lr)。这些属性代表了跟踪领域常见的难点。本发明采用跟踪领域常用的指标精确率和成功率来衡量算法的性能。若已知某一帧预测得到的目标边界框(记为rl),通过计算预测得到的rl与groundtruth(记为rc)之间的交并比若交并比大于给定的阈值,则认为这一帧被成功跟踪,成功率表示视频中被成功跟踪的帧数所占的比例。通常情况下,针对不同的阈值作出成功率曲线,通过计算曲线下面积areaundercurve(auc)评估跟踪算法。类似地,通过计算某一帧中预测得到的目标中心坐标与groundtruth中心坐标的欧式距离,若小于给定的阈值(默认为20个像素),则认为这一帧被精确跟踪,精确率表示视频中被精确跟踪的帧数所占的比例。表1为本发明提出的基于孪生神经网络及平行注意力模块的目标跟踪方法在otb2013数据集上的测试结果,本发明在这个数据集上取得了较好的跟踪结果,同时,速度达到66fps(framespersecond)满足了实时跟踪条件。尽管这otb2013存在着遮挡、变形、背景混乱、低分辨率等困难,但本发明提出的方法对这些困难具有很好的鲁棒性,因此表现较好。表1在otb2013上的跟踪结果数据集视频数量auc精确率fpsotb2013500.6690.88166本发明提出的方法主要包含平行注意力模块以及训练阶段使用的自适应焦点损失函数。从表2中可以看出,针对otb2013数据集,单纯使用原始孪生网络的auc达到0.608。在原始孪生网络的基础上,将特征提取网络换成resnet,auc达到0.623;在特征提取网络的模板分支上再加入平行注意力模块,auc达到0.653;在此基础上在训练阶段采用自适应焦点损失函数,auc达到0.669。这表明本发明提出的注意力模块和损失函数都对跟踪的性能有好的影响。它们分别可以强化目标特征的有效信息,抑制无关信息,以及在训练过程中减小简单样本对训练的负面影响,从而提高跟踪精度。表2在otb2013数据集上不同机制的影响上面结合附图对本发明的具体实施方式做了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1