基于自编码器与YOLO算法的高清图像小目标检测方法与流程
本发明属于目标检测技术领域,特别涉及到一种高清图像小目标的检测方法,可用于无人机航拍图像的目标识别。
技术背景
目前,随着目标检测技术的发展,特别是近几年,基于深度学习的目标检测算法的提出,例如faster-rcnn、ssd系列、yolo系列,这些算法与传统目标检测算法相比,基于深度学习的目标检测算法在准确率以及效率上都大大超过了传统检测算法。但是目前的算法都是基于现有的数据集进行优化,如imagenet、coco等,在实际应用中,如无人机航拍目标检测,由于无人机飞行高度较高,采集到的图像尺寸较大,一般都为高清图像,并且在采集到的图像中,目标尺寸一般较小,所以在对于高清图像的目标检测方面主要为小目标检测。
在目标检测中,对于高清图像的处理方式主要有两种,一种为下采样尺寸缩放的方式,一种为图像裁剪的方式,具体如下:
josephredmon等人发表在ieee国际计算机视觉与模式识别会议的非专利文献“yolo9000:better,faster,stronger”中提出对于yolo网络的改进方案中通过去掉全连接层的方式,使得网络可以检测不同尺寸大小的输入图像,该方法在使用voc2007+voc2012的数据集的实验结果中,通过下采样尺寸缩放的方式将输入图像缩放到288x288大小时,速度上可以达到91fps,但是在精度上只有69.0map,如果将输入图像缩放到544*544大小时,速度降低为40fps,精度提升为78.6map。从该实验中可以看出,大尺寸输入图像目标检测势必会造成计算量的加大,从而降低目标检测的速度,而通过下采样尺寸缩放的方式,又会造成目标空间信息的丢失,降低目标检测的精度。在高清图像的小目标检测中,如果将高清图像直接送入网络中检测,检测速度将会下降更为严重,如果通过尺寸缩放的方式,将会减少小目标特征信息,造成精度下降。
第二种常用方式为图像裁剪,具体做法为:将原始高清图像裁剪为小图送入网络进行检测,检测完毕之后进行合并。这种方式具有的优点是,通过裁剪,保证了图像的空间信息不损失,在目标检测精度上会有很好的效果,但是由于将一幅图像裁剪成了多幅图像,在目标检测速度上将会成倍的增加。
综上所述,如何在实际应用中,对高清图像进行快速又精确的目标检测成为一项有待解决的问题。
技术实现要素:
本发明的目的在于针对上述现有方法存在的缺陷,提供一种基于自编码器和yolo算法的高清图像小目标检测方法,旨在保证不降低高清图像检测速度的条件下,提高高清图像小目标的检测精度。
为实现上述目的,本发明的技术方案包括如下步骤:
(1)采集高清图像数据形成数据集,并对数据集进行标注,得到正确的标签数据,将数据集和标签数据以8:2的比例划分为训练集和测试集;
(2)将标注好的训练集进行数据扩充;
(3)对于每一幅高清图像数据,根据图像大小和标注信息,生成相应图像的目标mask数据;
(4)搭建一个包括编码网络和解码网络的全卷积自编码器模型,该编码网络用于对高清图像进行特征提取和数据压缩,该解码网络用于对压缩后的特征图恢复到原始大小;
(5)将高清图像训练集数据送入全卷积自编码器模型中进行训练,得到训练好的全卷积自编码器模型:
(5a)将网络的偏移量初始化为0,并采用kaiming高斯初始化方法对网络的权重参数进行初始化,根据高清图像训练集大小设置自编码器的迭代次数t1;
(5b)定义基于分区域的均方误差损失函数如下:
其中mask-mse-loss(y,y_)为所要计算的损失函数;y为解码器输出图像;y_为输入原始高清图像;α为目标区域的损失惩罚权重,设置为0.9;β为背景区域惩罚权重,设置为0.1;w为自编码器的输入图像尺寸宽度;h为自编码器的输入图像尺寸宽度;mask(i,j)为(3)中mask数据第(i,j)位置的值;
(5c)将高清图像训练集数据输入到全卷积自编码网络中,进行前向传播,得到编码后的特征图,再通过解码器对特征图进行恢复;
(5d)使用(5b)定义的基于分区域的均方误差损失函数,计算输入图像与输出图像的损失值;
(5e)使用反向传播算法进行全卷积自编码器的权值和偏移量更新,完成对全卷积自编码器训练的一次迭代;
(5f)重复(5c)~(5e),直到完成所有自编码器的迭代次数t1,得到训练好的全卷积自编码器;
(6)将训练好的全卷积自编码器的编码网络与yolo-v3检测网络进行拼接,并对拼接后的网络进行训练:
(6a)将训练好的全卷积自编码器的编码网络拼接到yolo-v3检测网络之前,形成拼接之后的混合网络;
(6b)对拼接后的混合网络进行训练:
(6b1)读取训练好的全卷积自编码器的参数,用读取的参数值初始化编码网络,并设置该编码网络的参数为不可训练的状态;
(6b2)设置yolo-v3网络的输入图像尺寸与全卷积自编码器网络的输入尺寸相同;
(6b3)从yolo官网上下载imagenet数据集上预训练的参数,用该参数对yolo-v3网络的参数进行初始化,并根据(1)采集的数据集大小设置yolo-v3网络的迭代次数t2;
(6b4)将高清图像训练集数据送入到拼接后的混合网络中进行正向传播,得到输出检测结果;
(6b5)使用yolo-v3算法中的损失函数,计算输出检测结果与(1)中标注的正确标签数据之间的损失值;
(6b6)根据损失值大小,使用反向传播算法进行混合网络的权值和偏移量更新,完成对混合网络训练的一次迭代;
(6b7)重复(6b4)~(6b6),直到完成所有yolo-v3的迭代次数t2,得到训练好的混合网络;
(7)将(1)中的测试集数据输入到训练好的混合模型中,得到最终的检测结果。
本发明与现有技术相比,具有以下优点:
本发明将自编码器的编码网络与yolo-v3检测网络相结合,且通过编码网络在很少损失目标区域特征的前提下对高清图像进行压缩,通过yolo-v3检测网络对压缩后图像进行小目标检测,由于编码网络只压缩背景特征信息,保留了目标特征信息,从而在保证了检测速度的情况下提高了高清图像中小目标检测的精度。
附图说明
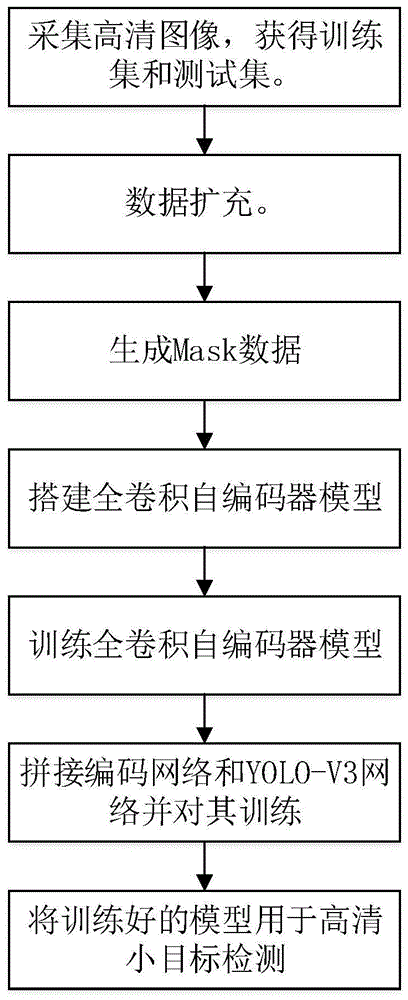
图1为本发明的实现流程图;
图2为本发明中采集高清图像的标注图;
图3为本发明中通过标注信息生成的mask数据图;
图4为本发明中卷积自编码器的网络结构图;
图5为本发明中编码器与yolo-v3网络相结合的结构图;
图6为用本发明在测试样本上的仿真检测结果图;
图7为现有下采样压缩高清图像方法经过yolo-v3在测试样本上的仿真检测结果图。
具体实施方式
以下结合附图对本发明的实施例和效果做进一步详细说明,所述实施例为对无人机拍摄的高清图像进行排污口小目标检测。
参照图1,本实例的实现步骤包括如下:
步骤1,采集高清图像,获得训练集和测试集。
采集无人机航拍的高清图像数据,图像宽度为1920像素,图像高度为1080像素;
使用常用的图像标注工具labelimg对采集到的图像数据进行目标标注,得到正确的标签数据,如图2所示;
将数据集和标签数据以8:2的比例划分为训练集和测试集。
步骤2,对标注好的数据集进行数据扩充。
2.1)对采集无人机航拍训练集中的每一幅高清图像分别做左右翻转、旋转、平移、加噪、亮度调整、对比度调整和饱和度调整的处理;
2.2)将经过处理后的图像数据加入到原始训练数据集中,得到扩充后的训练数据集。
步骤3,生成相应图像的目标mask数据图像。
3.1)根据无人机航拍采集的高清图像大小和标注信息,设置mask数据图像为二值图像数据,其宽度和高度与无人机航拍采集的高清图像宽度和高度相同,即mask数据图像宽为1920像素,高为1080像素,通道数为1;
3.2)读取原始图像中像素点所在的位置信息,通过该位置信息设置mask数据相对应像素点的值:
如果像素点在背景区域,mask数据相对应像素位置的值设置为0,
如果像素点在目标区域,mask数据相对应像素位置的值设置为1,
公式表示如下:
(i,j)是指像素点在无人机航拍图像数据中的第i行,第j列,mask(i,j)为mask图像数据在(i,j)位置的值。
本实例通过图2按照上述3.2)方法生成的mask图,如图3所示。
步骤4,搭建全卷积自编码器模型。
设全卷积自编码器模型包括编码网络和解码网络,该编码网络用于对高清图像进行特征提取和数据压缩,该解码网络用于对压缩后的特征图恢复到原始大小,搭建过程如下:
4.1)搭建编码网络:
编码网络包括5个卷积层,每个卷积层之间采用串联的连接方式,且每个卷积层参数设置如下:
第一层:卷积核大小为3*3,数量为16个,卷积步长为1,激活函数采用relu,输出特征图尺寸为1664*1664*16;
第二层:卷积核大小为3*3,数量为32个,卷积步长为2,激活函数采用relu,输出特征图尺寸为832*832*32;
第三层:卷积核大小为3*3,数量为64个,卷积步长为1,激活函数采用relu,输出特征图尺寸为832*832*64;
第四层:卷积核大小为3*3,数量为128,卷积步长为2,激活函数采用relu,输出特征图尺寸为416*416*128;
第五层:卷积核大小为1*1,数量为3,卷积步长为1,激活函数采用sigmoid,输出特征图尺寸为416*416*3;
4.2)搭建解码网络:
解码网络包括5个反卷积层,每个反卷积层之间采用串联的连接方式,且每一个反卷积层参数的设置如下:
第1层:卷积核大小为1*1,数量为128,卷积步长为1,激活函数采用relu,输出特征图尺寸为416*416*128;
第2层:卷积核大小为3*3,数量为64,卷积步长为2,激活函数采用relu,输出特征图尺寸为832*832*64;
第3层:卷积核大小为3*3,数量为32,卷积步长为1,激活函数采用relu,输出特征图尺寸为832*832*32;
第4层:卷积核大小为3*3,数量为16,卷积步长为2,激活函数采用relu,输出特征图尺寸为1664*1664*16;
第5层:卷积核大小为3*3,数量为3,卷积步长为1,激活函数采用sigmoid,输出特征图尺寸为1664*1664*3;
上述卷积核大小描述形式为w*h,其意义表示卷积核宽度为w,高度为h;
上述特征图尺寸描述形式为w*h*c,其意义表示特征图宽度为w像素,高度为h像素,通道数为c;
搭建好的全卷积网络如图4所示。
步骤5,训练搭建好的全卷积自编码器模型。
5.1)初始化网络参数:
将网络的偏移量初始化为0,并采用kaiming高斯初始化方法对网络的权重参数进行初始化,使其服从如下分布:
其中:wl为第l层的权重;n为高斯分布,即名正态分布;a为relu激活函数或leakyrelu激活函数的负半轴斜率,nl为每一层的数据维数,nl=卷积核边长2×channel数,channel为每一层卷积输入的通道数;
根据高清图像训练集大小设置自编码器的迭代次数为8000次;
5.2)将训练集图像数据进行上采样,并使经过上采样的训练集图像数据尺寸与全卷积网络的输入尺寸相同,即宽度为1664像素,高度为1664像素,通道数为3;
5.3)将mask数据进行上采样,并使经过上采样的mask数据尺寸与全卷积网络的数据宽高相同,即宽度为1664像素,高度为1664像素,通道数为1;
5.4)将上采样后的图像输入到全卷积自编码网络中,进行前向传播,得到编码后的特征图,再通过解码器对特征图进行恢复;
5.5)按如下公式构造基于分区域的均方误差损失函数:
其中mask-mse-loss(y,y_)为所要计算的损失函数;y为解码器输出图像;y_为输入原始高清图像;α为目标区域的损失惩罚权重,设置为0.9;β为背景区域惩罚权重,设置为0.1;w为编码器输入数据的宽度,为1664;h为编码器数据数据的高度,其值为1664,mask(i,j)为经过上采样的mask图像数据在(i,j)位置的值;
5.6)使用5.5)的损失函数,计算输入图像与输出图像的损失值:
5.7)使用反向传播算法进行全卷积自编码器的权值和偏移量更新,完成对全卷积自编码器训练的一次迭代:
5.7.1)使用反向传播算法更新权值,其公式如下:
其中:wt+1为更新后的权重;wt为更新前的权重;μ为反向传播算法的学习率,此处设置为0.001;
5.7.2)使用反向传播算法更新偏移量,其公式如下:
其中:bt+1为更新后的偏移量;bt为更新前的偏移量;μ为反向传播算法的学习率,其值为0.001;
5.8)重复5.2)~5.7),直到完成全卷积自编码器的迭代次数,得到训练好的全卷积自编码器。
步骤6,拼接全卷积自编码器的编码网络与yolo-v3检测网络,训练拼接后的混合网络:
6.1)将训练好的全卷积自编码器的编码网络拼接到yolo-v3检测网络之前,形成拼接之后的混合网络,如图5所示;
6.2)对拼接后的混合网络进行训练:
6.2.1)读取训练好的全卷积自编码器的参数,用读取的参数值初始化编码网络,并设置该编码网络的参数为不可训练的状态;
6.2.2)设置yolo-v3网络的输入图像尺寸与全卷积自编码器网络的输入尺寸相同;
6.2.3)从yolo官网上下载imagenet数据集上的预训练参数,用该参数对yolo-v3网络的参数进行初始化,并根据(1)采集的数据集大小设置yolo-v3网络的迭代次数为5000次;
6.2.4)将无人机航拍的高清图像训练集数据送入到拼接后的混合网络中进行正向传播,得到输出检测结果;
6.2.5)使用yolo-v3算法中的损失函数,计算输出检测结果与(1)中标注的正确标签数据之间的损失值,
该yolo-v3算法中的损失函数表示如下:
其中:λcoord为对预测坐标损失的惩罚权重,设置为5;
λnoobj为没有检测到目标时置信度损失的惩罚权重,设置为0.5;
k为输出特征图的尺度大小;
m为边界框的数量;
xi为yolo-v3网络输出的特征图中第i个单元格中预测的边界框中心位置的横坐标值;
yi为yolo-v3网络输出的特征图中第i个单元格中预测的边界框中心位置的纵坐标值;
wi为yolo-v3网络输出的特征图中第i个单元格中预测的边界框的宽度;
hi为yolo-v3网络输出的特征图中第i个单元格中预测边界框的高度;
ci为yolo-v3网络输出的第i个单元格预测的置信度;
pi(c)为yolo-v3网络输出的特征图中第i个单元格类别为c的概率;
6.2.6)根据6.2.5)计算的损失值大小,使用反向传播算法进行混合网络的权值和偏移量更新,权值和偏移量更新方法与5.7)的更新公式相同,完成对混合网络训练的一次迭代;
6.2.7)重复(6.2.4)~(6.2.6),直到完成所有yolo-v3的迭代次数,得到训练好的混合网络;
步骤7,使用训练好的网络进行目标检测。
将步骤1中的测试集数据输入到训练好的混合模型中得到最终的检测结果,检测出图像中的小目标,结果如图6所示。
在图6与图7中,画框并注明文字的区域表示在该区域成功检测到了目标,从图7现有方法的结果中可看出,在左下角部分,有两个明显的暗管小目标没有检测出来,在右下角的部分,有一个较为明显的暗管小目标也没有检测出来。对比图6中的检测结果,由于本发明在图像压缩过程中保留了目标的空间特性,成功检测出了左下角和右下角的目标。从对比结果可以看出,本发明在高清图像的小目标检测方面与现有方法相比具有明显优势。
- 还没有人留言评论。精彩留言会获得点赞!