一种基于监督自编码的脑控字符拼写识别方法及系统与流程
本发明涉及人机交互领域,特别是涉及一种基于监督自编码的脑控字符拼写识别方法及系统。
背景技术:
基于脑电信号的拼写是一种全新的信息交互方式,其不依赖于人体外周神经和肌肉系统,就能实现大脑与外部环境间的信息交流及控制,该交互方式将极大改善残障人士或一些特定受限应用的交互体验,在医疗康复、教育教学、游戏娱乐、智能家居及军事等领域具有广泛的应用前景。
当前基于脑电信号的字符拼写系统主要运用事件相关电位(erp)或稳态视觉诱发电位(ssvep)进行,erp在时间序列上是串行诱发的,当目标数量较多时,输出一个目标所需的时间较长;ssvep的信息传输率虽高,但字符闪烁会使用户感到视觉疲劳,不适合长期使用,因此采用运动视觉诱发电位可改善字符拼写速度,减少使用者视觉疲劳。目前采用运动视觉诱发电位的脑控拼写存在的问题:①编码字符指令少,输入速度慢,②识别解码主要通过选取最优电极导联或特征,再运用分类算法进行识别解码,由于脑电是皮层激活源在头皮电极处的叠加信号,不能直观反映拼写意图大脑活动信息,解码精度和效率不高。
技术实现要素:
本发明的目的是提供一种基于监督自编码的脑控字符拼写识别方法及系统,提高脑控字符拼写的准确性和效率。
为实现上述目的,本发明提供了如下方案:
一种基于监督自编码的脑控字符拼写识别方法,包括:
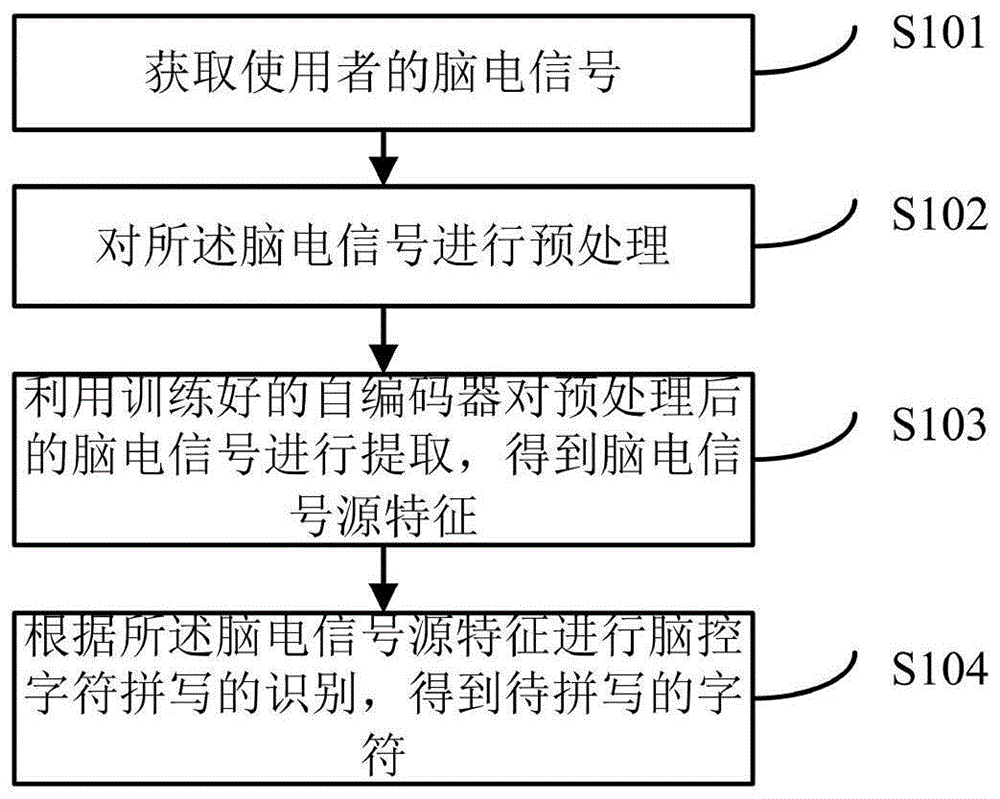
获取使用者的脑电信号;
对所述脑电信号进行预处理;所述预处理包括双侧乳突参考电极转换、0.5-40hz带通滤波、眼电伪迹去除,按照刺激呈现时间的0ms~400ms进行分段,以-100ms~0ms为基准进行基线校正;
利用训练好的自编码器对预处理后的脑电信号进行提取,得到脑电信号源特征;所述训练好的自编码器以预处理后的脑电信号为输入,以脑电信号源特征为输出;
根据所述脑电信号源特征进行脑控字符拼写的识别,得到待拼写的字符。
可选的,所述利用训练好的自编码器对预处理后的脑电信号进行提取,得到脑电信号源特征,之前还包括:
构建三级带输出类别反馈的自编码器;
对所述自编码器进行训练,得到训练好的自编码器。
可选的,所述构建三级带输出类别反馈的自编码器,具体包括:
以预处理后的脑电信号x作为输入,提取第一级源特征h1=φ(w1x+b1),构建一级自编码器;使得
以第一级源特征h1作为输入,提取第二级源特征h2=φ(w2h1+b2),构建二级自编码器,获重构输入信号
随机初始化
以第二级源特征h2作为输入,对应
可选的,所述根据所述脑电信号源特征进行脑控字符拼写的识别,得到待拼写的字符,之后还包括:
将所述待拼写的字符发送至刺激界面进行拼写校正;所述刺激界面包括a-z的26个英文字符、0-9的10个数字字符和逗号、句号、空格、返回4个功能字符的刺激界面,共分为5组,每组8个字符按九宫格方形外围排列,每个字符下方和九宫格中心均设置一个从左向右快速运动的方块。
一种基于监督自编码的脑控字符拼写识别系统,包括:
脑电信号获取模块,用于获取使用者的脑电信号;
预处理模块,用于对所述脑电信号进行预处理;所述预处理包括双侧乳突参考电极转换、0.5-40hz带通滤波、眼电伪迹去除,按照刺激呈现时间的0ms~400ms进行分段,以-100ms~0ms为基准进行基线校正;
脑电信号源特征确定模块,用于利用训练好的自编码器对预处理后的脑电信号进行提取,得到脑电信号源特征;所述训练好的自编码器以预处理后的脑电信号为输入,以脑电信号源特征为输出;
待拼写的字符确定模块,用于根据所述脑电信号源特征进行脑控字符拼写的识别,得到待拼写的字符。
可选的,还包括:
三级带输出类别反馈的自编码器构建模块,用于构建三级带输出类别反馈的自编码器;
自编码器训练模块,用于对所述自编码器进行训练,得到训练好的自编码器。
可选的,所述三级带输出类别反馈的自编码器构建模块具体包括:
一级自编码器构建单元,用于以预处理后的脑电信号x作为输入,构建一级自编码器,提取第一级源特征h1=φ(w1x+b1),然后重构输入信号
二级自编码器构建单元,用于以第一级源特征h1作为输入,构建二级自编码器,提取第二级源特征h2=φ(w2h1+b2),然后重构输入信号
预训练单元,用于随机初始化
三级带输出类别反馈的自编码器构建单元,用于以第二级源特征h2作为输入,对应
可选的,还包括:
拼写校正模块,用于将所述待拼写的字符发送至刺激界面进行拼写校正;所述刺激界面包括a-z的26个英文字符、0-9的10个数字字符和逗号、句号、空格、返回4个功能字符的刺激界面,共分为5组,每组8个字符按九宫格方形外围排列,每个字符下方和九宫格中心均设置一个从左向右快速运动的方块。
根据本发明提供的具体实施例,本发明公开了以下技术效果:
本发明所提供的一种基于监督自编码的脑控字符拼写识别方法及系统,脑电信号进行预处理,得到运动视觉诱发电位,由于每个字符刺激呈现是同时进行的,可提高意图到脑电信号的转换效率;利用训练好的自编码器对预处理后的脑电信号进行提取,得到脑电信号源特征。根据所述脑电信号源特征进行脑控字符拼写的识别,得到待拼写的字符。即将运动视觉诱发电位信号近似映射为脑皮层源电流密度信号,在自编码模型构建过程中,引入目标类别,提取与目标类别尽可能相关的脑皮层源电流密度特征,提高目标识别的准确性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明所提供的一种基于监督自编码的脑控字符拼写识别方法流程示意图;
图2为本发明所提供的一种基于监督自编码的脑控字符拼写识别方法对应的系统示意图;
图3为刺激界面示意图;
图4为三级带输出类别反馈的自编码器原理示意图;
图5为本发明所提供的一种基于监督自编码的脑控字符拼写识别系统结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的目的是提供一种基于监督自编码的脑控字符拼写识别方法及系统,提高脑控字符拼写的准确性和效率。
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
图1为本发明所提供的一种基于监督自编码的脑控字符拼写识别方法流程示意图,如图1所示,本发明所提供的一种基于监督自编码的脑控字符拼写识别方法,包括:
s101,获取使用者的脑电信号。使用者坐在显示器正前方,眼睛注视屏幕,字符拼写启动后,并如图2所示,64导ag/agcl电极按照国际10-20系统方式布设到使用者头皮上获取使用者的脑电信号。
获取使用者的脑电信号之后,将采集的电信号进行放大,如图2所示,通过采集放大装置进行脑电信号的采集与放大。
构建三级带输出类别反馈的自编码器,并如图4所示;
以预处理后的脑电信号x作为输入,提取第一级源特征h1=φ(w1x+b1),构建一级自编码器;使得
以第一级源特征h1作为输入,提取第二级源特征h2=φ(w2h1+b2),构建二级自编码器,获重构输入信号
以第二级源特征h2作为输入,对应
对所述自编码器进行预训练,得到训练好的自编码器。
随机初始化
s102,对所述脑电信号进行预处理;所述预处理包括双侧乳突参考电极转换、0.5-40hz带通滤波、眼电伪迹去除,按照刺激呈现时间的0ms~400ms进行分段,以-100ms~0ms为基准进行基线校正。
s103,利用训练好的自编码器对预处理后的脑电信号进行提取,得到脑电信号源特征;所述训练好的自编码器以预处理后的脑电信号为输入,以脑电信号源特征为输出。
s104,根据所述脑电信号源特征进行脑控字符拼写的识别,得到待拼写的字符。
将所述待拼写的字符发送至刺激界面进行拼写校正;所述刺激界面包括a-z的26个英文字符、0-9的10个数字字符和逗号、句号、空格、返回4个功能字符的刺激界面,共分为5组,每组8个字符按九宫格方形外围排列,每个字符下方和九宫格中心均设置一个从左向右快速运动的方块,并如图3所示。
通过刺激界面进行2级呈现,一次运动刺激时间为400ms,当前刺激试次有快速运动方块记为1,无快速运动方块记为0,则i次快速运动刺激可同时标记2i个目标输出,使用者选择字符的意图分2步进行识别,即先识别分组码,再识别字符码,其中,分组码采用3位,实现5组输出,字符码采用3位,实现8个字符输出,每个字符选择过程参照图3进行识别输出,一次快速运动刺激结束,所有运动方块消失100ms,以此作为下一刺激试次起始标志,刺激呈现程序可通过psychtoolbox编写。
刺激界面显示及脑电数据采集,使用者坐在显示器正前方,眼睛注视屏幕,字符拼写启动后,刺激呈现界面中滑动方块按表一所示分组码规则呈现,随后按字符码规则呈现,6次自左向右方块运动过程即可标记一个待选字符,并由使用者标注待选字符输出,以字符n为例,分组码滑动方块在3个呈现阶段依次为向右滑动、静止、静止,分组码标注为1、0、0,字符码滑动方块在3个呈现阶段依次为滑动、静止、滑动,字符码标注为1、0、1。表一如下所示:
表一
图5为本发明所提供的一种基于监督自编码的脑控字符拼写识别系统结构示意图,如图5所示,本发明所提供的一种基于监督自编码的脑控字符拼写识别系统,包括:脑电信号获取模块501、预处理模块502、脑电信号源特征确定模块503和待拼写的字符确定模块504,
脑电信号获取模块501用于获取使用者的脑电信号;
预处理模块502用于对所述脑电信号进行预处理;所述预处理包括双侧乳突参考电极转换、0.5-40hz带通滤波、眼电伪迹去除,按照刺激呈现时间的0ms~400ms进行分段,以-100ms~0ms为基准进行基线校正;
脑电信号源特征确定模块503用于利用训练好的自编码器对预处理后的脑电信号进行提取,得到脑电信号源特征;所述训练好的自编码器以预处理后的脑电信号为输入,以脑电信号源特征为输出;
待拼写的字符确定模块504用于根据所述脑电信号源特征进行脑控字符拼写的识别,得到待拼写的字符。
本发明所提供的一种基于监督自编码的脑控字符拼写识别系统还包括:三级带输出类别反馈的自编码器构建模块、自编码器训练模块和拼写校正模块。
三级带输出类别反馈的自编码器构建模块用于构建三级带输出类别反馈的自编码器;
自编码器训练模块用于对所述自编码器进行训练,得到训练好的自编码器。
拼写校正模块用于将所述待拼写的字符发送至刺激界面进行拼写校正;所述刺激界面包括a-z的26个英文字符、0-9的10个数字字符和逗号、句号、空格、返回4个功能字符的刺激界面,共分为5组,每组8个字符按九宫格方形外围排列,每个字符下方和九宫格中心均设置一个从左向右快速运动的方块。
所述三级带输出类别反馈的自编码器构建模块具体包括:一级自编码器构建单元、二级自编码器构建单元、预训练单元和三级带输出类别反馈的自编码器构建单元。
一级自编码构建单元用于以预处理后的脑电信号x作为输入,提取第一级源特征h1=φ(w1x+b1),然后重构输入信号
二级自编码构建单元用于以第一级源特征h1作为输入,提取第二级源特征h2=φ(w2h1+b2),然后重构输入信号
预训练单元随机初始化
三级带输出类别反馈的自编码器构建单元用于以第二级源特征h2作为输入,对应
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的系统而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
本发明中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!