基于高维PCANet的鲁棒图像识别方法与流程
本发明涉及图像处理和模式识别领域,尤其是待识别图像与训练图像有较大差异的鲁棒图像识别,主要用于处理和识别现实中的图像。
背景技术:
在现有计算机视觉和图像识别领域中,以卷积神经网络(convolutionalneuralnetworks,cnn)为代表的深度神经网络(deepneuralnetwork,dnn)取得了极大的成功,在一些公开的数据集上,前沿的深度学习方法的分类能力甚至超过了人类,例如:在lfw人脸数据库上的认证准确率,在imagenet上的图像分类准确率,以及在mnist上的手写数字识别准确率等。然而,在实际中,待识别图像在“分布”或“结构”上往往与训练图像有较大的差异,这种差异会导致dnn出现较大规模的识别错误,在深度学习领域中,这一现象被称为“协变量偏移(covariateshift)”。“协变量偏移”引发现有的图像识别方法存在准确率较低、可行性较差的技术缺陷。
技术实现要素:
为了克服已有协变量偏移所引发的图像识别准确率较低、可行性较差的不足,本发明提出一种准确性高、可行性好的基于高维pcanet(high-dimensionalpcanet,hpcanet)的鲁棒图像识别方法,hpcanet能够有效克服由于协变量偏移所引发的识别问题,尤其是当待识别图像存在遮挡、光照变化、分辨率差异等幅度较大的偏移时,能够大幅度提升图像识别性能。
本发明解决其技术问题所采用的技术方案是:
一种基于高维pcanet的鲁棒图像识别方法,包括以下步骤:
步骤1选取j张图像a={a1,…,aj}作为训练集,对应的类别标签为
步骤2初始化参数和输入数据:令
步骤3由
其中,
步骤4如果
步骤5计算
步骤6由v(l)获取cl+1个立体式滤波器组
步骤7计算第l+1个卷积层的特征图集x(l+1);
步骤8令l=l+1,执行上述步骤3~步骤7,直至l=l,这里l表示预先给定的最大卷积层数;
步骤9初始化参数和输入数据:令
步骤10由
步骤11如果
步骤12计算
步骤13由v(l)获取cl+1个立体式滤波器组
步骤14计算第l+1个卷积层的特征图集y(l+1);
步骤15令l=l+1,执行上述步骤3~步骤14,直至l=l;
步骤16将特征图集x(l)和y(l)合并起来形成新的特征图集f:
步骤17对特征图集f进行模式图编码,得到模式图集p:p={pi,β}i=1,…,n;β=1,…,β,其中,
步骤18从模式图集p欧诺个提取柱状图特征h:h=[hi]i=1,…,n,其中,hi=[hi,1,…,hi,b]t,hi,β=qhist(pi,β),qhist(pi,β)表示将模式图pi,β划分为q块,从每一块中提取柱状图,每个柱状图使用2t个分组,也就是,统计模式图的编码值在每一特征块的2t个分组中出现的频率;
步骤19如果
步骤20令
步骤21计算度量矩阵m=[mi,j]i=1,…,j;j=1,…,k,其中,
其中,d表示
步骤22计算测试集y中各样本的类别id=[idi]i=1,…,k:
其中,mi表示度量矩阵m中的第i列向量,minindx(·)表示mi中的最小元素的索引。
进一步,所述步骤7中,按照如下步骤计算第l+1个卷积层的特征图集x(l+1):7.1)将
再进一步,所述步骤14中,按照如下步骤计算第l+1个卷积层的特征图集y(l+1):14.1)将
本发明的技术构思为:当待识别图像与训练集图像存在遮挡、光照变化、分辨率差异等幅度较大的偏移时,现有的神经网络模型的识别性能往往会大幅度下降,而pcanet能够较好地解决此类问题。然而,pcanet存在如下两点不足:(1)pcanet所采用的是平坦式卷积,未充分考虑特征图的各通道之间的相关性;(2)pcanet在进行模式图编码时对所生成的特征图进行了8倍压缩,以致于所获取的模式图缺乏丰富的判别性特征。为了解决上述问题,受高维lbp思想的启发,本发明将立体式卷积和平坦式卷积结合起来,其中,立体式卷积可以充分考虑通道之间的相关性,而平坦式卷积能够对输入图像的每一个通道进行充分的主方向分解,因此,所得到的模式图相较于原始的pcanet具有更为丰富的特征,从而能够有效提升pcanet的鲁棒性。
本发明的有益效果主要表现在:能够更加有效的处理待识别图像中的遮挡、光照变化、分辨率差异等变化,从而有效地提升了有偏移图像的识别率。
附图说明
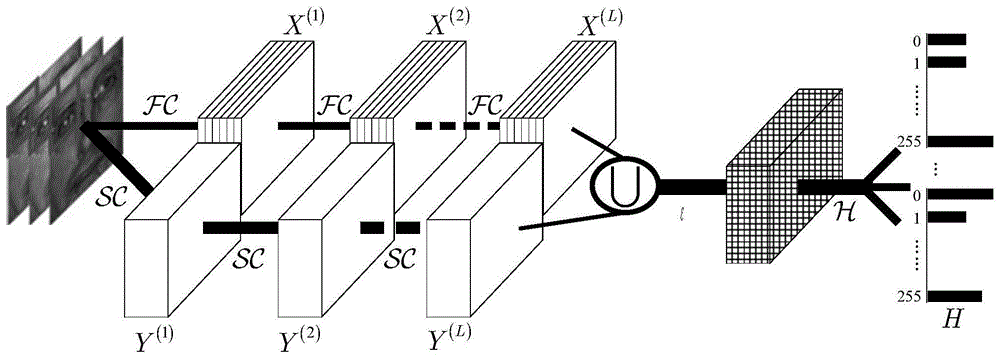
图1是本发明所述的高维pcanet的特征图提取过程,其中,
图2是本发明所述高维pcanet的分类过程,详见发明内容的步骤21和步骤22,图中的nn表示最近邻分类器,id表示待识别图像最终的类别;
图3是来自ar人脸数据库的训练集样本和测试集样本,其中,(a)测试集i的样本样例,(b)测试集ii的样本样例,(c)测试集iii的样本样例,(d)为训练集的样本样例;
图4(a)是vec(·)算子将矩阵拉伸为列向量的过程,图4(b)是matm×n(·)算子将列向量重置为矩阵的过程;
图5是平坦式卷积中从特征图提取特征块的过程图,其中,(a)是原始特征图,(b)是边界零填充,(c)是特征块选取,(d)是所选取的多通道特征块;
图6是立体式卷积中从特征图提取特征块的过程图,其中,(a)是原始特征图,(b)是边界零填充,(c)是特征块选取,(d)是所选取的多通道特征块;
图7(a)是平坦式滤波器的一维展示,图7(b)是立体式滤波器的一维展示;
图8是平坦式滤波器/立体式滤波器的二维展示,其中,(a)表示卷积层1的平坦式卷积核,(b)表示卷积层2的平坦式卷积核,(c)表示卷积层2的立体式卷积核;
图9是对待识别图像经过2层平坦式卷积和立体式卷积所生成的特征图的模值,其中,(a)表示待识别图像(有光照变化和遮挡),(b)表示经过2层平坦式卷积所生成的64个特征图的模值,(c)表示经过2层立体式卷积所生成的64个特征图的模值;
图10是高维pcanet方法所生成的16个模式图,其中,第一行的8个模式图来自于平坦式卷积所生成的特征图,第二行的8个模式图来自于立体式卷积所生成的特征图。
具体实施方式
下面结合附图对本发明作进一步描述。
参照图1~图10,一种基于高维pcanet(high-dimensionalpcanet,hpcanet)的鲁棒图像识别方法,所述方法包括以下步骤:
步骤1选取j张图像a={a1,…,aj}作为训练集,对应的类别标签为
步骤2初始化参数和输入数据:令
步骤3由
其中,
步骤4如果
步骤5计算
步骤6由v(l)获取cl+1个立体式滤波器组
步骤7按照如下步骤计算第l+1个卷积层的特征图集x(l+1):7.1)将
步骤8令l=l+1,执行上述步骤3~步骤7,直至l=l,这里l表示预先给定的最大卷积层数;
步骤9初始化参数和输入数据:令
步骤10由
步骤11如果
步骤12计算
步骤13由v(l)获取cl+1个立体式滤波器组
步骤14按照如下步骤计算第l+1个卷积层的特征图集y(l+1):14.1)将
步骤15令l=l+1,执行上述步骤3~步骤14,直至l=l;
步骤16将特征图集x(l)和y(l)合并起来形成新的特征图集f:
步骤17对特征图集f进行模式图编码,得到模式图集p:p={pi,β}i=1,…,n;β=1,…,β,其中,
图10展示了高维pcanet方法所生成的模式图;
步骤18从模式图集p欧诺个提取柱状图特征h:h=[hi]i=1,…,n,其中,hi=[hi,1,…,hi,b]t,hi,β=qhist(pi,β),qhist(pi,β)表示将模式图pi,β划分为q块,从每一块中提取柱状图,每个柱状图使用2t个分组,也就是,统计模式图的编码值在每一特征块的2t个分组中出现的频率;
步骤19如果
步骤20令
步骤21计算度量矩阵m=[mi,j]i=1,...,j;j=1,…,k,其中,
其中,d表示
步骤22计算测试集y中各样本的类别id=[idi]i=1,…,k:
其中,mi表示度量矩阵m中的第i列向量,minindx(·)表示mi中的最小元素的索引。
表1针对图3所给出的训练集和测试集,比较了hpcanet的三个版本(hpcanet-1、hpcanet-2、hpcanet-3)与现有方法(vgg-face、lcnn、pcanet)的识别率。这里,三个版本的hpcanet均采用两层卷积,且所采用的平坦式卷积核的个数均为8(卷积层1)+8(卷积层2),hpcanet-1所采用的立体式卷积核的个数分别为8和24,hpcanet-2所采用的立体式卷积核的个数分别为8和32,hpcanet-3所采用的立体式卷积核的个数分别为8和40。
表1
从表1可以看出,hpcanet-1~hpcanet-3都表现出了比pcanet更优的性能,尤其是当待识别图像的分辨率较低的时候,这一优势更为显著;另外,也可看出,从hpcanet-1到hpcanet-3,随着特征维度的提升,hpcanet的识别性能逐渐升高。
- 还没有人留言评论。精彩留言会获得点赞!