本发明属于类脑计算领域,涉及一种基于集成学习的脉冲神经网络模式识别方法及系统。
背景技术:
脉冲神经网络(snn)被誉为第三代人工神经网络,是人工智能计算领域近年来最热门的研究方向之一。以深度神经网络(dnn)为代表的第二代神经网络究其本质始终还是建立在复杂的数学模型基础上的,虽然其在结构上与人脑神经元结构类似,但与人脑神经元基于信号的时间(脉冲)来处理信息的计算机制有着本质的区别。为了实现真正意义上的类脑智能计算,snn这一新兴神经网络模型得到了广泛的研究。ibm公司推出的truenorth架构及芯片,采用了事件触发机制来触发模块工作,实现了极低的功耗,是数字集成电路实现snn的最具代表性之作。
脉冲神经网络应用于图像识别或模式识别领域的技术目前有很多,但是基于snn的高能效硬件电路与系统却很少。专利cn110210613a搭建了基于强化学习的snn硬件电路以实现xor分类功能,专利cn109816026a将卷积神经网络(cnn)与snn进行结构上的融合,实现了cnn信息特征提取能力强和snn稀疏、低功耗的优势的结合,专利cn108470190a在xilinxvirtex-7系列fpga平台上实现定制脉冲神经网络,通过仿生视觉传感器的动态图像信号或人工转化静态图像信号来产生脉冲序列,从而搭建了基于snn的图像识别电路系统,专利cn108985252a采用了dog层和简化脉冲耦合神经网络的方法对图像进行预处理,实现了更贴近生物特性、简单有效的snn模型。
现有的技术和方法大都聚焦在传统dnn到snn的转换方法、以及寻找有效的snn训练机制等技术问题上,但在有效解决snn模型性能差、以及从硬件架构层面挖掘snn模型的高能效潜力等方面还缺乏相关的技术研究。对于dnn而言,提高其模型性能的方法通常是提高模型的量化精度,而对于snn来说,由于其采用0、1的二元脉冲信号进行信息的处理这一特殊机制,因此通过snn模型的并行集成学习与优化,以及snn芯片的级联形成超高计算密度的类脑计算平台来提高snn的网络性能是未来重点的发展方向。如果考虑到目前呈指数倍增长的有着超低功耗需求的iot设备和嵌入式边缘计算平台的应用场景,那么snn的集成学习无疑将会成为一个重要突破点。
技术实现要素:
有鉴于此,本发明的目的在于提供一种基于集成学习的脉冲神经网络模式识别方法。
为达到上述目的,本发明提供如下技术方案:
一种基于集成学习的脉冲神经网络模式识别方法,该方法包括以下步骤:
s1:建立二元snn算法模型;
s2:基于bagging的esnn算法模型;
s3:设计基于esnn的系统。
可选的,所述步骤s1为:
将dnn模型的权重和激活值进行二值脉冲化,采用的脉冲化函数为:
其中xb是二值的网络权重或激活;
对权重和激活进行二元脉冲处理,降低内存占用;
利用α尺度因子使二值卷积逼近实值卷积;
假设i是某层的实值输入,w是某层的一个实值卷积核权重,b∈{-1,+1}是w的二值量化权重,是该卷积核对应的尺度因子;用w≈αb使b去逼近w,利用l2范数,转化为求以下最优化目标函数:
j(b,α)=||w-αb||2
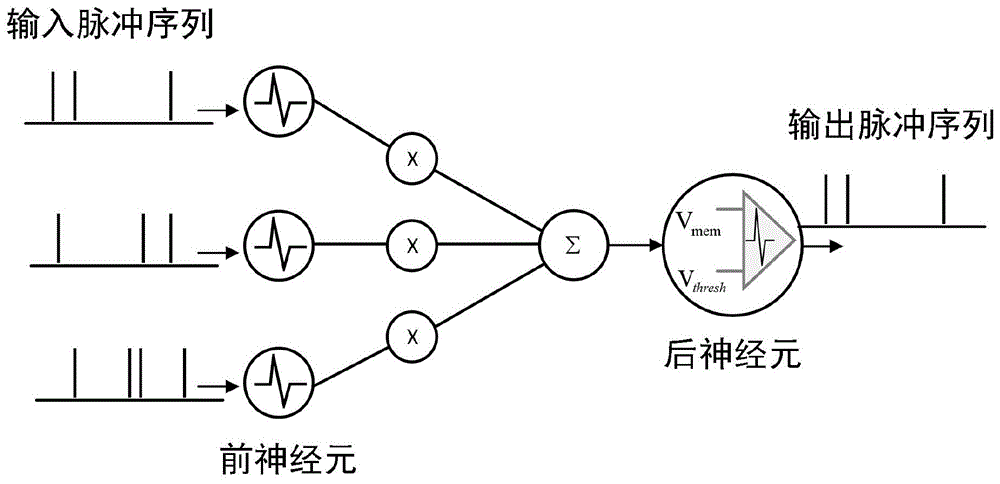
经过最优化求解过程求得最优解b*=sign(w),即最优二值权重是实值权重的符号位,最优缩放因子是实值权重w的每个元素的绝对值之和的均值;经过这个最优化过程完成对权重的脉冲化,脉冲函数为sign符号函数;对输入的脉冲化也是相同的过程,得到相同的最优解和输入脉冲函数;经过二元脉冲化的神经网络,若干个前神经元的输入和权重都是二元的脉冲信号,前神经元的计算结果经过聚合后形成后神经元的膜电位,通过阈值比较后输出脉冲信号,作为下一级的输入脉冲。
可选的,所述步骤s2为:
利用bagging算法同时训练多个相互独立的二元snn模型,然后推理时聚合所有的模型输出以表决出最后结果,实现基于bagging集成学习技术的二元snn模型算法框架;
利用多模型集成的方法使多个二值卷积核逼近于一个实值卷积核:
bagging算法的流程为以下步骤:
步骤1:假设包含m个训练样本的原始样本集为d={(x1,y1),(x2,y2)...(xm,ym),},对样本集进行m次自举采样bootstrap,即有放回的随机采样,得到一个包含m个样本的采样集;重复t次上诉操作得到t个采样集;
步骤2:对于步骤1得到的t个采样集,用每个采样集训练一个模型,共训练得到t个独立的同质模型;
步骤3:将t个模型对同一个测试样本的输出通过表决器来判定最后结果,对于分类任务通常选取投票数最多的类别作为最后结果,而回归任务则采用简单平均法。
可选的,所述步骤s3中,基于esnn的电路包括输入输出缓存与控制部分、片上存储器、脉冲神经网络流水线和bagging计算单元;
输入输出缓存与控制部分用于对来自外部io外设或总线的输入数据进行缓存和复用,解决跨时钟域的数据处理问题;
脉冲神经网络流水线包括多个级联的计算阵列,每个计算阵列用于计算相应位置的网络宏层,计算阵列包括多个并行的计算单元,分别实现不同卷积核的运算;
片上存储器用于存储snn模型的参数和中间计算结果,采用数据流式的计算架构,通过数据复用和计算单元的复用来实现宽度较深的网络计算;
bagging计算单元用于实现对并行流水线的输出结果进行聚合然后表决出最后结果;
所述系统采用基于数据流的全流水近存计算架构,输入数据经流所有的脉冲神经网络流水线,所有内存访问发生在片内且参数读取与数据严格同步;
每个计算阵列用于snn模型中一个宏层的计算,包括二元脉冲卷积层、批量归一化层、非线性激活层以及池化层;
计算阵列中还包括并行的计算单元pe;
计算单元由脉冲信号缓存模块、脉冲卷积模块、存储器以及控制器组成;
脉冲信号缓存模块由k×ni×ri的寄存器阵列组成,用来缓存输入的脉冲信号;若卷积核大小为k×k,每个行数据块长度为ri,当k个行数据块缓存完成后,便能每个时钟从中提取出一次脉冲卷积运算所需的滑动窗口的数据;ni是计算单元一次计算的数据通道数;脉冲卷积单元实现二元脉冲信号的卷积运算,移位器实现多个有权二元脉冲神经元的组合运算,累加器进行多次复用计算后的结果累加;阈值计算与池化单元负责进行批量归一化batchnormalization、非线性阈值激活activation和池化pooling运算;
采用归一化和激活函数结合的方式,将归一化层的参数和神经元的偏置合并为神经元的阈值电压,利用一个加法器实现神经元输出电压的阈值比较并根据输出电压的符号产生脉冲信号,最后根据模型的需要进行池化运算。
一种基于集成学习的脉冲神经网络模式识别系统,包括输入输出缓存与控制部分、片上存储器、脉冲神经网络流水线和bagging计算单元;
所述识别系统采用基于数据流的全流水近存计算架构,输入数据经流所有的脉冲神经网络流水线,所有内存访问发生在片内且参数读取与数据严格同步。
可选的,所述输入输出缓存与控制部分用于对来自外部io外设或总线的输入数据进行缓存和复用,解决跨时钟域的数据处理问题;
脉冲神经网络流水线包括多个级联的计算阵列,每个计算阵列用于计算相应位置的网络宏层,计算阵列包括多个并行的计算单元,分别实现不同卷积核的运算;
片上存储器用于存储snn模型的参数和中间计算结果,采用数据流式的计算架构,通过数据复用和计算单元的复用来实现宽度较深的网络计算;
bagging计算单元用于实现对并行流水线的输出结果进行聚合然后表决出最后结果。
可选的,所述计算阵列用于snn模型中一个宏层的计算,包括二元脉冲卷积层、批量归一化层、非线性激活层以及池化层。
可选的,所述计算阵列中还包括并行的计算单元pe;
计算单元pe包括脉冲信号缓存模块、脉冲卷积模块、存储器以及控制器。
可选的,所述脉冲信号缓存模块由k×ni×ri的寄存器阵列组成,用来缓存输入的脉冲信号;若卷积核大小为k×k,每个行数据块长度为ri,当k个行数据块缓存完成后,每个时钟从中提取出一次脉冲卷积运算所需的滑动窗口的数据;ni是计算单元一次计算的数据通道数;
脉冲卷积单元实现二元脉冲信号的卷积运算,移位器实现多个有权二元脉冲神经元的组合运算,累加器进行多次复用计算后的结果累加;
阈值计算与池化单元负责进行批量归一化batchnormalization、非线性阈值激活activation和池化pooling运算;
采用归一化和激活函数结合的方式,将归一化层的参数和神经元的偏置合并为神经元的阈值电压,利用一个加法器实现神经元输出电压的阈值比较并根据输出电压的符号产生脉冲信号,最后根据模型的需要进行池化运算。
本发明的有益效果在于:
1、二元snn由于脉冲神经元的传递函数不可微的性质阻止了模型的反向传播,因此snn始终未能达到与其他采用基础数学模型机制的神经网络模型相似的性能。本发明通过ensemblelearning可以有效的解决二元snn模型性能差的固有缺陷,满足了绝大部分类脑智能计算应用的高模型性能需求。
2、本发明提出的电路架构采用了基于数据流的近存计算架构,最大程度减少了内存访问次数,加之二元脉冲的计算机制将传统卷积运算转换为了位运算,使得架构实现了很高的能效。
3、在保证高能效表现的同时能够通过适当增加并行的二元snn的架构数量以提高模型性能,架构的灵活性提供了功耗与性能之间极佳的平衡,增加了电路架构的适用性。
本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
附图说明
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作优选的详细描述,其中:
图1为snn模型结构;
图2为基于bagging技术的snn模型框架;
图3为基于bagging的脉冲神经网络电路架构图;
图4为二元脉冲神经网络计算单元;
图5为每层神经元数目为128的3层感知机mlp模型;
图6为本发明应用场景图。
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。需要说明的是,以下实施例中所提供的图示仅以示意方式说明本发明的基本构想,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。
其中,附图仅用于示例性说明,表示的仅是示意图,而非实物图,不能理解为对本发明的限制;为了更好地说明本发明的实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;对本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
本发明实施例的附图中相同或相似的标号对应相同或相似的部件;在本发明的描述中,需要理解的是,若有术语“上”、“下”、“左”、“右”、“前”、“后”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此附图中描述位置关系的用语仅用于示例性说明,不能理解为对本发明的限制,对于本领域的普通技术人员而言,可以根据具体情况理解上述术语的具体含义。
本发明以基于bagging技术的集成脉冲神经网络(ensemblespikingneuralnetwork,esnn)模型为基础理论设计方案框架,进而引入了高能效的近存数据流式计算架构,通过多个并行的硬件架构来匹配多个二元snn模型,最后经过bagging单元电路进行聚合然后输出最后的结果。
1、二元snn算法模型原理
matthieucourbariaux在2016的论文binarizedneuralnetworks:trainingneuralnetworkswithweightsandactivationsconstrainedto+1or-1,首次将dnn模型的权重和激活值进行二值脉冲化。其采用的脉冲化函数为:
其中xb是二值的网络权重或激活。同时对权重和激活进行二元脉冲处理后可以极大地降低内存占用,加速模型的推理,但是二元脉冲模型极低的参数精度使得模型遭受到了较为严重的准确度损失。因此mohammadrastegari在2016年的论文xnor-net:imagenetclassificationusingbinaryconvolutionalneuralnetworks中提出了一种利用α尺度因子使二值卷积去逼近实值卷积的方法。假设i是某层的实值输入,w是某层的一个实值卷积核权重,b∈{-1,+1}是w的二值量化权重,是该卷积核对应的尺度因子。那么可以用w≈αb使b去逼近w,利用l2范数,转化为求以下最优化目标函数:
j(b,α)=||w-αb||2
经过最优化求解过程求得最优解b*=sign(w),即最优二值权重是实值权重的符号位,最优缩放因子是实值权重w的每个元素的绝对值之和的均值。经过这个最优化过程完成了对权重的脉冲化,脉冲函数为sign符号函数。对输入的脉冲化也是相同的过程,得到相同的最优解和输入脉冲函数,详细推导参见原论文。经过二元脉冲化的神经网络如图1所示。若干个前神经元的输入和权重都是二元的脉冲信号,前神经元的计算结果经过聚合后形成后神经元的膜电位,通过阈值比较后输出脉冲信号,作为下一级的输入脉冲。
2、基于bagging的esnn算法模型
2.1算法原理
bagging采用有放回重复采样的方法构成每次训练的采样集,每个采样集用于训练一个独立的模型。多模型集成的方法可以降低模型的方差,增强模型的鲁棒性,从而改善模型的过拟合状况。利用bagging算法同时训练多个相互独立的二元snn模型,然后推理时聚合所有的模型输出以表决出最后结果,这样便实现了基于bagging集成学习技术的二元snn模型算法框架,如图2所示。
多模型集成的方法使多个二值卷积核更逼近于一个实值卷积核。如公式(3)所示。
2.2算法步骤
bagging(bootstrapaggregating)是一种通过结合若干个同质弱模型以降低泛化误差的技术。核心思想是训练几个相互独立的模型,然后让所有模型共同表决测试样本的输出。bagging算法的流程主要为以下4个步骤:
步骤1:假设包含m个训练样本的原始样本集为d={(x1,y1),(x2,y2),...(xm,ym),},对样本集进行m次自举采样(bootstrap),即有放回的随机采样,得到一个包含m个样本的采样集。重复t次上诉操作得到t个采样集。
步骤2:对于步骤1得到的t个采样集,用每个采样集训练一个模型,共训练得到t个独立的同质模型。
步骤3:将t个模型对同一个测试样本的输出通过表决器来判定最后结果,对于分类任务通常选取投票数最多的类别作为最后结果,而回归任务则采用简单平均法。
3、基于esnn的电路架构与系统设计
以基于bagging的esnn为基础网络模型,并根据bagging集成学习技术的特点,设计了一种并行的snn电路架构以及bagging计算单元来实现对基于bagging的esnn模型的推理加速。
如图3所示,整个硬件电路架构由输入输出缓存与控制、片上存储器、脉冲神经网络流水线、bagging计算单元四个部分组成。输入输出缓存与控制部分负责对来自外部io外设或总线的输入数据进行缓存和复用,解决跨时钟域的数据处理问题。架构的核心电路是多个并行的二元脉冲神经网络计算流水线,每个流水线负责一个二元snn模型的计算。每个计算流水线内部由多个级联的计算阵列构成,每个计算阵列负责计算相应位置的网络宏层,计算阵列内部包含多个并行的计算单元,分别实现不同卷积核的运算。片上存储器用来存储所有snn模型的参数以及中间计算结果,由于采用了数据流式的计算架构,使得只需要存储每个子模块的少部分中间输出结果即可通过数据复用和计算单元的复用来实现宽度较深的网络计算。bagging计算单元用以实现对并行流水线的输出结果进行聚合然后表决出最后结果。整个硬件电路采用基于数据流的全流水近存计算架构,输入数据经流所有的计算流水线都不需要多余的控制指令,所有的内存访问都是发生在片内且参数读取与数据严格同步,具有很强的可扩展性和能效表现。
每个计算阵列负责snn模型中一个宏层的计算,通常包括二元脉冲卷积层、批量归一化层、非线性激活层以及池化层。计算阵列中并行的计算单元(processingelement,pe)是核心计算部件,其内部架构如图4所示。计算单元由脉冲信号缓存模块、脉冲卷积模块、存储器以及控制器组成。脉冲信号缓存模块由k×ni×ri的寄存器阵列组成,用来缓存输入的脉冲信号。若卷积核大小为k×k,每个行数据块长度为ri,当k个行数据块缓存完成后,便能每个时钟从中提取出一次脉冲卷积运算所需的滑动窗口的数据。而ni是计算单元一次可以计算的数据通道数。脉冲卷积单元可以实现二元脉冲信号的卷积运算,移位器可以实现多个有权二元脉冲神经元的组合运算,由于计算单元的高复用性,因此需用累加器进行多次复用计算后的结果累加。阈值计算与池化单元负责进行批量归一化(batchnormalization)、非线性阈值激活(activation)和池化(pooling)运算。采用归一化和激活函数结合的方式,将归一化层的参数和神经元的偏置合并为神经元的阈值电压,利用一个加法器实现神经元输出电压的阈值比较并根据输出电压的符号产生脉冲信号,最后根据模型的需要进行池化运算。
(1)本发明建立了并行多网络的二元snn算法模型框架,把ensemblelearning引入进脉冲神经网络中,利用多模型优势降低了模型方差,从而改善了模型过拟合状况,提升了整体性能。图5所示是一个每层神经元数目为128的3层感知机(multilayerperceptron,mlp)模型,在集成了1-8个网络时的性能提升表现。
(2)针对算法模型提出的电路架构具有全流水、内存访问少的工作特点,而且由于二元脉冲信号的数据计算机制,极大地提高了电路架构的能效。与cpu、gpu等通用平台,以及主流的二值神经网络硬件架构相比,本发明提出的架构在能效上分别提升了605倍、25倍、7%、91%,如表1所示。
表1本架构能效表
(3)多模型机制的硬件电路架构为模型性能和电路能效提供了一种很好的平衡,既可以在保证高能效的同时通过适当的增加并行流水线数量来有效地提升模型性能,也可以压缩流水线而取得更为出色的电路能效表现,在需要同时兼顾性能和功耗的ai边缘计算大行其道的今天,具有非常好的应用价值和推广前景。
如图6所示,本发明可应用于智能机器人、小型无人机跟踪识别平台等对性能和功耗都有较高要求的ai边缘计算领域。无人机上的机载处理器集成了通用处理器和神经网络计算单元,通用处理器完成可见光、红外传感器等视觉传感器的数据融合以及预处理,然后利用基于集成学习的脉冲神经网络计算单元进行信号处理及模式识别,处理器根据处理识别结果向无人机的飞控系统发出相应的高层动作指令,由飞行控制器直接控制伺服电机,从而实现对机器人的智能视觉导航、避障、及控制。无人机系统近年来在城市消防、交通监测等领域得到了愈加广泛的应用,但由于城市环境的复杂,对无人机平台的ai实时处理性能、功耗等各方面都有着相当严苛的要求,而本发明提出的高效能集成学习脉冲神经网络电路架构为无人机在更多智能计算领域的应用提供了更好的选择。
应当指出,以上所述具体实施方式可以使本领域的技术人员更全面地理解本发明创造,但不以任何方式限制本发明创造。因此,尽管本说明书参照附图和实施例对本发明创造已经进行了详细的说明,但是本领域人员应当理解,仍然可以对本发明创造进行修改或等同替换,而不脱离本发明技术方案的宗旨和范围,其均应涵盖在本发明专利的权利要求范围当中。
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。