基于无监督学习的屏幕图像去摩尔纹方法与流程
本发明属于计算机视觉领域,涉及拍屏图像摩尔纹去除的方法,具体讲,涉及基于无监督学习的屏幕图像去摩尔纹方法。
背景技术:
摩尔纹是指两个不同频率的阵列混叠在一起时产生的不规则条纹。当用数码相机拍摄数字显示设备时,相机感光元件和显示设备之间产生混叠,便很容易出现严重影响拍摄图像质量的摩尔纹。由于其形状不规则、颜色多样、密度各异,摩尔纹很难被去除。
现有的去除拍屏图像中摩尔纹的方法主要可以分为两类。一类是使用传统方法,通过利用摩尔纹的空间和频率特性,通过在yuv和rgb上联合处理,进而去除摩尔纹。但是这类方法一般只能去除频率较高的摩尔纹,而且很容易造成图像细节过模糊。
另一类方法是使用卷积神经网络(cnn)来直接学习摩尔纹图像到对应的干净图像之间的映射。然而,这类方法需要大量的成对并严格对齐的带摩尔纹的图片和干净图片来训练网络,而且它们并不能很好地处理拍摄过程中造成的亮度和对比度的畸变。
技术实现要素:
为克服现有技术的不足,本发明旨在提出更为普适性且方便训练的基于无监督学习的去摩尔纹方法。为此,本发明采取的技术方案是,基于无监督学习的屏幕图像去摩尔纹方法,使用不成对的带摩尔纹的图片以及无摩尔纹图片作为输入,通过训练,使网络学习由摩尔纹图像到干净图像之间的映射关系,最终实现输入摩尔纹图片,网络对摩尔纹实现去除,输出相应无摩尔纹图片。
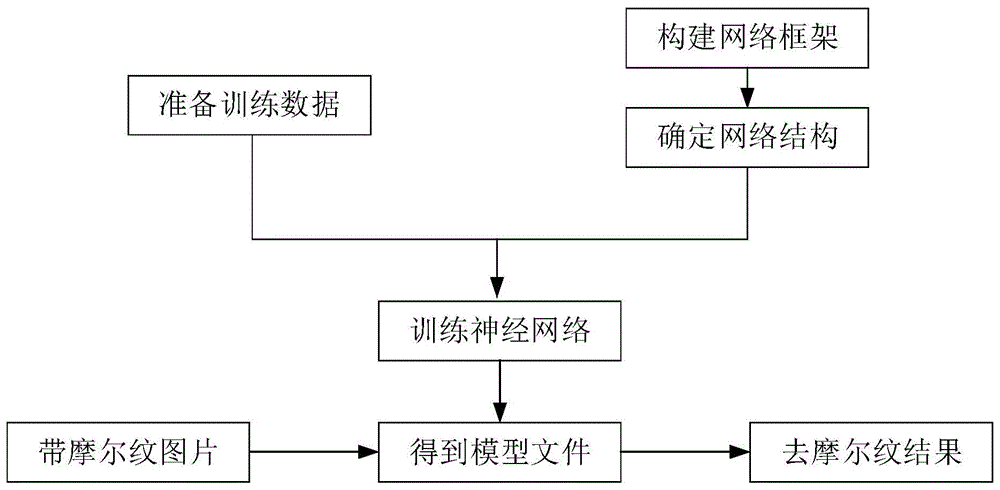
具体步骤如下:
1)分析摩尔纹特征,建立拍屏图像中摩尔纹模型:
im=ic+imc(1)
im为拍屏得到的带摩尔纹的图像,ic是被拍摄的原始图像,imc是摩尔纹层;
2)建立训练数据集
用不同的手机去拍摄展示在不同型号的显示设备上的文字、网页、人物照片、风景照;并将最终得到的带摩尔纹图和原始展示的图像或截屏图像切成图像块用于神经网络的训练;
3)设计网络框架
31)将带摩尔纹图像im输入到干净图像生成器
其中ψi表示经过预训练的vgg-19网络,这里选用第2、7、12、21、30层的输出特征图;
32)将干净图像ic输入到去摩尔纹生成器
其中cos(x,y)表示x和y的余弦相似度。
33)用输入的摩尔纹图像im减去去摩尔纹之后的结果
其中ψj表示经过预训练的vgg-19网络,这里选用第30层的输出特征图。
34)使用两组尺度不同的判别器
其中m和c分别指摩尔纹图像数据集和干净图像数据集;
35)训练判别器时使用的损失函数选用
训练小尺度判别器的损失函数和大尺度损失函数定义相同;
4)设计网络结构
41)生成器
42)大尺度判别器
5)设置好网络的学习率和各部分损失函数的权重,利用深度学习框架pytorch训练上述卷积神经网络,直到损失收敛,生成训练模型;
6)将带有摩尔纹的图片输入到网络中得到对应的去摩尔纹之后的干净图。
步骤5)的具体步骤是:
51)确定网络结构之后,将训练数据输入到网络;
52)在网络训练阶段,学习率设置为0.0002,权重λ1,λ2,λ3,λ4分别设置为10,1,2,2;
53)进行训练,得到摩尔纹图像和去掉摩尔纹的干净图像之间的映射关系。
本发明的特点及有益效果是:
本发明方法针对拍屏图像中的摩尔纹去除,通过无监督学习,得到摩尔纹图像与干净图像之间的映射,有效地去除了摩尔纹,本发明具有以下特点:
1.通过提出无监督学习方法,避免了其他深度学习方法中需要大量严格成对数据的难题。
2.通过精心设计的损失函数,使得去除摩尔纹的同时很好地保留图像的细节信息。
3.通过直接建立摩尔纹图像和干净图像之间的映射,使得在去摩尔纹的同时很好地修正了亮度和对比度畸变。
附图说明:
图1是算法流程图;
图2是网络框架图;
图3是本发明的输入和输出:输入是(a)带摩尔纹图像,输出是(b)去摩尔纹之后的图像。
图4是各个方法的结果比较。(a)为带摩尔纹图像,(b)是传统方法ldpc去除摩尔纹之后的结果,(c)是深度学习方法mr-cnn去除摩尔纹之后的结果,(d)是本发明的方法去除摩尔纹之后的结果。
具体实施方式
本发明通过基于无监督学习的方法,使用不成对的带摩尔纹的图片以及直接下载或截屏得到的干净图片作为输入。通过训练,使网络学习由摩尔纹图像到干净图像之间的映射关系。最终实现输入摩尔纹图片,网络对摩尔纹实现去除,输出相应干净图片。
为克服现有技术的不足,本发明旨在提供更为普适性且方便训练的基于无监督学习的去摩尔纹方法。步骤如下:
1)分析摩尔纹特征,建立拍屏图像中摩尔纹模型:
im=ic+imc(1)
简单来说,拍屏图像中的摩尔纹可以看成是一种复杂的加性噪声,这种噪声和拍摄的角度以及相机镜头的参数有关。方程(1)中,im为拍屏得到的带摩尔纹的图像,ic是被拍摄的原始图像,imc是摩尔纹层。
2)建立训练数据集
用不同的手机去拍摄展示在不同型号的显示设备上的文字、网页、人物照片、风景照等。并将最终得到的带摩尔纹图和原始展示的图像或截屏图像切成256*256的图像块用于神经网络的训练。
3)设计网络框架
31)将带摩尔纹图像im输入到干净图像生成器
其中ψi表示经过预训练的vgg-19网络,这里选用第2、7、12、21、30层的输出特征图。
32)将干净图像ic输入到去摩尔纹生成器
其中cos(x,y)表示x和y的余弦相似度。
33)用输入的摩尔纹图像im减去去摩尔纹之后的结果
其中ψj表示经过预训练的vgg-19网络,这里选用第30层的输出特征图。
34)使用两组尺度不同的判别器
其中m和c分别指摩尔纹图像数据集和干净图像数据集。
35)训练判别器时使用的损失函数选用
训练小尺度判别器的损失函数和大尺度损失函数定义相同。
4)设计网络结构
41)生成器
42)大尺度判别器
5)设置好网络的学习率和各部分损失函数的权重,利用深度学习框架pytorch训练上述卷积神经网络,直到损失收敛,生成训练模型。
6)将带有摩尔纹的图片输入到网络中得到对应的去摩尔纹之后的干净图。
步骤5)的具体步骤是:
51)确定网络结构之后,将训练数据输入到网络;
52)在网络训练阶段,学习率设置为0.0002,权重λ1,λ2,λ3,λ4分别设置为10,1,2,2;
53)进行训练,得到摩尔纹图像和去掉摩尔纹的干净图像之间的映射关系。
下面结合附图和具体实施例进一步详细说明本发明。
本发明采用如下技术方案:
1)分析摩尔纹特征,建立拍屏图像中摩尔纹模型:
im=ic+imc(1)
简单来说,拍屏图像中的摩尔纹可以看成是一种复杂的加性噪声,这种噪声和拍摄的角度以及相机镜头的参数有关。方程(1)中,im为拍屏得到的带摩尔纹的图像,ic是被拍摄的原始图像,imc是摩尔纹层。
2)建立训练数据集
用不同的手机去拍摄展示在不同型号的显示设备上的文字、网页、人物照片、风景照等。并将最终得到的带摩尔纹图和原始展示的图像或截屏图像切成256*256的图像块用于神经网络的训练。
3)设计网络框架
31)将带摩尔纹图像im输入到干净图像生成器
其中ψi表示经过预训练的vgg-19网络,这里选用第2、7、12、21、30层的输出特征图。
32)将干净图像ic输入到去摩尔纹生成器
其中cos(x,y)表示x和y的余弦相似度。
33)用输入的摩尔纹图像im减去去摩尔纹之后的结果
其中ψj表示经过预训练的vgg-19网络,这里选用第30层的输出特征图。
34)使用两组尺度不同的判别器
其中m和c分别指摩尔纹图像数据集和干净图像数据集。
35)训练判别器时使用的损失函数选用
训练小尺度判别器的损失函数和大尺度损失函数定义相同。
4)设计网络结构
41)生成器
42)大尺度判别器
5)设置好网络的学习率和各部分损失函数的权重,利用深度学习框架pytorch训练上述卷积神经网络,直到损失收敛,生成训练模型。
6)将带有摩尔纹的图片输入到网络中得到对应的去摩尔纹之后的干净图。
步骤5)的具体步骤是:
51)确定网络结构之后,将训练数据输入到网络;
52)在网络训练阶段,学习率设置为0.0002,权重λ1,λ2,λ3,λ4分别设置为10,1,2,2;
53)进行训练,得到摩尔纹图像和去掉摩尔纹的干净图像之间的映射关系。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!