一种基于大数据模型的餐饮油烟预测方法与流程
本发明涉及一种大数据技术领域,特别是涉及一种基于大数据模型的餐饮油烟预测方法。
背景技术:
餐饮业产生的大气污染物以油烟气的形式排入环境,根据其形态一般可分为颗粒物质和气体物质两类。其中,油烟颗粒物主要来源于烹饪过程中油脂的挥发凝结以及油脂食材的分解、裂解等,统称油烟;气体物质主要指挥发性有机物,即vocs,可促进大气oh自由基、o3和二次有机气溶胶的生成,从而导致光化学烟雾污染事件的发生。同时,餐饮油烟排放口vocs的浓度可达环境背景值的2~9倍,说明餐饮油烟vocs浓度较高,严重影响周围环境,餐饮油烟排放vocs还是油烟产生强烈刺激气味的主要原因,对周边居民生活产生直接干扰。
为了能较为全面、直接的摸清区域内餐饮行业基本情况,了解污染源的数量、结构和分布状况,专项调查是常用、有效的方式,但是也存在以下几点问题:
(1)人力、物力、财力消耗大
以专项调查的方式进行全方位摸索,所耗人力、物力、财力巨大,时间周期也相对较长,比如:我们要通过排放因子法计算该餐饮单位的vocs排放量,必须先获得其燃料类型、使用量、用油量,而此类数据的获取并没有专门的渠道,获取难度较大。
(2)数据更新性能差,可持续性不强
随着经济发展,餐饮行业变化波动较大,包括污染物处理技术的提升等均会对污染物排放量产生直接影响,因此某一次的专项调查结果无法具备较强的代表性,可持续性不强。因此,如何便捷、低耗的解决核心数据的获取问题,是破解难题的关键所在。
技术实现要素:
本发明旨在至少解决现有技术中存在的技术问题,特别创新地提出了一种基于大数据模型的餐饮油烟预测方法。
为了实现本发明的上述目的,本发明提供了一种基于大数据模型的餐饮油烟预测方法,包括以下步骤:
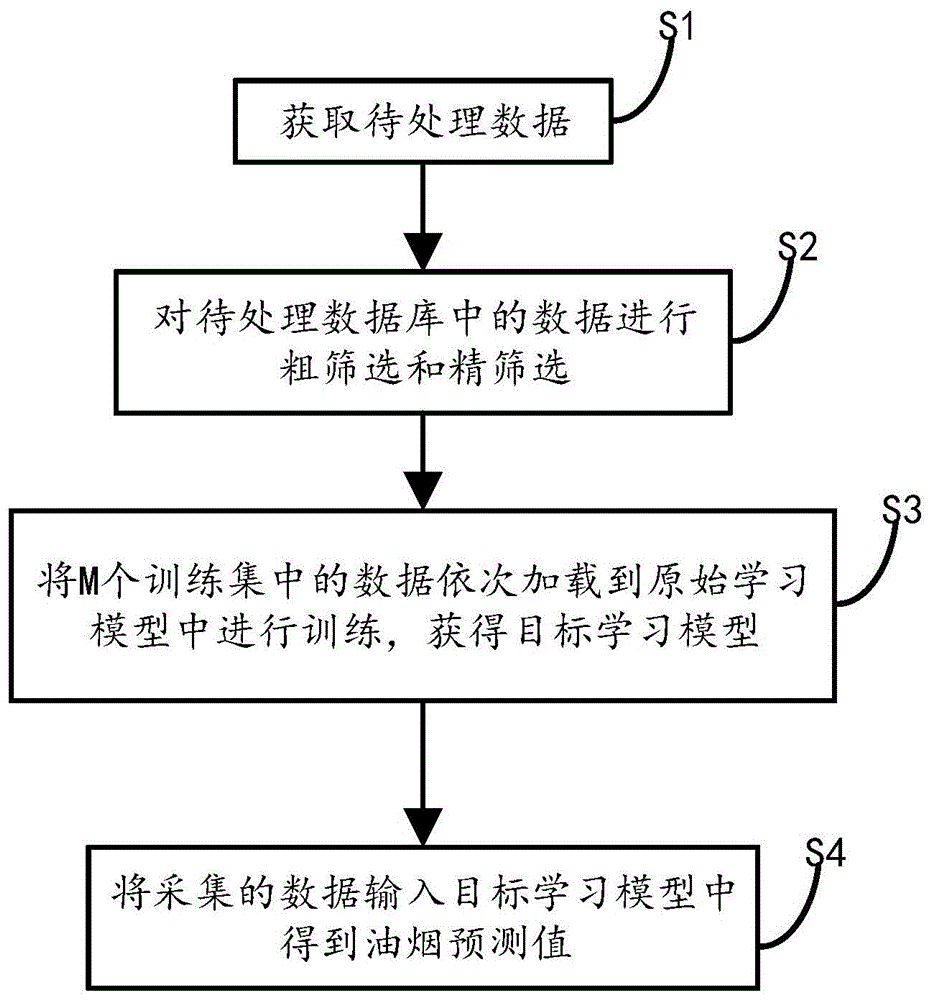
s1,获取待处理数据,将获取的待处理数据形成待处理数据库;
s2,对待处理数据库中的数据进行粗筛选和精筛选,将筛选出的异常数据排除于待处理数据库;得到处理数据库;
s3,将处理数据库中的数据划分为m个训练集和n个测试集;所述m、n为大于或者等于1的正整数,将m个训练集中的数据依次加载到原始学习模型中进行训练,获得目标学习模型;
s4,将采集的数据输入目标学习模型中得到油烟预测值。
在本发明的一种优选实施方式中,在步骤s2中,数据粗筛方法为:
其中,∑-1表示∑的逆矩阵,|∑|表示协方差矩阵的行列式值,μ表示方差;x=x1,x2,x3,…,xk;(x-μ)t为(x-μ)的转置矩阵;
exp(q)表示以自然底数e为底数,q为指数的指数函数;
xl表示在定量化数据库中,数据类型序号排序为l的数据;所述l为小于或者等于k的正整数;
其中,p为预设异常数据阈值;
不满足不等式的数据列为异常数据点,将异常数据排除于待处理数据库。
在本发明的一种优选实施方式中,在步骤s2中,数据精筛的方法为:
s21,解析定量化数据库中的数据文件;
s22,计算每个点与其他所有点之间的欧几里德距离,计算每个点的k-距离值;
s23,对所有点的k-距离集合进行升序排序,输出排序后的k-距离值;
s24,将所有点的k-距离值,在excel中用散点图显示k-距离变化趋势;
s25,根据散点图确定半径eps的值;
s26,根据给定最少点的数量minpts,以及半径eps的值,计算所有核心点,并建立核心点与到核心点距离小于半径eps的点的映射;
s27,根据得到的核心点集合,以及半径eps的值,计算能够连通的核心点,得到噪声点;该噪声点即为异常数据;将噪声点排除于待处理数据库。
在本发明的一种优选实施方式中,在步骤s2中,m个训练集分别为第1训练集、第2训练集、第3训练集、……、第m训练集,n个测试集分别为第1测试集、第2测试集、第3测试集、……、第n测试集,({a1,a2,a3,…,am}∪{b1,b2,b3,…,bn})=c,ai表示第i训练集,所述i为小于或者等于m的正整数,bj表示第j测试集,所述j为小于或者等于n的正整数,c表示处理数据库。
在本发明的一种优选实施方式中,在步骤s3中,原始学习模型为随机森林、lightgbm、xgboost、catboost之一或者任意组合。
在本发明的一种优选实施方式中,还包括步骤s5,
s5,若油烟预测值大于或者等于预设油烟阈值,则云端服务器向智能终端发送报警区域。
在本发明的一种优选实施方式中,在步骤s1中,所述待处理数据包括每家餐饮单位属性,所述餐饮单位属性包括注册资金,注册资金的单位为万元,经营面积,经营面积的单位为平方米,年纳税额,年纳税额的单位为万元,固定灶头数,移动灶头数,平均营业时长,平均营业时长的单位为时,平均每天食堂就餐人数,平均每天食堂就餐人数的单位为人,堂食人均消费,堂食人均消费的单位为元,餐饮类型,主要加工方式,燃料类型,油烟净化设备数,油烟净化设备类型,月份,当月用水,当月燃料,当月用油之一或者任意组合。
在本发明的一种优选实施方式中,从待处理数据库中筛选出定量化数据,所述定量化数据包括经营面积,经营面积的单位为平方米,平均营业时长,平均营业时长的单位为时,平均每天食堂就餐人数,平均每天食堂就餐人数的单位为人,当月用水,当月燃料,当月用油之一或者任意组合。
综上所述,由于采用了上述技术方案,本发明能够对餐饮行业使用的水电气等数据通过目标学习模型得到餐饮用油量,进而对油烟进行预测。
本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
图1是本发明流程示意图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
本发明提供了一种基于大数据模型的餐饮油烟预测方法,如图1所示,包括以下步骤:
s1,获取待处理数据,将获取的待处理数据形成待处理数据库;
s2,对待处理数据库中的数据进行粗筛选和精筛选,将筛选出的异常数据排除于待处理数据库;得到处理数据库;
s3,将处理数据库中的数据划分为m个训练集和n个测试集;所述m、n为大于或者等于1的正整数,将m个训练集中的数据依次加载到原始学习模型中进行训练,获得目标学习模型;
s4,将采集的数据输入目标学习模型中得到油烟预测值。
在本发明的一种优选实施方式中,在步骤s2中,数据粗筛方法为:
其中,k表示定量化数据库中数据类型的总个数;
∑表示协方差矩阵,∑-1表示∑的逆矩阵,|∑|表示协方差矩阵的行列式值,μ表示方差;x=x1,x2,x3,…,xk;(x-μ)t为(x-μ)的转置矩阵;
exp(q)表示以自然底数e为底数,q为指数的指数函数;
xl表示在定量化数据库中,数据类型序号排序为l的数据;所述l为小于或者等于k的正整数;
其中,p为预设异常数据阈值;
不满足不等式的数据列为异常数据点,将异常数据排除于待处理数据库。
在本发明的一种优选实施方式中,在步骤s2中,数据精筛的方法为:
s21,解析定量化数据库中的数据文件;
s22,计算每个点与其他所有点之间的欧几里德距离,计算每个点的k-距离值;
s23,对所有点的k-距离集合进行升序排序,输出排序后的k-距离值;
s24,将所有点的k-距离值,在excel中用散点图显示k-距离变化趋势;
s25,根据散点图确定半径eps的值;
s26,根据给定最少点的数量minpts,以及半径eps的值,计算所有核心点,并建立核心点与到核心点距离小于半径eps的点的映射;
s27,根据得到的核心点集合,以及半径eps的值,计算能够连通的核心点,得到噪声点;该噪声点即为异常数据;将噪声点排除于待处理数据库。
在本发明的一种优选实施方式中,在步骤s2中,m个训练集分别为第1训练集、第2训练集、第3训练集、……、第m训练集,n个测试集分别为第1测试集、第2测试集、第3测试集、……、第n测试集,({a1,a2,a3,…,am}∪{b1,b2,b3,…,bn})=c,ai表示第i训练集,所述i为小于或者等于m的正整数,bj表示第j测试集,所述j为小于或者等于n的正整数,c表示处理数据库。
在本发明的一种优选实施方式中,在步骤s3中,原始学习模型为随机森林、lightgbm、xgboost、catboost之一或者任意组合。
在本发明的一种优选实施方式中,还包括步骤s5,
s5,若油烟预测值大于或者等于预设油烟阈值,则云端服务器向智能终端发送报警区域。
在本发明的一种优选实施方式中,在步骤s1中,所述待处理数据包括每家餐饮单位属性,所述餐饮单位属性包括注册资金,注册资金的单位为万元,经营面积,经营面积的单位为平方米,年纳税额,年纳税额的单位为万元,固定灶头数,移动灶头数,平均营业时长,平均营业时长的单位为时,平均每天食堂就餐人数,平均每天食堂就餐人数的单位为人,堂食人均消费,堂食人均消费的单位为元,餐饮类型,主要加工方式,燃料类型,油烟净化设备数,油烟净化设备类型,月份,当月用水,当月燃料,当月用油之一或者任意组合。
在本发明的一种优选实施方式中,从待处理数据库中筛选出定量化数据,所述定量化数据包括经营面积,经营面积的单位为平方米,平均营业时长,平均营业时长的单位为时,平均每天食堂就餐人数,平均每天食堂就餐人数的单位为人,当月用水,当月燃料,当月用油之一或者任意组合。
在本发明的一种优选实施方式中,还包括分析各类污染物的计算方法,各类污染物的计算方法为:ei=efi×ai×(1-η),其中:ei为第i种污染源vocs排放量;efi为第i种污染源vocs产污系数;ai为第i种污染源涉及vocs产生的活动水平;η为第i种污染源对象的vocs处理效率,无处理设施则为0。
尽管已经示出和描述了本发明的实施例,本领域的普通技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!