权利要求书的元件名词及元件名词所属位置自动得出设备的制作方法
1.本发明涉及一种元件名词及元件名词所属位置的自动得出设备,特别是涉及一种对于无字间空格语言文字权利要求书的元件名词及元件名词所属位置自动得出设备。
背景技术:
2.专利说明书有其复杂性而并不容易阅读。通过人工智能辨识出专利权利要求中的元件名词为人工智能专利助读系统的基础。所谓元件名词,是指专利权利要求中构成元件的定义字,该元件名词并不只是名词,而是以名词字为最终字,而由包含形容词、动词、副词或名词所构成的定义字,例如,“接收天线”、“信号发送机构”等。通过得出专利权利要求的元件名词,可得出该元件名词的所属位置,因此而可更明确得出对应于该元件名词的动作特征、连接关系或位置关系的对应位置,以明确协助专利阅读者更了解该专利权利要求的技术特征。
3.然而,对于无字间空格语言文字,例如亚洲语言,包含中文、日文或韩文,由于字与字之间并无空格,因此相较于英文,该无字间空格语言文字较难辨识出字与字之间的组合,因此较难得出各种组合后的字词。在此困难下,难以实现自然语言的词性分析。虽然有人提出建立元件名词词库的设备,以词性进行元件名词的辨识,但是专利权利要求的元件名词有各种可能的变化,无法建立如此庞大数量的元件名词数据库,常常存在对动词、名词、形容词、副词等的误判。再者,即使可建立出此庞大数量的元件名词词库,进行如此巨大数据库的数据比对装置将非常费时,因此难以实施。
4.因此,关于如何以高效率、正确地自动得出权利要求书的元件名词;即如何以不需建立元件名词数据库的方式且不以词性进行元件名词的判断,而是根据专利权利要求的撰写格式以及特性,在不需花费庞大系统计算及储存资源的情况下,有效率的得出数量最多、准确度最高、得出速度最快的设备,成为一个课题。
技术实现要素:
5.本发明的目的即在提供一种对于无字间空格语言文字权利要求书的元件名词及元件名词所属位置自动得出设备,不需建立元件名词数据库的方式且不以词性进行元件名词的判断,以不可能为元件名词的文字位置逐步排除的方式而最终得出元件名词,如此可有效率的得出数量最多、准确度最高、得出速度最快的权利要求书的元件名词及元件名词所属位置。
6.本发明为解决现有技术的问题所采用的技术手段为提供一种对于无字间空格语言文字权利要求书的元件名词及元件名词所属位置自动得出设备,其主要特点是,是对于以无字间空格语言文字构成的无字间空格语言文字权利要求书予以自动得出权利要求书的各个所得出元件名词及所得出元件名词所属位置,该元件名词及元件名词所属位置自动得出设备包含:基本排除文字纪录排除装置,自动读取该无字间空格语言文字权利要求书文字c-text,并根据基本排除文字库中的数个基本排除文字而自该无字间空格语言文字权
利要求书文字c-text中将该基本排除文字予以记录为排除,而使该无字间空格语言文字权利要求书文字c-text中经排除该基本排除文字后的连续文字作为基本排除文字连续文字;可删文字纪录排除装置,为自动读取多数个该基本排除文字连续文字,并根据可删文字删去规则而自各个该基本排除文字连续文字中将可删文字予以记录为排除,该可删文字删去规则为自基本排除文字连续文字中将该可删文字删去规则定义的特定排除文字予以作为该可删文字而予以记录为排除且/或将该特定排除文字的相邻文字或相邻连续文字予以作为该可删文字而予以记录为排除,而使该基本排除文字排除连续文字中经排除该可删文字后的连续文字作为可删文字删去连续文字;单个文字纪录排除装置,为自动读取多数个该可删文字删去连续文字,并将仅具有单个文字的可删文字删去连续文字予以记录为排除,使经排除该单个文字后的可删文字删去连续文字作为初步元件名词;以及进阶排除文字纪录排除装置,为自动读取多数个该初步元件名词,并根据进阶排除文字库中的数个进阶排除文字而自各个该初步元件名词中将该进阶排除文字予以记录为排除,而使该初步元件名词中经排除该进阶排除文字后的连续文字作为该所得出元件名词。
7.在本发明的一实施例中提供一种所述的元件名词及元件名词所属位置自动得出设备,其中该可删文字纪录排除装置还包括首部文字记录排除装置,该首部文字记录排除装置为自动读取多数个该基本排除文字连续文字,并根据首部删去规则定义的可删识别文字,以判断各个该基本排除文字连续文字的起始文字或起始连续文字是否具有该可删识别文字并予以作为对应可删识别文字,以将该对应可删识别文字和/或该对应可删识别文字之后的指定字数文字予以作为首部删去文字而记录为排除、或判断各个该基本排除文字连续文字的起始文字的相邻前文字或相邻前连续文字是否具有该可删识别文字并予以作为对应可删识别文字以将该起始文字之后的指定字数文字予以作为首部删去文字而记录为排除,由此使该基本排除文字排除连续文字中经排除该首部删去文字后的连续文字作为该可删文字删去连续文字。
8.在本发明的一实施例中提供一种所述的元件名词及元件名词所属位置自动得出设备,其中该可删文字纪录排除装置还包括尾部文字记录排除装置,该尾部文字记录排除装置自动读取多数个该基本排除文字连续文字,并根据尾部删去规则所定义之一可删识别文字,以判断各个该基本排除文字连续文字的最终文字或最终连续文字是否具有该可删识别文字并予以作为对应可删识别文字以将该对应可删识别文字和/或该对应可删识别文字之前的指定字数文字予以作为尾部删去文字而记录为排除、或判断各个该基本排除文字连续文字的最终文字的相邻后文字或相邻后连续文字是否具有该可删识别文字并予以作为对应可删识别文字以将该最终文字之前的指定字数文字予以作为尾部删去文字而记录为排除,由此而使该基本排除文字排除连续文字中经排除该首部删去文字后的连续文字作为该可删文字删去连续文字。
9.在本发明的一实施例中提供一种所述的元件名词及元件名词所属位置自动得出设备,该进阶排除文字纪录排除装置还包括细部元件名词得出装置,该细部元件名词得出装置将为与“一”后相邻的该所得出元件名词与为与“该”后相邻的该所得出元件名词比对,当比对吻合时,则确定与“该”后相邻的该所得出元件名词为细部元件名词而作为该所得出元件名词。
10.在本发明的一实施例中提供一种所述的元件名词及元件名词所属位置自动得出
设备,根据各个所得出元件名词、各个所得出元件名词的所得出元件名词所属位置、标点符号及换行符号得出该无字间空格语言文字权利要求书的架构。
11.本发明为解决现有技术的问题所采用的另一技术手段涉及一种对于无字间空格语言文字权利要求书文字c-text的元件名词及元件名词所属位置自动得出设备,其主要特征是,是对于以无字间空格语言文字构成的无字间空格语言文字权利要求书文字c-text予以自动得出所得出元件名词及所得出元件名词所属位置,该元件名词及元件名词所属位置自动得出设备包含:元件对照表元件名词记录排除装置,该元件对照表元件名词记录排除装置为自动读取该无字间空格语言文字权利要求书文字c-text,并根据元件名词对照表中的元件对照表元件名词,自该无字间空格语言文字权利要求书文字c-text中将该元件对照表元件名词予以记录为排除,使该无字间空格语言文字权利要求书文字c-text中经排除该元件对照表元件名词后的连续文字作为元件对照表元件名词排除连续文字;基本排除文字记录排除装置,为自动读取该元件对照表元件名词排除连续文字,并根据基本排除文字库中的数个基本排除文字,自该元件对照表元件名词排除连续文字中将该基本排除文字予以记录为排除,使该元件对照表元件名词排除连续文字中经排除该基本排除文字后的连续文字作为基本排除文字连续文字;可删文字记录排除装置,自动读取多数个该基本排除文字连续文字,并根据可删文字删去规则,自各个该基本排除文字连续文字中将可删文字予以记录为排除,该可删文字删去规则为自基本排除文字连续文字中将该可删文字删去规则定义的特定排除文字予以作为该可删文字,并予以记录为排除且/或将该特定排除文字的相邻文字或相邻连续文字予以作为该可删文字而予以记录为排除,使该基本排除文字排除连续文字中经排除该可删文字后的连续文字作为可删文字删去连续文字;单个文字记录排除装置,自动读取多数个该可删文字删去连续文字,并将仅具有单个文字的可删文字删去连续文字予以记录为排除,使经排除该单个文字后的可删文字删去连续文字作为初步元件名词;以及进阶排除文字记录排除装置,自动读取多数个该初步元件名词,并根据进阶排除文字库中的数个进阶排除文字,从各个该初步元件名词中将该进阶排除文字予以记录为排除,使该初步元件名词中经排除该进阶排除文字后的连续文字作为该所得出元件名词。
12.在本发明的另一实施例中提供另一种所述的元件名词及元件名词所属位置自动得出设备,该可删文字纪录排除装置还包括首部文字记录排除装置,该首部文字记录排除装置为自动读取多数个该基本排除文字连续文字,并根据首部删去规则定义的可删识别文字,以判断各个该基本排除文字连续文字的起始文字或起始连续文字是否具有该可删识别文字并予以作为对应可删识别文字以将该对应可删识别文字和/或该对应可删识别文字之后的指定字数文字予以作为首部删去文字而记录为排除、或判断各个该基本排除文字连续文字的起始文字的相邻前文字或相邻前连续文字是否具有该可删识别文字并予以作为对应可删识别文字以将该起始文字之后的指定字数文字予以作为首部删去文字而记录为排除,由此而使该基本排除文字排除连续文字中经排除该首部删去文字后的连续文字作为该可删文字删去连续文字。
13.在本发明的另一实施例中提供另一种所述的元件名词及元件名词所属位置自动得出设备,该可删文字纪录排除装置还包括尾部文字记录排除装置,该尾部文字记录排除装置自动读取多数个该基本排除文字连续文字,并根据尾部删去规则定义可删识别文字,以判断各个该基本排除文字连续文字的最终文字或最终连续文字是否具有该可删识别文
字并予以作为对应可删识别文字以将该对应可删识别文字和/或该对应可删识别文字之前的指定字数文字予以作为尾部删去文字而记录为排除、或判断各个该基本排除文字连续文字的最终文字的相邻后文字或相邻后连续文字是否具有该可删识别文字并予以作为对应可删识别文字以将该最终文字之前的指定字数文字予以作为尾部删去文字而记录为排除,由此使该基本排除文字排除连续文字中经排除该尾部删去文字后的连续文字作为该可删文字删去连续文字。
14.在本发明的另一实施例中提供另一种所述的元件名词及元件名词所属位置自动得出设备,该进阶排除文字纪录排除装置还包括细部元件名词得出装置,该细部元件名词得出装置将为与“一”后相邻的该所得出元件名词与为与“该”后相邻的该所得出元件名词比对,当比对吻合时,则确定与“该”后相邻的该所得出元件名词为细部元件名词作为该所得出元件名词。
15.在本发明的另一实施例中为涉及另一种所述的元件名词及元件名词所属位置自动得出设备,根据各个所得出元件名词、各个所得出元件名词之所得出元件名词所属位置、标点符号及换行符号而得出该无字间空格语言文字权利要求书的架构。
16.采用本发明的对于无字间空格语言文字权利要求书的元件名词及元件名词所属位置自动得出设备,可对于权利要求书的元件名词及元件名词所属位置之自动得出,不需建立元件名词数据库的方式且不以词性进行元件名词的判断,而根据专利权利要求的撰写格式以及特性,以不可能为元件名词的文字位置逐步排除的方式最终得出元件名词,如此在不需花费庞大系统计算及储存资源的情况下,提供可有效率的得出数量多、准确度高、提供速度快的权利要求书的元件名词及元件名词所属位置的自动得出设备。
附图说明
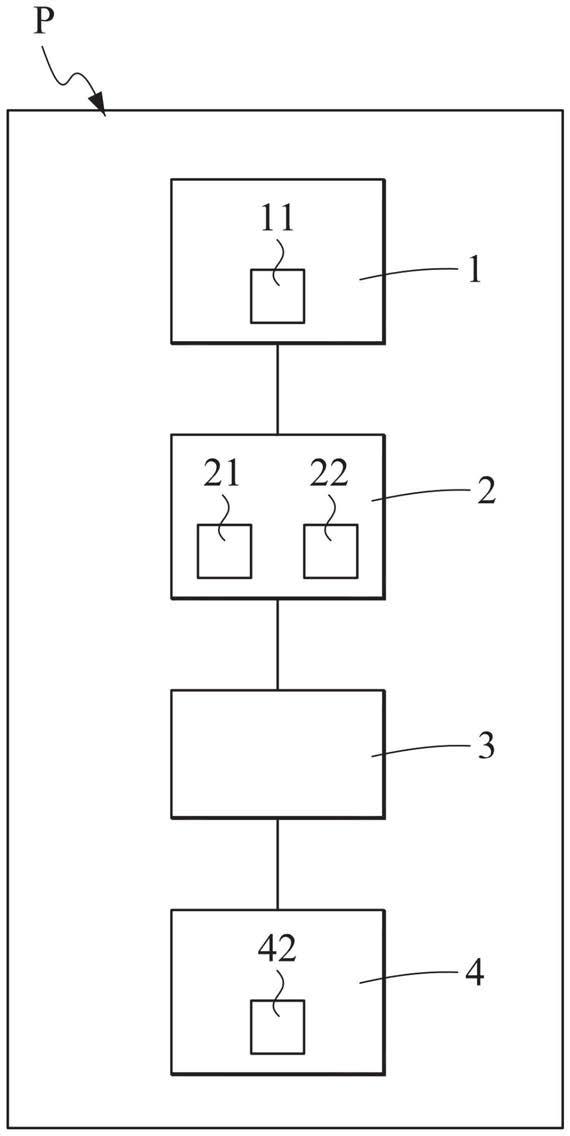
17.图1为显示根据本发明的对于无字间空格语言文字权利要求书的元件名词及元件名词所属位置自动得出设备的一实施例的架构方块示意图。
18.图2为显示当基本排除文字连续文字的起始文字或起始连续文字具有该可删识别文字则将可删识别文字予以作为该对应可删识别文字的示意图。
19.图2b为显示当基本排除文字连续文字的起始文字或起始连续文字具有可删识别文字则将可删识别文字予以作为该对应可删识别文字的另一示意图。
20.图2c为显示判断各个基本排除文字连续文字的起始文字的相邻前文字或相邻前连续文字是否具有可删识别文字并予以作为一对应可删识别文字的示意图。
21.图3a为显示当基本排除文字连续文字的尾部文字或尾部连续文字具有可删识别文字则将可删识别文字予以作为对应可删识别文字的示意图。
22.图3b为显示当基本排除文字连续文字的最终文字或最终连续文字具有可删识别文字则将可删识别文字予以作为对应可删识别文字的示意图。
23.图3c为显示判断各个基本排除文字连续文字的最终文字的相邻前文字或相邻前连续文字是否具有可删识别文字并予以作为对应可删识别文字的示意图。
24.图4为显示根据本发明的对于无字间空格语言文字权利要求书的元件名词及元件名词所属位置自动得出设备的另一实施例的架构方块示意图。
25.附图标记
26.p
ꢀꢀꢀꢀꢀꢀ
元件名词及元件名词所属位置自动得出设备
27.1a
ꢀꢀꢀꢀꢀ
元件对照表元件名词记录排除装置
[0028]1ꢀꢀꢀꢀꢀꢀ
基本排除文字记录排除装置
[0029]
11
ꢀꢀꢀꢀꢀ
基本排除文字库
[0030]2ꢀꢀꢀꢀꢀꢀ
可删文字纪录排除装置
[0031]
21
ꢀꢀꢀꢀꢀ
首部文字删去装置
[0032]
22
ꢀꢀꢀꢀꢀ
对应前相邻字判断装置
[0033]3ꢀꢀꢀꢀꢀꢀ
单个文字纪录排除装置
[0034]4ꢀꢀꢀꢀꢀꢀ
进阶排除文字纪录排除装置
[0035]
42
ꢀꢀꢀꢀꢀ
第二细部元件名词得出装置
[0036]
b
ꢀꢀꢀꢀꢀꢀ
基本排除文字
[0037]
b-text 基本排除文字连续文字
[0038]
sd
ꢀꢀꢀꢀꢀ
特定排除文字
具体实施方式
[0039]
以下根据图1至图4,说明本发明的实施方式。该说明并非为限制本发明的实施方式,而为本发明的实施例的一种。
[0040]
如图1至图3c所示,该元件名词及元件名词所属位置自动得出设备p为对于以一无字间空格语言文字所构成的无字间空格语言文字权利要求书c-text予以自动得出其具有的所得出元件名词em及所得出元件名词所属位置ep,该元件名词及元件名词所属位置自动得出设备p包含:基本排除文字纪录排除装置1,自动读取该无字间空格语言文字权利要求书文字c-text,并根据一基本排除文字库11中的数个基本排除文字b而自该无字间空格语言文字权利要求书文字c-text中将该基本排除文字b予以记录为排除,使该无字间空格语言文字权利要求书文字c-text中经排除该基本排除文字b后的连续文字作为一基本排除文字连续文字b-text。
[0041]
此处的无字间空格语言文字包含:中文、日文或韩文。但本发明并不限于此。
[0042]
详细而言,在该基本排除文字纪录排除装置1中,该基本排除文字库11的基本排除文字b,可包含:“,”;“;”;“:”;“。”;“一”;“该”;“与”;“及”;“且”;“于”;“并”;“至”;“而”;“在”;“中”;“其”;“系”;“之”;“的”;“个”;“从”;“也”;“只”;“和”;“则”;“内,”;“中,”;“下,”;“处,”;“内;”;“中;”;“下;”;“处;”;“内。”;“中。”;“下。”;“处。”;“中之”;“下之”;“内之”;“处之”;“之间”;“时,”;“藉由”;“藉以”;“用以”;“用来”;“作为”;“涉及”;“根据”;“依据”;“包含”;“包括”;“其中”;“来自”;“用于”;“沿着”;“至少”;“具有”;“提供”;“以及”;“至少”;“一种”;“一个”;“复数”;“多个”;“每个”;“下述”;“大于”;“小于”;“等于”;“所述”;“特征”;“上述”;“进行”;“较大”;“较小”;“相同”;“之间,”;“不大于”;“不小于”;“不等于”;“且/或”;“及/或”;“一位于”;“相关的”;“相关的”;“之间的”;“之间的”;“形成在”;“接收到”;“经配置”;“用于提供”;“相关联的”;“特征在于”;“其特征在于”等文字。且该排除方式为:先排除字数较多的基本排除文字,再排除字数较少的基本排除文字。例如,先执行五个字的“其特征在于”基本排除文字,再依序四个字的“用于提供”、“相关联的”、“特征在于”,再执行三个字的“之间,”、“不大于”、“不小于”、“不等于”、“且/或”、“及/或”、“一位于”、“相
关的”、“相关的”、“之间的”、“之间的”、「形成在”、“直接将”、“不需要”、“接收到”、“经配置”,之后再依序执行二个字,最后再执行一个字的基本排除文字。举例来说,无字间空格语言文字权利要求书c-text如下:
[0043]
一种缓冲元件,包含:多层材料,包含隔离层、被设置成与该隔离层邻接的聚合材料层,及被设置成与该隔离层邻接且与其对立的稳定层;多个柱状物,其被设置于该多层材料内,每个该多个柱状物包含厚度,上表面及侧壁,该侧壁为从该上表面并底切该上表面以形成位于该上表面和该侧壁之间的半径化的上缘;多个间隔物区域,其被设置于该多个柱状物之间,每个该多个间隔物区域包含间隔物区域厚度;其中该柱状物厚度大于该间隔物区域厚度。
[0044]
经该基本排除文字纪录排除装置1执行后而为如下(含有下划线的文字为该基本排除文字b):
[0045]
一种缓冲元件,包含:一多层材料,包含一隔离层、一被设置成与该隔离层邻接的聚合材料层,及一被设置成与该隔离层邻接且与其对立的稳定层;多个柱状物,其被设置于该多层材料内,每个该多个柱状物包含一厚度,一上表面及一侧壁,该侧壁为从该上表面并底切该上表面以形成一位于该上表面和该侧壁之间的半径化的上缘;多个间隔物区域,其被设置于该多个柱状物之间,每个该多个间隔物区域包含一间隔物区域厚度;其中该柱状物厚度大于该间隔物区域厚度。
[0046]
本发明为通过将不可能为元件名词的字词予以排除,逐步得出可能的元件名词,上述将该基本排除文字b予以排除即为将不可能为元件名词的字词予以排除的第一步,在本发明的其他装置中为继续对于不可能为元件名词的字词予以记录记录为排除。通过该基本排除文字纪录排除装置1对于该无字间空格语言文字权利要求书文字c-text予以排除数个该基本排除文字b之后所得的结果为数个基本排除文字连续文字b-text,也就是说通过数个该基本排除文字b之分隔而得出未被分隔的连续文字,而每组连续文字称为一组基本排除文字连续文字b-text,因此而得出多组基本排除文字连续文字b-text。以上述例子为例,得出如下的数个基本排除文字连续文字b-text(亦即,不具有下划线的各别连续文字):“缓冲元件”、“多层材料”、“隔离层”、“被设置成”、“隔离层邻接”、“聚合材料层”、“被设置成”、“隔离层邻接”、“对立”、“稳定层”、“柱状物”、“被设置“、”该多层材料”、“柱状物”、“厚度”、”上表面”、“侧壁”、“侧壁”、“上表面”、“底切”、“上表面”、“形成”、“上表面”、“侧壁”、“半径化”、“上缘”、“间隔物区域”、“被设置”、“柱状物”、“间隔物区域”、“间隔物区域厚度”、“柱状物厚度”、“间隔物区域厚度”。
[0047]
在本发明的一实施例中,为将该基本排除文字b给定特定标示元(例如,bd(basic deleting words))作为该基本排除文字的识别。例如,当该基本排除文字b的该特定标示元为bw,则将被识别出的该基本排除文字予以记录为具有“bw”的特定标示元。此外,并可标记该特定标示字在该无字间空格语言文字权利要求书的起始位置及结束位置,例如,“一种”这个基本排除文字的起始位置为0,结束位置为1。并将该特定标示元、该基本排除文字的内容、该特定标示字的起始位置及结束位置予以记录于内存中,例如记录为(bw,“一种”0,1)。但本发明并不限于上述方式,只要可明确标示该无字间空格语言文字权利要求书中的该基本排除文字及该基本排除文字连续文字的相互之间的位置关系、以及该基本排除文字及该基本排除文字连续文字的内容即可。
[0048]
接着,说明与该基本排除文字纪录排除装置1连接的可删文字纪录排除装置2。该可删文字纪录排除装置2为自动读取数个该基本排除文字连续文字b-text,并根据可删文字删去规则dr(deletion rule)自各个该基本排除文字连续文字b-text中将可删文字d予以记录为排除,该可删文字删去规则dr为自基本排除文字连续文字b-text中将该可删文字删去规则dr定义的特定排除文字sd予以作为该可删文字d而予以记录为排除且/或将该特定排除文字sd的相邻文字或相邻连续文字予以作为该可删文字d而予以记录为排除,使该基本排除文字排除连续文字b-text中经排除该可删文字d后的连续文字作为可删文字删去连续文字d-text。
[0049]
即,如图2a、图2b、图2c、图3a、图3b及图3c所示(所记录为排除的文字以“xx”表示,经找到的该特定排除文字sd以圆圈表示),该可删文字删去规则dr为寻找该基本排除文字连续文字b-text中是否具有该特定排除文字sd(如图2a、图2b、图3a及图3b所示)、或是在相邻于该基本排除文字连续文字b-text的该基本排除文字b中是否具有该特定排除文字sd(如图2c及图3c所示),如果在该基本排除文字连续文字b-text中具有该特定排除文字sd的话(如图2a、图2b、图3a及图3b所示),则将该基本排除文字连续文字b-text中的该特定排除文字sd予以记录为排除(如图2a及图3a所示),或是将该特定排除文字sd连同该特定排除文字sd的相邻文字或相邻连续文字予以作为该可删文字d予以记录为排除(如图2b及图3b所示)。此外,如果在该基本排除文字b中具有该特定排除文字sd(如图2c及图3c所示),则将该基本排除文字连续文字b-text的首部或尾部的特定字数的文字或连续文字予以作为该可删文字d,予以记录为排除。详细来说,该特定排除文字sd为存在于该基本排除文字连续文字b-text之中,或是存在于该基本排除文字连续文字b-text的相邻之外。所谓“存在于该基本排除文字连续文字b-text的相邻之外的特定排除文字sd”是指:该特定排除文字sd并不存在于该基本排除文字连续文字b-text之中,而是存在于该基本排除文字连续文字b-text的前相邻基本排除文字b的尾部或后相邻基本排除文字b的首部中。进一步而言,本发明的该可删文字纪录排除装置2除了对于该基本排除文字连续文字b-text找出该特定排除文字sd之外,并可找出该基本排除文字连续文字b-text的前相邻基本排除文字b的尾部文字、后相邻基本排除文字b的尾部文字、前相邻基本排除文字b的尾部连续文字、或后相邻基本排除文字b的尾部连续文字是否为该特定排除文字sd,如果是的话,则将该基本排除文字连续文字b-text的首部文字、尾部文字、首部连续文字、或尾部连续文字予以取出作为该可删文字d,予以记录排除。
[0050]
以“一被设置成与该隔离层邻接的聚合材料层”中的“一被设置成与”片段为例,其中“一”及“与”为该基本排除文字b,而“被设置成”为该基本排除文字连续文字b-text。当该可删文字删去规则dr中“被设置”被指定为该特定排除文字sd,也就是,该特定排除文字sd为存在于该基本排除文字连续文字b-text之中,因此,将该特定排除文字sd“被设置”予以作为该可删文字,将该可删文“被设置”予以自该基本排除文字连续文字“被设置成”中予以记录排除,形成经排除“被设置”的可删文字删去连续文字“成”。这为图2a的例子。
[0051]
以“将天线耦接于该隔离层的信号发送器”中的“将天线耦接于”片段为例,其中“将”及“于”为该基本排除文字b,而“天线耦接”为该基本排除文字连续文字b-text。当该可删文字删去规则dr中“于”被指定为该特定排除文字sd,也就是,该特定排除文字sd为存在于该基本排除文字连续文字b-text「天线耦接”的外部(尾部)相邻基本排除文字b处(此处,
“
于”已经在该基本排除文字纪录排除装置1中被记录排除,作为该基本排除文字b),且由该可删文字删去规则dr规定为“将在该基本排除文字连续文字的尾部邻接字“于”的前二字予以记录排除”的规则,因此将“于”之前的位在该基本排除文字连续文字b-text的尾部二字“耦接”予以自该基本排除文字连续文字b-text中予以记录排除,而得出“将天线(耦接)于”,其中刮号中为该可删文字纪录排除装置2所记录排除部分(亦即,为该可删文字d),因此,而得出该可删文字删去连续文字d-text“天线”。这为图3c的例子。
[0052]
具体而言,本发明的该可删文字纪录排除装置2进一步具有首部文字记录排除装置21(亦即,如图2a、图2b及图2c所示),该首部文字记录排除装置21为自动读取数个该基本排除文字连续文字b-text,并根据首部删去规则hr定义的可删识别文字iw(identifying word),判断各个该基本排除文字连续文字b-text的起始文字或起始连续文字是否具有该可删识别文字iw并予以作为对应可删识别文字found-iw以将该对应可删识别文字found-iw和/或该对应可删识别文字found-iw之后的指定字数文字予以作为一首部删去文字hd而记录为排除、或判断各个该基本排除文字连续文字b-text的起始文字的相邻前文字或相邻前连续文字是否具有该可删识别文字iw并予以作为对应可删识别文字found-iw以将该起始文字之后的指定字数文字予以作为首部删去文字hd而记录为排除,由此使该基本排除文字排除连续文字b-text中经排除该首部删去文字hd后的连续文字作为该可删文字删去连续文字d-text。
[0053]
该可删文字纪录排除装置2进一步具有尾部文字记录排除装置22如图3a、图3b、图3c,该尾部文字记录排除装置22为自动读取数个该基本排除文字连续文字b-text,并根据尾部删去规则tr所定义的可删识别文字iw,判断各个该基本排除文字连续文字b-text的最终文字或最终连续文字是否具有该可删识别文字iw并予以作为对应可删识别文字found-iw以将该对应可删识别文字found-iw和/或该对应可删识别文字found-iw之前的指定字数文字予以作为尾部删去文字td而记录为排除、或判断各个该基本排除文字连续文字b-text的最终文字的相邻后文字或相邻后连续文字是否具有该可删识别文字iw并予以作为对应可删识别文字found-iw以将该最终文字之前的指定字数文字予以作为尾部删去文字td而记录为排除,由此使该基本排除文字排除连续文字b-text中经排除该尾部删去文字td后的连续文字作为该可删文字删去连续文字d-text。
[0054]
以下说明该首部文字记录排除装置21的一实施例。该首部删去规则hr,如图2a、图2b及图2c所示。
[0055]
在图2a中,是指当该基本排除文字连续文字b-text的起始文字或起始连续文字具有该可删识别文字iw,则将可删识别文字iw予以作为该对应可删识别文字found-iw,以将该对应可删识别文字found-iw予以作为一首部删去文字hd记录为排除。例如,当该首部文字记录排除装置21的该首部删去规则hr定义的可删识别文字iw(identifying word)为:“被设置”、“或”;“被”;“随”;“为”;“将”;“给”(以字数多先执行),则将该些可删识别文字iw自该基本排除文字连续文字b-text的起始处予以记录为排除。
[0056]
在图2b中,是指当该基本排除文字连续文字b-text的起始文字或起始连续文字具有该可删识别文字iw,则将可删识别文字iw予以作为该对应可删识别文字found-iw,以将该对应可删识别文字found-iw以及该对应可删识别文字found-iw之后的指定字数文字予以作为一首部删去文字hd而记录为排除。例如,当该可删识别文字iw为:“分别”;“当前”;
“
将经”;“使经”;“该经”;“且经”;“用以”;“用来”;“用于”;“得到”;“设置”;“配置”;“以上”;“以内”;“利用”;“处于”;“~在”;“~地~”;“未被~”;“可~”(以字数多先执行),则将该些文字暨该些文字之后两个文字予以记录为排除。
[0057]
在图2c中,是判断各个该基本排除文字连续文字b-text的起始文字的相邻前文字或相邻前连续文字(存在于相邻前基本排除文字b中)是否具有该可删识别文字iw并予以作为一对应可删识别文字found-iw以将该起始文字之后的指定字数文字予以作为一首部删去文字hd而记录为排除,由此使该基本排除文字排除连续文字b-text中经排除该首部删去文字hd后的连续文字作为该可删文字删去连续文字d-text。例如,当该基本排除文字连续文字b-text的相邻的前一个文字或相邻前连续文字(此些文字及连续文字已经被纪录为排除)为:用以、用以、用来、用于、彼此等可删识别文字iw,则将该基本排除文字连续文字b-text的起始处后两个文字予以记录为排除。
[0058]
以下说明该尾部文字记录排除装置22的一实施例。该尾部删去规则tr,如图3a、图3b及图3c所示。
[0059]
在图3a,为指当该基本排除文字连续文字b-text的尾部文字或尾部连续文字具有该可删识别文字iw,则将可删识别文字iw予以作为该对应可删识别文字found-iw,以将该对应可删识别文字found-iw予以作为一尾部删去文字td而记录为排除。例如,当该尾部文字记录排除装置21的该尾部删去规则tr定义的可删识别文字iw(identifying word)为:或、成、于、时、来、有、者、对应、相关、连同、之间、邻接、“元件名词+两个字”(以字数多先执行),则将该些可删识别文字iw自该基本排除文字连续文字b-text的尾部处予以记录为排除。
[0060]
在图3b中,为指当该基本排除文字连续文字b-text的最终文字或最终连续文字具有该可删识别文字iw,则将可删识别文字iw予以作为该对应可删识别文字found-iw,以将该对应可删识别文字found-iw以及该对应可删识别文字found-iw之前的指定字数文字予以作为尾部删去文字td而记录为排除。例如,当该可删识别文字iw为:给、到(以字数多先执行)、为,则将该些文字暨该些文字之前两个文字予以记录为排除。
[0061]
在图3c中,为判断各个该基本排除文字连续文字b-text的最终文字的相邻后文字或相邻后连续文字(存在于相邻后基本排除文字b中)是否具有该可删识别文字iw并予以作为一对应可删识别文字found-iw以将该最终文字之前的指定字数文字予以作为尾部删去文字td而记录为排除,由此使该基本排除文字排除连续文字b-text中经排除该尾部删去文字td后的连续文字作为该可删文字删去连续文字d-text。例如,当该基本排除文字连续文字b-text的相邻的后一个文字或相邻后连续文字(此些文字及连续文字已经被纪录为排除)为:该、一、于、在,则将该基本排除文字连续文字b-text的最终处前两个文字予以记录为排除。
[0062]
因此前述例子成为以下,其中由该可删文字纪录排除装置2记录为排除的内容以黑底字表示。
[0063]“一种缓冲元件,包含:一多层材料,包含一隔离层、一被设置成与该隔离层邻接的聚合材料层,及一被设置成与该隔离层邻接且与其对立的稳定层;多个柱状物,其被设置于该多层材料内,每个该多个柱状物包含一厚度,一上表面及一侧壁,该侧壁为从该上表面并底切该上表面以形成一位于该上表面和侧壁之间的半径化的上缘;多个间隔物区域,其被
设置于该多个柱状物之间,每个该多个间隔物区域包含一间隔物区域厚度;其中该柱状物厚度大于该间隔物区域厚度。”。
[0064]
本发明的该元件名词及元件名词所属位置自动得出设备p进一步包含单个文字纪录排除装置3,该单个文字纪录排除装置3连接该可删文字纪录排除装置2,以自动读取数个该可删文字删去连续文字d-text,并将仅具有单个文字sw的可删文字删去连续文字d-text予以记录为排除,使经排除该单个文字sw后的可删文字删去连续文字d-text作为一初步元件名词p-en。
[0065]
因此前述例子成为以下,其中由该单个文字纪录排除装置3记录为排除的内容以字框表示。“一种缓冲元件,包含:一多层材料,包含一隔离层、一被设置与该隔离层邻接的聚合材料层,及一被设置与该隔离层邻接且与其对立的稳定层;多个柱状物,其被设置于该多层材料内,每个该多个柱状物包含一厚度,一上表面及一侧壁,该侧壁为从该上表面并底切该上表面以形成一位于该上表面和该侧壁之间的半径化的上缘;多个间隔物区域,其被设置于该多个柱状物之间,每个该多个间隔物区域包含一间隔物区域厚度;其中该柱状物厚度大于该间隔物区域厚度。”。
[0066]
本发明的该元件名词及元件名词所属位置自动得出设备p进一步包含一进阶排除文字纪录排除装置4,该进阶排除文字纪录排除装置4连接于该单个文字纪录排除装置3以自动读取数个该初步元件名词p-en,并根据一进阶排除文字库al中的数个进阶排除文字ed,从各个该初步元件名词p-en中将该进阶排除文字ed予以记录为排除,使该初步元件名词中p-en经排除该进阶排除文字ed后的连续文字作为该所得出元件名词r-en。
[0067]
详细而言,该进阶排除文字库al中的数个进阶排除文字ed包含:初步元件名词为二个文字且该初步元件名词之前、之后为“于”、“成”、“至”、“在”、“用于”等,则将该初步元件名词予以删除;以及“经xx”(xx代表二个文字)、“为xx”(xx代表二个文字)、“待xx”(xx代表二个文字)、“之间”、“同时”、“实时”、“以上”、“被xx的”(xx代表二个文字)、“xx化”等文字,则将该初步元件名词予以删除。
[0068]
因此前述例子成为以下,其中由该进阶排除文字纪录排除装置4记录为排除的内容以删除线表示。“一种缓冲元件,包含:一多层材料,包含一隔离层、一被设置与该隔离层邻接的聚合材料层,及一被设置与该隔离层邻接且与其对立的稳定层;多个柱状物,其被设置于该多层材料内,每个该多个柱状物包含一厚度,一上表面及一侧壁,该侧壁为从该上表面并底切该上表面以形成一位于该上表面和该侧壁之间的的上缘;多个间隔物区域,其被设置于该多个柱状物之间,每个该多个间隔物区域包含一间隔物区域厚度;其中该柱状物厚度大于该间隔物区域厚度。”。
[0069]
以上未具有任何标号为所得出元件名词(即,本发明所要得出的元件名词),依序包含:缓冲元件、多层材料、隔离层、隔离层、聚合材料层、隔离层、稳定层、柱状物、多层材料、柱状物、厚度、上表面、侧壁、侧壁、上表面、上表面、上表面、侧壁、上缘、间隔物区域、柱状物、间隔物区域、间隔物区域厚度、柱状物厚度、间隔物区域厚度。
[0070]
如图1所示,进一步而言,依据本发明的一实施例的对于无字间空格语言文字权利要求书的元件名词及元件名词所属位置自动得出设备p,其中在该进阶排除文字纪录排除
装置4进一步包含细部元件名词得出装置42,该细部元件名词得出装置42将为与“一”后相邻的该所得出元件名词予以为与“该”后相邻的该所得出元件名词比对,当比对吻合时,则确定与“该”后相邻的该所得出元件名词为细部元件名词而作为该所得出元件名词。通过该方式,确定该所得出元件名词,因此可再次执行该首部删去规则hr中的“元件名词+两个字”的记录为排除,增加元件名词之得出正确度。
[0071]
如图1所示,依据本发明的实施例的对于无字间空格语言文字权利要求书的元件名词及元件名词所属位置自动得出设备p,为根据各个所得出元件名词、各个所得出元件名词的所得出元件名词所属位置、标点符号及换行符号得出该无字间空格语言文字权利要求书的架构。例如,可通过标点符号对于无字间空格语言文字权利要求书进行换行,且将所得出的该所得出元件名词予以标示为可点选,以在点选后可跳至该所得出元件名词位于说明书的位置,由此可更加了解该所得出元件名词的意义。
[0072]
因此前述例子成为以下,其中并进一步将“;”所属区段予以对仗显示,所得出元件名词为以下划线表示。
[0073]
一种缓冲元件,包含:
[0074]
一多层材料,
[0075]
包含一隔离层、
[0076]
一被设置成与该隔离层邻接的聚合材料层,
[0077]
及一被设置成与该隔离层邻接且与其对立的稳定层;
[0078]
多个柱状物,
[0079]
其被设置于该多层材料内,
[0080]
每个该多个柱状物包含一厚度,
[0081]
一上表面及一侧壁,
[0082]
该侧壁为从该上表面并底切该上表面以形成一位于该上表面和该侧壁
[0083]
之间的的上缘;
[0084]
多个间隔物区域,
[0085]
其被设置于该多个柱状物之间,
[0086]
每个该多个间隔物区域包含一间隔物区域厚度;
[0087]
其中该柱状物厚度大于该间隔物区域厚度。
[0088]
本发明除了上述实施例之外,可通过先将元件对照表中所列出的元件名词予以先行于该对于无字间空格语言文字权利要求书文字c-text中找出,再进行该基本排除文字纪录排除装置1中的该基本排除文字连续文字b-text的得出,以增加整体指令周期以及正确性。如图4所示,在本发明的另一实施例,该对于无字间空格语言文字权利要求书文字c-text的元件名词及元件名词所属位置自动得出设备p可另设置元件对照表元件名词记录排除装置1a,该元件对照表元件名词记录排除装置1a连接于该基本排除文字纪录排除装置1该元件对照表元件名词记录排除装置1a为自动读取该无字间空格语言文字权利要求书文字c-text,并根据元件名词对照表en-list中的一元件对照表元件名词list-en而自该无字间空格语言文字权利要求书文字c-text中将该元件对照表元件名词list-en予以记录为排除,而使该无字间空格语言文字权利要求书文字c-text中经排除该元件对照表元件名词list-en后的连续文字作为元件对照表元件名词排除连续文字d-en。得出的该元件对照表
元件名词排除连续文字d-en予以传送至该基本排除文字记录排除装置1,由该基本排除文字记录排除装置1为同样执行上述操作,以自该元件对照表元件名词排除连续文字d-en中将该基本排除文字b予以记录为排除,使该元件对照表元件名词排除连续文字d-en中经排除该基本排除文字b后的连续文字作为基本排除文字连续文字b-text。
[0089]
进一步而言,在先行得出该元件对照表元件名词list-en之后,可在后续的可删文字纪录排除装置2(包含有该首部文字记录排除装置21及该首部文字记录排除装置22)的该可删文字删去规则dr中订定出关于该元件对照表元件名词list-en的规则运算,可增加整体指令周期以及正确性。亦即,该可删文字纪录排除装置2中的该可删文字删去规则dr将该元件对照表元件名词list-en予以纳入为该特定排除文字sd,以自基本排除文字连续文字b-text中将该特定排除文字sd予以作为该可删文字d而予以记录为排除且/或将该特定排除文字sd的相邻文字或相邻连续文字予以作为该可删文字d而予以记录为排除,使该基本排除文字排除连续文字b-text中经排除该可删文字d后的连续文字作为可删文字删去连续文字d-text。
[0090]
具体而言,该可删文字纪录排除装置2的首部文字记录排除装置21为自动读取数个该基本排除文字连续文字b-text,并将该元件对照表元件名词list-en予以纳入为该首部删去规则定义的可删识别文字iw,以除了第一实施例的判断之外,再根据该元件对照表元件名词list-en,判断各个该基本排除文字连续文字b-text的起始文字的相邻前文字或相邻前连续文字是否具有该元件对照表元件名词list-en并予以作为对应可删识别文字found-iw以将该起始文字之后的指定字数文字予以作为一首部删去文字而记录为排除(亦即,在将该元件对照表元件名词list-en予以纳入为该首部删去规则hr定义的可删识别文字iw时,为图2c以及图3c的例子,其中该可删识别文字iw为在该基本排除文字连续文字b-text的起始文字之外的相邻前文字或相邻前连续文字)。此时,该首部文字记录排除装置21为与第一实施例相同,对于其他非该元件对照表元件名词list-en的可删识别文字iw仍为:判断各个该基本排除文字连续文字b-text的起始文字或起始连续文字是否具有该可删识别文字iw并予以作为对应可删识别文字found-iw以将该对应可删识别文字found-iw且/或该对应可删识别文字found-iw之后的指定字数文字予以作为一首部删去文字而记录为排除、或判断各个该基本排除文字连续文字的起始文字的相邻前文字或相邻前连续文字是否具有该可删识别文字并予以作为对应可删识别文字以将该起始文字之后的指定字数文字予以作为首部删去文字而记录为排除,由此使该基本排除文字排除连续文字中b-text经排除该首部删去文字后的连续文字作为该可删文字删去连续文字d-text。
[0091]
详细而言,该首部文字记录排除装置21除了执行与第一实施例相同的对于该可删识别文字iw的判断之外,并会依据得知的该元件对照表元件名词list-en对该基本排除文字排除连续文字b-text进行以下之文字记录排除,以得到该可删文字删去连续文字d-text。例如,该可删文字删去规则dr订定出:“将”+“list-en”+
“……
至”(亦即,“将”以及“list-en”为位在该基本排除文字排除连续文字b-text
“……
至”之外且为前相邻,且“至”为在该基本排除文字排除连续文字b-text的尾部)的情形,则将“至”及“至”之前的两个字予以记录为排除。又例如,该可删文字删去规则dr订定出:“把”+“list-en”+
“……
至”(亦即,“把”以及“list-en”为位在该基本排除文字排除连续文字b-text
“……
至”之外且为前相邻,且“至”为在该基本排除文字排除连续文字b-text的尾部)的情形,则将“至”及“至”之
前的两个字予以记录为排除。又例如,该可删文字删去规则dr订定出:“把”+“list-en”+
“……
以”(亦即,“把”以及“list-en”为位在该基本排除文字排除连续文字b-text
“……
以”之外且为前相邻,且“以”为在该基本排除文字排除连续文字b-text的尾部)的情形,则将“以”及「以”之前的两个字予以记录为排除。
[0092]
在具有先行得出该元件对照表元件名词list-en的该元件对照表元件名词记录排除装置1a的无字间空格语言文字权利要求书文字c-text的元件名词及元件名词所属位置自动得出设备p,该可删文字纪录排除装置2的该尾部文字记录排除装置22为自动读取数个该基本排除文字连续文字b-text,并将该元件对照表元件名词list-en予以纳入为该尾部删去规则tr所定义的可删识别文字iw,以除了第一实施例的判断之外,再根据该元件对照表元件名词list-en,判断各个该基本排除文字连续文字b-text的最终文字的相邻后文字或相邻后连续文字是否具有该元件对照表元件名词list-en并予以作为对应可删识别文字found-iw以将该最终文字之后的指定字数文字予以作为尾部删去文字而记录为排除(亦即,在将该元件对照表元件名词list-en予以纳入为该尾部删去规则tr所定义的可删识别文字iw时,为图2c以及图3c的例子,其中该可删识别文字iw为在该基本排除文字连续文字b-text的最终文字之外的相邻后文字或相邻后连续文字)。此时,该尾部文字记录排除装置22为与第一实施例相同,对于其他非该元件对照表元件名词list-en的可删识别文字iw仍为:判断各个该基本排除文字连续文字b-text的最终文字或最终连续文字是否具有该可删识别文字iw并予以作为一对应可删识别文字found-iw以将该对应可删识别文字found-iw和/或该对应可删识别文字found-iw之前的指定字数文字予以作为一尾部删去文字td而记录为排除、或判断各个该基本排除文字连续文字b-text的最终文字的相邻后文字或相邻后连续文字是否具有该可删识别文字iw并予以作为一对应可删识别文字found-iw以将该最终文字之前的指定字数文字予以作为一尾部删去文字td而记录为排除,由此而使该基本排除文字排除连续文字b-text中经排除该尾部删去文字td后的连续文字作为该可删文字删去连续文字d-text。
[0093]
举例而言,该尾部文字记录排除装置22除了执行与第一实施例相同的对于该可删识别文字iw的判断之外,并会依据所得知之该元件对照表元件名词list-en而对该基本排除文字排除连续文字b-text进行以下的文字记录排除,以得到该可删文字删去连续文字d-text。例如,该可删文字删去规则dr订定出:“至”+“list-en,”(亦即,“list-en,”为位在该基本排除文字b-text
“……
至”之外且为后相邻,且“至”为在该基本排除文字排除连续文字b-text的尾部)的情形,则将“至”及“至”之前的两个字予以记录为排除(直到标点符号,如“;”、“,”)。又例如,该可删文字删去规则dr订定出:“给”+“list-en,”(亦即,“list-en,”为位在该基本排除文字b-text
“……
给”之外且为后相邻,且“给”为在该基本排除文字排除连续文字b-text的尾部)的情形,则将“给”及“给”之前的两个字予以记录为排除(至标点符号,如“;”、“,”)。又例如,该可删文字删去规则dr订定出:“到”+“list-en,”(亦即,“list-en,”为位在该基本排除文字b-text
“……
到”之外且为后相邻,且“到”为在该基本排除文字排除连续文字b-text的尾部)的情形,则将“到”及“到”之前的两个字予以记录为排除(至标点符号,如“;”、“,”)。又例如,该可删文字删去规则dr订定出:“至”+“list-en上,”(亦即,“list-en上,”为位在该基本排除文字b-text
“……
至”之外且为后相邻,且“至”为在该基本排除文字排除连续文字b-text的尾部)的情形,则将“至”及“至”之前的两个字予以记录为
排除。
[0094]
采用本发明的对于无字间空格语言文字权利要求书的元件名词及元件名词所属位置自动得出设备,可对于权利要求书的元件名词及元件名词所属位置之自动得出,不需建立元件名词数据库的方式且不以词性进行元件名词的判断,而根据专利权利要求的撰写格式以及特性,以不可能为元件名词的文字位置逐步排除的方式最终得出元件名词,如此在不需花费庞大系统计算及储存资源的情况下,提供可有效率的得出数量多、准确度高、提供速度快的权利要求书的元件名词及元件名词所属位置的自动得出设备。
[0095]
以上的叙述以及说明仅为本发明的较佳实施例的说明,本领域技术人员当可依据所界定的保护范围以及上述的说明而作其他的修改,同时,这些修改仍应是为本发明的创作精神而在本发明的保护范围中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1