面向液基细胞学检查的融合推理与学习的决策分类方法与流程
本发明属于计算机软件开发领域,具体涉及一种融合推理与学习的决策分类方法。
背景技术:
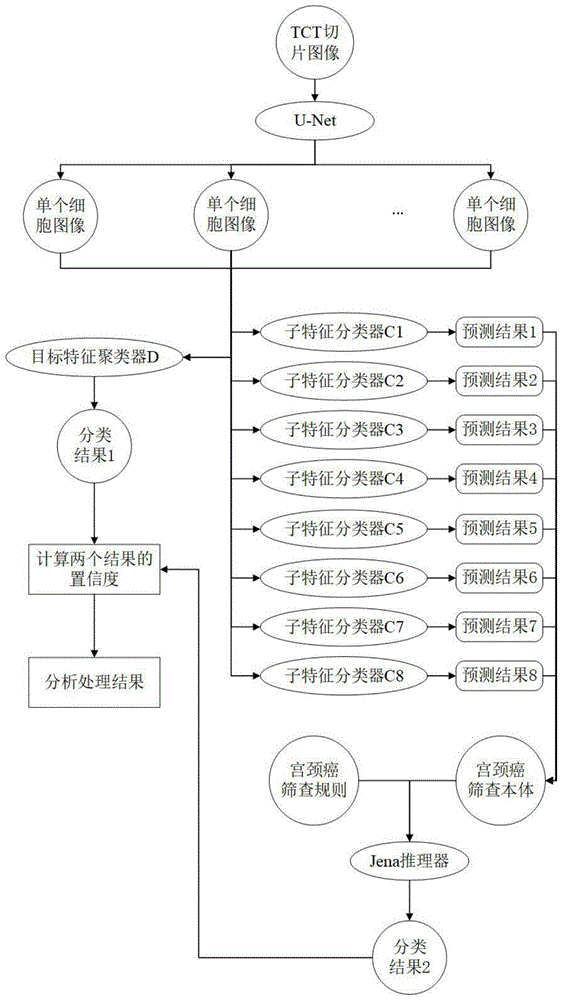
:宫颈癌是严重的健康问题之一,全世界每年有近50万妇女患此病。使用巴氏涂片筛查宫颈癌开创了宫颈癌筛查的先河,随着计算机技术逐渐应用于医学领域中,tct联合描述性诊断(tbs)的筛查方法成为了现今广泛使用的高准确率的宫颈癌筛查技术。液基细胞学检查(tct)技术能够有效地降低宫颈病变漏诊率,但tct检查的人工成本比较高。筛查所需的子宫颈细胞样本中包含成千上万个子宫颈细胞,医师在显微镜下对其进行观察诊断的过程非常耗时耗力。因此,使用人工智能技术对子宫颈细胞样本图像进行宫颈癌筛查是有极大意义的。宫颈细胞图像的自动化识别研究在很早就已经开展。目前,人工智能技术仍然主要应用于医学图像,以辅助医师进行癌症筛查,本发明也是通过融合知识推理和机器学习这两种人工智能技术来对宫颈鳞状上皮细胞图像进行分类。关于知识推理,它是在计算机或智能系统中模拟人类的智能推理方式,依据推理控制策略,利用形式化的知识进行机器思维和求解问题的过程。当前已存在一些比较成熟的知识推理方法,一种经典的推理方法是规则推理,它把相关领域的专家知识形式化的描述出来,形成系统规则,这些规则表示着该领域的一些问题与这些问题相应的答案,可以利用它们来模仿专家在求解中的关联推理能力。此外,人们还提出了基于一阶逻辑学习算法推理以及基于本体推理等知识推理方法。在机器学习方面,它是研究怎样使用计算机模拟或实现人类学习活动的科学,是人工智能中最具智能特征,最前沿的研究领域之一,其经过几十年的发展已成为如今人工智能技术中最重要的一环。机器学习模型一般被分成两种,一种是判别式模型,它能清晰地分辨出多类或某一类与其他类之间的差异特征,适用于较多类别的识别且模型更简单,目前应用范围较为广泛;另一种是深度生成模型,其研究单类问题比判别式模型更灵活,模型可以通过增强学习得到,且能用于数据不完整的情况,例如本发明中使用到的目标特征聚类神经网络——变分自编码器(vae)。vae是基于变分贝叶斯(variationalbayes,vb)推断的生成式网络结构,如今它在深度生成模型领域得到越来越多的研究和应用。虽然知识推理和机器学习都得到了极大的发展,但许多现实中复杂的问题并不能仅仅通过其中一个技术来解决。感知和推理是人类基本的能力,然而在当前的机器学习系统中,感知和推理模块是很难兼容的。神经网络很难具有推理的能力,同样,逻辑推理也很难具有学习的能力,因此,神经网络和逻辑推理结合是解决现实复杂问题的发展必然趋势。技术实现要素:发明目的:本发明目的在于针对现有技术的不足,提供一种面向tct的融合推理与学习的决策分类方法。一方面,本发明实现导入机器学习结果的知识规则推理,对宫颈鳞状上皮细胞图像进行类型识别;另一方面,本发明结合推理结果和机器学习结果进行演进,计算推理结果和目标特征聚类器结果的置信度,并且根据两个结果和它们的置信度来分析处理多种情况。融合知识推理和机器学习两种途径来提高分类结果的精确度和可靠性。技术方案:本发明所述面向液基细胞学检查的融合推理与学习的决策分类方法,包括如下步骤:1)数据和本体准备:构建用于决策目标的数据集和与数据有关的本体,提取二者之间的多个关联数据特征,将其作为目标特征的子特征;2)神经网络和规则构建:训练包括一个目标特征聚类器和多个子特征分类器的神经网络集合,构建决策目标相关的推理规则;3)知识推理与神经网络融合:融合知识推理与机器学习,实现支持机器学习结果的知识规则推理和推理结果结合机器学习结果的演进方法,并分析处理结果。本发明进一步优选地技术方案为,步骤1)的数据和本体准备包含构建训练目标特征聚类神经网络的数据集、构建宫颈癌筛查本体、提取子特征、构建训练子特征分类神经网络的数据集,以及添加实体数据。作为优选地,构建训练目标特征聚类神经网络的数据集是由tct细胞切片图像使用深度学习分割网络u-net将这些细胞切片图像上的细胞分割下来,得到单个宫颈鳞状上皮细胞图像,在其中选取成像清晰且分割效果较好的细胞图像,作为数据集的组成部分。优选地,宫颈癌筛查本体通过自下而上的方法构建,关联特征是依据已构建好的宫颈鳞状上皮细胞图像数据集和宫颈癌筛查本体,将宫颈癌筛查知识中高频提及的概念与细胞图像特征相互对应、关联选取,并作为子特征分类器的分类标准。优选地,步骤2)中神经网络和规则构建包含搭建并训练目标特征聚类神经网络模型、搭建并训练子特征分类神经网络模型,以及构建宫颈癌筛查规则。优选地,目标特征聚类器通过训练vae得到,它直接对宫颈鳞状上皮细胞图像进行无监督聚类,子特征分类器通过训练卷积神经网络cnn得到,分别按照步骤1)中提取的子特征的标准对细胞图像进行分类;推理规则由专家知识转化为swrl语言获得。优选地,步骤3)的知识推理与神经网络融合包含实现支持机器学习结果的知识规则推理、结合推理结果和机器学习结果进行演进,以及分析处理结果。优选地,知识推理与神经网络融合的具体方法为:将一个待分类细胞喂给目标特征聚类器和子特征分类器,目标特征聚类器的结果为分类结果1;子特征分类器的结果转化为本体中对应概念的实体和实体关系,通过规则推理得到分类结果2;结合推理结果和机器学习结果进行演进,分别计算分类结果1和分类结果2的置信度,根据两个结果和它们的置信度分析处理多种情况,由于情况的不同最终处理结果也不同,包括:①输出结果,使用规则解释结果;②人工选取正确的分类结果,迭代优化框架中的内容;③输出结果,迭代优化框架中的内容;④结果无效,不输出结果。有益效果:(1)本发明步骤2)中本体描述了领域知识的概念以及概念之间的关系,数据和本体之间的关联数据特征作为目标特征的子特征,是后续训练子特征分类器的标准;步骤3)中目标特征聚类器直接对数据进行无监督聚类,多个子特征分类器分别按照步骤2)提取到的子特征的标准来分类数据,推理规则描述了从子特征到目标特征之间的逻辑关系,由专家知识转化而来。步骤4)中创新地融合了知识推理和神经网络,将步骤3)得到的子特征分类器的结果转化为实体和实体间的关系进行知识规则推理,并且实现了推理结果结合机器学习结果的演进方法,即引入置信度概念,根据推理结果、机器学习结果、二者的置信度来分析处理多种情况,由于情况的不同最终处理结果也不同。(2)本发明提出融合推理和学习的决策分类方法框架,并使用该框架对宫颈鳞状上皮细胞图像进行类型识别,得到支持子特征分类器结果的规则推理结果,以及目标特征聚类器结果,结合二者进行演进,根据推理结果、目标特征聚类器结果、二者的置信度来分析处理多种情况。本发明创新地将知识推理和机器学习两种途径结合在一起,使分类框架同时拥有推理和感知能力。该分类框架不仅提升了分类结果的精确率,还使得结果拥有可解释性,并由于迭代优化的处理而逐渐提高了结果的可靠性。(3)本发明的主要创新之处和价值在于,在同一模块种融合推理与学习两种方法。融合点之一在于关联数据和知识,提取二者之间的关联数据特征,作为目标特征的子特征;融合点之二在于结合子特征分类器的结果和构建的规则,来实现支持机器学习结果的知识规则推理,提高分类结果的精确率;融合点之三在于结合推理结果和机器学习结果进行演进,赋予结果可解释性,并提高结果的可靠性。(4)本发明的融合推理与学习的决策分类方法的价值在于在一个框架中兼容学习和推理模块,以解决许多单一模块无法解决的复杂问题。该方法面向tct,应用于宫颈癌筛查领域,辅助医师对tct切片中的细胞群进行宫颈癌判断,有效地降低宫颈病变漏诊率。附图说明图1为宫颈癌细胞类型识别软件的流程示意图;图2是融合知识推理和机器学习的决策分类方法的框架示意图;图3是宫颈癌筛查本体结构示意图;图4是目标特征聚类神经网络的结构示意图;图5是子特征分类神经网络的结构示意图。具体实施方式下面通过附图对本发明技术方案进行详细说明,但是本发明的保护范围不局限于所述实施例。实施例:本实施例用于实现一套面向tct的宫颈癌细胞类型识别方法。首先使用深度学习分割网络u-net从tct细胞切片图像上提取单个鳞状上皮细胞图像,这些待分类的细胞图像经过目标特征聚类器d和子特征分类器c1-c8,得到9个结果,其中聚类器d的结果为细胞类型分类结果1,分类器c1-c8的结果均为细胞的特征分类结果。将c1-c8的结果转化为宫颈癌筛查本体中对应概念的实体和实体关系,与构建好的宫颈癌细胞诊断规则一同导入到drools推理器中,使用推理器进行规则推理,得到细胞类型分类结果2。结合推理结果和机器学习结果进行演进,计算分类结果1和分类结果2的置信度,根据两个结果和它们的置信度来分析处理多种情况。软件流程如图1所示。一、第一阶段(提出分类框架)首先提出了融合知识推理和机器学习的决策分类方法的框架,描述了融合推理与学习的决策分类方法的具体内容,包括数据和本体准备、规则和神经网络构建、知识推理与神经网络融合这三个模块:(1)数据和本体准备,首先制作训练目标特征神经网络的宫颈鳞状上皮细胞图像数据集,然后使用protégé软件和owl语言自下而上地构建宫颈癌筛查本体,最后根据二者之间的关联关系提取细胞特征,将其作为目标特征的子特征,并根据细胞特征对训练子特征神经网络的数据集进行分类、为本体中细胞特征对应的概念添加分类实体。(2)神经网络和规则构建,搭建并训练目标特征神经网络d和子特征分类神经网络c1-c8,得到目标特征聚类器d和子特征分类器c1-c8,然后使用swrl语言将专家知识转化为宫颈癌筛查规则。(3)知识推理与神经网络融合,实现了支持机器学习结果的知识规则推理和结合推理结果和聚类器d结果的演进方法,根据两个结果本身和它们的置信度来分析处理各种情况,以得到相应的处理结果。融合知识推理和机器学习的决策分类方法的框架示意图如图2所示。二、第二阶段(数据和本体准备)本实施例根据提出的分类框架,对宫颈鳞状上皮细胞数据集和宫颈癌筛查本体进行准备和构建,并提取二者之间的关联细胞特征,作为目标特征的子特征。(1)制作训练目标特征神经网络的数据集医院提供的tct细胞切片图像为多张65500×65500分辨率的高清大图片,使用深度学习分割网络u-net将这些细胞切片图像上的细胞分割下来,得到上万张尺寸为128×128的单个宫颈鳞状上皮细胞图像。本实施例在其中选取m张成像清晰且分割效果较好的细胞图像,作为数据集的组成部分。定义一个实例空间,使用数组x={x1,...,xm}来表示,其代表本实施例选取的m张细胞图像样本,xi为对应的每个细胞图像。除此之外,需要对这m张细胞图像进行标注。定义一个标签空间,使用数组y={y1,...,ym}来表示,yi为xi对应的标签。我们将宫颈鳞状上皮细胞的6个类别进行标注:①正常鳞状上皮细胞;②高度鳞状上皮内病变(hsil);③低度鳞状上皮内病变(lsil);④鳞状细胞癌(scc);⑤非典型鳞状细胞-意义不明确(asc-us);⑥非典型鳞状细胞-不除外高度鳞状上皮内病变(asc-h)。定义数据集d={(x1,y1),(x2,y2),...,(xm,ym)},其中xi∈x,yi∈y。为了提升模型的收敛速度,需要对数据进行预处理:a.对m张细胞图像的像素特征进行归一化处理,将特征的取值区间缩放到[0,1]范围内;b.采用归一化方法将图像依次灰度化,然后对其像素值除以255,使它缩放到[0,1]中,以加快训练网络的收敛性;c.使用留出法将预处理完的数据集d划分为训练集s与测试集t,将样本比例设置为4:1。使用训练集s来训练目标特征聚类神经网络d,测试集t则用于评估该网络的性能,并在第四阶段作为测试集使用。(2)建立宫颈癌筛查本体本实施例使用protégé软件和owl语言,自下而上地构建宫颈癌筛查本体。首先,对宫颈癌筛查的领域知识进行抽取,从不同来源、不同数据结构的数据中获取知识;其次,对知识进行融合,将分散、异构和自治的知识融合成统一的知识,以保证知识的一致性;最后,对知识进行加工,即补全、纠错以及更新知识。得到的宫颈癌筛查本体的具体内容如表1、表2和表3所示,结构如图3所示。表1本体名称对照表表2属性名称对照表#属性名称(property)中文名称1is_part_of是…的一部分2hasproperty具有属性3diagnosis诊断4detect检出5operate做检查6is_precancerous_lesions_of是…的癌前病变表3本体之间的关系(3)提取细胞特征(子特征)提取宫颈鳞状上皮细胞图像和宫颈癌筛查知识之间的关联特征,将知识中高频提到的概念(本体)与宫颈鳞状上皮细胞图像进行关联和对应,以抽取用于下一阶段训练子特征分类神经网络的分类标准。例如,知识中提到:细胞中等大小,细胞核增大、细胞核为双(多)核、细胞核深染的挖空细胞,细胞核显著增大、核质比(n/c)低的非挖空细胞为lsil的细胞学特征;小细胞、细胞核增大、n/c显著增加、细胞核明显深染、无核仁为hsil的细胞学特征,等等。本实施例根据知识以及细胞图像特征,提取到的宫颈鳞状上皮细胞的特征如表4所示。表4细胞特征那么,第三阶段将分别训练8个子特征神经网络c1-c8,以通过识别细胞大小、细胞核大小、细胞核为单核还是双(多)核、n/c、细胞核染色程度、有无核仁、是否为挖空细胞、是否鳞状分化这些不同来分类细胞。(4)制作训练子特征神经网络的数据集用于训练子特征分类神经网络c1-c8的数据集d1-d8仍然由选取的m张成像清晰且分割效果较好的宫颈鳞状上皮细胞图像所组成,并对数据集的细胞图像进行类别标注。每个子特征神经网络的数据集的具体分类标注方法,是根据其对应的细胞特征和相关宫颈细胞学知识来确定的,如表5所示。表5c1-c8的数据集分类标注其中,d1、d2、d4、d5这四个数据集为模糊集合。虽然细胞面积和细胞核面积可以通过图形算法直接计算出来,但宫颈癌细胞学知识没有提及具体的面积和面积大小之间的关系,导致面积值无法应用于规则推理,因此使用神经网络对细胞面积大小和细胞核面积大小不同的细胞进行分类。本实施例使用留出法将8个数据集d1-d8分别划分为训练集s1-s8与测试集t1-t8,样本比例依然为4:1,每个测试集用于评估对应的子特征分类神经网络的性能。(5)添加实体数据将上一步的分类标准作为实体添加到本体中其对应的细胞特征概念。为本体中的cell_area(细胞面积大小)添加中等细胞和小细胞这两个实体,为nucleus_area(细胞核面积大小)添加细胞核显著增大、细胞核增大和细胞核正常这三个实体,为nucleus_count(细胞核为单核还是多核)添加单核和多核这两个实体,为n/c(核质比)添加核质比高和核质比低这两个实体,为deep_dyeing(深染程度)添加明显深染、深染和轻度深染这三个实体,为nucleolus_count(有无核仁)添加有核仁和无核仁这两个实体,为koilocyte(是否为挖空细胞)添加是挖空细胞和不是挖空细胞这两个实体,为squamous_differentiation(是否鳞状分化)添加鳞状分化和没有鳞状分化这两个实体。三、第三阶段(神经网络和规则构建)本实施例根据提出的分类框架,构建目标特征聚类神经网络d,并根据第二阶段提取的8个细胞特征来构建子特征分类神经网络c1-c8。对这些神经网络进行训练,得到目标特征聚类器d,以及子特征分类器c1-c8。将宫颈癌细胞诊断专家知识转化为swrl规则语言,得到推理规则。(1)目标特征聚类神经网络搭建和训练目标特征聚类神经网络d选取vae架构来训练,包含编码器、解码器,其结构如图4所示。编码器由一个encoder神经层和与之相连的两个并列的神经层z_mean(均值μ)和z_std(方差σ2)组成:encoder神经层由两组前后相接的一层卷积层conv和激活函数leakyrelu组成,其输入为训练集s;z_mean和z_std全部使用全连接层实现,其输入是encoder神经层的输出;隐变量z是从这两个参数确定的正态分布上采样的。解码器由一个decoder神经层和与之相连的decoder_out输出层组成:decoder神经层的结构与encoder一致,其输入是隐变量z;本实施例使用全连接层来实现decoder_out输出层,然后使用激活函数sigmoid(decoder_out)将输入映射到输出。本实施例使用vae理论上的聚类损失函数:其中q(z)是标准正态分布,p(z|x)和q(x|z)是条件正态分布。将聚类类别设置为六类,学习率设置为0.2。从第1步训练开始,每一步训练都从原始数据中采样到x,通过p(z|x)提取到编码特征z,然后分类器p(y|z)将编码特征进行分类,从而得到类别,然后从分布q(y)中选取一个类别y,从分布q(z|y)中选取一个随机隐变量z,生成器q(x|y)解码隐变量z为原始样本。当损失函数或训练步数达到30000步时,结束训练并保存模型,得到目标特征聚类器d。对聚类器得到的六个聚类分布进行标注,即根据聚类分布上的细胞图像大多属于的细胞类型来标明哪个聚类分布属于哪个细胞类型。本实施例对目标特征聚类器d进行评估。聚类器d使用马氏距离作为聚类标准,将测试集t的每一个细胞图像样本喂给聚类器d,输出为六个类别分布中距离该细胞最短的类别和对应的距离,将每个类别单独视为正类,所有其它类型视为负类,计算每个类别的精确率(precision)。精确率计算公式如下:tp、fp的定义如表6所示。表6tp、fp的定义本实施例将六个类别的精确率分别乘以对应权重的值作为评估标准。由于正常细胞图像占测试集的比重较大,而另外五种癌变细胞图像数量较少,因此正常细胞类别的精确率对应权重较高,将其设置为0.5,其他癌细胞类别的精确率对应权重较低,将其全部设置为0.1。那么聚类器d的评估值evad计算方法为:其中p1为正常细胞类别的精确率,p2~p6分别为hsil、lsil、scc、asc-us、asc-h类别的精确率。(2)子特征分类神经网络搭建和训练子特征分类神经网络c1-c8全部选择cnn架构进行训练,它的结构由两组前后相接的一层卷积层conv(relu)和一层池化层maxpool,以及后接的两层全连接层fc(relu)和fc(softmax)组成。其结构如图5所示。子特征分类神经网络c1-c8分别希望按照细胞面积大小、细胞核面积大小、细胞核为单核还是双(多)核、核质比(n/c)、细胞核染色程度、有无核仁、是否为挖空细胞、是否鳞状分化的标准来分类细胞。本实施例使用交叉熵作为神经网络c1-c8的损失函数:其中,n代表着n种类别。8个子特征分类神经网络分别使用其对应的训练集进行训练,设置学习率为0.1,当损失函数或训练步数达到10000步时,结束训练并保存模型,得到子特征分类器c1-c8。本实施例对子特征分类器c1-c8进行评估。将测试集t1的每一个细胞图像样本喂给子特征分类器c1,输出为该细胞可能所属的类别中概率最高的类别和对应的概率,其他7个子特征分类器的测试与c1相同。对于二元分类器c1、c3、c4、c6、c7、c8,其评估标准就是精确率;对于三元分类器c2、c4,其评估标准为三个类别的精确率的平均值。通过所述计算方法得到子特征分类器c1-c8的评估值evac1-evac8。(3)规则构建本实施例使用到的宫颈癌细胞学形态诊断专家知识如表7所示。表7宫颈癌细胞学形态诊断专家知识如果细胞图像不符合任何一个宫颈癌细胞的诊断规则,即该细胞的细胞核大小为正常,则将该细胞归类为正常细胞。本实施例使用swrl语言将专家知识由自然语言转化为规则语言。例如,对于lsil的细胞学特征:细胞中等大小,细胞核增大、细胞核为双(多)核、细胞核深染的挖空细胞,细胞核显著增大、n/c低的非挖空细胞,本实施例将其翻译为swrl语言:cervix_cell(?c)^hasproperty(?c,是挖空细胞)^hasproperty(?c,中等细胞)^hasproperty(?c,细胞核增大)^hasproperty(?c,多核)^hasproperty(?c,深染)->lsil1(?c)cervix_cell(?c)^hasproperty(?c,核质比低)^hasproperty(?c,中等细胞)^hasproperty(?c,不是挖空细胞)^hasproperty(?c,细胞核显著增大)->lsil2(?c)除宫颈癌细胞学形态诊断规则以外,还有一条规则用来描述细胞某组织的组成部分的性质也是该组织的性质这一知识,本实施例将其翻译为swrl语言:is_part_of(?a,?b)^hasproperty(?a,?c)->hasproperty(?b,?c)。四、第四阶段(融合推理与学习)本实施例根据提出的分类框架,创新地将知识推理和神经网络融合起来。将测试集t的一个待分类细胞喂给第三阶段得到的目标特征聚类器d和子特征分类器c1-c8,导入子特征分类器的结果到本体中进行知识规则推理,并且实现了推理结果结合机器学习结果的演进方法,计算两个结果的置信度,然后根据推理结果、聚类器d结果、二者的置信度来分析处理多种情况,由于情况的不同最终处理结果也不同。(1)实现支持机器学习结果的知识规则推理将测试集t中的一个待分类的细胞图像样本同时喂给第三阶段得到的目标特征聚类器和子特征分类器。聚类器d的输出为六个宫颈细胞类别分布中距离该细胞图像最近的类别和对应的马氏距离dmin,并记录此细胞图像距离所有分布中最远的马氏距离dmax。该类别为分类结果1。分类器c1的输出为该细胞是中等细胞和小细胞两个类别中概率最高的类别和对应的概率p1;分类器c2的输出为该细胞的细胞核显著增大、细胞核增大和细胞核正常三个类别中概率最高的类别和对应的概率p2;分类器c3的输出为该细胞的细胞核为单核和细胞核为双(多)核两个类别中概率最高的类别和对应的概率p3;分类器c4的输出为该细胞的n/c高和n/c低两个类别中概率最高的类别和对应的概率p4;分类器c5的输出为该细胞的细胞核明显深染、细胞核深染和细胞核轻度深染三个类别中概率最高的类别和对应的概率p5;分类器c6的输出为该细胞的细胞核有核仁和无核仁两个类别中概率最高的类别和对应的概率p6;分类器c7的输出为该细胞是挖空细胞和不是挖空细胞两个类别中概率最高的类别和对应的概率p7;分类器c8的输出为该细胞鳞状分化和没有鳞状分化两个类别中概率最高的类别和对应的概率p8。将分类器c1-c8的分类结果转化为本体中的实体数据和实体之间的关系,与第三阶段已构建好的swrl规则一同导入到drools推理器中,进行规则推理,得到的推理结果为分类结果2。例如,一个待分类细胞经过分类器c1-c8,得到的类别分别为:小细胞、细胞核增大、单核、核质比高、细胞核明显深染、有核仁、不是挖空细胞、没有鳞状分化,将待分类细胞作为cervix_cell的实体,将待分类细胞细胞核作为nucleus的实体,将待分类细胞核仁作为nucleolus的实体,实体间的关系如表8所示。表8实体关系实体属性实体待分类细胞hasproperty小细胞待分类细胞hasproperty核质比高待分类细胞hasproperty不是挖空细胞待分类细胞hasproperty没有鳞状分化待分类细胞细胞核is_part_of待分类细胞待分类细胞细胞核hasproperty细胞核增大待分类细胞细胞核hasproperty单核待分类细胞细胞核hasproperty明显深染待分类细胞核仁is_part_of待分类细胞细胞核待分类细胞核仁hasproperty有核仁那么根据这些实体和实体关系,以及小细胞、细胞核增大、n/c高、细胞核明显深染、有明显核仁为scc这一推理规则,推理出该细胞为scc。如果推理结果为冲突,则人工干预对错误进行处理,然后再一次推理得到结果。(2)结合推理结果和机器学习结果演进本实施例为聚类器和每个分类器的分类结果定义一个可信度(cred),其包括两个部分:一部分为该网络自身的评估值,另一部分为该结果的可靠度(reli)。两个部分平均值为该结果的可信度。对于聚类器d来说,它的评估值为evad,它的聚类结果的可靠度relid计算方法为:其中,dmin为细胞图像距离六个宫颈细胞类别分布最近的马氏距离,dmax为细胞图像距离所有分布中最远的马氏距离dmax。因此,聚类器d的可信度为:对于分类器c1-c8来说,它的评估值为evacn,它的聚类结果的可靠度relicn为所有类别中概率最高的概率值pn。因此,分类器cn的可信度为:为分类结果1和分类结果2定义置信度(con)概念,并对两个结果的置信度分别进行计算。分类结果1的置信度con1和聚类器d的可靠度relid相同,分类结果2的置信度con2与分类器c1-c8的可信度credc1~credc8均有关系。由于规则中细胞特征出现的频率不同,所以分类器c1-c8结果的重要性也不同,例如细胞面积大小、细胞核面积大小和细胞核深染程度在多个规则中出现,而是否为挖空细胞、是否鳞状分化这样的细胞特征只出现了一次。因此,计算分类结果2的置信度con2时要为分类器c1-c8结果的可信度分配权重,其计算方法如下:con2=0.25×credc1+0.2×credc2+0.1×credc3+0.1×credc4+0.15×credc5+0.1×credc6+0.05×credc7+0.05×credc8(3)分析并处理结果对比分类结果1、分类结果2。①如果两个结果相同,则:a.con1>0.5且con2>0.5,那么认为两个结果的可靠性都比较高,输出该分类结果并利用该分类结果的规则解释结果;b.con1>0.5且con2≤0.5,那么认为分类结果1的可靠性较高,分类结果2的可靠性较低,输出该分类结果,并优化子特征分类神经网络c1-c8的参数;c.con1≤0.5且con2>0.5,那么认为分类结果1的可靠性较低,分类结果2的可靠性较高,输出该分类结果,并优化目标特征聚类神经网络d的参数;d.con1≤0.5且con2≤0.5,那么认为两个结果的可靠性都比较低,结果无效不输出结果,同时优化子特征分类神经网络c1-c8和目标特征聚类神经网络d的参数,以及对数据集的细胞图像进行调整优化。②如果两个结果不同,则:a.con1>0.5且con2>0.5,那么认为两个结果的可靠性都比较高,人工选择正确的结果,如果错误结果为分类结果1,则输出分类结果2并优化目标特征聚类神经网络d的参数,如果错误结果为分类结果2,则输出分类结果1并对规则和知识进行检错和补正,以及优化子特征分类神经网络c1-c8的参数,如果两个结果都为错误的,则结果无效不输出结果,同时优化子特征分类神经网络c1-c8和目标特征聚类神经网络d的参数,以及对所有数据集的细胞图像进行调整优化。b.con1>0.5且con2≤0.5,那么认为分类结果1的可靠性较高,分类结果2的可靠性较低,输出分类结果1并对规则和知识进行检错和补正,以及优化子特征分类神经网络c1-c8的参数;c.con1≤0.5且con2>0.5,那么认为分类结果1的可靠性较低,分类结果2的可靠性较高,输出分类结果2并优化目标特征聚类神经网络d的参数,以及对数据集d进行调整和优化。d.con1≤0.5且con2≤0.5,那么认为两个结果的可靠性都比较低,结果无效不输出结果,同时优化子特征分类神经网络c1-c8和目标特征聚类神经网络d的参数,以及对所有数据集的细胞图像进行调整优化。综上所述,本实施例通过四个阶段,即提出分类框架、数据和本体准备、神经网络和规则构建、融合推理与学习,来实现融合推理与学习的决策分类方法,为识别tct切片上的宫颈鳞状上皮细胞类别提供了一种有效的途径。通过应用新型的分类和演进方法,本实施例能够在提高分类结果准确率的同时对分类结果进行解释,并且因为迭代优化的步骤使结果越来越可靠,符合医疗应用需求。为检验本方法的效果,本实施例在tct切片图像上开展了试验,实验验证步骤如下:(1)将测试集t的一个待分类细胞图像依次喂给目标特征聚类器d和子特征分类器c1-c8,聚类器d的结果作为分类结果1。(2)将分类器c1-c8的结果转化为本体中对应概念的实体数据和实体关系,通过drools推理器进行规则推理,得到分类结果2。(3)分别计算两个结果的置信度con1和con2,根据分类结果1、分类结果2和两者的置信度,分析处理8种不同的情况,并根据具体情况产生相应的处理结果。(4)重复步骤1~3,直到测试集t的1000个细胞均完成分类,并对分类的准确率进行计算。实验表明,本实施例所提出的融合推理与学习的决策分类方法准确率约为71%,在多分类问题方面,较其他分类方法准确率有所提升。本实施例还赋予了分类结果可解释性,描述了将其归为某一类别的依据,同时引入置信度概念,根据结果和置信度的不同分析处理各种情况,并因为其中迭代优化的步骤,分类结果将会随着测试次数的增加而越来越可靠。如上所述,尽管参照特定的优选实施例已经表示和表述了本发明,但其不得解释为对本发明自身的限制。在不脱离所附权利要求定义的本发明的精神和范围前提下,可对其在形式上和细节上作出各种变化。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1