一种基于神经网络的文字识别方法与流程
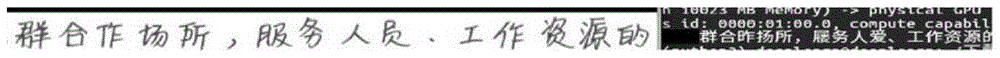
【技术领域】
本发明涉及文字识别技术技术领域,具体涉及一种基于神经网络的文字识别方法。
背景技术:
现在的文字识别算法中,有多种文字识别算法,如:densnet+ctc,crnn+ctc,resnet+ct等等,在多种算法中,他们的损失函数都是统一为ctc,在提取特征层不一样,如densnet和resnet属于卷积类的提取,crnn是cnn和rnn的结合,属于卷积核语言模型的组合,目前市面上的文字识别算法如图1、图2所示。出现了识别错误的现场,并且这种错误是在训练10g的大样本下的错误。
在现有的文字识别算法中,大部分的特征提取层是由densnet和resnet组成,如果复杂一点的会由cnn和rnn组成,这种组成对印刷体的识别效果会非常不错,但对于手写体来说,densnet和resnet密集型网络提取特征,并且手写体属于松散并且无规律的结构,用这两种方法提取特征会更加容易丢失特征,从而让文字识别出现错误,cnn和rnn的组合在市面上的结构也和densnet和resnet一样复杂,也一样容易丢失特征甚至到达特征消失的地步(计算完后无限接近于0)。
技术实现要素:
本发明的目的在于针对现有技术的缺陷和不足,提供一种基于神经网络的文字识别方法。
本发明所述的一种基于神经网络的文字识别方法,采用如下步骤:
s1:采用待识别文本图像,且转换为灰度图像,形成训练样本图片;
s2:对s1中的训练样本图片,输入至cnn卷积神经网络,通过对卷积层的输出通道、卷积核和步长的参数设定,以及层归一化处理,然后提取特征,输出特征矩阵;
s3:基于lstm神经网络的cell组成的双向rnn的语言模型;
s4:将s2中的得到的特征矩阵,输入至s3中的双向rnn的语言模型中,通过对多层卷积的输出通道、卷积核和步长的参数设定,进行提取特征,输出特征矩阵,以及多次对训练数据进行归一化处理,激活、以及最大池化处理,得到对s1中训练样本图片中的文字序列的识别结果。
进一步地,s2中的利用cnn卷积神经网络,对s1中的训练样本图片,进行特征提取,采用如下步骤:
s201:对s1中的训练样本图片,进行卷积运算,进行特征提取,形成特征矩阵;上述卷积运算的参数如下:输出:64,卷积核:3,步长:1;上述最大池化的参数如下:卷积核:2,步长:2;
s202:对s201中的特征矩阵;进行卷积运算,进行特征提取;上述卷积运算的参数如下:输出:128,卷积核:3,步长:1;上述最大池化的参数如下:卷积核:2,步长:2;
s203:对s202中的特征矩阵;进行卷积运算,进行特征提取;上述卷积运算的参数如下:输出:256,卷积核:3,步长:1;
s204:对上述训练数据,进行卷积神经网络的归一化操作;
s205:然后再使用卷积神经网络的激活函数,进行激活处理,将激活信息向后传入下一层的神经网络;
s206:通过卷积运算,进行特征提取,形成特征矩阵,其参数如下:输出:256,卷积核:3,步长:1;
s207:对上述的训练数据,进行层归一化运算;s208:再使用卷积神经网络的激活函数,进行激活处理;
s209:然后通过卷积神经网络,进行最大池化操作,抽取其最大值,形成特征矩阵;其参数如下:池化窗口大小:2;池化步长:宽为2,高为2;padding:valid;
s210:进行卷积运算,其参数如下:输出:512,卷积核:3,步长:1,进行特征提取,形成特征矩阵;
s211:对s210中的特征矩阵,进行卷积神经网络的归一化操作;
s212:然后再使用卷积神经网络的激活函数,进行激活处理;
s213:再进行卷积运算操作,进行特征提取,形成特征矩阵,其参数如下:输出:512,卷积核:3,步长:1;
s214:对上述产生的训练数据,进行层归一化操作;
s215:再使用卷积神经网络的激活函数,进行激活处理;
s216:然后,再次对上述产生的训练数据,再进行最大池化操作,其参数如下:卷积核大小:高为2,宽为1;步长大小:高为2,宽为1;
s217:再次进行卷积运算,进行特征提取,形成特征矩阵;其参数如下:输出:512;卷积核:2;卷积核步长:高为2,宽为1;
s218:再进行层归一化操作;
s219:然后再使用卷积神经网络的激活函数,进行激活处理。
进一步地,对s3中的基于lstm神经网络的cell组成的双向rnn的语言模型,进行特征提取,采用如下步骤:
s301:对s2中经cnn卷积神经网络提取的特征矩阵,利用双向rnn的语言模型,再次进行卷积运算处理;其参数如下:输出:64,卷积核:3,padding:vali;
s302:进行卷积运算,进行特征提取,形成特征矩阵,其参数如下:输出:64,卷积核:3,padding:same;
s303:对上述训练数据,进行层归一化运算处理;
s304:使用卷积神经网络的激活函数,进行激活处理;
s305:然后再进行池化层最大池化操作,其参数如下:池化窗口大小:2,池化步长:宽为2,高为2;padding:valid;
s306:进行卷积运算操作,进行特征提取,其参数如下:输出:128,卷积核:3,padding:same;
s307:对上述产生的训练数据,采用归一化运算处理;
s308:使用卷积神经网络的激活函数,进行激活处理;
s309:进行卷积运算,进行特征提取,形成特征矩阵,其参数如下:输出:128,卷积核:3,padding:same;
s310:对上述的训练数据,进行层归一化运算处理;
s311:使用卷积神经网络的激活函数,进行激活处理;
s312:然后再进行池化层最大池化操作,其参数如下:池化窗口大小:2;池化步长:宽为2,高为1;padding:valid;
s313:进行卷积运算,进行特征提取,形成特征矩阵,其参数如下:输出:256,卷积核:3,padding:same;
s314:对上述训练数据,进行层归一化运算处理;
s315:使用卷积神经网络的激活函数,进行激活处理;
s316:进行卷积运算,进行特征提取,形成特征矩阵,其参数如下:输出:256,卷积核:3,padding:same;
s317:对上述训练数据,进行层归一化运算处理;
s318:使用卷积神经网络的激活函数,进行激活处理;
s319:再进行池化层最大池化操作,提取其特大值,形成特征矩阵,其参数如下:池化窗口大小:2;池化步长:宽为2,高为1;padding:valid;
s320:进行卷积运算,进行特征提取,形成特征矩阵,其参数如下:输出:512,卷积核:3,padding:same;
s321:对上述训练数据,进行层归一化运算处理;
s322:使用卷积神经网络的激活函数,进行激活处理;
s323:进行卷积运算,进行特征提取,形成特征矩阵,其参数如下:输出:512,卷积核:3,padding:same;
s324:对上述训练数据,进行层归一化运算处理;
s325:使用卷积神经网络的激活函数,进行激活处理;
s326:再进行池化层最大池化操作,提取其特大值,其参数如下:池化窗口大小:宽为3,高为1;池化步长:宽为3,高为1;padding:valid。
本发明有益效果为:本发明所述的一种基于神经网络的文字识别方法,它基于cnn和rnn的文字识别算法,通过改进cnn和rnn层,其特征提取更加达到点子上,不会出现特征丢失和特征消失的问题,提高识别效率和正确率。
【附图说明】
此处所说明的附图是用来提供对本发明的进一步理解,构成本申请的一部分,但并不构成对本发明的不当限定,在附图中:
图1是本发明中的背景技术中的文字识别算法的示意图;
图2是图1右部放大图;
图3是本发明中的拓扑示意图;
图4是本发明中的针对背景技术中的训练样本图片进行文字识别的示意图;
图5是图4的右部放大图。
【具体实施方式】
下面将结合附图以及具体实施例来详细说明本发明,其中的示意性实施例以及说明仅用来解释本发明,但并不作为对本发明的限定。
如图3所示,本具体实施方式所述的一种基于神经网络的文字识别方法,采用如下步骤:
s1:采用待识别文本图像,且转换为灰度图像,形成训练样本图片;
s2:对s1中的训练样本图片,输入至cnn卷积神经网络,通过对卷积层的输出通道、卷积核和步长的参数设定,以及层归一化处理,然后提取特征,输出特征矩阵;
s3:基于lstm神经网络的cell组成的双向rnn的语言模型;
s4:将s2中的得到的特征矩阵,输入至s3中的双向rnn的语言模型中,通过对多层卷积的输出通道、卷积核和步长的参数设定,进行提取特征,输出特征矩阵,以及多次对训练数据进行归一化处理,激活、以及最大池化处理,得到对s1中训练样本图片中的文字序列的识别结果。
进一步地,s2中的利用cnn卷积神经网络,对s1中的训练样本图片,进行特征提取,采用如下步骤:
s201:对s1中的训练样本图片,进行卷积运算,进行特征提取,形成特征矩阵;上述卷积运算的参数如下:输出:64,卷积核:3,步长:1;上述最大池化的参数如下:卷积核:2,步长:2;
s202:对s201中的特征矩阵;进行卷积运算,进行特征提取;上述卷积运算的参数如下:输出:128,卷积核:3,步长:1;上述最大池化的参数如下:卷积核:2,步长:2;
s203:对s202中的特征矩阵;进行卷积运算,进行特征提取;上述卷积运算的参数如下:输出:256,卷积核:3,步长:1;
s204:对上述训练数据,进行卷积神经网络的归一化操作,防止梯度爆炸和梯度消失,能够使得网络模型错误率极大降低;
s205:然后再使用卷积神经网络的激活函数,进行激活处理,将激活信息向后传入下一层的神经网络;
其中:激活函数如sigmoid函数、tanh函数、relu函数、dropout函数;当输入数据特征相差明显时,用tanh的效果会很好,且在循环过程中会不断扩大特征效果并显示出来。当特征相差不明显时,sigmoid效果比较好。同时,用sigmoid和tanh作为激活函数时,需要对输入进行规范化,否则激活后的值全部都进入平坦区,隐层的输出会全部趋同,丧失原有的特征表达。而relu会好很多,有时可以不需要输入规范化来避免上述情况。因此,现在大部分的卷积神经网络都采用relu作为激活函数;
s206:通过卷积运算,进行特征提取,形成特征矩阵,其参数如下:输出:256,卷积核:3,步长:1;
s207:对上述的训练数据,进行层归一化运算;能够降低分布变化的影响,使用归一化策略,把数据分布映射到一个确定的区间,有利于快速的调整神经网络的网络结构;
s208:再使用卷积神经网络的激活函数,进行激活处理;
s209:然后通过卷积神经网络,进行最大池化操作,抽取其最大值,形成特征矩阵;其参数如下:池化窗口大小:2;池化步长:宽为2,高为2;padding:valid;卷积网络也经常使用池化层来缩减模型的大小,提高计算速度,同时提高所提取特征的鲁棒性;
s210:进行卷积运算,其参数如下:输出:512,卷积核:3,步长:1,进行特征提取,形成特征矩阵;
s211:对s210中的特征矩阵,进行卷积神经网络的归一化操作;
s212:然后再使用卷积神经网络的激活函数,进行激活处理;
s213:再进行卷积运算操作,进行特征提取,形成特征矩阵,其参数如下:输出:512,卷积核:3,步长:1;
s214:对上述产生的训练数据,进行层归一化操作;
s215:再使用卷积神经网络的激活函数,进行激活处理;
s216:然后,再次对上述产生的训练数据,再进行最大池化操作,其参数如下:卷积核大小:高为2,宽为1;步长大小:高为2,宽为1;
s217:再次进行卷积运算,进行特征提取,形成特征矩阵;其参数如下:输出:512;卷积核:2;卷积核步长:高为2,宽为1;
s218:再进行层归一化操作;
s219:然后再使用卷积神经网络的激活函数,进行激活处理。
进一步地,对s3中的基于lstm神经网络的cell组成的双向rnn的语言模型,进行特征提取,采用如下步骤:
s301:对s2中经cnn卷积神经网络提取的特征矩阵,利用双向rnn的语言模型,再次进行卷积运算处理;其参数如下:输出:64,卷积核:3,padding:vali;
s302:进行卷积运算,进行特征提取,形成特征矩阵,其参数如下:输出:64,卷积核:3,padding:same;
s303:对上述训练数据,进行层归一化运算处理;
s304:使用卷积神经网络的激活函数,进行激活处理;
s305:然后再进行池化层最大池化操作,其参数如下:池化窗口大小:2,池化步长:宽为2,高为2;padding:valid;
s306:进行卷积运算操作,进行特征提取,其参数如下:输出:128,卷积核:3,padding:same;
s307:对上述产生的训练数据,采用归一化运算处理;
s308:使用卷积神经网络的激活函数,进行激活处理;
s309:进行卷积运算,进行特征提取,形成特征矩阵,其参数如下:输出:128,卷积核:3,padding:same;
s310:对上述的训练数据,进行层归一化运算处理;
s311:使用卷积神经网络的激活函数,进行激活处理;
s312:然后再进行池化层最大池化操作,其参数如下:池化窗口大小:2;池化步长:宽为2,高为1;padding:valid;
s313:进行卷积运算,进行特征提取,形成特征矩阵,其参数如下:输出:256,卷积核:3,padding:same;
s314:对上述训练数据,进行层归一化运算处理;
s315:使用卷积神经网络的激活函数,进行激活处理;
s316:进行卷积运算,进行特征提取,形成特征矩阵,其参数如下:输出:256,卷积核:3,padding:same;
s317:对上述训练数据,进行层归一化运算处理;
s318:使用卷积神经网络的激活函数,进行激活处理;
s319:再进行池化层最大池化操作,提取其特大值,形成特征矩阵,其参数如下:池化窗口大小:2;池化步长:宽为2,高为1;padding:valid;
s320:进行卷积运算,进行特征提取,形成特征矩阵,其参数如下:输出:512,卷积核:3,padding:same;
s321:对上述训练数据,进行层归一化运算处理;
s322:使用卷积神经网络的激活函数,进行激活处理;
s323:进行卷积运算,进行特征提取,形成特征矩阵,其参数如下:输出:512,卷积核:3,padding:same;
s324:对上述训练数据,进行层归一化运算处理;
s325:使用卷积神经网络的激活函数,进行激活处理;
s326:再进行池化层最大池化操作,提取其特大值,其参数如下:池化窗口大小:宽为3,高为1;池化步长:宽为3,高为1;padding:valid。
本设计中的第二步rnn:用的是lstm的cell组成的动态双向rnn语言模型(输出为256);在改进了特征提取层之后,识别的文字用了200m的数据来训练,如图4、图5所示。
本发明中,申请人尝试过densnet和resnet以外的特征提取方法,如googlenet,nasnet等等,其最终的文字识别率远低于本发明,其识别效果较差。
本发明中的,图1为传统的文字识别方法对训练文本图片,图1的右部为文字显示为识别后的结果(反黑显示部分);经过文字识别后的效果,其识别的结果如图2所示,图2是图1的右部放大图。
本专利的具体实施中,以本发明的文字识别方法,图3中左侧的识别文本部分与图1中识别文本部分相同;图3中右侧部分为通过本发明的文字识别方法后得到的文字识别结果,如图3中右侧部分(反黑显示部分)的文字显示其识别效果,如图5所示,图5为图4的右部放大图。
上述二者的识别效果和正确率一目了然,本专利的识别率和效果优异。
本发明有益效果为:本发明所述的一种基于神经网络的文字识别方法,它基于cnn和rnn的文字识别算法,通过改进cnn和rnn层,其特征提取更加达到点子上,不会出现特征丢失和特征消失的问题,提高识别效率和正确率。
以上所述仅是本发明的较佳实施方式,故凡依本发明专利申请范围所述特征及原理所做的等效变化或修饰,均包括于本发明专利申请范围内。
- 还没有人留言评论。精彩留言会获得点赞!