一种基于分组卷积神经网络的表情识别方法与流程
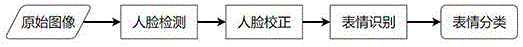
本发明涉及计算机视觉领域,尤其涉及一种基于分组卷积神经网络的表情识别方法。
背景技术:
情绪是人类在强烈心理活动下产生的认知体验,是引导社会环境中交流的重要元素。情绪的引发有多种来源,包括心情、性格、动机等。面部表情作为独特的信号传递系统,能够表达人的心理状态,是分析情绪的有效方法之一。表情识别主要有如下四个流程:人脸定位、人脸校正、特征提取和表情分类。特征提取和表情分类作为流程中的重要部分,是表情识别的核心难点问题。传统方法使用手工设计的几何特征和外观特征提取面部信息,其中几何特征基于图像中的几何属性,外观特征基于图像的灰度信息。这些方法对于特定数据分布具有很高的识别精度,但是难以处理大范围的姿态变化,泛化到其他数据集时效果差。近年来,基于数据驱动的方法备受关注。例如,卷积神经网络模型通过权值共享和下采样的方式直接从数据中学习特征,对姿态、遮挡和光线等变化具有鲁棒性。但是为了获得更高的准确率,学者不断加深模型的深度,导致模型参数量过多。这不利于模型的训练和实际应用的使用。
技术实现要素:
为解决现有技术存在的识别准确率较低,识别速度慢的技术问题,本发明提供一种基于分组卷积神经网络的表情识别方法,包括:
s1:搭建并训练分组卷积神经网络模型;
s2:提取输入图像信息;所述分组卷积神经网络模型将每个卷积层分解为深度卷积和点卷积,再将每个所述点卷积分组;
s3:搭建人脸校正器;
s4:采用人脸校正器检测并校正输入图像,获得预处理图像;
s5:采用分组卷积神经网络模型分类预处理图像中的人脸表情;
所述s2包括:
s2.1:将输入图像转换为灰度图像;
s2.2:复制灰度图像,获得三套包含同样数据的第一灰度图像,第二灰度图像,第三灰度图像;
s2.3:采用第一频道采集第一灰度图像获得第一频道数据,第二频道采集第二灰度图像获得第二频道数据,第三频道采集第三灰度图像获得第三频道数据,根据第一频道数据、第二频道数据、第三频道数据组成的卷积层输出的计算公式如下:
其中,f1为线性整流函数,f2为卷积层计算函数,卷积核为3乘3,f3为批归一化函数,xi为采集的每个像素点的值,conv为卷积,e为期望,var为方差,[·]为张量的连接,foutput为卷积层输出。
优选的,所述搭建人脸校正器采用hog特征和svm算法。
优选的,所述s4包括:通过逻辑回归树,检测输入图像中人脸的至少四个检测图像基准点,通过所述人脸校正器的至少四个校正基准点匹配所述至少四个检测图像基准点,根据所述至少四个校正基准点分割输入图像,获得预处理图像。
优选的,所述s1包括:
获取训练样本,所述训练样本包括至少1000张第一表情图像;
使用数据增广方法,将每一张第一表情图像进行旋转,和/或,裁剪,和/或,放缩,获得至少10张对应所述第一表情图像的第二表情图像;
随机抠除第二表情图像中至少一个图块,获得带有空白区域的第三表情图像;
使用第三表情图像训练分组卷积神经网络模型。
优选的,所述搭建人脸校正器采用hog特征和svm算法的步骤包括:
根据梯度直方图计算方法获得人脸图像的hog特征:
其中,
根据支持向量机原理搭建人脸svm模型;
使用获得的标准人脸图像hog特征训练人脸svm模型,获得训练结果;
使用训练结果形成人脸校正器。
优选的,根据ferplus表情识别数据库训练分组卷积神经网络模型的步骤包括:
计算梯度值
其中
优选的,利用分组卷积神经网络模型构建的至少一类分类表情分类器,根据输入核函数层的提取特征得到由所有表情的预测概率组成的向量,计算公式如下:
其中
本发明提供的技术方案在人脸定位和人脸校正的基础上,利用分组卷积神经网络模型将人脸特征提取和表情分类的流程结合在一起,以实现对人脸的表情识别,在实验室环境下单摄像头和图像处理实现了对人脸表情的识别,在保证准确率的同时还具有较高的实时性,有效地分析人脸表情信息。
附图说明
图1为本发明实施例一提供的基于分组卷积神经网络的表情识别方法的流程图。
图2为本发明实施例一提供的人脸检测器的检测示意图。
图3为本发明实施例一提供的人脸校正器的校正示意图。
图4为本发明实施例一提供的分组卷积神经网络表情识别框架图。
图5为本发明实施例一提供的分组卷积神经网络迭代周期图。
图6为本发明实施例一提供的分组卷积神经网络提取的特征图。
图7为本发明实施例一提供的分组卷积神经网络在ferplus数据集上的混淆矩阵。
具体实施方式
下面结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护范围。
实施例一
本实施例提供了一种基于分组卷积神经网络的表情识别方法,如图1-4所示。如图1所示,本实施例提供的一种基于分组卷积神经网络的表情识别方法包含四个部分:输入单帧图像、人脸检测、人脸校正、表情识别。从原始输入图像开始,经过两个环节的图像处理,然后预测人脸表情的分类。
本实施例提供的人脸检测器的具体构建过程如下:
首先,识别精度和计算时间为人机交互环境之中检测和定位人脸的两个标准,但是考虑到表情识别系统的实时性,在保证一定精度的前提之下,需要选取计算速度更快的特征和学习算法。因此,本实施例使用hog特征和svm分类器。
本实施例根据hog特征和svm算法形成人脸检测器,用于检测单帧图像之中的人脸位置。具体来说,本实施例获取训练样本,所述训练样本包括3000张lfw数据库中的人脸图像;根据方向梯度直方图的生成方法计算人脸图像的hog特征;使用提取的hog特征训练人脸检测svm模型;根据训练结果形成人脸检测器。所述hog特征梯度计算公式如下:
其中,
图2为本实施例一提供的人脸检测器的检测示意图。如图2所示,原始图像输入后,首先计算出图像的hog特征形式,然后将训练后的标准人脸hog特征与其进行比对,最后找到原始图像中人脸的位置并输出。
本实施例使用回归树集合检测人脸图块中的基准点,以对所述单帧图像之中的人脸进行校正。具体来说,获取训练样本,所属训练样本包括2000张训练人脸图像和330张测试人脸图像;使用形状不变特征分割的回归树集合对所述训练样本进行训练;使用训练结果构成人脸校正器。图3为本实施例一提供的人脸校正器的校正示意图。如图3所示,人脸图块输入后,首先计算出人脸的68个特征点,然后与标准人脸的68个特征点进行比对,最后对人脸图块进行校正。
本实施例利用分组卷积神经网络对校正后的人脸进行特征提取和预测,以获得表情分类。具体来说,搭建分组卷积网络模型;根据分组卷积和深度可分离卷积对网络模型进行优化;获得人脸表情识别数据库;使用数据增广等方法对表情数据进行预处理;使用预处理的表情图像数据集进行训练;将训练结果作为最终表情分类器。
考虑到真实环境中的应用需要高实时性,过于庞大的神经网络架构会导致计算量增加。通过减少分组卷积神经网络中的稠密块的数量和增长率,以及瓶颈层和压缩层的设置,减少模型参数量,从而使得学习更有表征性的特征。如图4所示,本实施例设计的分组卷积神经网络包含3个稠密块而且增长率设置为12,即包含3个内含12个卷积层的模块;稠密块和压缩层的超参数都设置为0.5,可以取得较好优化效果。
在提取输入图像信息时,首先将输入图像转化为灰度图像,根据上述稠密块数量的优化计算,复制灰度图像,获得三套包含同样数据的灰度图像数据,并采用三个频道分别采集三套灰度图像数据。在每个稠密块中设置12层的卷积层,每个卷积层的操作由线性整流函数、批归一化函数和3乘3的卷积计算组合成的,每一层的卷积层组合计算后生成的特征图张量将会被连接到后续的卷积层输入中。对于输入数据的频道数为3的情况下,第l层卷积网络将有
其中,f1为线性整流函数,f2为卷积层计算函数,卷积核为3乘3,f3为批归一化函数,xi为采集的每个像素点的值,conv为卷积,e为期望,var为方差,[·]为张量的连接,foutput为卷积层输出。
48乘48像素人脸图像提取出的标准hog特征维数为324,相比于以原始像素为特征的维数减少了85.94%。根据梯度提取的区域大小,hog特征维数范围为324-576。
在每个稠密块的中间存在过渡层,目的是完成参数压缩和调整计算变量。经过3个稠密块后,模型计算的特征张量将会输入全连接网络层,该层联合核函数将图像中提取的特征映射成1×7的向量,其中每个位置的值代表该类别表情的自信度,由所有表情的预测概率组成的向量计算公式如下
其中
本实施例利用分组卷积神经网络训练表情分类器。对于深度卷积神经网络模型而言,为了达到高准确率,需要大量的训练数据,故本实施例采用ferfin数据集作为训练数据集。ferfin数据集改进自fer2013数据集,包含“中立”图像12858例、“开心”图像9354例、“惊讶”图像4462例、“悲伤”图像4351例、“愤怒”图像3082例、“厌恶”图像575例和“害怕”图像816例,总计35498例48乘48像素的灰白人物表情图像。
考虑到表情识别任务中存在的姿态、光线、遮挡等变化,因此本实施例分两步对ferfin数据库进行处理。针对每一张图片使用数据增广方法,将原始图片翻转、旋转、裁剪、放缩和变形获得十二张新图片;将新图片随机截取走16乘16像素的图块,获得带有空白区域的图片。
为了加快分组卷积网络模型的收敛速度,本实施例使用下述动量方法替代常规的梯度下降方法获得梯度,动量方法计算公式如下:
其中
如图5所示,使用分组卷积和深度可分离卷积优化后的网络模型在ferplus数据集上的学习曲线,横坐标表示训练的迭代周期(epoch),纵轴表示在验证数据集上的准确率。densenet-1,2,3分别拥有3,3,4个denseblock,其中densenet-1,2的每个denseblock中包含12层卷积层,而densenet-3的卷积层数依次是6,12,24,16。前两个模型是经过调试,尝试在降低模型复杂度的同时增加准确率而获得的预料不到的最佳的模型,第三个模型则是参考国际图像分类大赛中的卷积模型使用的卷积层层数而设定的。可以看到,三个模型在学习过程中的准确率都在25个迭代周期内达到75%以上,并且波动小,收敛快。
如图6所示,为所使用的优化densenet网络提取的特征图,从左往右表示所提取的特征随着denseblock的增加而更加抽象。使用densenet-2模型,采用4个denseblock,卷积层层数依次是6,12,24,16。可以看到最后特征图中,模型的关注点在于特殊的几何图形,这些图形可能涵盖了所有在“开心”类别图像中出现的纹理线条。
如图7所示,所使用模型在ferplus数据集上的混淆矩阵,使用的是densenet-2模型,采用4个denseblock,卷积层层数依次是6,12,24,16。其中在针对“开心”类别,准确率和召回率分别达到了96.07%和96.67%,f1参数值为91.61%。在厌恶类别表现最差准确率为88.24%,召回率为50%,一部分原因在于数据集中的“厌恶”类别数据较少且难以分辨区别。
本发明提供的基于分组卷积神经网络的表情识别方法包括:预处理人脸表情数据,训练分组卷积神经网络模型获得表情分类器,训练人脸检测器,训练人脸校正器,基于单帧图像的人脸检测,基于单帧图像的人脸校正和记录,基于单帧图像的表情识别,获得表情分类。本实施例通过优化之后的分组卷积神经网络的表情模型,使用实验室环境下的单摄像头和网络传输方案实现了在线的表情识别,在保证准确率的同时还具有较高的实时性。
以上所述的具体实施例,对本发明的目的,技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!