一种基于LSTM的空气污染分析方法与流程
本发明涉及基于观测点数据的空气污染分析问题,提出了一种基于lstm的空气污染分析方法。
背景技术:
空气污染分析是利用空气中某些气体成分的特征及其时空分布,并通过特定的分析方法对空气进行预测和溯源。该技术在天气预测,大气污染治理等领域具有非常重要的研究及应用价值。
随着经济、工业化的快速发展,中国的空气质量迅速恶化。空气污染已经成为中国最严重的环境问题之一。要知道如何治理需要知道大气污染的预测和大气污染源头,实现对空气污染源的快速定位,能够帮助决策者更加准确找到空气污染的源头,从而做出可靠的决策。
目前对空气溯源研究的比较少,而现在的空气溯源并不能解决小范围实时监测空气污染并快速、准确的找到污染源。
因此,采用一种基于lstm的空气污染分析方法来处理空气污染溯源问题就显得尤为重要。
技术实现要素:
本发明针对现有技术的不足,提供一种基于lstm的空气污染分析方法,包括以下步骤:
步骤1,构造空气扩散模型:将某地区的各个观测站,以及他们之间的关系进行区域化划分,利用各个观测站之间的空气信息和气象信息,来构造空气扩散模型。
步骤2,对监测点进行预测分析:根据监测点的历史数据,运用lstm结合步骤1构造的空气扩散模型,对监测点的空气进行预测。
步骤3,单点溯源分析:根据步骤2得到的各个区域对监测点的空气预测的影响权重,结合空气扩散模型对影响权重加权距离数值化,并定位污染源点。
在上述的一种基于lstm的空气污染分析方法,所述步骤1具体包括:
步骤1.1,根据得到的风向可以判断空气污染粒子的流动方向和风速
步骤1.2,选取所有观测站中一个站点,根据该选取的站点与相邻站点之间的空间关系进行区域划分,以该选取的站点为中心,根据风向的八个方向将区域划分为八块,相邻的站点在这八块区域里面。
步骤1.3,基于粒子实际运动速度,可得到粒子在这区域内的运动轨迹y:
步骤1.4,重复步骤1.2-步骤1.3直至所有观测站中的站点全部划分完毕。
在上述的一种基于lstm的空气污染分析方法,所述步骤2具体包括:
步骤2.1,构建相邻站点对中心站点的污染贡献值m(t)。构建相邻站点j对中心站点的污染贡献值m(t),m(t)=m(t-1)*(1-kt-1*t)。粒子运动衰减因子为:
步骤2.2,将空气历史数据(包括pm2.5、so2、等气体监测参数)与污染贡献值m(t)进行数据融合并进行归一化处理,得到lstm输入x。x={x1,x2,x3.......xn},n为序列长度。
步骤2.3,通过lstm对空气数据进行学习,并把学习后得到的训练值与测试集进行比对调优,得到高精度的预测值。
步骤2.4,得到空气预测值ht和各个时刻相邻站点对中心站点的影响权重yt,yt={y1,y2,.....yn}。
在上述的一种基于lstm的空气污染分析方法,所述步骤2中通过lstm算法的得到高精度的预测值具体步骤流程如下:
步骤4.1,计算遗忘门ft,遗忘门ft是以上一时刻的输出ht-1和现在时刻的输入xt为输入的,ft=σ(wf*[ht-1,xt]+bf),上式中,wf是遗忘门的权重矩阵,[ht-1,xt]表示把两个向量连接成一个更长的向量,bf是遗忘门的偏置项,σ为sigmoid函数。wf为0-1之间的随机初始值,bf的初始值为0.
步骤4.2,计算输入门it,输入门it和一个tanh函数配合控制有哪些新信息加入,it=σ(wi*[ht-1,xt]+bi),其中wi是输入门的权重矩阵,bi是输入门的偏置项。wi为0-1之间的随机初始值,bi的初始值为0.
步骤4.3,计算输出门ot,ot=σ(wo*[ht-1,xt]+bo)。w0为0-1之间的随机初始值,b0的初始值为0.
步骤4.4,得到空气预测值ht和各个时刻相邻站点对当前站点的影响权重yt,yt={y1,y2,.....yn},n表示有当前站点有n个相邻站点。
在上述的一种基于lstm的空气污染分析方法,所述步骤3具体包括:
步骤3.1,在k时刻预测t时刻的空气数据,t>k。设置偏差系数q偏差系数可以随意设定,偏差系数也可称为偏差率,当在k时刻预测到t时刻的预测值与在t时刻监测的实际值的误差超过偏差系数时,开始进行污染源定位溯源。
步骤3.2,基于空气预测算法得到的各个时间步相邻站点对中心站点的影响权重yt,根据t时刻相邻站点对中心站点的影响权重yt和粒子的运动速度
步骤3.3,对加权距离权重计算进行迭代计算。
步骤3.4,每溯源一个时间步,计算相邻站点的影响权重,当相邻各个站点的影响权重yt都为0时,停止迭代计算并得到t-n时刻的坐标点c,坐标点c为污染源点。根据权利要求2所述的一种基于lstm的空气污染分析方法,其特征包括:以当前站点为中心,根据风向的八个方向将区域划分为八块。
因此,本发明具有如下优点:1.空气传感器采用分布式网络搭建,可以实时、较全面的获取空气数据和气象数据。2.利用一定时空的污染物数据,采用lstm算法能准确的预测空气数据。3.利用加权距离权重可以较快速、准确的找到污染源点。
附图说明
图1为本发明一种基于lstm的空气污染分析方法的步骤流程图。
图2为构造空气扩散模型步骤流程图。
图3为监测点进行预测分析步骤流程图。
图4为单点溯源分析的步骤流程图。
图5为单点溯源分析的溯源坐标说明图。
具体实施方式
下面将结合附图和实施例对本发明作进一步的详细说明。
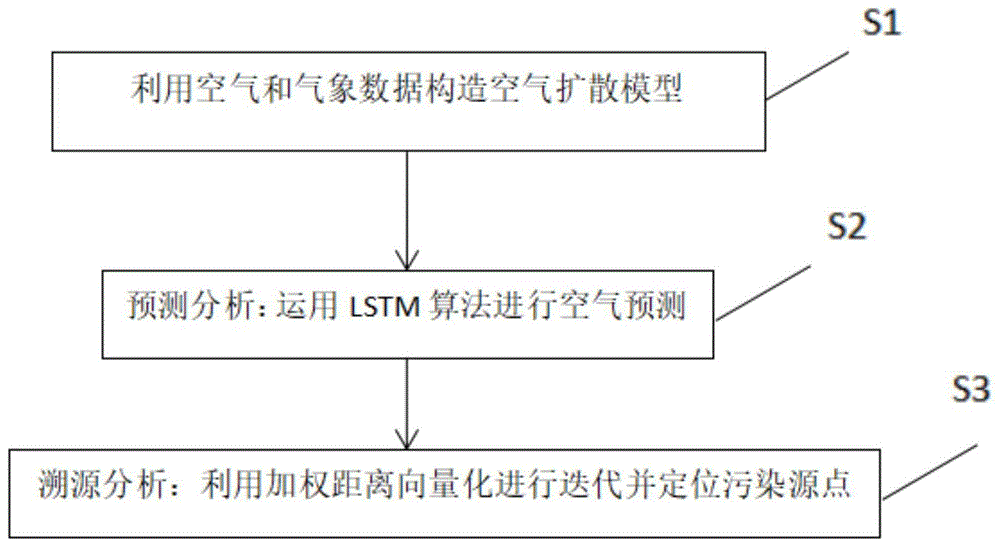
本发明的一种基于lstm的空气污染分析方法,流程如图1所示,包括以下步骤:
步骤s1:利用空气和气象数据构造空气扩散模型;
步骤s2:运用lstm算法进行空气预测;
步骤s3:利用加权距离向量化进行迭代并定位污染源点。
下面将对每个步骤进行具体的说明:
步骤s1实现了空气扩散模型的构造,利用获得的空气数据和气象数据来构建空气模型,并根据站点进行区域划分。图2给出了该方法的具体流程如下:
根据得到的风向可以判断空气污染粒子的流动方向和风速
根据当前站点(指将所有观测站逐一分别作为当前站点)与相邻站点之间的空间关系进行区域划分,以当前站点为中心,根据风向的八个方向将区域划分为八块,相邻的站点在这八块区域里面。
基于粒子实际运动速度,可得到粒子在这区域内的运动轨迹y:
步骤s2实现了空气的预测,利用lstm算法来对监测站点的空气做预测计算。图3给出了该方法的具体流程如下:
构建相邻站点对中心站点的污染贡献值m(t)。以相邻站点j对中心站点的粒子的污染贡献值为例,则粒子从相邻站点j运动到中心站点i中从t-1时刻到t时刻的现存的污染贡献值m(t)为:m(t)=m(t-1)*(1-kt-1*t)。粒子运动衰减因子为:
将空气历史数据(包括pm2.5、so2、等气体监测参数)与污染贡献值m(t)进行数据融合并进行归一化处理,得到lstm输入x。x={x1,x2,x3.......xn},n为序列长度。
通过lstm对空气数据进行学习,并把学习后得到的训练值与测试集进行比对调优,得到高精度的预测值。
得到空气预测值ht和各个时刻相邻站点对中心站点的影响权重yt,yt={y1,y2,.....yn}。
lstm算法的流程如下:
(1)计算遗忘门ft,遗忘门ft是以上一时刻的输出ht-1和现在时刻的输入xt为输入的,ft=σ(wf*[ht-1,xt]+bf),上式中,wf是遗忘门的权重矩阵,[ht-1,xt]表示把两个向量连接成一个更长的向量,bf是遗忘门的偏置项,σ为sigmoid函数。wf为0-1之间的随机初始值,bf的初始值为0.
(2)计算输入门it,输入门it和一个tanh函数配合控制有哪些新信息加入,it=σ(wi*[ht-1,xt]+bi),其中wi是输入门的权重矩阵,bi是输入门的偏置项。wi为0-1之间的随机初始值,bi的初始值为0.
(3)计算输出门ot,ot=σ(wo*[ht-1,xt]+bo)。w0为0-1之间的随机初始值,b0的初始值为0.
(4)得到空气预测值ht和各个时刻相邻站点对当前站点的影响权重yt,yt={y1,y2,.....yn},n表示有当前站点有n个相邻站点。
步骤s3实现了空气的溯源,利用加权距离向量化并进行迭代后定位污染源点。图4、图5给出了该方法的具体流程如下:
在k时刻预测t时刻的空气数据,t>k。设置偏差系数q偏差系数可以随意设定,偏差系数也可称为偏差率,当在k时刻预测到t时刻的预测值与在t时刻监测的实际值的误差超过偏差系数时,开始进行污染源定位溯源。
基于空气预测算法得到的各个时间步相邻站点对中心站点的影响权重yt,根据t时刻相邻站点对中心站点的影响权重yt和粒子的运动速度
对加权距离权重计算进行迭代计算。
每溯源一个时间步,计算相邻站点的影响权重,当相邻各个站点的影响权重yt都为0时,停止迭代计算并得到t-n时刻的坐标点c,坐标点c为污染源点。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何属于本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!