一种面向非规则程序的自适应线程划分方法与流程
本发明属于计算机技术领域,具体涉及一种面向非规则程序的自适应线程划分方法。
背景技术:
多核时代到来,使传统的并行编程模式和编译技术面临着新的挑战。实现串行程序在多核上执行的一个有效方法是串行程序并行化,既解决了传统串行程序的改造,又合理利用了日益发展且丰富的核资源。传统的并行化方法,比如:openmp,mpi,tbb,opencl,cuda等多采用保守的方法解决依赖问题,即采用同步或通信来序列化存在依赖关系的并发单位(线程或者进程),导致非规则程序的并行化效果不佳。线程级推测(thread-levelspeculation,tls),即推测多线程技术,允许并发单位之间的数据依赖而激进地并行执行,克服了传统并行化方法不能有效消解线程级模糊依赖关系的局限,用于并行化非规则程序展现出好的前景。线程划分是tls实现在串行程序中插入线程划分语句的关键步骤,是程序推测并行化的核心环节,直接影响加速比性能,因此,对线程划分方法的研究刻不容缓。
已有的线程划分方法主要分为:基于启发式规则的线程划分方法、基于机器学习的线程划分方法和基于图的线程划分方法等。前者在线程划分中,依据启发式规则确定线程划分方案,在程序执行流程路径上确定线程划分语句的插入位置;后两者利用机器学习方法学习样本中的线程划分知识,并根据程序特征预测线程划分方案,利用划分方案执行程序划分。上述线程划分方法在划分规则或划分知识指导下为同类程序生成统一线程划分方案。但是,对于未知程序,其复杂性和执行状态难以预测,使用统一线程划分方案难以确保最大程度提升加速比性能。
为了解现有线程划分方法的发展状况,对现有的论文和专利进行了检索、比较和分析,筛选出如下与本发明相关度比较高的技术信息:
技术方案1:基于启发式规则的线程划分方法(heuristicrules-based(hr-based)threadpartitionapproach)在划分串行程序过程中,依据启发式规则确定所有程序划分后生成的线程粒度、线程之间的数据依赖、激发距离等参数的取值范围,从而确定划分标志(sp-cqip点)的位置。
题目《min-cutprogramdecompositionforthread-levelspeculation》的论文,利用图的最小割算法划分程序流图,使用启发式来平衡数据依赖、性能代价、加载不平衡等因素的代价,程序划分后获得了性能提升。
题目《ageneralcompilerframeworkforspeculativemultithreading》的论文,找出程序执行的关键路径上利用启发式规则确定线程划分后各个线程的粒度、优先级等。
题目《mitosis:aspeculativemultithreadedprocessorbasedonprecomputationslices》的论文,为了减小激发对(sp-cqip)的搜索空间,使用启发式规则选择候选激发对。在选择过程中,贡献率小于贡献阈值的激发对被放弃,激发对要同时在相同的过程内或者循环体中,激发对的长度小于长度阈值,sp到cqip的概率要大于概率阈值,precomputation-slice(p-slice)长度和推测线程大小比例小于比例阈值。
技术方案2:基于机器学习的线程划分方法(machinelearning-based(ml-based)threadpartitionapproach)利用机器学习方法学习样本集中的线程划分知识,并根据新输入程序的特征预测其划分方案,利用该划分方案指导该程序过程的划分。
题目《基于模糊聚类的推测多线程划分算法》的论文利用聚类方法搜索有效线程解空间来获得较优的线程划分。
题目《anovelthreadpartitioningapproachbasedonmachinelearningforspeculativemultithreading》的论文提出了一个基于knn的线程划分方法。该方法主要包含两个部分:训练样本集的产生和提取样本集中蕴含的划分知识,并利用每一个未知程序和样本之间的相似度选择k个最相似的样本来决定该程序的线程划分方案。
题目《partitioningstreamingparallelismformulti-cores:amachinelearningbasedapproach》的论文在一个移动和自动的编译器上使用机器学习方法划分流程序,离线学习先验知识并预测未知程序的划分结构。
题目《optimizingpartitionthresholdsinspeculativemultithreading》的论文提取影响线程划分的五个主要影响参数,并利用层遍历的方法优化这五个参数,从而为程序获得较优的线程划分方案。
题目《qinling:aparametricmodelinspeculativemultithreading》的论文利用一个线性回归方法发掘线程划分参数和加速比之间的规律,提取出非规则程序的划分方案。
题目《usingartificialneuralnetworkforpredictingthreadpartitioninginspeculativemultithreading》利用人工神经网络学习线程划分知识,并预测未知程序的划分方案
技术方案3:基于图的线程划分方法利用程序的加权控制流图(weightedcontrolflowgraph,wcfg)较全面的涵盖程序特征信息,并执行wcfg不同路径上的综合划分。
题目《agraph-basedthreadpartitionapproachinspeculativemultithreading》的论文,提出了一个基于图的线程划分方法,在该方法中,用加权控制流图来形式化表达非规则程序,并利用机器学习方法学习线程划分知识和预测未知程序的划分方案,且生成的划分方案应用于程序的各个过程中。
题目《gba:agraph-basedthreadpartitionapproachinspeculativemultithreading》的论文,提出了一个基于图的线程划分方法,在该方法中,用程序的加权控制流图(wcfg)来形式化表达非规则程序,并利用机器学习方法学习线程划分知识和为未知程序预测出一个线程划分方案。
题目为《improvinggraphpartitioningformoderngraphsandarchitectures》的论文,针对稀疏非规则数据进行图划分,提出一个多线程图划分器mt-metis,并在36核上使用多个领域中20幅不同图进行实验,验证了方法的有效性。
技术方案1,2,3分别使用不同的方法实现了基于启发式规则的线程划分,基于机器学习的线程划分,基于图的线程划分。然而,这些方案中均存在一些缺陷。
技术方案1通过启发式规则来规定线程划分时线程粒度、线程间依赖度、激发距离等的上下限,进而指导线程划分标志位(sp-cqip)的插入位置。相比其他方法,该方案具有简单、易操作的优势。然而,却存在着统一划分规则使用于所有待划分程序,导致部分程序线程划分后得不到最佳的性能提升。
技术方案2利用机器学习方法学习样本中线程划分知识,并根据待划分程序和样本的相似度比较,使用最相似样本的划分方案来指导该待划分程序,进行实行线程划分。基于机器学习的线程划分方法具有智能、自动划分等优势,然而和方案1相比,都存在着线程划分的最小单元是程序,不是程序的过程问题。然而,线程划分操作是以程序中过程为单位进行的,因此导致程序中部分过程得不到最佳性能提升。
技术方案3提出了一个基于图的线程划分方法,在该方法中,用加权控制流图来形式化表达非规则程序,并利用机器学习方法学习线程划分知识和为未知程序预测出一个线程划分方案。该方案能够充分挖掘程序的特征信息,然而也存在着程序中过程得不到个性化划分,程序性能得不到最大程序提升。
从目前国内外对非规则程序线程划分方法的研究现状来看:基于启发式规则的线程划分方法具有简单、易操作的优势;基于机器学习的线程划分方法具有智能、自动划分等优势;基于图的线程划分方法能够更加全面表达程序的数据和控制信息。但是,综上所述,已有的线程划分方法针对同一类非规则程序多采用统一的线程划分方案,且很少关注程序的复杂性和执行状态等方面,从而严重影响到串行程序并行化的效率。
技术实现要素:
本发明所要解决的技术问题是在多核平台上提供一种面向非规则程序的自适应线程划分方法,解决现有的线程划分方法针对同一类非规则程序多采用统一的线程划分方案,且很少关注程序的复杂性和执行状态等方面,从而严重影响到串行程序并行化的效率等问题。
本发明为解决上述技术问题所采用的技术方案是:一种面向非规则程序的自适应线程划分方法,包括以下步骤:
步骤一、建立非规则程序的复杂度计算模型
1.1、采用形式化表达,以基本块为分析单元构建程序的cfg图,通过程序剖析获得的特征值以注释的形式被添加到cfg图上构成加权控制流图;
1.2、基于概率统计和图遍历,对加权控制流图上可能存在的各条路径的复杂度即分复杂度进行计算;
1.3、整合分复杂度,获得程序的整体复杂度。
步骤二、构建符合程序上下文的候选线程划分方案集
采用融合程序上下文和程序特征的方法构建候选线程划分方案集,先以程序特征为基础构建初始候选集,在此基础上基于程序上下文参数值对其进行过滤,生成最终候选线程划分方案集。
步骤三、构建符合程序复杂度的线程划分方案选择机制
从步骤一和步骤二分别得到程序复杂度和候选线程划分方案集后,依据专家知识,建立“程序复杂度→线程划分方案”的方案选择映射规则集;根据映射规则和程序复杂度,执行上下文,选出候选划分方案集中最适合的线程划分方案。
本发明所述规则集用于存储推理所用的专家知识,在规则集中,线程划分方案选择机制的专家知识用映射规则表示,专家知识映射规则表示的一般形式为if<condition>,then<conclusion>。
本发明的有益效果是:(1)本发明着重研究在多核平台上面向非规则程序的自适应线程划分方法,搭建程序复杂度计算模型,立足经典线程划分方法构建候选划分方案集,依据专家知识建立线程划分方案选择机制,兼顾上下文和程序复杂度选择最适合程序的线程划分方案,能够实现程序的最佳划分,从而充分利用多核资源,和最大程度挖掘出非规则程序的潜在并行性。
(2)本发明拟利用自适应机制,在复合型线程划分方法的基础上,根据程序特征和上下文自适应地选择出其最适合的线程划分方案,不仅能够解决多核平台和程序串行执行的矛盾问题,也能够提升串行程序并行化后加速比性能,可为多核处理器设计提供新方法。
(3)本发明的自适应线程划分方法,在有效解决非规则串行程序在多核平台上并行化问题的同时,也推动了并行技术的进步,促进了高性能计算、云计算等相关产业的健康、良性和快速发展,具有较好的应用前景和实用价值。
附图说明
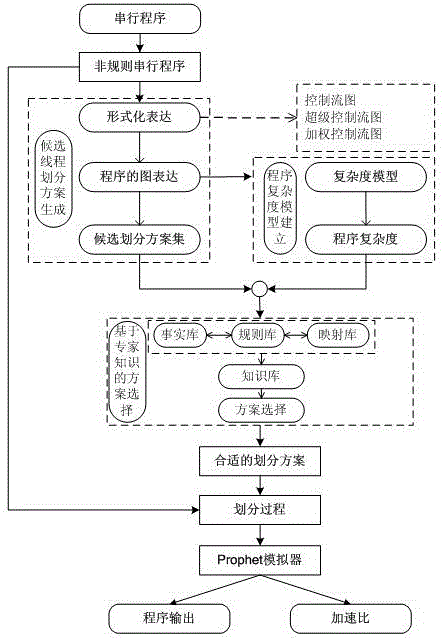
图1为本发明自适应线程划分方法的整体流程示意图;
图2为本发明程序的复杂度计算流程示意图;
图3为本发明构建候选线程划分方案集的流程示意图;
图4为线程划分方案选择机制流程示意图。
具体实施方式
下面结合说明书附图对本发明的具体实施方式(实施例)进行描述,使本领域的技术人员能够更好地理解本发明。
本发明自适应线程划分方法的整体方案及流程如图1所示。以非规则串行程序作为输入,以程序复杂度计算模型建立、候选线程划分方案生成、基于专家知识的划分方案选择为主要研究点,选择出程序最适合的线程划分方案来执行线程划分,在prophet模拟器上获得加速比值和程序运行结果。
(1)非规则程序的复杂度计算模型的建立
影响线程划分的程序特征很多,如数据依赖、控制依赖、分支个数、基本块个数、平均动态指令数、循环结构的嵌套层数、过程调用个数等。这些特征的值反映出程序的复杂性(复杂度是复杂性的度量值)。现有的线程划分方法多数不能充分考虑程序复杂度对线程划分的影响,仅仅选取程序特征作为线程划分方法的输入,容易导致不同线程划分方法选取的程序特征不统一、生成的线程划分方案不够准确等问题。
本发明的程序复杂度计算模型首先采用形式化表达,以基本块为分析单元构建程序的cfg图,通过程序剖析获得的特征值,以注释的形式被添加到cfg图上构成加权控制流图(wcfg);基于概率统计和图遍历,对wcfg上可能的各条路径的复杂度(即分复杂度)进行计算;最后,整合分复杂度,获得程序的整体复杂度。图2给出了程序复杂度计算的流程图。
在图2中,p代表输入的非规则串行程序,g(p)代表wcfg,f1~fn(n∈n)代表程序特征,f1()~fn()(n∈n)代表转换函数,comp1()~compn()(n∈n)代表各个路径的复杂度,comp代表p的总复杂度。在模型中,首先,未知程序p经过形式化表达,转成wcfg,即g(p);其次,对g(p)中可能的各条路径(从头结点到尾结点)上进行特征提取,分别用f1~fn(n∈n)来表示;再次,用转换函数f1()~fn()(n∈n)实现特征值到复杂度的映射,比如:基本块个数x对应的复杂度为0.01×x,循环个数y对应的复杂度为0.2×y等;然后,对g(p)中各条路径的复杂度comp1()~compn()进行分别计算;最后,对各条路径的复杂度进行汇总,得出程序p的复杂度。
(2)符合程序上下文的候选线程划分方案集的构建
采用融合程序上下文和程序特征的方法构建候选线程划分方案集,先以程序特征为基础构建初始候选集,在此基础上基于程序上下文参数值对其进行过滤,生成最终候选线程划分方案集。图3给出了候选线程划分方案集的构建流程。
在图3中,p代表非规则串行程序,f1~fn代表程序特征,formal(p)代表p的形式化表达,m1~mn(n∈n)代表n个经典线程划分方法,schem1~schemn代表n个线程划分方案。线程划分方法编号为:基于启发式规则线程划分方法(m1)编号为1,基于机器学习的线程划分方法(m2)编号为2,基于图关键路径的线程划分方法(m3)编号为3,基于图全路径的线程划分方法(m4)编号为4,混合线程划分方法(m5)编号为5等。路径编号分别是:关键路径编号为1,其他非关键路径编号为2~n(n∈n)。线程划分方案是由线程划分方法编号,路径编号和线程划分算法中影响线程划分结果的五个主要参数构成(五个参数分别是:激发距离上限(upperlimitofspawningdistance,ulosd)、激发距离下限(lowerlimitofspawningdistance,llosd)、数据依赖数(datadependencecount,ddc)、线程粒度上限(upperlimitofthreadgranularity,ulotg)、线程粒度下限(lowerlimitofthreadgranularity,llotg))。通过引入上下文参数δ1~δn(n∈n),使得本发明中线程划分方法是上下文可知的,也使构建的候选线程划分方案集更能捕获程序状态的变化。
(3)符合程序复杂度的线程划分方案选择机制的构建
在上述步骤(1)和(2)分别计算出程序复杂度和构建候选线程划分方案集后,依据专家知识,建立“程序复杂度->线程划分方案”的方案选择的映射规则集;根据映射规则和程序复杂度、执行上下文,选出候选划分方案集中最适合的线程划分方案。图4给出了线程划分方案选择机制流程图。
规则集用于存储推理所用的专家知识。在规则集中,线程划分方案选择机制的专家知识用产生式规则(又称映射规则)表示。产生式规则把知识表示分为前提和结论两部分。专家知识产生式规则表示的一般形式是if<condition>,then<conclusion>,例如:
(i)if<复杂度comp∈[0.8,1.0]>,then<选择schem1’>;
(ii)if<复杂度comp∈[0.6,0.8)>,then<选择schem2’>;
(iii)if<复杂度comp∈[0.4,0.6)>,then<选择schem3’>;
(iv)if<复杂度comp∈[0.2,0.4)>,then<选择schem4’>;
(v)if<复杂度comp∈(0.0,0.2)>,then<选择schem5’>。
schem1’~schem5’是由上述步骤(2)产生的候选线程划分方案集中选出的划分方案,由程序的复杂度和规则来决定。以上给出产生映射规则的部分案例。
本发明利用自适应机制,提出面向非规则程序的自适应线程划分方法,旨在实现最大程度提升非规则程序的加速比性能这一总体研究目标,为新兴并行技术的广泛应用和健康发展,提供必要和亟需的线程划分方法和相关基础理论。
(1)程序加速比性能的最大提升
通过研究程序特征和线程划分方案之间的关系,建立复合型线程划分方案,利用自适应机制和专家知识的指导,使程序自主选择出并执行最适合的划分方案,获取最大加速比值。
(2)探索程序特征影响加速比性能的规律
通过分析影响程序并行化的因素,建立程序复杂度模型、候选线程划分方案集、划分方案选择机制,探索出程序特征影响其加速比性能的规律,为多核平台上非规则程序并行化提供方法上的支持。
- 还没有人留言评论。精彩留言会获得点赞!