一种提高机器翻译准确度的方法及其装置与流程
本发明涉及机器翻译技术领域,特别涉及一种提高机器翻译准确度的方法及其装置。
背景技术:
目前,现有的主流机器翻译方法是基于端到端的神经机器翻译方法,利用大规模双语平行语料,通过encoder-decoder神经网络框架进行模型训练。为了更好地表达原文本的含义,许多方法是通过将外部资源,如句法信息、短语信息等融入到模型训练中。神经网络内部操作复杂,无法保证输入文本被正确翻译,容易出现错翻、漏翻等现象;获取的外部资源,例如通过句法分析器获取的句法信息,无法保证其准确性,而错误信息的引入会影响模型翻译的效果。
技术实现要素:
本发明提供一种提高机器翻译准确度的方法及其装置,用以解决神经网络内部操作复杂,无法保证输入文本被正确翻译,容易出现错翻、漏翻的情况。
一种提高机器翻译准确度的方法,其特征在于,包括:
确定双语平行语料中的源语料和目标语料;
根据预设的关键语义要素抽取分类网络,获取所述目标语料中每个句子的关键语义,并确定所述关键语义在句子中的位置信息;
根据所述位置信息,基于encoder-decoder框架增加所述关键语义在句子中的权重;
通过encoder-decoder框架对增加权重后的目标语料和源语料进行训练,确定翻译模型。
作为本发明的一种实施例:所述确定双语平行语料中的源语料和目标语料,包括:
获取现有的双语平行语料数据,对所述双语平行语料数据中的句子进行断句分词处理,获取断句分词后的双语语料集;
根据预设的文本转化规则,将所述语料集转化为双语语料文本;
根据所述双语料文本的语义,确定所述双语语料文本中的关键语义和非关键语义;
根据所述关键语义的权重,确定目标语料;
通过所述关键语义和非关键语义和所述现有的双语平行语料数据匹配,确定源语料。
作为本发明的一种实施例:所述根据预设的关键语义要素抽取分类网络,获取所述目标语料中每个句子的关键语义,并确定所述关键语义在句子中的位置信息之前,还包括:
获取现有的单语语料数据,对所述单语语料进行分类处理,确定分类处理后的单语语料文本;
根据所述单语语料文本中的语义,确定所述单语语料文本的关键语义和非关键语义,并对所述关键语义和非关键语义分别进行标记,获取标记单语语料;
将所述标记单语语料作为训练数据构建关键语义要素抽取网络;
根据所述关键语义要素抽取网络,通过双向lstm来建模所述单语语料文本的词语级的向量表示,然后利用所述向量表示进行所述关键语义和非关键语义的二分类训练,得到关键语义要素抽取分类网络。
作为本发明的一种实施例:所述根据所述位置信息,基于encoder-decoder框架增加所述关键语义在句子中的权重,包括:
获取端到端的encoder-decoder框架,通过所述encoder-decoder框架读取源语料,确定所述源语料的源序列;
通过所述encoder-decoder框架中的encoder模块将所述源序列转成固定维度的第一向量表示,并输入到所述encoder-decoder框架的encoder-decoderattention端;
通过所述encoder-decoder框架读取所述目标语料,确定所述目标语料的目标序列;
经过所述encoder-decoder框架的decoder模块将输入的所述目标序列转成固定维度的第二向量表示,并输入到所述encoder-decoderattention端,所述encoder-decoderattention端根据所述关键语义,确定所述关键语义在句子中的位置信息,并增加所述关键语义在句子中的权重。
作为本发明的一种实施例:所述通过encoder-decoder框架对增加权重后的目标语料和所述源语料进行训练,确定翻译模型之前,还包括:
将所述增加权重的关键语义通过下式(1)进行softmax计算,确定翻译顺序;
其中,所述s(z)i表示翻译第i个单词的概率;所述e表示zi的底数;zi表示第i个词的向量;所述c表示类别个数;所述j表示第j个单词;
根据所述翻译顺序,实现梯度回转。
一种提高机器翻译准确度的装置,其特征在于,包括:
第一确定模块:用于在双语平行语料中确定源语料和目标语料;
第二确定模块:用于根据预设的关键语义要素抽取分类网络,获取所述目标语料中每个句子的关键语义,并确定所述关键语义在句子中的位置信息;
处理模块:用于根据所述位置信息,基于encoder-decoder框架增加所述关键语义在句子中的权重;
第三确定模块:用于通过encoder-decoder框架对增加权重后的目标语料和所述源语料进行训练,确定翻译模型。
作为本发明的一种实施例,所述第一确定模块包括:
第一获取单元:用于获取现有的双语平行语料数据,对所述双语平行语料数据中的句子进行断句分词处理,获取断句分词后的双语语料集;
第一转化单元:用于根据预设的文本转化规则,将所述语料集转化为双语语料文本;
第一确定单元:用于根据所述双语料文本的语义,确定所述双语语料文本中的关键语义和非关键语义;
第二确定单元:用于根据所述关键语义的权重,确定目标语料;
第三确定单元:通过所述关键语义和非关键语义和所述现有的双语平行语料数据匹配,确定源语料。
作为本发明的一种实施例,所述第二确定模块包括:
第四确定单元:用于获取现有的单语语料数据,对所述单语语料进行分类处理,确定分类处理后的单语语料文本;
第二获取单元:用于根据所述单语语料文本中的语义,确定所述单语语料文本的关键语义和非关键语义,并对所述关键语义和非关键语义分别进行标记,获取标记单语语料;
第一网络构建单元:用于将所述标记单语语料作为训练数据构建关键语义要素抽取网络;
第一处理单元:根据所述关键语义要素抽取网络,通过双向lstm来建模所述单语语料文本的词语级的向量表示,然后利用所述向量表示进行所述关键语义和非关键语义的二分类训练,得到关键语义要素抽取分类网络。
作为本发明的一种实施例,所述处理模块包括:
第五确定单元:用于获取端到端的encoder-decoder框架,通过所述encoder-decoder框架读取源语料,确定所述源语料的源序列;
第二处理单元:用于通过所述encoder-decoder框架中的encoder模块将所述源序列转成固定维度的第一向量表示,并输入到所述encoder-decoder框架的encoder-decoderattention端;
第六确定单元:用于通过所述encoder-decoder框架读取所述目标语料,确定所述目标语料的目标序列;
第三处理单元:用于通过所述encoder-decoder框架的decoder模块将输入的所述目标序列转成固定维度的第二向量表示,并输入到所述encoder-decoderattention端,所述encoder-decoderattention端根据所述关键语义,确定所述关键语义在句子中的位置信息,并增加关键语义在句子中的权重。
作为本发明的一种实施例,所述装置还包括:
第二处理模块:用于将所述增加权重的关键语义通过下式(1)进行softmax计算,确定翻译顺序;
其中,所述s(z)i表示翻译第i个单词的概率;所述e表示zi的底数;zi表示第i个词的向量;所述c表示类别个数;所述j表示第j个单词;
根据所述翻译顺序,实现梯度回转。
本发明的有益效果在于:通过对目标语料中的关键语义进行标记,并在训练中增加其权重,使得decoder端在解码时更加关注该部分信息,降低了原文本中关键语义错翻、漏翻的概率,从而使得decoder端更忠实于原文本的含义;关键语义的抽取本质上是句子本身信息的抽取,虽然关键语义要素抽取网络无法做到完成正确地抽取出句子中的关键语义,但抽取出的内容仍然是句子本身的语义,这样可以在一定程度上避免因外部资源引入而产生的一些错误判断。
本发明的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过在所写的说明书以及附图中所特别指出的结构来实现和获得。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1为本发明实施例中一种提高机器翻译准确度的方法的算法流程图;
图2为本发明实施例中一种提高机器翻译准确度的装置的装置模块图;
具体实施方式
以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。
双语平行语料是原文为一种语言,翻译文为另一种语言,为平行设置的语料库,例如英汉双语平行语料库是以句子为单位,原文为英文,译文为中文的句句对应的双语语料库。
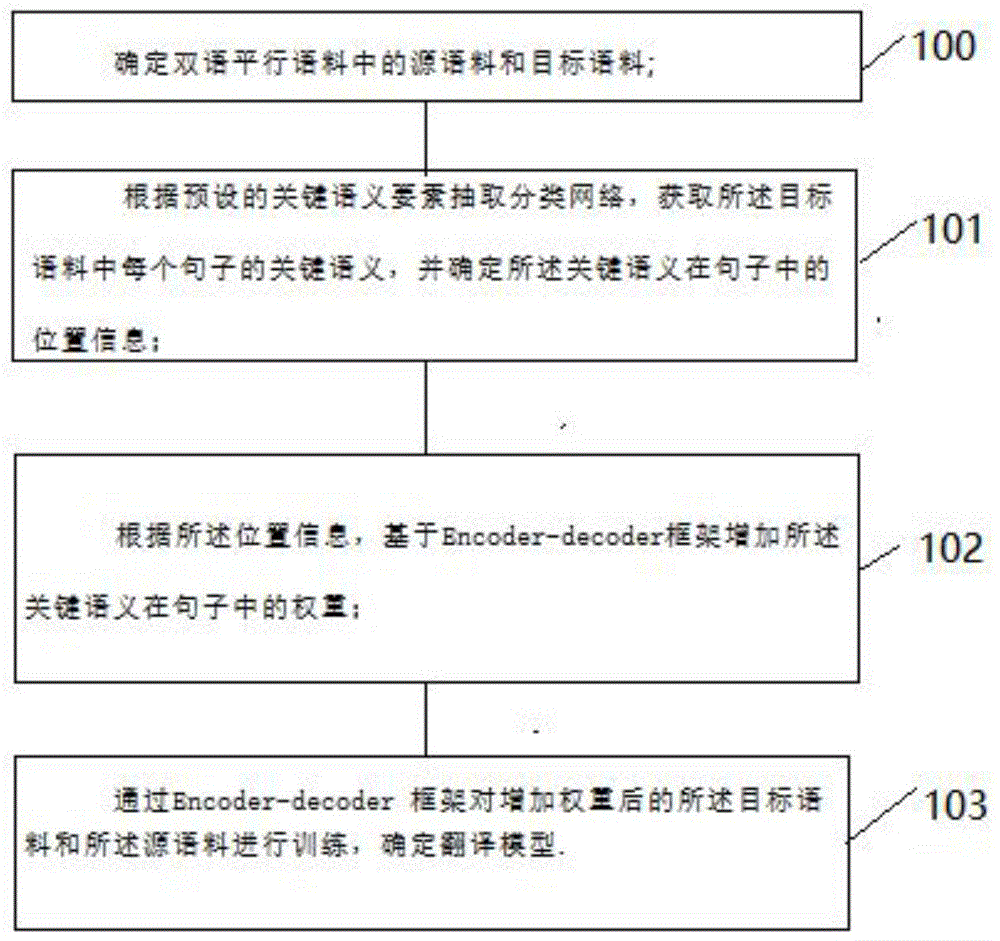
如图1所示本发明实施例中一种提高机器翻译准确度的方法的算法流程图,一种提高机器翻译准确度的方法,包括:
步骤100:确定双语平行语料中的源语料和目标语料;
步骤101:根据预设的关键语义要素抽取分类网络,获取所述目标语料中每个句子的关键语义,并确定所述关键语义在句子中的位置信息;关键语义为翻译句子时,句子的主语。
步骤102:根据所述位置信息,基于encoder-decoder框架增加所述关键语义在句子中的权重;
步骤103通过encoder-decoder框架对增加权重后的所述目标语料和所述源语料进行训练,确定翻译模型。
本发明的原理在于:本发明通过双语平行语料的源语料和目标语料,提取关键语义,根据关键语义构建关键语义要素抽取分类网络,从而确定关键语义在句子中的位置,通过encoder-decoder框架增加关键语义在句子中的权重,增加权重之后,通过encoder-decoder框架对增加权重之后的源语料和目标语料进行训练,得到最终翻译模型。
本发明的有益效果在于:通过对目标语料中的关键语义进行标记,并在训练中增加其权重,使得decoder端在解码时更加关注该部分信息,降低了原文本中关键语义错翻、漏翻的概率,从而使得decoder端更忠实于原文本的含义;关键语义的抽取本质上是句子本身信息的抽取,虽然关键语义要素抽取网络无法做到完成正确地抽取出句子中的关键语义,但抽取出的内容仍然是句子本身的语义,这样可以在一定程度上避免因外部资源引入而产生的一些错误判断。
作为本发明的一种实施例:所述确定双语平行语料中的源语料和目标语料,包括:
获取现有的双语平行语料数据,对所述双语平行语料数据中的句子进行断句分词处理,获取断句分词后的双语语料集;
根据预设的文本转化规则,将所述语料集转化为双语语料文本;
根据所述双语料文本的语义,确定所述双语语料文本中的关键语义和非关键语义;非关键语义是翻译的句子时,句子中除了主语之外的感叹词等不影响翻译效果的词语。
根据所述关键语义的权重,确定目标语料;
通过所述关键语义和非关键语义和所述现有的双语平行语料数据匹配,确定源语料。
本发明的原理在于:本发明通过对现有的双语平行语料数据断句、分词处理,得到双语语料集。基于文本转化的规则,通过转化的语料文本得到关键语义和非关键语义,基于关键语义的权重和关键语义和非关键语义和所述现有的双语平行语料数据匹配结果,从而得到目标语料和源语料。
本发明的有益效果在于:本发明通过分词、断句、文本转化等方式,确定双语平行语料中的关键语义和非关键语义,进而确定目标语料和源语料。本发明获取目标语料和源语料的方式能够准确定位关键语义,进而确定目标语料,可以使得机器翻译时,能够正确翻译,减少错翻译和误翻译。
作为本发明的一种实施例:所述根据预设的关键语义要素抽取分类网络,获取所述目标语料中每个句子的关键语义,并确定所述关键语义在句子中的位置信息之前,还包括:
获取现有的单语语料数据,对所述单语语料进行分类处理,确定分类处理后的单语语料文本;
根据所述单语语料文本中的语义,确定所述单语语料文本的关键语义和非关键语义,并对所述关键语义和非关键语义分别进行标记,获取标记单语语料;
将所述标记单语语料作为训练数据构建关键语义要素抽取网络;
根据所述关键语义要素抽取网络,通过双向lstm来建模所述单语语料文本的词语级的向量表示,然后利用所述向量表示进行所述关键语义和非关键语义的二分类训练,得到关键语义要素抽取分类网络。
本发明原理在于:本发明通过单语语料数据的分类处理,基于单语语料文本的关键语义和非关键语义,构建关键语义要素抽取网络,再通过双向lstm得到关键语义要素抽取分类网络。
本发明的有益效果在于:本发明通过单语语料得到关键语义要素抽取分类网络,因为单语语料和双语语料的关键语义具有相似性,根据相似性能够通过关键语义要素抽取分类网络训练双语语料,从而确定双语语料的目标语料,使得翻译的准确度增加。
作为本发明的一种实施例:所述根据所述位置信息,基于encoder-decoder框架增加所述关键语义在句子中的权重,包括:
获取端到端的encoder-decoder框架,通过所述encoder-decoder框架读取源语料,确定所述源语料的源序列;
通过所述encoder-decoder框架中的encoder模块将所述源序列转成固定维度的第一向量表示,并输入到所述encoder-decoder框架的encoder-decoderattention端;
通过所述encoder-decoder框架读取所述目标语料,确定所述目标语料的目标序列;
经过所述encoder-decoder框架的decoder模块将输入的所述目标序列转成固定维度的第二向量表示,并输入到所述encoder-decoderattention端,所述encoder-decoderattention端根据所述关键语义,确定所述关键语义在句子中的位置信息,并增加所述关键语义在句子中的权重。
本发明的原理在于:基于关键语义的位置信息,通过encoder-decoder框架的decoder模块以端到端的方式,增加关键语义的权重。
本发明的有益效果在于:本发明通过增加双语语料中目标语料的权重,翻译时,关键语义更加清晰,从而翻译的准确度更高。
作为本发明的一种实施例:所述通过encoder-decoder框架对增加权重后的所述目标语料和所述源语料进行训练,确定翻译模型之前,还包括:
将所述增加权重的关键语义通过下式(1)进行softmax计算,确定翻译顺序;
其中,所述s(z)i表示翻译第i个单词的概率;所述e表示zi的底数;zi表示第i个词的向量;所述c表示类别个数;所述j表示第j个单词;
根据所述翻译顺序,实现梯度回转。
如附图2所示本发明实施例中一种提高机器翻译准确度的装置的装置模块图,包括:
第一确定模块:用于在双语平行语料中确定源语料和目标语料;
第二确定模块:用于根据预设的关键语义要素抽取分类网络,获取所述目标语料中每个句子的关键语义,并确定所述关键语义在句子中的位置信息;
第一处理模块:用于根据所述位置信息,基于encoder-decoder框架增加所述关键语义在句子中的权重;
第三确定模块:用于通过encoder-decoder框架对增加权重后的所述目标语料和所述源语料进行训练,确定翻译模型。
本发明的原理在于:本发明通过第一确定模块、第二确定模块、第三确定模块和处理模块确定双语平行语料的源语料和目标语料,提取关键语义,根据关键语义构建关键语义要素抽取分类网络,从而确定关键语义在句子中的位置,通过encoder-decoder框架增加关键语义在句子中的权重,增加权重之后,通过encoder-decoder框架对增加权重之后的源语料和目标语料进行训练,得到最终翻译模型。
本发明的有益效果在于:通过对目标语料中的关键语义进行标记,并在训练中增加其权重,使得decoder端在解码时更加关注该部分信息,降低了原文本中关键语义错翻、漏翻的概率,从而使得decoder端更忠实于原文本的含义;关键语义的抽取本质上是句子本身信息的抽取,虽然关键语义要素抽取网络无法做到完成正确地抽取出句子中的关键语义,但抽取出的内容仍然是句子本身的语义,这样可以在一定程度上避免因外部资源引入而产生的一些错误判断。
作为本发明的一种实施例,所述第一确定模块包括:
第一获取单元:用于获取现有的双语平行语料数据,对所述双语平行语料数据中的句子进行断句分词处理,获取断句分词后的双语语料集;
第一转化单元:用于根据预设的文本转化规则,将所述语料集转化为双语语料文本;
第一确定单元:用于根据所述双语料文本的语义,确定所述双语语料文本中的关键语义和非关键语义;
第二确定单元:用于根据所述关键语义的权重,确定目标语料;
第三确定单元:通过所述关键语义和非关键语义和所述现有的双语平行语料数据匹配,确定源语料。
本发明的原理在于:本发明通过过第一获取单元和第一转化单元对现有的双语平行语料数据断句、分词处理,得到双语语料集。基于文本转化的规则,通过转化的语料文本在第一确定模块处理下得到关键语义和非关键语义,基于关键语义的权重和关键语义和非关键语义和所述现有的双语平行语料数据匹配结果,从而通过第二确定单元和第三确定单元得到目标语料和源语料。
本发明的有益效果在于:本发明通过第一获取单元和第一转化单元以分词、断句、文本转化等方式处理双语语料,再通过第一确定单元双语平行语料中的关键语义和非关键语义,进而确定目标语料和源语料。本发明获取目标语料和源语料的方式能够准确定位关键语义,进而确定目标语料,可以使得机器翻译时,能够正确翻译,减少错翻译和误翻译。
作为本发明的一种实施例,所述第二确定模块包括:
第四确定单元:用于获取现有的单语语料数据,对所述单语语料进行分类处理,确定分类处理后的单语语料文本;
第二获取单元:用于根据所述单语语料文本中的语义,确定所述单语语料文本的关键语义和非关键语义,并对所述关键语义和非关键语义分别进行标记,获取标记单语语料;
第一网络构建单元:用于将所述标记单语语料作为训练数据构建关键语义要素抽取网络;
第一处理单元:根据所述关键语义要素抽取网络,通过双向lstm来建模所述单语语料文本的词语级的向量表示,然后利用所述向量表示进行所述关键语义和非关键语义的二分类训练,得到关键语义要素抽取分类网络。
本发明原理在于:本发明通过单语语料数据的分类处理,基于单语语料文本的关键语义和非关键语义,通过第一网络构建单元构建关键语义要素抽取网络,再通过第一处理单元的双向lstm得到关键语义要素抽取分类网络。
本发明的有益效果在于:本发明通过单语语料得到关键语义要素抽取分类网络,因为单语语料和双语语料的关键语义具有相似性,根据相似性能够通过关键语义要素抽取分类网络训练双语语料,从而确定双语语料的目标语料,使得翻译的准确度增加。
作为本发明的一种实施例,所述处理模块包括:
第五确定单元:用于获取端到端的encoder-decoder框架,通过所述encoder-decoder框架读取源语料,确定所述源语料的源序列;
第二处理单元:用于通过所述encoder-decoder框架中的encoder模块将所述源序列转成固定维度的第一向量表示,并输入到所述encoder-decoder框架的encoder-decoderattention端;
第六确定单元:用于通过所述encoder-decoder框架读取所述目标语料,确定所述目标语料的目标序列;
第三处理单元:用于通过所述encoder-decoder框架的decoder模块将输入的所述目标序列转成固定维度的第二向量表示,并输入到所述encoder-decoderattention端,所述encoder-decoderattention端根据所述关键语义,确定所述关键语义在句子中的位置信息,并增加所述关键语义在句子中的权重。
本发明的原理在于:基于关键语义的位置信息,通过encoder-decoder框架的decoder模块以端到端的方式,增加关键语义的权重。
本发明的有益效果在于:本发明通过增加双语语料中目标语料的权重,翻译时,关键语义更加清晰,从而翻译的准确度更高。
作为本发明的一种实施例,所述装置还包括:
第二处理模块:用于将所述增加权重的关键语义通过下式(1)进行softmax计算,确定翻译顺序;
其中,所述s(z)i表示翻译第i个单词的概率;所述e表示zi的底数;zi表示第i个词的向量;所述c表示类别个数;所述j表示第j个单词;
根据所述翻译顺序,实现梯度回转。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!