一种保障高空中油箱内视觉采集图像空地一致性的方法与流程
本发明涉及图像识别的技术领域,特别是涉及一种保障高空中油箱内视觉采集图像空地一致性的方法。
背景技术:
在现实生活中,无论是民用飞机还是军事领域,飞机油箱中的剩余油量都是评估飞机续航能力、确保飞行安全的重要指标,它的精准程度对飞机重心控制、机动性、续航时间计算、有效载重确定均有重要意义。当前广泛使用的油量测量方法主要有电容式传感器、光纤传感器、超声波传感器等,但随着飞机研究水平和深度学习的高速发展,越来越多的人采用基于机器视觉的非接触式油量测量方法,提出通过深度网络以直接获取深度信息为目标的视觉非接触式测量技术,可以在减少油量测量成本的同时提高油量测量精度,这种方法正逐渐被普及。但无论是利用卷积神经网络、循环神经网络还是最近提出的深度q网络,以上大多数方法都是基于监督学习,即视觉式测量需借助已标定的油量数据进行有监督学习,这意味着数据驱动的深度学习在一个场景下训练的测量模型,面临场景变更时性能会急剧下降。
在军事领域,未来空战环境飞行条件下未知因素众多,飞机姿态机动变化随机性强,液面视觉表征对应油量数据情况复杂多变,导致高空实飞环境与地面实验环境存在较大差异,高空飞行中有很多地面没有的空中特殊状态油量图像且均为未标定图像数据,这使得通过地面数据学得的测量模型无法保证空中数据的检测效果,也即是无法保证测量性能方面地面模拟状态与飞行状态下的空地一致性。
技术实现要素:
为解决上述技术问题,本发明提供一种保障高空中油箱内视觉采集图像空地一致性的方法,根据空中数据在地面数据中的视觉特征潜在相似度,结合空中数据与地面数据语义间的相似度,合成空中数据样本的虚拟特征,利用生成的虚拟特征及空中数据的多模态语义标签训练得到语义分类器,在测试时,将空中数据送入训练好的语义分类器中得到空中数据的语义结果,对比油量数据集中收集的多模态语义信息库得出空中数据的测试类别。
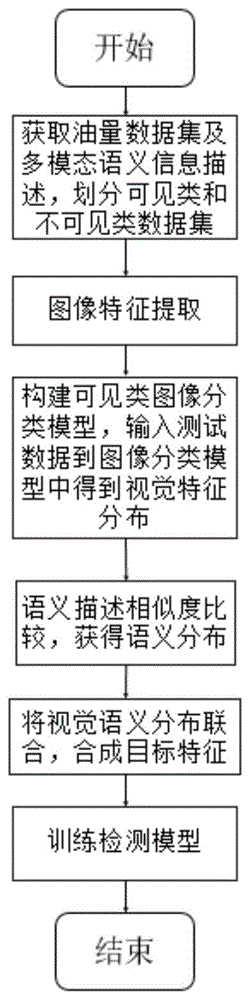
本发明的一种保障高空中油箱内视觉采集图像空地一致性的方法,包括以下步骤:s1:获取油量图像数据集及多模态语义信息描述,将空中数据命名为不可见类,地面模拟数据命名为可见类,构建不可见类和可见类共有的多模态语义库;
s2:构建深度特征提取网络和可见类样本图像分类模型;
s3:通过可见类样本及类别标签训练的图像分类模型,计算不可见类与可见类样本特征之间的视觉特征潜在相似度;
s4:构建浅层神经网络,将构建的多模态语义库中所有类别的语义标签输入到浅层神经网络中,使所有类别的语义标签处于同一个嵌入空间进行维度压缩,将不可见类别语义与可见类别语义特征进行相似度比较,得到不可见类与可见类之间的语义相似度;
s5:对于每一个不可见类,将它们的视觉特征潜在相似度和语义特征相似度联合;
s6:计算可见类中每一类特征数据的均值和标准差,根据不可见类样本在可见类样本中的联合分布情况合成不可见类样本的虚拟目标特征;
s7:构建语义分类模型,对不可见类样本进行预测。
与现有技术相比本发明的有益效果为:本发明在非接触式视觉油面测量领域保障高空中油箱内视觉采集图像的空地一致性方面提供了一个新方法,采用合成缺失目标特征的零样本学习方法对空中特殊状态油量样本进行识别,充分考虑了油量图像的特性。同时与现有零样本学习方法大多只考虑语义特征之间的映射不同,构建视觉特征分类模型获得了图像之间的视觉特征潜在相似度。将视觉和语义特征相似度联合获得每个目标类别的条件概率分布,通过随机采样合成样本,使合成的目标特征更具有判别力。由此,本发明能够合成更趋近于目标样本的虚拟特征,考虑到油量数据集包含图像特征和多模态语义描述的特性,综合考虑视觉特征和语义特征两方面的分布情况合成目标样本,生成的样本也更具有判别性,有效的保障了高空中油箱内视觉采集图像的空地一致性。
附图说明
图1是本发明方法的整体方法流程图;
图2是本发明中获取视觉特征潜在相似度的结构示意图;
图3是本发明中获取语义相似度的结构细示意图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
实施例:
s1获取油量图像数据集及飞机角度、角度加速度,液面等传感器数据,以油箱总体积1%的差距划分油量图像的类别,构建多模态语义信息库,对油量图像数据集进行训练集和测试集的划分,训练集为地面实验数据,测试集为空中特殊状态数据,将测试集的样本类数据集命名为不可见类,样本记为xte={x1,x2,…xte}及其类别标签yte={y1,y2,...yte};将训练集的样本类数据集命名为可见类,样本记为xtr={x1,x2,...xtr}及其类别标签ytr={y1,y2,...ytr},其中
s2构造特征提取网络模型f(·)和图像分类模型d(·),特征提取网络是为了提取所有样本的特征,分类模型为了训练可见类的类别分类器,分类模型损失函数计算公式如下:
其中
s3将提取的不可见类样本特征f(xte)送入步骤s2得到的图像分类模型中,如图2所示,得到每一类不可见类在可见类中的视觉特征分布数量,根据分布情况得出每一类不可见类与可见类视觉特征潜在相似度,计算公式如下:
其中
s4如图3所示,构建浅层神经网络用于语义词向量生成,这里采用开源的自然语言处理模型为例进行说明,将多模态语义库中每一个类别的语义标签送入自然语言处理模型中,使所有类别的语义向量处于同一个嵌入空间,得到可见类别的语义向量as与不可见类别的语义向量au,计算每一个不可见类与其它可见类之间的相似程度,计算公式如下:
其中
s5对于每一个未知类,将步骤三和步骤四得到的相似度进行联合,得到不可见类与所有可见类之间的视觉语义联合相似度,计算公式如下:
筛选出与每一个不可见类相关的n个可见类,其中n个可见类联合概率累计之和不低于95%;
s6对可见类中每一类的样本特征求均值μ和标准差σ,依据每一个不可见类的视觉特征和语义的联合概率pij生成虚拟均值和标准差,计算公式如下:
其中μj,σj是生成的第j类不可见类的均值和标准差,μi,σi是可见类中第i类样本的均值和方差,n代表样本数量,根据每一个不可见类的均值和标准差生成一定数量符合高斯分布的虚拟目标特征;
s7构建语义分类模型,使用合成的不可见类的虚拟目标特征作为分类模型的输入,对应的不可见类的语义向量作为标签,使用一般的监督学习分类算法,训练得到语义分类器。将测试集送入语义分类器中,得到测试集样本的语义分类结果,使用knn算法进行预测,将测试集多模态语义库中每一类不可见类的语义与预测语义对比,真实语义与预测语义差值之和最小的类别作为预测类别,即分类结果。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变型,这些改进和变型也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!