一种基于SimpleShot的One-Shot学习新方法与流程
本发明涉及simpleshot算法,一种对最近邻分类重新研究以进行小样本学习的目标识别技术。该技术是小样本学习领域重要的技术之一,通过对最近邻分类的重新审视,结合一些新颖的思想,在小样本学习领域具有先进的准确率。
背景技术:
近年来,随着深度学习的发展,越来越多的深度学习模型在计算机视觉领域尤其是图像分类领域取得了非常不错的成果,实现了最先进的性能,在识别准确率上甚至已经可以达到与人类视觉相匹敌的状态。但是,这种现象的形成是由于要实现极其强大的性能,就必须要依赖庞大的具有标签的数据来训练模型,并且该模型需要具备不同视觉变化的网络。事与愿违,在实际的应用中,人类标注成本以及在一些特殊领域中某些类别的数据稀缺性极大的限制了当前视觉系统有效学习新视觉概念的适应性。对此,如何在仅拥有少量新类的标记样本的情况下学习一种具有良好适应性的模型成为了一个很有意义的研究课题。
在小样本学习领域中,人类视觉系统具有当前计算机视觉无法比拟的能力,开发一个小样本学习的计算机视觉系统是非常重要的。在小样本学习环境中,通常能想到的是,首先需要使用大量的训练数据对模型进行训练,以实现识别基类的能力;随后,将具有少量数据的新类输入该模型,用于识别需要识别的新类。这既是迁移学习的思想。为了使模型具有鲁棒性防止过拟合的问题出现,成功的小样本学习模型必须有效地重用从基类上学习到的知识。
当前,在深度学习中,小样本学习是数据短缺下的学习问题,这是深度学习中的一个重要挑战,因为在许多现实世界中可能无法提供大量的训练实例。尽管元学习的最新进展使得在小样本学习任务中获得令人印象深刻的性能成为可能,但在我们获得的信息很少情况下仍然具有挑战性(例如one-shot学习)。
技术实现要素:
为了克服小样本学习中容易产生的过拟合问题,提高现有小样本图像分类方法分类的准确度,本发明提出了一种基于simpleshot的one-shot学习新方法。
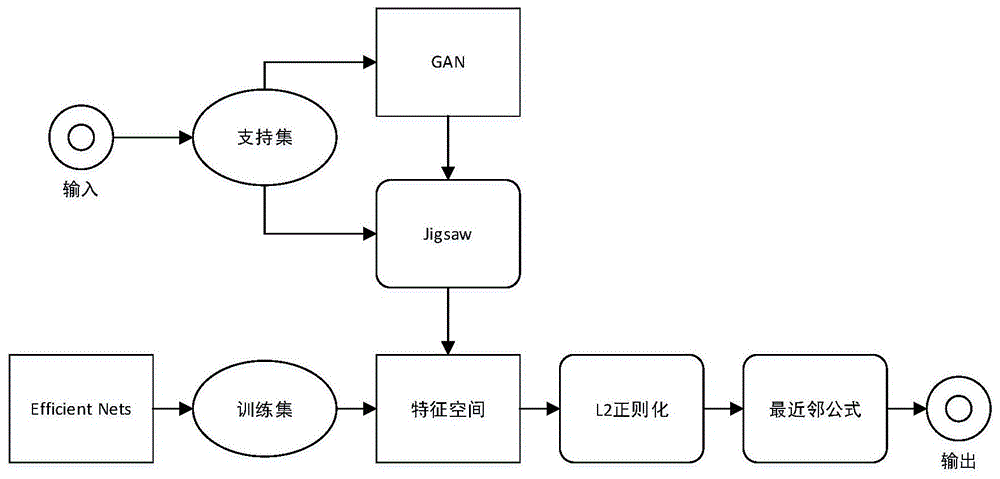
本发明的思路为:通过使用目前在图像分类领域具有最优性能的特征提取网络efficientnets作为特征提取网络,在基类上进行训练,网络训练后得到特征空间,然后输入新类的小样本,并在该特征空间中,对图像进行特征变换,即使用正则化技术缓解过拟合问题,在最后进行最近邻分类。另外在支持集方面,本发明使用一种有效的数据增强方法——改进的jigsaw图像增强技术来对少量的样本进行数据增广,进一步缓解过拟合问题。
s100,构建一个由基类a形成的数据集dbase={(i1,y1),...,(in,yn))},in表示第n张图像,yn为第n张图像的标签,其中包含n个来自基类a的标记图像,即yn∈{1,...,a},使用efficientnets作为特征提取网络fθ,在基类a上训练后,将训练后的模型称为特征空间,其中θ为特征提取网络的参数;
s200,假设获得了来自c个新类的带标签图像的支持集,其中每个新类都有k=1个样本,通过生成对抗网络gan对支持集中的图像进行数据增广,使用jigsaw对数据进行处理,得到新的支持集dsupport;
s300,为了简化表示,将x=fθ(i)表示为通过特征空间后的特征图像,在特征空间中,对dsupport中的图像进行特征提取;
s400,对提取的特征进行先进行居中处理,再进行归一化和正则化处理,实现特征转换;
s500,对转换之后的特征,使用距离度量公式进行最近邻分类,得到分类结果。
进一步的,步骤s100的具体实现方式如下,
对生成特征的卷积网络fθ(i)即efficientnets进行训练,其中θ为卷积网络的参数,通过调整学习率以及相关超参数,包括学习率调整步长和学习率衰减大小,以最大程度地减少dbase在卷积网络的最后一层全连接层,即线性分类器上的损失loss:
其中,w∈r表示最后一层全连接层中的参数,i表示图像,y表示图像对应的标签,损失函数l为交叉熵损失,当loss的大小稳定在10-2的数量级,则停止训练。
进一步的,步骤s200中通过生成对抗网络gan对每个类别仅有的一张图片的支持集进行数据增广,生成的未标记的image2,然后使用改进的jigsaw数据增广方法对数据进行处理,得到新的支持集dsupport,具体实现方式如下,将原支持集中已标记的imagel和生成的未标记的image2分别分成4块,随机选择两张图片中的两块,对imagel中选中的两个图像块赋予权重w,image2中选中的两个图像块赋予权重1-w,然后将相同位置的图像块进行叠加,最终得到合成图像image。
进一步的,w的取值为0.3或0.4或0.5。
进一步的,步骤s400的具体实现方式如下,
首先对支持集上得到的特征图像计算平均特征向量
进一步的,步骤s500中使用欧几里德距离
其中
为实现上述目的,与现有技术相比,本发明具有以下优点:
(1)最近邻分类器可以在不需要元学习的情况下,在小样本学习基准上达到最先进的性能,使最近邻居分类重新确立为小样本学习的明显但有竞争力的基准。
(2)simpleshot算法在小样本学习领域已经取得了先进的性能,在此基础上,本发明使用一种在图像分类领域性能上目前最优的网络efficientnets作为特征提取网络,进一步提高分类的精度。
(3)针对小样本学习领域的过拟合问题,本发明在数据增强方面,通过一种图像快速增强方法jigsaw进行了数据增强,并对jigsaw进行了改进,有效缓解了过拟合问题,进一步提高分类精度。
附图说明
图1为本发明的流程图;
图2为改进的jigsaw方法进行数据增广的示意图。
具体实施方式
下面结合附图对本发明的技术方案作进一步的描述。
如图1所示,本发明提供了一种基于simpleshot的小样本学习方法,主要针对one-shot学习,包括以下步骤:
s100:假设我们得到了一个基类形成的数据集dbase={(i1,y1),...,(in,yn))},其中包含n个来自基类a的标记图像,即yn∈{1,...,a},in表示第n张图像,yn为第n张图像的标签,使用efficientnets作为特征提取网络fθ在此基类上训练后,将此训练后的模型称为特征空间;
进一步步骤s100的实现方式如下:
使用基类对特征网络进行训练即以通常图像分类的正常步骤进行,具体如下:
假设我们得到了一个数据集dbase={(i1,y1),...,(in,yn))},其中包含n个来自基类a的标记图像,即yn∈{1,...,a},按照7∶3的比例随机划分为训练集与验证集,对生成特征的卷积网络fθ(i)即efficientnets进行训练,其中θ为网络的参数,通过调整学习率以及相关超参数(学习率调整步长和学习率衰减大小),以最大程度地减少dbase在卷积网络的最后一层全连接层即线性分类器(最后一层网络层中的参数w)的loss:
损失函数l为交叉熵损失。当loss的大小稳定在10-2的数量级,则可以停止训练。卷积网络使用随机梯度下降联合训练。
s200:假设我们获得了来自c个新类的带标签图像的支持集dsupport,其中每个新类都有k=1个样本,即支持集dsupport包含每类仅有k=1个标记样本的c个类别的设置:
进一步的,步骤s200的具体实现方式如下:
假设我们获得了来自c个新类的带标签图像的支持集dsupport,其中每个新类都有k个样本。本发明针对one-shot图像分类,也就是说k=1,每个新类的带标签的样本数量为1,我们希望用jigsaw的方法对该数据进行数据增强,显然,一张图片无法进行jigsaw。由于jigsaw数据增强方法对于其他数据增强方法来说是正交互补的,我们通过生成对抗网络(gan)首先对仅有的一张图片进行数据增广,譬如得到5张生成图像,再通过jigsaw组合图片,形成新的dsupport。具体的实现如下:
gan的基本原理:假设我们有两个网络g(generator)和d(discriminator)。正如它的名字所暗示的那样,它们的功能分别是:g是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做g(z);d是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出d(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。
在训练过程中,生成网络g的目标就是尽量生成真实的图片去欺骗判别网络d。而d的目标就是尽量把g生成的图片和真实的图片分别开来。这样,g和d构成了一个动态的“博弈过程”。在最理想的状态下,g可以生成足以“以假乱真”的图片g(z)。对于d来说,它难以判定g生成的图片究竟是不是真实的,因此d(g(z))=0.5。公式如下:
整个式子由两项构成。x表示真实图片,z表示输入g网络的噪声,而g(z)表示g网络生成的图片。d(x)表示d网络判断真实图片是否真实的概率(因为x就是真实的,所以对于d来说,这个值越接近1越好)。而d(g(z))是d网络判断g生成的图片的是否真实的概率。g的目的:上面提到过,d(g(z))是d网络判断g生成的图片是否真实的概率,g应该希望自己生成的图片“越接近真实越好”。也就是说,g希望d(g(z))尽可能得大,这时v(d,g)会变小。因此我们看到式子的最前面的记号是min(g)。d的目的:d的能力越强,d(x)应该越大,d(g(x))应该越小。这时v(d,g)会变大。因此式子对于d来说是求最大max(d)。
通过gan得到的结果,与原始数据通过jigsaw得到最终的dsupport,jigsaw算法是将一个图片分为9分,通过将两张图片进行随机拆分组合的形式合成新的图片,受到人类能够识别幻想的图片,本发明将jigsaw算法进行了改进,在原始jigsaw的基础上,本发明使用的方法如下示例图,原始的jigsaw原理本质上是将未标记的图片image2(未标记的图像,在本发明中为gan生成的图像)的4/9以下的图像块对已标记的image1进行替换,而本发明使用的方法是将原支持集中已标记的image1和生成的未标记的image2分别分成4块,随机选择两张图片中的两块,对image1中选中的两个图像块赋予权重w(0<w<1,w的取值是根据实验要求设定的,通常令w=0.3,0.4,0.5),image2中选中的两个图像块赋予权重1-w,然后将相同位置的图像块进行叠加,最终得到合成图像image。实验证明,在mini-imagenet数据集上,simple-shot的特征提取网络使用conv4的四层卷积网络时,使用该方法最高能够提高原始one-shot分类精度高达20%(原始分类精度为49.51%,数据增广后为71.75%)。
s300:为了简化表示,将x=fθ(i)表示通过特征空间得到的特征图像。在特征空间中,对dsupport中的图像进行特征提取;
s400:在特征空间中,对上述提取的特征进行特征转换,并在特征转换之前,对特征进行归一化处理;
进一步的,步骤s400的具体实现如下:
为了实现更高的精度,我们需要在特征转换之前进行居中处理:对支持集上得到的特征图像计算平均特征向量
在特征空间中,已经得到了dsupport也就是新类别的一系列特征,我们要对特征进行特征转换,也即l2归一化(l2n):给定一个特征向量
s500:对特征转换之后的特征,使用距离度量公式进行最近邻分类,得到分类结果。
进一步的,步骤s500的具体实现如下:
对特征转换之后的特征,使用欧几里德距离
最近邻居规则将最相似的支持图像的标签(在特征空间中)分配给测试图像
下面对本发明中比较突出的两个点进行更加详细的说明:
(1)网络设置
efficientnet提出了一个更有原则性的方法来扩大cnn的规模,从而可以获得更好的准确性和效率,它使用一个简单而高效的复合系数来以更结构化的方式放大cnns。不像传统的方法那样任意缩放网络维度,如宽度,深度和分辨率,而是用一系列固定的尺度缩放系数来统一缩放网络维度。通过使用这种新颖的缩放方法和automl技术,它具有最高达10倍的效率(更小、更快)。
模型扩展的有效性在很大程度上依赖于baseline网络。为了进一步提高性能,必须要有一个新的基准网络efficientnet-b0如表1所示。
表1基准网络efficientnet-b0的网结构
实施细节:使用随机梯度下降法从头开始训练所有网络90个epochs,以最大程度地减少a-way分类的交叉熵损失(a是基类的数量)。将初始学习率设置为0.1,并使用256张图像的batch大小。在mini-imagenet上,分别在45和66个epoch将学习率减少了10个。在tiered-imagenet上,每隔30个周期将学习率除以10。根据验证类的一站式五向准确性(使用simpleshot(l2n)进行测量)执行提前停止。
(2)通过改进的jigsaw进行数据增广
jigsaw是一种新颖的拼图数据扩充方法。该方法将所有图像调整为相同的固定大小,并分为9个块。随机选择未标签的图像ii的某些块,并替换为已有标签的图像iu中相应位置的m个块(m≤4),得到合成图像
通常,要求ii和iu具有相同的类标签。当iu的类别标签与ii的类别标签不同时,可以将合成图像
- 还没有人留言评论。精彩留言会获得点赞!