渲染方法及装置、存储介质、处理器与流程
本申请涉及图像渲染领域,具体而言,涉及一种渲染方法及装置、存储介质、处理器。
背景技术:
云端虚拟化技术当前发展非常迅速。随着公有云平台和私有云平台的进一步发展,对于虚拟桌面云平台提出了进一步的细分需求。当前在虚拟云桌面方向,根据用户的使用行为,逐步细化出云桌面办公用户、2d/3d设计开发用户、3d游戏娱乐用户。
在当前技术条件下,桌面云对于第一类用户有很多的解决方案,qemu+spice协议开源项目,可以满足云桌面办公用户的需求。而对于2d/3d设计开发以及3d游戏娱乐两类用户,需要云端虚拟出来能够渲染3d应用的虚拟显卡。
针对虚拟机的3d渲染需求,当前的解决方案一般分为三种:
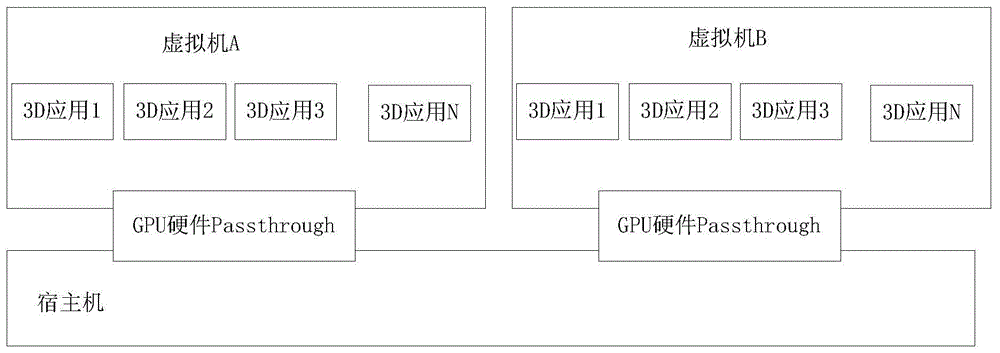
第一种是在云端主机中安装多个物理的图形处理器(gpu)显卡,并借助passthrough技术将单个物理显卡映射到每个客户的虚拟机(vm)中作为该虚拟机的物理显卡来使用,vm通过passthrough到虚拟机的物理显卡实现对3d指令的渲染,该渲染方案的示意图如图1所示。
第二种是在云端主机中,安装单个物理的gpu显卡,并借助vgpu技术将单个物理显卡虚拟成多张vgpu显卡,并逐个映射到客户的vm中作为虚拟显卡来使用,vm通过虚拟显卡vgpu实现对3d指令的渲染,该渲染方案的示意图如图2所示。
第三种是虚拟机虚拟显卡方案。每个虚拟机通过各自的虚拟显卡,将渲染请求发送给宿主机,宿主机利用物理显卡完成真正的渲染。所有渲染可以共用一张物理显卡,也可以使用不同的物理显卡,该渲染方案的示意图如图3所示。
上述三种方案各有优缺点。第一种方案,技术实现简单,不过每个虚拟机在启动时就要绑定好gpu硬件并独占使用,而实际运行当中可能根本不需要使用到gpu,造成gpu资源的浪费;第二种方案技术实现相对复杂,需要gpu硬件支持,而且该功能一般限定在某些特定厂家的特定型号gpu,价格昂贵,使用成本高;第三种方案,最为灵活,虚拟机启动和运行中都不需要绑定至固定的gpu硬件,宿主机也不需要选择特定厂家特定型号的gpu硬件,从成本考虑也是最优的。现在使用第三种方案的越来越多。
但是,第三种方案也存在一个问题。每个虚拟机的软件虚拟gpu只能对应至一个物理gpu硬件。当虚拟机的3d渲染需求大于对应的物理gpu硬件能力时,将不可避免地影响到用户体验。即使宿主机的其他物理gpu硬件处于空闲状态,也无法分担当前虚拟机繁重的渲染任务。简而言之,虚拟机的软件虚拟gpu与宿主机的物理gpu硬件之间的映射粒度太粗,属于一对一的映射关系。
针对上述的问题,目前尚未提出有效的解决方案。
技术实现要素:
本申请实施例提供了一种渲染方法及装置、存储介质、处理器,以至少解决由于虚拟机的软件虚拟gpu与宿主机的物理gpu硬件之间的映射粒度太粗造成的当虚拟机的3d渲染需求大于对应的物理gpu硬件能力时,影响渲染效果的技术问题。
根据本申请实施例的一个方面,提供了一种渲染方法,包括:确定至少一个发起渲染请求的目标应用;在虚拟机中为每个发起渲染请求的目标应用创建渲染上下文,其中,渲染上下文至少包括执行渲染请求对应的渲染动作时所需的数据,虚拟机运行在宿主机的操作系统上;在宿主机中依据渲染上下文之间的关系通过至少一个图形处理器对渲染上下文进行渲染。
可选地,在虚拟机中为每个发起渲染请求的目标应用创建渲染上下文,包括:为每个目标应用创建一个或多个渲染上下文,其中,一个目标应用对应的多个渲染上下文之间可以共享数据或者相互独立。
可选地,在宿主机中依据渲染上下文之间的关系通过至少一个图形处理器对渲染上下文进行渲染,包括:如果多个渲染上下文属于同一个目标应用,且多个渲染上下文之间相互独立,依据宿主机中的同一个图形处理器或者多个图形处理器对多个渲染上下文进行渲染;如果多个渲染上下文属于同一个目标应用,且多个渲染上下文之间共享数据,依据宿主机中的同一个图形处理器对多个渲染上下文进行渲染;如果多个渲染上下文属于不同的目标应用,依据宿主机中的同一个图形处理器或者多个图形处理器对多个渲染上下文进行渲染。
可选地,在虚拟机中为每个发起渲染请求的目标应用创建渲染上下文,包括:依据虚拟机中运行的目标渲染上下文管理器为每个发起渲染请求的目标应用创建渲染上下文。
可选地,在虚拟机中为每个发起渲染请求的目标应用创建渲染上下文之后,上述方法还包括:依据虚拟机中运行的目标渲染应用程序接口解析器将目标应用的第一应用程接口解析为中间表示格式的指令,第一应用程序接口用于发起渲染请求,第一应用程接口与渲染上下文存在对应关系;依据虚拟机中运行的目标渲染调度器将中间表示格式的指令发送至宿主机。
可选地,在宿主机中依据渲染上下文之间的关系通过至少一个图形处理器对渲染上下文进行渲染之前,上述方法还包括:依据宿主机中运行的目标渲染上下文管理器判断在宿主机中是否已经创建中间表示格式的指令对应的渲染上下文;如果判断结果为否,在宿主机中创建中间表示格式的指令对应的渲染上下文;在中间表示格式的指令对应的渲染上下文环境中,依据宿主机中运行的目标渲染应用程序接口解析器将中间表示格式的指令转换为宿主机运行的操作系统支持的第二程序调用接口。
可选地,在宿主机中依据渲染上下文之间的关系通过至少一个图形处理器对渲染上下文进行渲染,还包括:依据宿主机中运行的图形处理器调度器选择处于空闲状态的图形处理器执行第二程序调用接口对应的渲染动作。
根据本申请实施例的另一方面,还提供了一种渲染装置,包括:确定模块,用于确定至少一个发起渲染请求的目标应用;创建模块,用于在虚拟机中为每个发起渲染请求的目标应用创建渲染上下文,其中,渲染上下文至少包括执行渲染请求对应的渲染动作时所需的数据,虚拟机运行在宿主机的操作系统上;渲染模块,用于在宿主机中依据渲染上下文之间的关系通过至少一个图形处理器对渲染上下文进行渲染。
根据本申请实施例的再一方面,还提供了一种存储介质,存储介质包括存储的程序,其中,在程序运行时控制存储介质所在设备执行以上的渲染方法。
根据本申请实施例的再一方面,还提供了一种处理器,处理器用于运行存储在存储器中的程序,其中,程序运行时执行以上的渲染方法。
在本申请实施例中,采用确定至少一个发起渲染请求的目标应用;在虚拟机中为每个发起渲染请求的目标应用创建渲染上下文,其中,渲染上下文至少包括执行渲染请求对应的渲染动作时所需的数据,虚拟机运行在宿主机的操作系统上;在宿主机中依据渲染上下文之间的关系通过至少一个图形处理器对渲染上下文进行渲染的方式,通过将一个虚拟机的渲染任务分发至多个物理gpu硬件去完成,从而实现了当虚拟机的3d渲染需求大于对应的物理gpu硬件能力时,也能保证较好的渲染效果的技术效果,进而解决了由于虚拟机的软件虚拟gpu与宿主机的物理gpu硬件之间的映射粒度太粗造成的当虚拟机的3d渲染需求大于对应的物理gpu硬件能力时,影响渲染效果技术问题。
附图说明
此处所说明的附图用来提供对本申请的进一步理解,构成本申请的一部分,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
图1是根据本申请实施例的一种图渲染方案的结构图;
图2是根据本申请实施例的另一种渲染方案的结构图;
图3是根据本申请实施例的另一种渲染方案的结构图;
图4是根据本申请实施例的一种渲染方法的流程图;
图5是根据本申请实施例的一种图像渲染系统的架构图;
图6示出了一种同一应用内拥有共享数据的渲染上下文进行渲染的示意图;
图7示出了一种同一应用内五共享数据的渲染上下文进行渲染的示意图;
图8是根据本申请实施例的一种渲染装置的结构图。
具体实施方式
为了使本技术领域的人员更好地理解本申请方案,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分的实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本申请保护的范围。
需要说明的是,本申请的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本申请的实施例能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
根据本申请实施例,提供了一种渲染方法的实施例,需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
图4是根据本申请实施例的一种渲染方法的流程图,如图4所示,该方法包括如下步骤:
步骤s402,确定至少一个发起渲染请求的目标应用。
步骤s404,在虚拟机中为每个发起渲染请求的目标应用创建渲染上下文,其中,渲染上下文至少包括执行渲染请求对应的渲染动作时所需的数据,虚拟机运行在宿主机的操作系统上。
步骤s406,在宿主机中依据渲染上下文之间的关系通过至少一个图形处理器对渲染上下文进行渲染。
通过上述步骤,通过将一个虚拟机的渲染任务分发至多个物理gpu硬件去完成,从而实现了当虚拟机的3d渲染需求大于对应的物理gpu硬件能力时,也能保证较好的渲染效果的技术效果。
根据本申请的一个可选的实施例,步骤s404可以通过以下方法实现:为每个目标应用创建一个或多个渲染上下文,其中,一个目标应用对应的多个渲染上下文之间可以共享数据或者相互独立。
图5是根据本申请实施例的一种图像渲染系统的架构图,为了方便理解,下面先对系统组成进行简单介绍,如图5所示,
宿主机,负责在其操作系统之上运行多个虚拟机,以及管理多个物理gpu硬件。其中,负责管理物理gpu硬件的主要软件模块包括:3drenderingcontextmanager、3drenderingirinterpreter、gpudispatcher。
虚拟机内部,运行着称为客户机操作系统的软件系统。虚拟机的操作系统运行在宿主机操作系统之上,使用的是由宿主机操作系统提供的虚拟化的cpu、内存等资源,因此,虚拟机操作系统与宿主机操作系统之间可以通过内存映射等方式进行数据交换。虚拟机内部软件虚拟gpu相关的模块包括:3drenderingcontextmanager、3drenderingapiinterpreter、3drenderingirdispatcher。
在执行步骤s402时,虚拟机的3drenderingcontextmanager为每个发起渲染请求的3d应用创建并维护渲染上下文。
在本步骤中,首先,用户通过操作虚拟机的客户机运行3d应用,虚拟机的操作系统调用3d应用的3dapi(应用程序接口),3dapi发起渲染请求;然后,虚拟机的3drenderingcontextmanager,为每个发起渲染请求的3d应用创建并维护渲染上下文。
需要说明的是,一个渲染上下文包含了gpu执行具体渲染动作时所需的所有数据。一个3d应用可以创建多个独立的渲染上下文,也可以创建相互之间有共享数据的渲染上下文。每个3dapi调用时,都有一个归属的上下文环境,它的作用域仅在当前上下文环境中,仅影响当前上下文的渲染结果。这也是本方案提出的基于3d渲染上下文为最小映射颗粒的理论基础。
根据本申请的一个可选的实施例,步骤s406通过以下方式实现:如果多个渲染上下文属于同一个目标应用,且多个渲染上下文之间相互独立,依据宿主机中的同一个图形处理器或者多个图形处理器对多个渲染上下文进行渲染;如果多个渲染上下文属于同一个目标应用,且多个渲染上下文之间共享数据,依据宿主机中的同一个图形处理器对多个渲染上下文进行渲染;如果多个渲染上下文属于不同的目标应用,依据宿主机中的同一个图形处理器或者多个图形处理器对多个渲染上下文进行渲染。
同一应用的无共享数据的渲染上下文,可以由同一个物理gpu硬件渲染,也可以分发至不同物理gpu硬件渲染;同一应用的有共享数据的渲染上下文,由同一物理gpu硬件渲染;不同应用的渲染上下文,可以由同一个物理gpu硬件渲染,也可以分发至不同物理gpu硬件渲染。
根据本申请的一个可选的实施例,执行步骤s404时依据虚拟机中运行的目标渲染上下文管理器为每个发起渲染请求的目标应用创建渲染上下文。
需要说明的是,这里的目标渲染上下文管理器是指图5中虚拟机内部的3drenderingcontextmanager。
根据本申请的一个可选的实施例,步骤s404执行完成之后,依据虚拟机中运行的目标渲染应用程序接口解析器将目标应用的第一应用程接口解析为中间表示格式的指令,第一应用程序接口用于发起渲染请求,第一应用程接口与渲染上下文存在对应关系;依据虚拟机中运行的目标渲染调度器将中间表示格式的指令发送至宿主机。
上述目标渲染应用程序接口解析器是指图5中虚拟机内部的3drenderingapiinterpreter。虚拟机的3drenderingapiinterpreter,将运行在虚拟机中的3d应用的3dapi(上述第一应用程序接口)解析成与硬件无关的中间表示格式(intermediaterepresentation,ir)。
需要说明的是,解析成ir的目的是屏蔽虚拟机和宿主机之间操作系统和渲染环境的差异。比如,虚拟机的客户机操作系统为windows,使用的3dapi为d3d,宿主机操作系统为linux,使用的3dapi为opengl。虚拟机的3drenderingapiinterpreter先将windows的d3dapi调用解析为双方约定的ir指令,宿主机再将ir指令还原为linux的openglapi调用指令。
上述目标渲染调度器是指图5中虚拟机内部的3drenderingirdispatcher。虚拟机的3drenderingirdispatcher将解析之后的ir指令流发送给宿主机。
需要说明的是,本步骤提到的发送有很多实现方式,因为虚拟机是运行在宿主机操作系统之上,使用的宿主机提供的内存虚拟地址空间,因此最常用的就是采用内存映射的方式。
在本申请的一个可选的实施例中,在执行步骤s406之前,还需要依据宿主机中运行的目标渲染上下文管理器判断在宿主机中是否已经创建中间表示格式的指令对应的渲染上下文;如果判断结果为否,在宿主机中创建中间表示格式的指令对应的渲染上下文;在中间表示格式的指令对应的渲染上下文环境中,依据宿主机中运行的目标渲染应用程序接口解析器将中间表示格式的指令转换为宿主机运行的操作系统支持的第二程序调用接口。
宿主机的3drenderingcontextmanager(宿主机中运行的目标渲染上下文管理器),在接收到ir指令流之后,判断是否已经创建该ir指令流所属的渲染上下文;如果没有,则创建该ir指令流所属的渲染上下文。需要说明的是,每个虚拟机的每条ir指令流都有隶属的渲染上下文环境。
在本步骤中,在收到每一条ir指令流时,宿主机的3drenderingcontextmanager负责检查是否已经创建该ir指令流所属的渲染上下文;如果没有,则新建该ir指令流所属的渲染上下文。
宿主机的3drenderingirinterpreter(宿主机中运行的目标渲染应用程序接口解析器),在该条ir指令流所属的渲染上下文环境中,将ir指令流还原为宿主机操作系统支持的3dapi调用指令(即上述第二程序调用接口)。
根据本申请的一个可选的实施例,执行步骤s406时依据宿主机中运行的图形处理器调度器选择处于空闲状态的图形处理器执行第二程序调用接口对应的渲染动作。
宿主机的gpudispatcher,从所管理的多个物理gpu硬件中,选择处于空闲状态的gpu硬件,将3dapi调用指令发送给该gpu硬件,以使该gpu硬件执行3dapi调用指令对应的具体渲染动作。
需要说明的是,同一个渲染上下文,始终在同一个gpu硬件进行渲染。宿主机的gpudispatcher负责管理多个物理gpu硬件。
在本步骤中,宿主机的gpudispatcher从所管理的多个gpu硬件中选择处于空闲状态的gpu硬件,将3dapi调用指令发送给该gpu硬件,由该gpu硬件执行3dapi调用指令对应的具体渲染动作。
需要进一步说明的,不同应用或同一应用的不同渲染上下文之间的关系。一个3d应用可以同时创建多个渲染上下文,而且多个渲染上下文之间可以共享数据,也可以相互独立。拥有共享数据的渲染上下文,必须由宿主机的同一物理gpu进行渲染,如图6所示,应用a对应的渲染上下文a和渲染上下文b拥有共享数据,因此在宿主机上需要用同一个物理gpu渲染。
同一应用的无共享数据的多个渲染上下文,可以分发至不同的物理gpu硬件渲染,也可以由同一个物理gpu硬件渲染。选择规则由宿主机的gpudispatcher决定,通常对于一个新的渲染上下文,优先选择相对空闲的物理gpu硬件进行渲染,如图7所示,应用a对应的渲染上下文a和渲染上下文b无共享数据,因此在宿主机上可以用两个不同的物理gpu渲染,当然也可以用同一个物理gpu渲染。
图8是根据本申请实施例的一种渲染装置的结构图,如图8所示,该装置包括:
确定模块80,用于确定至少一个发起渲染请求的目标应用。
创建模块82,用于在虚拟机中为每个发起渲染请求的目标应用创建渲染上下文,其中,渲染上下文至少包括执行渲染请求对应的渲染动作时所需的数据,虚拟机运行在宿主机的操作系统上。
渲染模块84,用于在宿主机中依据渲染上下文之间的关系通过至少一个图形处理器对渲染上下文进行渲染。
需要说明的是,图8所示实施例的优选实施方式可以参考图4所示实施例的相关描述,此处不再赘述。
本申请实施例还提供了一种存储介质,存储介质包括存储的程序,其中,在程序运行时控制存储介质所在设备执行以上的渲染方法。
存储介质用于存储执行以下功能的程序:确定至少一个发起渲染请求的目标应用;在虚拟机中为每个发起渲染请求的目标应用创建渲染上下文,其中,渲染上下文至少包括执行渲染请求对应的渲染动作时所需的数据,虚拟机运行在宿主机的操作系统上;在宿主机中依据渲染上下文之间的关系通过至少一个图形处理器对渲染上下文进行渲染。
本申请实施例还提供了一种处理器,处理器用于运行存储在存储器中的程序,其中,程序运行时执行以上的渲染方法。
处理器用于运行执行以下功能的程序:确定至少一个发起渲染请求的目标应用;在虚拟机中为每个发起渲染请求的目标应用创建渲染上下文,其中,渲染上下文至少包括执行渲染请求对应的渲染动作时所需的数据,虚拟机运行在宿主机的操作系统上;在宿主机中依据渲染上下文之间的关系通过至少一个图形处理器对渲染上下文进行渲染。
上述本申请实施例序号仅仅为了描述,不代表实施例的优劣。
在本申请的上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见其他实施例的相关描述。
在本申请所提供的几个实施例中,应该理解到,所揭露的技术内容,可通过其它的方式实现。其中,以上所描述的装置实施例仅仅是示意性的,例如所述单元的划分,可以为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,单元或模块的间接耦合或通信连接,可以是电性或其它的形式。
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本申请各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可为个人计算机、服务器或者网络设备等)执行本申请各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、只读存储器(rom,rewxdzd-onlymemory)、随机存取存储器(rwxdzm,rwxdzndomwxdzccessmemory)、移动硬盘、磁碟或者光盘等各种可以存储程序代码的介质。
以上所述仅是本申请的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本申请原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本申请的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!