一种基于秩为r的离散非负矩阵分解聚类方法与流程
本发明属机器学习和数据挖掘
技术领域:
,具体涉及一种基于秩为r的离散非负矩阵分解聚类方法。
背景技术:
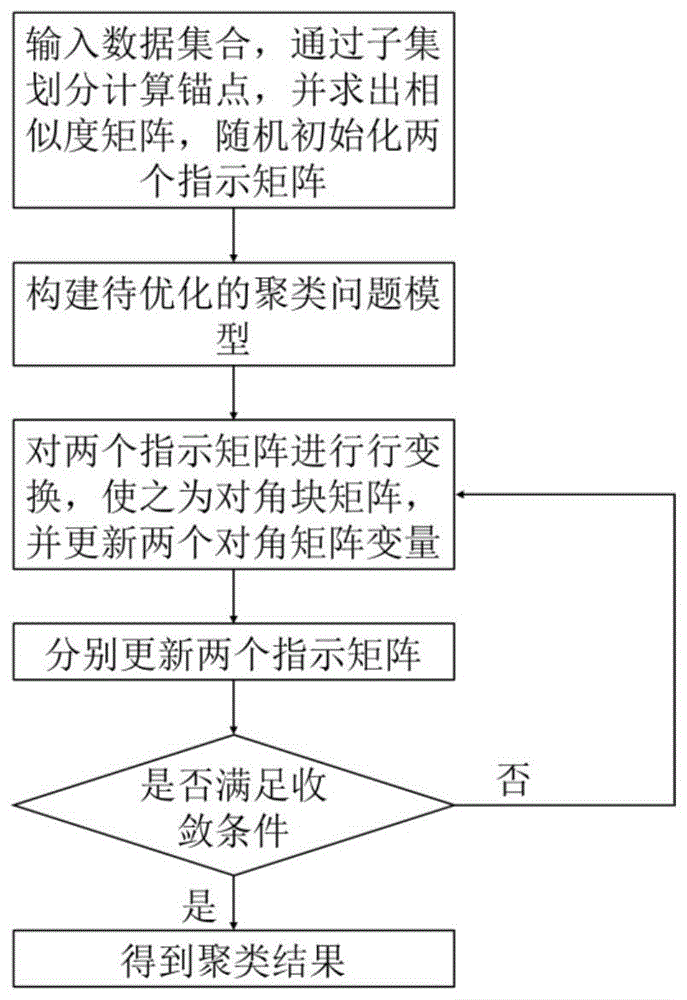
:聚类是近年来机器学习和数据挖掘领域中的研究热点之一,通过把数据分成许多不同的组来挖掘数据的潜在结构,其中,同一组中数据点之间具有更高的相似性,不同分组中点的相似性较低。聚类已成功应用于图像分割、数据挖掘及模式识别等多个领域。非负矩阵分解(nmf)、谱聚类、子空间聚类、多视角聚类等为聚类算法的分支,其中nmf因其数学优势和优越的结果引起了越来越多的关注。但是目前有许多基于nmf的聚类方法需要两个阶段来获得最终的聚类结果,其与直接优化目标函数得到聚类结果所获得的数据结构相比,聚类结构更差。此外,通过两个阶段得到的聚类结果不唯一,即需要通过像k-means这样的后处理技术来获得最终的离散结果。为了解决上述问题,许多非负矩阵分解方法通过把元素约束限制为指示矩阵来得到离散解,由此得到更好的聚类结果。此外,因为数据有多种类型,很多单边聚类方法,即仅通过特征分布聚类样本,或者仅通过样本的分布情况对特征进行分布,无法更好地处理文本数据和基因数据等,因此,基于联合聚类的方法被提出来,即利用样本和特征的联合信息来同时聚类样本和特征,研究结果证明此类方法比单边方法的聚类结果更好。不同于单边聚类方法,联合聚类方法同时对数据的行和列进行聚类,即同时找到相似的行和列,对于一个矩形矩阵,存在许多联合聚类结构,最常见的包括:棋盘结构和对角块结构,后者为把输入矩阵通过行列变换转换为对角块形式。如正交非负矩阵三因子分解方法(onmtf)和快速非负矩阵分解方法(fnmtf)都是基于棋盘结构。棋盘结构假定每个元素都应属于一个联合类,而现实中的许多数据为稀疏结构,因此,对角块结构更适合来处理稀疏数据。联合k-means快速聚类算法(bkm)即利用指示矩阵的性质并采用对角块结构来建模,实验显示其表现出很好的性能。但bkm算法中,每个块矩阵的秩为1,这样,此模型无法很好地逼近输入矩阵,也无法获得输入矩阵更多的信息。技术实现要素:为了克服现有技术的不足,本发明提供一种基于秩为r的离散非负矩阵分解聚类方法。首先,利用k-means算法进行数据集划分并得到样本锚点;然后,利用锚点计算得到初始相似度矩阵;最后,构建基于秩为r的离散非负矩阵分解聚类问题模型,并采用迭代更新方法对模型进行求解,得到指示矩阵,从而得到数据聚类结果。一种基于秩为r的离散非负矩阵分解聚类方法,其特征在于步骤如下:步骤1:对输入数据集合x,利用k-means算法将所有数据点划分到两个大小相等的子集中,然后,再分别对每个子集按相同的方法进行划分,直至得到m个数据子集,以每个子集的中心数据点为锚点,所有m个锚点共同构成锚点集合w,m为设定的锚点个数,m的可设定取值范围为(1,n),其中,n为输入数据集合包含的数据点个数;步骤2:按照计算原输入数据集合中的第i个数据点xi和锚点集合中的第j个锚点wj之间的距离,i=1,…,n,j=1,…,m;对每一个数据点xi,i=1,…,n,将所有锚点与其的距离按照从小到大进行排序,并将与其距离最小的k个锚点作为其k近邻点,k为(0,m)之间的整数,然后,按照下式计算每个锚点wj与数据点xi的相似度:其中,j=1,…,m,表示与数据点xi距离最小的第k+1个锚点与该数据点之间的距离,表示数据点xi的第h个近邻点与该数据点之间的距离,h=1,…,k;以数据点和锚点之间的相似度bij为第i行j列元素,得到初始相似矩阵i=1,…,n,j=1,…,m;步骤3:构建待优化的聚类问题模型如下:其中,ind表示指示矩阵集合,diag表示对角矩阵集合,f表示大小为n×c的指示矩阵,g表示大小为m×c的指示矩阵,f和g的每一行只有一个值为1的非零元素,其余元素均为0,f和g均为对角块矩阵,b为初始相似矩阵通过行列变换得到的相似矩阵,c为给定的聚类类别个数,取值为小于输入数据集合所包含数据点个数的正整数;pr表示第r个大小为n×n的对角矩阵,其元素依次为矩阵b1,b2,…,bc的第r个最大奇异值及其所对应的左奇异向量的乘积,qr表示第r个大小为m×m的对角矩阵,其元素依次为矩阵b1,b2,…,bc的第r个最大奇异值对应的右奇异向量,r为逼近参数,b1,b2,…,bc为相似矩阵b中的分块矩阵,满足和步骤4:迭代求解公式2的问题模型,得到最终的指示矩阵f,具体为:步骤4.1:对于给定的输入数据集合x,随机初始化指示矩阵f和g;步骤4.2:通过行交换使f和g均为对角块矩阵,模型中其他元素也相应进行行列变换以保持求解问题的不变性;步骤4.3:固定f和g,分别按以下公式更新pr和qr:其中,为矩阵的第r列,为矩阵的第r列,i=1,…,c;对矩阵bi进行svd分解,得到bi=urσrvr,σr为bi前r个最大奇异值组成的对角矩阵,ur为由与σr相对应的左奇异向量组成的矩阵,vr为由与σr相对应的右奇异向量组成的矩阵;步骤4.4:固定pr、qr、f,更新g:其中,gij为矩阵g的第i行j列元素,b·i为矩阵b的第i列向量,(·)·l表示矩阵的第l列向量,(qr)ii为对角矩阵qr的第i个对角元素,i=1,…,m,j=1,…,c;步骤4.5:固定pr、qr、g,更新f:其中,fij为矩阵f的第i行j列元素,bi·为矩阵b的第i行向量,(·)l·表示矩阵的第l行向量,(pr)ii为对角矩阵pr的第i个对角元素,i=1,…,n,j=1,…,c;步骤4.6:将更新后的f、g、pr、qr带入下式计算得到函数值j:如果此时得到的函数值和上一次迭代得到的函数值的差的绝对值小于阈值a,则停止迭代,此时得到的f即为最终的指示矩阵,矩阵f的第i行中元素1所在的列序号即为原始输入集合中第i个数据点所属的类别,i=1,…,n;否则,返回步骤4.2,进行下一次迭代更新;所述的阈值a的取值范围为0<a<10e-6。本发明的有益效果是:由于模型中采用对角块结构,使得该算法能够充分挖掘输入矩阵的行和列之间的联合信息,从而提高聚类效果;由于直接通过求解目标函数得到离散的聚类结构,而不需要采用k-means等进行后处理,得到的聚类结果稳定且唯一;由于构建的问题模型以秩为r的块逼近输入矩阵,能够获得更好的聚类结果。附图说明图1是本发明的一种基于秩为r的离散非负矩阵分解聚类方法流程图;图2是本发明的dnmf-rr模型中参数r对目标函数的影响;图3是本发明的dnmf-rr模型中参数r对不同数据集的聚类结果的影响。具体实施方式下面结合附图和实施例对本发明进一步说明,本发明包括但不仅限于下述实施例。如图1所示,本发明提供了一种基于秩为r的离散非负矩阵分解聚类方法,其基本实现过程如下:1、生成代表性锚点为了降低聚类计算所需的时间复杂度,需要在保持原有数据结构的情况下尽量减小数据规模,因此,本发明先对输入数据集进行子集划分,从n个原始数据点中生成m个代表性锚点。即对输入数据集合x,利用k-means算法将所有数据点划分到两个大小相等的子集中,然后,再利用k-means算法分别对每个子集进行划分,直至得到m个大小相等的数据子集,以每个子集的中心数据点为锚点,所有m个锚点共同构成锚点集合w,m为设定的锚点个数,m的可设定取值范围为(1,n),其中,n为输入数据集合包含的数据点个数。2、利用锚点计算初始相似度矩阵用相似矩阵表示所要构造的二部图。在欧式空间中,两个点之间的距离越小,相似度应该越高。基于此,待求解的目标函数可以写为:上式中,函数的第二项为正则项,α为正则化参数,取值范围为(0,+∞),如果没有正则项,求解问题(8)时很容易出现数据点和距离最近的锚点相似度为1,和其余锚点的相似度为0的情况。在实际构图时,为了保持二部图的稀疏性,采用k近邻方法进行构图,即:按照计算原输入数据集合中的第i个数据点xi和锚点集合中的第j个锚点wj之间的距离,i=1,…,n,j=1,…,m;然后,将从小到大排序,当锚点w·j是该数据点的k近邻点,即是第i个数据点最近的前k个锚点时,其初始相似度为否则,该锚点不是该数据点的近邻点,其初始相似度为0,即bij=0,其中,k为(0,m)之间的整数,可由使用者进行设置。以数据点和锚点之间的相似度bij为第i行j列元素,得到初始相似矩阵i=1,…,n,j=1,…,m。正则化参数α的闭式解可以通过对公式(8)拉格朗日函数求导并根据kkt条件得到,即3、确定待优化的聚类问题dnmf-rrchrisding证明了放缩的k-means算法与放缩的非负矩阵分解nmf之间的等价关系,两者均以二部图作为输入,基于二部图的nmf模型总结如下:其中,表示初始的相似性矩阵,和表示将分解为两个更小的非负矩阵,此时不是指示矩阵。正交限制保证了解的唯一性,式(9)的优点是可以对的行列同时聚类,然而,在实际中,为了得到最终的离散聚类结果,还需进行k-means等后处理,导致解的不唯一性,而且,求解式(9)很耗时,因此,把矩阵和限制为指示矩阵,得到如下模型:其中,ind表示指示矩阵集合。通过在矩阵和上加入新的约束,此模型可以直接得到离散聚类结果,不需要额外的后处理,而且,虽然去掉了矩阵和的正交约束,但更严格的新约束条件仍可以保证解的唯一性。对矩阵进行行列变换,即把矩阵和分别变换为对角块矩阵,同时,对也做相应的行列变换,使得公式(10)等同于下式:其中,f表示大小为n×c的指示矩阵,g表示大小为m×c的指示矩阵,f和g的每一行只有一个值为1的非零元素,其余元素均为0,c为给定的聚类类别个数,取值为小于输入数据集合所包含数据点个数的正整数。此时,fgt为元素为1的对角块矩阵。然而,f和g都为指示矩阵,条件太严格,fgt不能很好地逼近输入矩阵,因此,加入额外的因子s来更好地逼近输入矩阵b,进而获得原始数据更多的信息,得到模型如下:其中,diag表示对角矩阵集合。fsgt为对角块矩阵,为了进一步逼近输入矩阵b,加入对角矩阵p和q来代替s,即:此时,pfgtq仍为对角块矩阵。从上述模型(11)-(13)可以看出,虽然得到的新模型能够以对角块的形式更好地逼近b,但是每个分块矩阵的秩为1,不能得到更好的效果,因此,本发明提出的基于秩为r的离散非负矩阵分解聚类方法(dnmf-rr)求解数据的离散聚类结果,构建如下的以每个分块矩阵的秩为r的新的聚类问题模型:此时,模型中的是以对角块矩阵的形式逼近矩阵b,pr表示第r个大小为n×n的对角矩阵,其元素依次为矩阵b1,b2,…,bc的第r个最大奇异值及其所对应的左奇异向量的乘积,qr表示第r个大小为m×m的对角矩阵,其元素依次为矩阵b1,b2,…,bc的第r个最大奇异值对应的右奇异向量,参数r控制着模型的逼近程度,b1,b2,…,bc为相似矩阵b中的分块矩阵,满足和图2给出了本发明的的dnmf-rr模型中参数r对目标函数的影响,图中,usps、chess、tmp、minist、wave分别为数据集名称。图3给出了本发明的dnmf-rr模型中参数r对不同数据集的聚类结果的影响。为了更好地展示模型(11)-(14),下式以c=2为例,解释了各模型的结构:其中,1ab为元素全为1的列向量,ab为其下标。4、迭代求解聚类问题模型(a)固定f和g,更新pr和qr:因为是对角块矩阵,所以公式(14)式可以写为:又因为每一个bi(i=1,2,...,c)相互独立,所以求解式(15)等同于分别求解以下c个函:对于第i个函数,通过对bi(i=1,2,...,c)进行svd分解得到即令bi=ur∑rvr,∑r为bi前r个最大奇异值组成的对角矩阵,ur为由与∑r相对应的左奇异向量组成的矩阵,vr为由与∑r相对应的右奇异向量组成的矩阵。因此得到其中分别为的第r列。(b)固定pr、qr、f,更新g:由于矩阵b的每一列是独立的,因此可按照下式对矩阵g的每个行向量gi·(i=1,2,...,m)进行更新,从而得到更新后的矩阵g。其中,gij为矩阵g的第i行j列元素,b·i为矩阵b的第i列向量,(·)·l表示矩阵的第l列向量,(qr)ii为对角矩阵qr的第i个对角元素,i=1,…,m,j=1,…,c。(c)固定pr、qr、g,更新f:由于矩阵b的每一行是独立的,因此可按照下式对矩阵f的每个行向量fi·(i=1,2,...,n)进行更新,从而得到更新后的矩阵f。其中,fij为矩阵f的第i行j列元素,bi·为矩阵b的第i行向量,(·)l·表示矩阵的第l行向量,(pr)ii为对角矩阵pr的第i个对角元素,i=1,…,n,j=1,…,c。(d)将更新后的f、g、pr、qr带入下式计算得到函数值j:如果此时得到的函数值和上一次迭代得到的函数值的差的绝对值小于阈值a,则停止迭代,此时得到的f即为最终的指示矩阵,矩阵f的第i行中元素1所在的列序号即为原始输入集合中第i个数据点所属的类别,i=1,…,n;否则,返回步骤4.2,进行下一次迭代更新;所述的阈值a的取值范围为0<a<10e-6。本实施例在中央处理器为intelcorei7-8700、主频3.19ghz、内存32g的windows10操作系统上使用matlab软件进行实验,分别对chess数据集、tmp数据集、wave数据集、usps数据集、minist这5个数据集进行聚类处理,这些数据公开于网址http://www.escience.cn/people/fpnie/papers.html,各数据集的信息如表1所示。为了验证本发明方法的有效性,分别选取k均值(k-means)方法、大规模谱聚类(lsc)方法、无监督的大图嵌入(ulge)方法、快速标准切图(fnc)方法、可缩放的标准切图(snc)方法、对称非负矩阵分解(symnmf)方法和本发明的dnmf-rr方法对不同数据集进行聚类处理,并计算acc和nmi两个指标,其中,acc为准确率,表示聚类的准确率,取值范围为[0,1],值越大,代表聚类结果越好,nmi为归一化互信息,表示两个随机变量之间的关联程度,取值范围为[0,1],值越大,代表聚类结果越好,计算结果如表2所示。可以看出,相对于其他方法,采用本发明方法均获得了较好的acc和nmi值,聚类效果更好。表1数据集样本数特征数类别数chess3196362tmp15606172wave2746213usps185425610minist349578410表2当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1