数据模型的构建方法、装置、设备及计算机可读存储介质与流程
本发明涉及金融科技(fintech)数据处理技术领域,尤其涉及一种数据模型的构建方法、装置、设备及计算机可读存储介质。
背景技术:
随着计算机技术的发展,越来越多的技术应用在金融领域,传统金融业正在逐步向金融科技(fintech)转变,但由于金融行业的安全性、实时性要求,也对数据模型的构建技术提出了更高的要求。
目前金融机构授信方法采用的是线下授信方法,该方法是依赖人工经验对用户授信做出判断和决策,部分金融机构会综合评分卡进行判断,但评分卡的制定过程仍是以人工经验为主,将审批中的固定经验以评分卡形式进行呈现,使用评分卡辅助进行用户的授信决策,由于不同审批员的经验不同,从而导致了评分卡分数的不一样,从而导致了用户授信的准确性低。虽然有部分金融机构对用户授信使用了数据建模方式,但核心仍是参考了个人授信做法,从而导致了相关征信数据源单一性,从而导致了用户授信的真实性低。由此可知,目前金融机构授信方法的用户授信准确率低、以及用户授信真实性低。
技术实现要素:
本发明的主要目的在于提供一种数据模型的构建方法、装置、设备及存储介质,旨在解决现有的用户授信准确率低、以及用户授信真实性低的技术问题。
为实现上述目的,本发明提供一种数据模型的构建方法,所述数据模型的构建方法包括步骤:
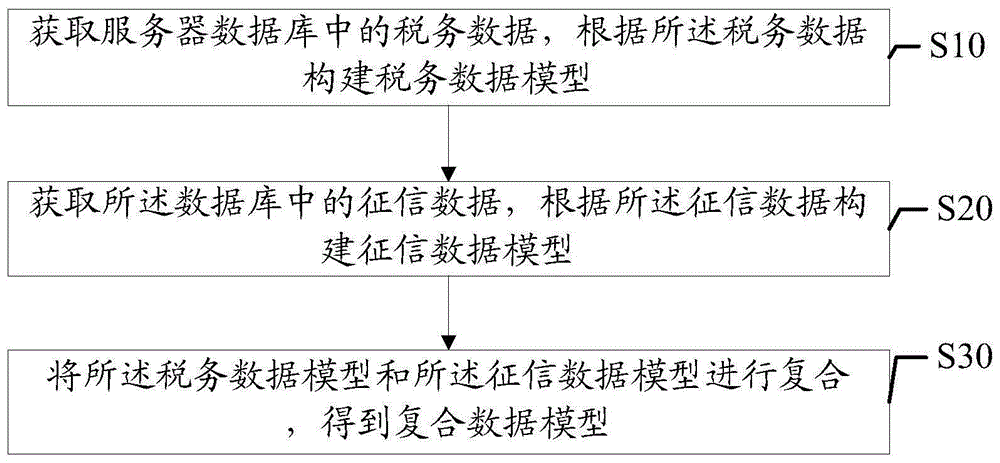
获取服务器数据库中的税务数据,根据所述税务数据构建税务数据模型;
获取所述数据库中的征信数据,根据所述征信数据构建征信数据模型;
将所述税务数据模型和所述征信数据模型进行复合,得到复合数据模型。
优选地,所述获取服务器数据库中的税务数据,根据所述税务数据构建税务数据模型的步骤包括:
获取所述数据库中的税务数据,所述税务数据包括财务数据和非财务数据;
根据财务数据构建得到财务数据模型,根据非财务数据构建得到非财务数据模型;
将所述财务数据模型和所述非财务数据模型进行合并,得到所述税务数据模型。
优选地,所述根据财务数据构建得到财务数据模型的步骤包括:
根据所述财务数据的业务逻辑关联性,收集所述财务数据的变量数据,并将所述变量数据进行数据分析,得到分析数据;
将所述分析数据进行数据重构,得到重构财务数据,并将所述重构财务数据进行模型构建,得到所述财务数据模型。
优选地,所述将所述财务数据模型和所述非财务数据模型进行合并,得到所述税务数据模型的步骤包括:
获取所述财务数据模型中的第一模型参数,并获取所述非财务数据模型中的第二模型参数;
将所述第一模型参数和所述第二模型参数进行参数映射,得到映射数据;
将所述映射数据进行数据整理,得到整理数据,并将所述整理数据进行加权合并,得到所述税务数据模型。
优选地,所述获取所述数据库中的征信数据,根据所述征信数据构建征信数据模型的步骤包括:
获取所述数据库中的征信数据,所述征信数据包括用户信用数据和用户贷款数据;
根据所述用户信用数据构建得到用户信用数据模型,根据所述用户贷款数据构建得到用户贷款数据模型;
将所述用户信用数据模型和所述用户贷款数据模型进行合并,得到所述征信数据模型。
优选地,所述将所述税务数据模型和所述征信数据模型进行复合,得到复合数据模型的步骤包括:
获取所述税务数据模型对应的分值,并获取所述征信数据模型对应的标签;
将所述分值和所述标签进行逻辑复合,得到所述复合数据模型。
优选地,所述将所述税务数据模型和所述征信数据模型进行复合,得到复合数据模型的步骤之后,还包括:
将所述复合数据模型存储于所述数据库中,并接收终端设备发送的授信请求,通过所述复合数据模型对所述授信请求进行授信处理,得到授信结果;
将所述授信结果发送至所述终端设备,以供所述终端设备在接收到所述授信结果后,输出所述授信结果。
此外,为实现上述目的,本发明还提供一种数据模型的构建装置,其特征在于,所述数据模型的构建装置包括:
获取模块,用于获取服务器数据库中的税务数据;
构建模块,用于根据所述税务数据构建税务数据模型;
所述获取模块还用于获取所述数据库中的征信数据;
所述构建模块还用于根据所述征信数据构建征信数据模型;
复合模块,用于将所述税务数据模型和所述征信数据模型进行复合,得到复合数据模型。
此外,为实现上述目的,本发明还提供一种数据模型的构建设备,所述数据模型的构建设备包括存储器、处理器和存储在所述存储器上并在所述处理器上运行的数据模型的构建程序,所述数据模型的构建程序被所述处理器执行时实现如上所述的数据模型的构建方法的步骤。
此外,为实现上述目的,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质上存储有数据模型的构建程序,所述数据模型的构建程序被处理器执行时实现如上所述的数据模型的构建方法的步骤。
本发明实现获取数据库中的税务数据,根据税务数据构建税务数据模型,获取数据库中的征信数据,根据征信数据构建征信数据模型,再将税务数据模型和征信数据合并为复合数据模型。由此可知,本发明复合数据模型是由税务数据模型和征信数据模型复合的,在税务数据模型构建的过程中,获取数据库中的税务数据,根据税务数据构建税务数据模型,采用的是服务器全线上的方式获取数据和构建模型,而不需要依赖人工经验对用户授信做出判断和决策,因此得到用户授信的结果是很精确的。在征信数据模型的过程中,获取数据库中的征信数据,根据征信数据构建征信数据模型,采用的是服务器全线上的方式获取数据和构建模型,而不需要参考个人授信方法,而且得到的相关征信数据源是多样性的,从而使得用户授信的结果更加具有真实性。综上可知,通过复合数据模型能够精准和真实地对用户进行授信,从而提高了用户授信的准确率,以及用户授信的真实性。
附图说明
图1是本发明数据模型的构建方法第一实施例的流程示意图;
图2是本发明数据模型的构建装置较佳的结构示意图;
图3是本发明实施例方案涉及的硬件运行环境的结构示意图。
本发明目的的实现、功能特点及优点将合并实施例,参照附图做进一步说明。
具体实施方式
应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明提供一种数据模型的构建方法,参照图1,图1为本发明数据模型的构建方法第一实施例的流程示意图。
本发明实施例提供了数据模型的构建方法的实施例,需要说明的是,虽然在流程图中示出了逻辑顺序,但是在某些数据下,可以以不同于此处的顺序执行所示出或描述的步骤。
数据模型的构建方法包括:
步骤s10,获取服务器数据库中的税务数据,根据所述税务数据构建税务数据模型。
服务器通过线上方式获取数据库中用户的税务数据,然后根据数据特征提取税务数据中的数据,根据提取的数据构建税务数据模型。
其中,服务器是基于大数据的智能数据处理平台。线上方式就是通过互联网进行的系列操作,不需要通过人工干预。用户包括但不限制于个体户、小微型企业、中型企业和大型企业。数据特征为收入和支出等等,税务数据包括财务数据和非财务数据等,财务数据包括财务报表数据和纳税数据等,非财务数据包括用户数据和纳税行为数据等。构建模型方法有数学方法构建模型、时间序列方法构建模型、传统逻辑回归方法构建模型和神经网络方法构建模型等,本实施不限制构建模型方法的形式。
其中,本实施例可采用的构建模型方法为传统逻辑回归方法构建模型,具体为,在构建模型之前,服务器需要对构建样本进行设计,在构建样本设计的过程中,需要考虑构建样本风险的前瞻性,将发生逾期次数大于或等于30次的构建样本定义为坏构建样本,将没有发生过实质性逾期的构建样本定义为好构建样本,然后根据该构建样本设计对构建样本进行剔除或保留。在构建样本设计之后,服务器根据数据特征分为多个维度数据,然后对维度数据进行指标衍生,接着再对衍生变量进行变量筛选,变量筛选包括变量初筛和变量精筛。变量初筛就是根据衍生变量的缺失程度和集中程度进行筛选,将缺失程度过多和集中程度较高的衍生变量进行筛除,然后再对剩余的衍生变量进行分段和分档。变量精筛主要考虑衍生变量之间的关联性,判断衍生变量是否有一定相同质性,然后保留关联性较强和同质性较强的衍生变量中区分能力较好的衍生变量。在完成变量筛选之后,服务器构建模型,然后再将构建出的模型在构建样本以外的数据中进行测试。
需要说明的是,变量精筛的目的是保证模型入选的衍生变量都有一定的独立性,可在多个维度对目标建立较好的区分能力。分档的目的是为了使连续的衍生变量离散化,能够使得模型具有更好的稳定性。分档的目的是提升衍生变量区分能力,确保后续保留的衍生变量对目标有一定的区分能力。模型测试的目的是为了提高模型的稳定性。
进一步地,在本发明中,构建所有的数据模型都可以采用上述的传统逻辑回归方式构建模型。
在本实施例中,比如,根据税务数据的数据特征将税务数据分为报表财务数据、纳税数据和非财务数据3个维度数据,然后对维度数据分别进行指标含义或/和指标时间层面的衍生,如报表财务数据,可衍生出用户在上一年的营业收入、上两年的营业收入、上一年的营业收入增长率、以及根据用户截至目前最新的营业收入进行推算,得到用户当年营业收入值,并预测用户当年营业收入增长率等,从而可以得到用户长期和短期的变动特征。
所述步骤s10包括:
步骤a,获取所述数据库中的税务数据,所述税务数据包括财务数据和非财务数据;
步骤b,根据财务数据构建得到财务数据模型,根据非财务数据构建得到非财务数据模型;
步骤c,将所述财务数据模型和所述非财务数据模型进行合并,得到所述税务数据模型。
具体地,服务器获取数据库中用户的税务数据,根据数据的明细情况将税务数据进行数据分类,根据数据的性质可将该税务数据归类为财务数据和非财务数据,然后根据该财务数据和非财务数据构建数据模型,分别得到对应的财务数据模型和非财务数据模型,再通过预设模型合并方式将该财务数据模型和非财务数据模型进行模型合并,从而得到税务数据模型。
其中,数据分类就是将税务数据中具有共同属性或特征的数据归并在一起,即将具有相同内容或/和相同性质的数据集合在一起。模型合并就是将2个或2个以上的数据模型融合在一起,预设模型合并方式包括但不限制于加权表决模型合并方式和多数表决模型合并方式。
需要说明的是,税务数据模型可为税银模型,也可根据不同情景组合的其他税务数据模型。
在本实施例中,比如,服务器根据数据的明细情况将税务数据分类为用户数据、财务报表数据和纳税行为数据等等,根据数据的性质将财务报表数据归类为财务数据,将用户数据和纳税行为数据归类为非财务数据。
进一步地,所述步骤b包括:
步骤d,根据所述财务数据的业务逻辑关联性,收集所述财务数据的变量数据,并将所述变量数据进行数据分析,得到分析数据;
步骤e,将所述分析数据进行数据重构,得到重构财务数据,并将所述重构财务数据进行模型构建,得到所述财务数据模型。
具体地,服务器根据财务数据的性质,在数据库中收集与财务数据在业务中有关联或相似属性的变量数据,根据变量数据中的数据类型将该变量数据进行数据分类,然后将分类后的数据进行聚合,得到分析数据,通过预设重构方式将该分析数据中的数据进行相应的结构转换和格式转换,得到重构财务数据,再通过预设模型构建方法将该重构财务数据进行模型构建,从而得到财务数据模型。
其中,预设重构方式包括但不限定于中文转英文方式重构和中文转数字方式重构等,预设模型构建方法与上述模型构建方法相同。
需要说明的是,服务器中预先设置了各个数据对应的英文或/和数据。
在本实施例中,比如,服务器设定财务报表数据为f、纳税数据为t、户现金流数据为uc、用户资产数据为up、用户收益数据为ui、用户实际缴税数据为uat和用户应缴税数据为urt。服务器根据财务数据的性质,在数据库中收集到业务中关联或相似属性的变量数据有用户现金流数据、用户资产数据、用户收益数据、用户实际缴税数据和用户应缴税数据等,根据数据类型可将变量数据用户现金流数据、用户资产数据和用户收益数据进行归类,聚合为财务报表数据,将变量数据用户实际缴税数据和用户应缴税数据进行归类,聚合为纳税数据,然后对财务报表数据和纳税数据进行结构转换和格式转换,将财务报表中的用户现金流数据、用户资产数据和用户收益数据分别转化为f-uc、f-up和f-ui,将纳税数据中的用户实际缴税数据和用户应缴税数据t-uat和t-urt,从而得到f-uc、f-up、f-ui、t-uat和t-urt的重构财务数据,然后将该重构财务数据构建模型,从而得到财务数据模型,因此,财务数据模型可用于税务数据中的财务报表判断,还可用于其他可取得财务报表数据的场景。
进一步,需要说明的是,用户实际缴税数据是用户现金流数据中的用户支付税金的明细数据,反映了当期用户实际缴纳的所有税款总额。用户应缴税数据是用户实际缴税数据,减去用户资产数据中负债资产的年末和年初应缴税数据的差额。财务报表数据中不会直接列出用户实际缴税数据和用户应缴税数据,需要根据用户现金流数据和用户资产数据计算得到。
由此可知,纳税数据属于财务报表数据中的一部分,为了构建的数据模型有更好的区分能力,服务器抽取了财务报表数据中关联性较强和同质性较好的纳税数据。财务数据同时考虑了财务报表数据和纳税数据,综合反映了用户在财务报表数据和纳税数据中的财务状况,即综合用户长期数据和短期数据进行考量,可对用户的财务风险状态进行较好的判断。
进一步地,非财务数据模型可通过上述方法进行模型构建。其中,非财务数据中的变量数据有用户生产经营范围数据、用户经营管理数据和用户纳税管理数据等,最后服务器可将变量数据有用户生产经营范围数据、用户经营管理数据聚合为用户数据,将用户纳税管理数据聚合为纳税行为数据。纳税行为数据属于用户数据的一部分,为了构建的数据模型有更好的区分能力,服务器提取了用户数据中关联性较强和同质性较好的纳税行为数据。
需要说明的是,非财务数据综合了用户数据、纳税行为数据和其他数据,可对用户在非财务数据方面进行有效性的评价。
进一步地,所述步骤c包括:
步骤f,获取所述财务数据模型中的第一模型参数,并获取所述非财务数据模型中的第二模型参数;
步骤g,将所述第一模型参数和所述第二模型参数进行参数映射,得到映射数据;
步骤h,将所述映射数据进行数据整理,得到整理数据,并将所述整理数据进行加权合并,得到所述税务数据模型。
具体地,服务器获取财务数据模型中所有的模型参数,即第一模型参数,并获取非财务数据模型中所有的模型参数,即第二模型参数,根据第一模型参数和第二模型参数的数据完整程度进行对应的评分,然后通过预设映射方法将该第一模型参数和该第二模型参数进行参数关系对应映射,得到映射数据,再通过预设整理方法将该映射数据按照先后顺序进行排序,得到整理数据,再通过预设加权方法对该整理数据进行加权计算,得到加权数据,最后将加权数据构建模型,从而得到税务数据模型。
需要说明的是,预设映射方法有时间对应关系映射和信息对应关系映射等,预设整理方法有按时间排序法和按分值排序法等,预设加权方法有总结加权方法和平均加权方法等,本实施不限制预设映射方法、预设整理方法和预设加权方法的形式。服务器在得到映射数据的同时,加权计算第一模型参数和第二模型参数的分值,得到映射数据相应的分值。
在本实施例中,比如,预设映射方法为时间对应关系映射,预设整理方法为按时间排序法,预设加权方法为平均加权方法。服务器设定用户数据为u、用户生产经营范围数据为u-ps。财务数据模型中所有的模型参数为2017-f-uc、2018-f-uc和2019-f-uc,服务器根据数据完整程度得到2017-f-uc、2018-f-uc和2019-f-uc对应的70、75和80。非财务数据模型中所有的模型参数为2017-u-ps、2018-u-ps和2019-u-ps,服务器根据数据完整程度得到2017-u-ps、2018-u-ps和2019-u-ps对应的分值为76、81和86,根据时间映射关系得到映射数据2017-f-uc--u-ps、2018-f-uc-u-ps和2019-f-uc-u-ps,通过平均加权后得到对应的分值为73、78和83,将映射数据2017-f-uc--u-ps、2018-f-uc-u-ps和2019-f-uc-u-ps按照时间的先后顺序进行排序,得到整理数据,然后在对整理后的数据进行平均加权计算,得到f-uc-u-ps的加权数据,对应的分值为78,然后构建模型,得到f-uc-u-ps的税务数据模型,其对应的分值为78。
步骤s20,获取所述数据库中的征信数据,根据所述征信数据构建征信数据模型。
服务器通过线上方式获取数据库中用户的征信数据,然后根据数据性质将该征信数据进行归类,得到用户各层次信用的征信数据,根据归类后的征信数据构建征信数据模型。
其中,数据性质即征信数据的数据属性。在本实施例中,根据数据性质,征信数据可分为包括但不限制于国家征信数据、银行征信数据和民间征信数据等等。国家征信数据就是政府主导的贷款数据。银行征信数据是指银行及其他金融机构的贷款数据。民间征信数据是指民间金融机构的贷款数据。
所述步骤s20包括:
步骤i,获取所述征信数据,所述征信数据包括用户信用数据和用户贷款数据;
步骤j,根据所述用户信用数据构建得到用户信用数据模型,根据所述用户贷款数据构建得到用户贷款数据模型;
步骤k,将所述用户信用数据模型和所述用户贷款数据模型进行合并,得到所述征信数据模型。
具体地,服务器获取用户的征信数据,该征信数据包括用户信用数据和用户贷款数据,然后构建该用户信用数据和用户贷款数据对应的数据模型,得到对应的用户信用数据模型和用户贷款数据模型,通过预设模型合并方法将用户信用数据模型和用户贷款数据模型进行模型合并,从而得到征信数据模型。
其中,根据用户信用数据构建得到用户信用数据模型和根据用户贷款数据构建得到用户贷款数据模型可通过构建财务报表数据模型方法进行构建。合并得到征信数据模型的方法可通过得到税务数据模型的合并方法进行合并,合并后的征信数据有服务器增加的对应标签。
需要说明的是,用户信用数据包括用户身份数据、用户公共数据和用户信用卡数据等。用户信用卡数据包括发卡银行数据、授信额度数据和借还款数据等。用户贷款数据包括发放贷款机构属性数据、贷款额度数据、贷款期限数据和还款数据等。用户贷款数据属于用户信用数据中的一部分,为了构建的数据模型有更好的区分能力,服务器提取了用户信用数据中关联性较强和同质性较好的用户贷款数据。用户贷款数据中不会直接列出在用户信用数据中,需要在用户信用卡数据中获取和计算得到的。基于用户贷款偿还数据建立的用户贷款数据模型,部分等同于关键用户信用数据指标细化的用户信用数据模型。
步骤s30,将所述税务数据模型和所述征信数据模型进行复合,得到复合数据模型。
服务器在的得到税务数据模型和征信数据模型之后,通过预设模型复合方式将该税务数据模型和征信数据模型进行模型复合,从而得到复合数据模型。其中,预设模型复合方式有但不限制于模型逻辑复合方式和模型维度复合方式。
需要说明的是,复合数据模型综合考虑了用户在税务数据和征信数据方面的表现,从而对用户形成了完整的全面评价。
进一步地,步骤s30包括:
步骤l,获取所述税务数据模型对应的分值,并获取所述征信数据模型对应的标签;
步骤m,将所述分值和所述标签进行逻辑复合,得到所述复合数据模型。
服务器获取税务数据模型中的分值和征信数据模型中的标签,然后将该分值和该标签进行逻辑复合,得到逻辑复合结果,然后根据该逻辑复合结果构建数据模型,从而得到复合数据模型。其中,逻辑复合就是将分值和标签进行多种逻辑组合的操作。
在本实施例中,比如,服务器获取税务数据模型中的分值为90,征信数据模型中的标签为“用户信用额度高”、“用户信用等级优秀”和“用户偿还债务能力强”等等,然后通过逻辑复合后可为“用户税务数据90分且信用额度高且信用等级优秀”、“用户税务数据90且前借款额度适中且偿还债务能力强”等等的逻辑复合结果,最后构建逻辑复合结果模型得到复合数据模型。
本发明实现获取数据库中的税务数据,根据税务数据构建税务数据模型,获取数据库中的征信数据,根据征信数据构建征信数据模型,再将税务数据模型和征信数据合并为复合数据模型。由此可知,本发明复合数据模型是由税务数据模型和征信数据模型复合的,在税务数据模型构建的过程中,获取数据库中的税务数据,根据税务数据构建税务数据模型,采用的是服务器全线上的方式获取数据和构建模型,而不需要依赖人工经验对用户授信做出判断和决策,因此得到用户授信的结果是很精确的。在征信数据模型的过程中,获取数据库中的征信数据,根据征信数据构建征信数据模型,采用的是服务器全线上的方式获取数据和构建模型,而不需要参考个人授信方法,而且得到的相关征信数据源是多样性的,从而使得用户授信的结果更加具有真实性。综上可知,通过复合数据模型能够精准和真实地对用户进行授信,从而提高了用户授信的准确率,以及用户授信的真实性。
进一步地,提出本发明数据模型的构建方法第二实施例。
所述数据模型的构建方法第二实施例与所述数据模型的构建方法第一施例的区别在于,所述数据模型的构建方法还包括:
步骤l,将所述复合数据模型存储于所述数据库中,并接收终端设备发送的授信请求,通过所述复合数据模型对所述授信请求进行授信处理,得到授信结果;
步骤m,将所述授信结果发送至所述终端设备,以供所述终端设备在接收到所述授信结果后,输出所述授信结果。
具体地,在服务器接收用户授信请求之前,用户需要在其终端设备中输入用户的基本数据,然后将基本数据压缩为授信请求,在终端设备侦测到该授信请求之后,将该授信请求发送至服务器中。服务器在得到复合数据模型之后,将该复合数据模型存储在服务器的数据库中,在服务器接收到用户的授信请求之后,分析授信请求中用户的基本数据,然后将用户的基本数据通过复合数据模型进行认定,得到认定结果,然后将认定结果与服务器中预设认定门限进行比较,从而得到授信结果,再将该授信结果发送至用户的终端设备中,在用户的终端设备接收到授信结果之后,输出该授信结果,然后用户可根据该授信结果得到是否有授信资格。
其中,用户的基本数据包括用户的名称、单位地址和单位编号等等。预设认定门限是在服务器中预先设定的要求,在本实施例中不作限制。授信结果就是是否予用户通过授信。
需要说明的是,当认定结果高于或者等于预设认定门限时,授信结果为予通过授信,反之,授信结果为不予通过授信。
在本实施例中,比如,预设认定门限为“用户税务数据90分且信用额度高且信用等级优秀”。服务器将授信请求中用户的基本数据通过复合数据模型进行认定之后的结果为“用户税务数据90分且信用额度高且信用等级良好”则授信结果为不予该用户通过授信,用户根据该授信结果得到没有授信资格。
本实施例将复合数据模型存储于数据库中,并接收终端设备发送的授信请求,通过复合数据模型对授信请求进行授信处理,得到授信结果,将授信结果发送至终端设备,以供终端设备在接收到授信结果后,输出授信结果。由此可知,用户只需在终端设备中输入授信请求,无需再进行其他操作即可查询其授信结果,从而提高了用户授信查询的效率。
此外,本发明还提供一种数据模型的构建装置,参照图2,所述数据模型的构建装置包括:
获取模块10,用于获取服务器数据库中的税务数据;
构建模块20,用于根据所述税务数据构建税务数据模型;
所述获取模块10还用于获取所述数据库中的征信数据;
所述构建模块20还用于根据所述征信数据构建征信数据模型;
复合模块30,用于将所述税务数据模型和所述征信数据模型进行复合,得到复合数据模型。
进一步地,所述获取模块10还用于获取获取所述数据库中的税务数据,所述税务数据包括财务数据和非财务数据。
进一步地,所述构建模块20还用于根据财务数据构建得到财务数据模型;根据非财务数据构建得到非财务数据模型。
进一步地,所述构建模块20还包括:
第一合并单元,用于将所述财务数据模型和所述非财务数据模型进行合并,得到所述税务数据模型。
收集单元,用于根据所述财务数据的业务逻辑关联性,收集所述财务数据的变量数据;
分析单元,用于将所述变量数据进行数据分析,得到分析数据;
重构单元,用于将所述分析数据进行数据重构,得到重构财务数据;
构建单元,用于将所述重构财务数据进行模型构建,得到所述财务数据模型。
进一步地,所述获取模块10还用于获取所述财务数据模型中的第一模型参数;获取所述非财务数据模型中的第二模型参数。
进一步地,所述第一合并单元还包括:
映射子单元,用于将所述第一模型参数和所述第二模型参数进行参数映射,得到映射数据;
整理子单元,用于将所述映射数据进行数据整理,得到整理数据;
加权子单元,用于将所述整理数据进行加权合并,得到所述税务数据模型。
进一步地,所述获取模块10还用于获取所述征信数据,所述征信数据包括用户信用数据和用户贷款数据。
进一步地,所述构建模块20还用于根据所述用户信用数据构建得到用户信用数据模型;根据所述用户贷款数据构建得到用户贷款数据模型。
进一步地,所述构建模块20还包括:
第二合并单元,用于将所述用户信用数据模型和所述用户贷款数据模型进行合并,得到所述征信数据模型。
进一步地,所述获取模块10还用于获取所述税务数据模型对应的分值;获取所述征信数据模型对应的标签。
进一步地,所述复合模块30还用于将所述分值和所述标签进行逻辑复合,得到所述复合数据模型。
进一步地,所述数据模型的构建装置还包括:
存储模块,用于将所述复合数据模型存储于所述数据库中;
接收模块,用于接收终端设备发送的授信请求;
授信模块,通过所述复合数据模型对所述授信请求进行授信处理,得到授信结果;
发送模块,用于将所述授信结果发送至所述终端设备,以供所述终端设备在接收到所述授信结果后,输出所述授信结果。
本发明基于数据模型的构建装置具体实施方式与上述基于数据模型的构建方法各实施例基本相同,在此不再赘述。
此外,本发明还提供一种数据模型的构建设备。如图3所示,图3是本发明实施例方案涉及的硬件运行环境的结构示意图。
需要说明的是,图3即可为数据模型的构建设备的硬件运行环境的结构示意图。
图3即可为数据模型的构建设备的硬件运行环境的结构示意图。
如图所示,该数据模型的构建设备可以包括:处理器1001,例如cpu,存储器1005,用户接口1003,网络接口1004,通信总线1002。其中,通信总线1002用于实现这些组件之间的连接通信。用户接口1003可以包括显示屏(display)、输入单元比如键盘(keyboard),可选用户接口1003还可以包括标准的有线接口、无线接口。网络接口1004可选的可以包括标准的有线接口、无线接口(如wi-fi接口)。存储器1005可以是高速ram存储器,也可以是稳定的存储器(non-volatilememory),例如磁盘存储器。存储器1005可选的还可以是独立于前述处理器1001的存储装置。
可选地,数据模型的构建设备还可以包括rf(radiofrequency,射频)电路,传感器、wifi模块等等。
本领域技术人员可以理解,图3中示出的数据模型的构建设备结构并不构成对数据模型的构建设备的限定,可以包括比图示更多或更少的部件,或者组合某些部件,或者不同的部件布置。
如图3所示,作为一种计算机存储介质的存储器1005中可以包括操作系统、网络通信模块、用户接口模块以及数据模型的构建程序。其中,操作系统是管理和控制数据模型的构建设备硬件和软件资源的程序,支持数据模型的构建程序以及其它软件或程序的运行。
在图所示的数据模型的构建设备中,用户接口1003主要用于用户的终端设备,以供用户向服务器输入用户授信请求和/或显示服务器返回的授信结果;网络接口1004主要用于服务器,与用户终端进行数据通信;处理器1001可以用于调用存储器1005中存储的数据模型的构建程序,并执行如上所述的数据模型的构建设备的控制方法的步骤。
本发明数据模型的构建设备具体实施方式与上述数据模型的构建方法各实施例基本相同,在此不再赘述。
此外,本发明实施例还提出一种计算机可读存储介质,所述计算机可读存储介质上存储有数据模型的构建程序,所述数据模型的构建程序被处理器执行时实现如上所述的数据模型的构建方法的步骤。
本发明计算机可读存储介质具体实施方式与上述数据模型的构建方法各实施例基本相同,在此不再赘述。
需要说明的是,在本文中,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者装置不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者装置所固有的要素。在没有更多限制的数据下,由语句“包括一个……”限定的要素,并不排除在包括该要素的过程、方法、物品或者装置中还存在另外的相同要素。
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多数据下前者是更佳的实施方式。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分可以以软件货物的形式体现出来,该计算机软件货物存储在一个存储介质(如rom/ram、磁碟、光盘)中,包括若干指令用以使得一台数据模型的构建设备执行本发明各个实施例所述的方法。
- 还没有人留言评论。精彩留言会获得点赞!