基于卷积神经网络和注意力模型的人脸识别方法与流程
本发明涉及人脸识别技术,具体为基于卷积神经网络和注意力模型的人脸识别方法。
背景技术:
人脸识别是指通过提取静态图像或视频序列中的人脸信息并与已有的人脸数据库中的信息进行比对,来识别或验证一个或多个人脸的技术。相较于签名、指纹等生物特征识别手段,基于图像的身份识别系统的信息提取更为便捷。因其广泛的应用方向和商业价值而成为计算机视觉和模式识别领域中最活跃的研究方向之一。近年来,基于深度学习的人脸身份识别网络取得了显著的成绩。与此同时,注意力模型在深度学习各个领域被广泛使用。视觉注意力机制模仿人类视觉所特有的大脑信号处理机制。通过快速扫描全局图像,获得需要重点关注的目标区域,而后对这一区域投入更多注意力资源,以获取更多所需要关注目标的细节信息,而抑制其他无用信息。此方式极大地提高了视觉信息处理的效率与准确性。
近几年来,深度学习与视觉注意力机制结合的研究工作,大多数是集中于使用掩码来形成注意力机制。掩码的原理在于通过另一层新的权重,将图片数据中关键的特征标识出来,通过学习训练,让深度神经网络学到每一张新图片中需要关注的区域,也就形成了注意力。注意力有两个大的分类:软注意力(softattention)和强注意力(hardattention)。强注意力是一个随机的预测过程,更强调动态变化,并且不可微,训练一般需要通过增强学习来完成。软注意力的关键在于其可微,即可以计算梯度,可利用神经网络的方法进行训练。在基于cnn的注意力模型中,又主要分为两种注意力域,分别是空间域(spatialdomain)和通道域(channeldomain)。空间域中的注意力主要分布在空间中,表现在图像上就是对图像上不同区域的关注程度不同,反映在数学上即,针对某个大小为c×w×h的特征图,有效的一个空间注意力对应一个大小为w×h的矩阵,每个位置对原特征图对应位置的像素而言即为一个权重。此方法将同一像素的多通道数值进行整合压缩,在计算注意力权重时对像素进行求导,即可得到特征的空间注意力。通道域的注意力主要分布在通道中,表现在图像上就是对不同的图像通道的关注程度不同。反映在数学上即,针对某个大小为c×w×h的特征图,某一通道注意力对应一个大小为c×1×1的矩阵,每个位置对原特征图对应通道的全部像素是一个权重。此方法将同一通道的多个像素数值进行整合压缩,在计算注意力权重时对通道进行求导,即可得到特征的通道注意力。
现有的基于深度学习和注意力模型的人脸识别方法使用训练样本进行人脸特征的自动学习,能够提取到优秀的具有区分度的人脸特征。但是高效的神经网络往往需要大量的参数,在训练和测试时的计算资源消耗较大,这也对网络的迁移、重载和嵌入式设计带来了困难。因此需要寻找一种小型化网络的设计方案。
技术实现要素:
本发明提供了基于卷积神经网络和注意力模型的人脸识别方法,以解决现有的人脸识别神经网络普遍对计算资源消耗大的问题,从而降低网络模型对设备的需求,同时提升计算速度;通过使用注意力模型和bottleneck结构,在进一步减少网络参数的基础上,克服了浅层网络难以提取具有丰富语义信息的特征的缺陷,并结合各个尺度的语义信息来完成识别任务,获得了高准确率的识别结果。
本发明通过如下技术方案实现:基于卷积神经网络和注意力模型的人脸识别方法,包括以下步骤:
s1、对人脸图像进行预处理;
s2、将预处理后的图像数据输入到卷积神经网络中提取高维特征,得到高维特征fc;
s3、将高维特征fc输入到注意力模型中,通过神经网络的训练方法计算注意力掩膜,获得空间域和通道域的注意力分布特征m(fc);
s4、将注意力分布特征m(fc)输入到bottleneck模块中,使用shortcut机制获取特征h(m(fc));
s5、将特征h(m(fc))输入到全卷积网络分类结构中,使用dropout策略和softmax函数,得到最终的人脸识别结果。
从以上技术方案可知,本发明采用注意力模型(attention模型)和bottleneck模块来取代vgg模型中的中高层网络,极大的减少了模型所需的参数数量,有效降低了训练时的显存和时间消耗;同时也有效提升了网络对数据的学习能力,增加了系统的稳定性和实用性。本发明与现有技术相比,具有如下优点和有益效果:
1、本发明中整体神经网络在保留vgg简明结构特点和良好泛化性能的同时,显著地减少了参数数量,大幅降低了训练时的显存和内存占用,同时极小的网络模型也有利于嵌入式设计。
2、本发明中注意力模块基于一维卷积设计,在进一步减少参数数量的基础上,实现了对像素域和通道域信息的充分使用。
3、本发明中bottleneck模块基于一维卷积和单一batchnorm层的设计,在进一步减少参数数量的基础上,减少了计算时间,同时完成了对多维信息的捕捉。
4、本发明具有对本地数据集快速高效的学习能力,在处理具有光照差异和姿态变化的数据时仍具备高性能。
附图说明
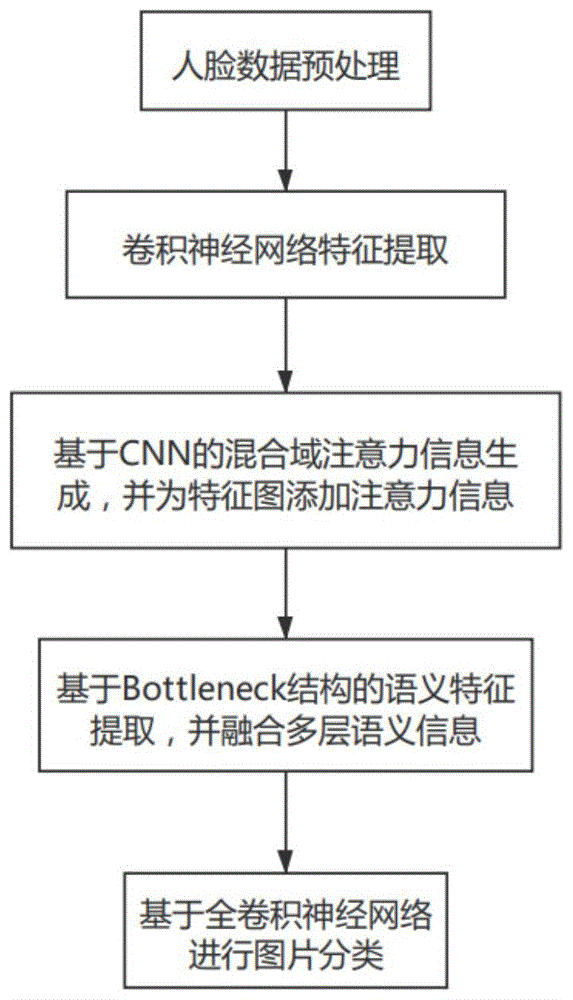
图1为本发明一实施例提供的基于卷积神经网络和注意力模型的人脸识别方法的流程示意图;
图2为本发明一实施例提供的卷积神经网络特征提取模块结构示意图;
图3为本发明一实施例提供的注意力模型和bottlecnk模块的原理示意图;
图4为本发明一实施例提供的基于卷积神经网络和注意力模型的人脸识别神经网络模块的应用示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本实施例提供了基于卷积神经网络和注意力模型的人脸识别方法,采用attention模型和bottleneck模块对浅层卷积神经网络输出特征进行处理,建立包括像素域和通道域信息的高维语义特征;如图1,所述方法具体包括以下步骤:
1)、人脸图像预处理:其中,所述预处理包括将rgb人脸图像转化为灰度图像、对图像进行随机左右翻转、对图像张量进行标准化、图像像素尺寸归一化为
2)、卷积神经网络(cnn)特征提取:将步骤1)预处理后的图像数据输入到卷积神经网络中提取高维特征,得到高维特征fc,其中,卷积神经网络结构采用改进vgg网络的设计;
3)、注意力(attention)模型:将步骤2)输出的高维特征fc输入到软注意力模型中,通过神经网络的训练方法计算注意力掩膜,获得空间域和通道域的注意力分布特征m(fc),其中,注意力模型基于cnn网络设计;
4)、bottleneck模块:将步骤3)输出的注意力分布特征m(fc)输入到bottleneck模块中,使用shortcut机制获取特征h(m(fc)),其中,bottleneck模块基于一维卷积;
5)、全卷积网络(fcn)分类:将步骤4)输出的特征h(m(fc))输入到fcn分类结构中,得到最终的人脸识别结果。fcn分类结构使用dropout策略和softmax函数。
进一步地,步骤1)人脸图像预处理中,将rgb图像转化为灰度图像,具体为:
将rgb图像转化为灰度图像后,单通道灰度图像扩张为n通道灰度图像,图像转化计算公式和通道扩张公式为:
grayi=λigray+biasi
式中,r,g,b分别代表原图像的rgb三通道像素值。i表示第i个灰度通道,
进一步地,步骤1)中对图像张量进行标准化如下:
式中,xi为i通道的输入数据,e(xi)为均值,σ(xi)为标准差。在本实施例中,由于图片进行张量转化时已映射到(0,1)空间,为了减少计算量并获得更具分辨性的输入数据,指定e(xi)=0.5和σ(xi)=0.5,将xi映射到(-1,1)空间,允许生成负样本。
如图2,将归一化后的人脸图像数据输入到卷积神经网络中,以提取目标高维特征。在步骤2)中,输入的图像数据在经过第一个最大池化(maxpooling)层后使用批次标准化(batchnormalization),在每一个卷积层后都使用最大池化进行图片降采样,卷积层数目为5,收缩后的特征尺寸w×h(本实施例中为8×8)为原始图片的
式中,wh为卷积神经网络参数,xi为卷积神经网络输入,m为批次大小。本实施例中批次大小取值32,输出特征fc形式为:(32,128,8,8),在进行批次标准化计算时舍弃偏置项bias。
如图3,使用attention模型为输出的高维特征的不同通道和不同像素点添加注意力信息,并进一步使用bottleneck模块对不同维度的信息进行捕捉,以此提升卷积神经网络性能,具体为:
一、将步骤2)输出的尺寸为(cc,wc,hc)的三维特征(即高维特征)拼接为长度为cc×wc×hc的输入矢量vc;本实施例中三维特征的尺寸为(128,8,8),矢量vc长度为128×8×8=8192;
二、采用全连接网络结构关联输入矢量vc和长度为wc×hc的输出矢量vp,建立每一个高维特征像素点与其他像素点及通道的关系;本实施例中输出矢量vp长度为8×8=64;
三、将卷积输出经过sigmoid激活函数生成注意力特征图σ,此时注意力特征图尺寸为8×8=64,进行掩膜展示时需将矢量重构为8×8的图像数据;
四、将得到的注意力特征图与步骤2)的输出特征fc进行张量乘法计算,形成对空间域和通道域的注意力增强,得到注意力增强后的特征m(fc):
m(fc)=ψ(fc×w×h(contact(fc)))=ψ(fc×w×h(vc))
式中,contact()为矩阵拼接,fc×w×h()为对特征矢量vc进行的网络计算,ψ()为注意力特征图的张量乘法(掩膜)计算。本实施例中,使用张量乘法(掩膜)计算基于广播机制(boardcasting);具体为,高维特征尺度为(32,128,64),将尺度为(32,1,64)的掩膜与128个通道的每个高维特征进行尺度为(32,64)的对应元素相乘,得到特征m(fc)的尺度为(32,128,64)。
进一步地,步骤4)中bottleneck模块使用shortcut机制获取特征的过程,具体为:
一、使用1×1一维卷积将步骤3)输出的特征m(fc)进行降维,融合不同通道之间的信息;本实施例通过降维操作,将通道数由128降至32;
二、对降维后的特征矢量两端进行补零处理,然后进行卷积核为3的一维卷积,即进行3×3卷积,得到的特征矢量尺度为(32,32,64);
三、再次进行1×1卷积,恢复维度,得到尺度为(32,128,64)的特征fb(m(fc));
四、输出特征hb(m(fc)),其中hb(m(fc))=fb(m(fc))+m(fc),本实施例中进行矩阵对位元素相加,特征hb(m(fc))尺度为(32,128,64)。
也就是说,bottelneck结构在对特征m(fc)进行1×1卷积后使用批次标准化,随后连续使用卷积核为3的一维卷积及1×1卷积及relu激活函数,得到特征fb(m(fc))。
参考图4,fcn使用dropout策略和softmax函数对bottleneck输出的数据实施分类,得到最终的识别结果。本实施例中采用了两层全连接层,神经元数目为512,dropout系数取值0.2。
以上所述,仅为本发明专利较佳的实施例,但本发明专利的保护范围并不局限于此,本领域的普通技术人员在本发明专利所公开的范围内,根据本发明专利的技术方案及其发明专利构思加以等同替换或改变,都属于本发明专利的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!