一种基于关键词提取的问答工作方法与流程
本发明涉及一种问答技术领域,特别是涉及一种基于关键词提取的问答工作方法。
背景技术:
可解释性ai既是一个旧话题,也是一个新话题。上世纪70年代末、80年代初,当时很多的辅助顾问系统已在可解释性上有研究。在人工智能研究之初,科学家们就提出人工智能系统需要能解释,特别是这些人工智能系统参与决定的情况下。但是过去的人工智能系统,它们是以规则、以知识为基础,而这些人工智能系统的规则和知识是人定义的,据此推算出来的结果,人是可以理解的。近几年,深度学习很大程度上推动了人工智能的快速发展,可解释性ai成为一个新的课题。对机器学习,特别是深度学习来说,可解释性ai是一个很大的挑战。为什么可解释性ai这么重要呢?第一,对我们使用者来说,如果人工智能的技术只是提一些建议或者帮助我们做决定,做决定的人他要必须理解,为什么人工智能系统给他们提了这个建议。比如,医生做诊断,要能理解为什么医疗诊断系统做这样的建议。第二,对于受到ai影响的人,如果ai自己做了决定,那些受到决定影响的人要能够理解这个决定。第三,对于开发者来说,理解了深度学习的黑盒子,可以通过提供更好的学习数据,改善方法和模型,提高系统能力。
目前,最近的qa著作都提倡端到端语义匹配方法,这种方法倾向于黑匣子,并直接为每个<问题,答案>对输出匹配分数。通常,问题/答案/评论首先被编码成低维向量表示,然后用于基于一些相关函数(例如,点积)来生成匹配分数。实际上,在开放领域中,几乎所有最新的答案选择方式都属于此类,例如,依靠深度神经网络(dnn)中的隐藏单元来表示qa句子对的相关性。尽管这种方式现在非常流行,但是end2end范式由于缺乏可解释性而受到挑战。即使最近做出了许多努力,仍然很难解释密集的矢量表示或答案与问题如何匹配。同时,不同的注意力机制已被整合到dnn模型中,以关联两个句子中的相关部分。尽管在某种程度上,中间注意力可以帮助揭示两个句子之间的软对齐方式,但是由于注意力得分和输出之间存在非线性关系,因此模型的透明度仍然较低。
技术实现要素:
本发明旨在至少解决现有技术中存在的技术问题,特别创新地提出了一种基于关键词提取的问答工作方法。
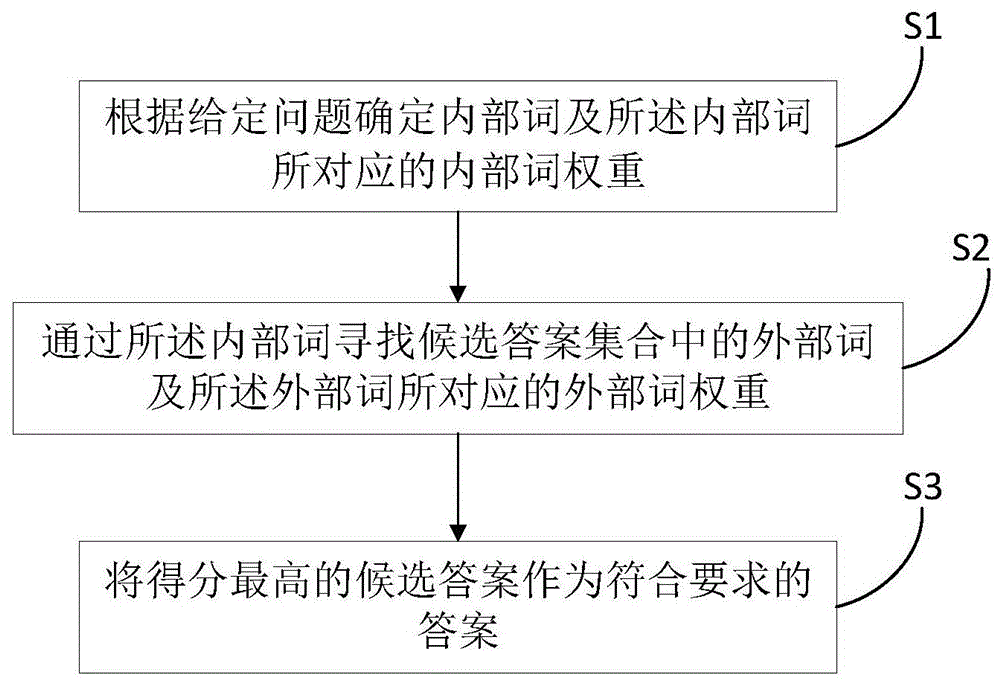
为了实现本发明的上述目的,本发明提供了一种基于关键词提取的问答工作方法,包括以下步骤:
s1,根据给定问题确定内部词及所述内部词所对应的内部词权重;
s2,通过所述内部词寻找候选答案集合中的外部词及所述外部词所对应的外部词权重;
s3,将得分最高的候选答案作为符合要求的答案。
在本发明的一种优选实施方式中,步骤s1包括根据给定问题确定问题单词的权重方法,其方法为:
将给定问题q转化为问题单词序列[q1,q2,q3,…,qn];
然后使用bert神经网络进行编码,问题单词序列进行编码之后输出为
再将输出通过具有sigmoid输出层的全连接前馈网络,输出问题单词序列的权重fint(qi|q)。
在本发明的一种优选实施方式中,问题单词的权重计算方法为:
其中,w表示权重矩阵;
b表示偏移量;
si表示将编码结果
fint(qi|q)表示给定问题q中问题单词qi的权重。
在本发明的一种优选实施方式中,在步骤s1中还包括计算<q,a>对的精确成对匹配分数,即所有内部词的加权和;
其<q,a>对的精确成对匹配分数的计算方法为:
当qi在a中出现,即qi∈a,则i(qi∈a)=1;此时qi为内部词;
当qi未在a中出现,即
其中,sepm(q,a)表示<q,a>对的精确成对匹配分数;
a表示候选答案;
精确成对匹配的目的是为正确答案分配比错误答案更高的分数,从而指导fint(qi|q)对出现在正确答案中但不在其他候选答案中的单词赋予更多的权重,使用标准的交叉熵损失函数,将其最小化:
其中,a+表示给出的候选答案为正确答案;
sepm(q,a+)表示<q,a+>对的精确成对匹配分数。
在本发明的一种优选实施方式中,
当qi在a+中出现,即qi∈a+,则i(qi∈a+)=1;此时qi为内部词;
当qi未在a+中出现,即
其中,sepm(q,a+)表示<q,a+>对的精确成对匹配分数。
在本发明的一种优选实施方式中,步骤s2包括根据候选答案集合确定词对<qi,aj>的相似性方法,其方法为:
把候选答案a转化为候选答案单词序列[a1,a2,a3,…,am],m为候选答案a中候选答案单词的总个数;
然后使用bert神经网络进行编码,候选答案单词序列进行编码之后输出为
用fext(qi,aj|q,a)来评量词对<qi,aj>的相似性。
在本发明的一种优选实施方式中,在步骤s2中词对<qi,aj>的相似性的计算方法为:
其中,fext(qi,aj|q,a)表示评量词对<qi,aj>的相似性;
在本发明的一种优选实施方式中,在步骤s2中还包括问答对之间的匹配程度;
其问答对之间的匹配程度的计算方法为:
其中,fint(qi|q)表示给定问题q中问题单词qi的权重;
max表示选取最大的值;
使用标准的交叉熵损失函数:
sspm(q,a+)表示<q,a+>对的软匹配分数;
sspm(q,a)表示<q,a>对的软匹配分数;
最小化损失函数就是我们的目标函数:
其中,min表示选取最小的值,
θ表示网络里训练得到的参数。
在本发明的一种优选实施方式中,在步骤s3中包括:
设内部词集合为
设外部词集合为
存在候选答案集合为c={c1,c2,c3,…,cu},u为候选答案的总个数,求相似度最高的答案;这个问题用数学公式表示如下:
p()表示概率;
其中,argmax表示求出的最大值的集合;
c表示候选答案集合中的一个候选答案;
d表示关键词;关键词代表的是一个问题中的所有词对获取答案的重要程度,重要程度高的便是关键词,如果这些词对应的也出现在答案里,则是内部词,如果出现在答案中的词和关键词有联系但不是关键词就是外部词,关键词是针对问题而言,内部和外部词针对答案而言。
其中,
对候选答案集合c中的每个候选答案,计算p(d|c)p(c)/p(d)的值,然后选取最大值对应的那个答案cmax,该cmax就是最优解
假设关键词之间相互独立,则公式可以改写为:
其中,qi表示关键词;
η表示关键词集合;
wi表示关键词权重;
由于每个概率很小,避免计算过程中出现下溢,引入对数函数,得到下面公式:
由于关键词分为外部词和内部词,所以分开计算然后求和作为候选答案的得分,最高得分的候选答案便是最符合要求的答案,
综上所述,由于采用了上述技术方案,本发明能够根据关键词(内部词和外部词)匹配到最佳的答案,提高效率。
本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
图1是本发明流程示意框图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
本发明提供了一种基于关键词提取的问答工作方法,如图1所示,包括以下步骤:
s1,根据给定问题确定内部词及所述内部词所对应的内部词权重;
s2,通过所述内部词寻找候选答案集合中的外部词及所述外部词所对应的外部词权重;
s3,将得分最高的候选答案作为符合要求的答案。
在本发明的一种优选实施方式中,步骤s1包括根据给定问题确定问题单词的权重方法,其方法为:
将给定问题q转化为问题单词序列[q1,q2,q3,…,qn],n为给定问题q中问题单词的总个数;
然后使用bert神经网络进行编码,问题单词序列进行编码之后输出为
再将输出通过具有sigmoid输出层的全连接前馈网络,输出问题单词序列的权重fint(qi|q)。
在本发明的一种优选实施方式中,问题单词的权重计算方法为:
其中,σ表示sigmoid函数;
w表示权重矩阵;
b表示偏移量;
si表示将编码结果
fint(qi|q)表示给定问题q中问题单词qi的权重。
在本发明的一种优选实施方式中,在步骤s1中还包括计算<q,a>对的精确成对匹配分数,即所有内部词的加权和;
其<q,a>对的精确成对匹配分数的计算方法为:
当qi在a中出现,即qi∈a,则i(qi∈a)=1;此时qi为内部词;
当qi未在a中出现,即
其中,sepm(q,a)表示<q,a>对的精确成对匹配分数;
a表示候选答案;
精确成对匹配的目的是为正确答案分配比错误答案更高的分数,从而指导fint(qi|q)对出现在正确答案中但不在其他候选答案中的单词赋予更多的权重,使用标准的交叉熵损失函数,将其最小化:
其中,a+表示给出的候选答案为正确答案;
sepm(q,a+)表示<q,a+>对的精确成对匹配分数。
在本发明的一种优选实施方式中,
当qi在a+中出现,即qi∈a+,则i(qi∈a+)=1;此时qi为内部词;
当qi未在a+中出现,即
其中,sepm(q,a+)表示<q,a+>对的精确成对匹配分数。
在本发明的一种优选实施方式中,步骤s2包括根据候选答案集合确定词对<qi,aj>的相似性方法,其方法为:
把候选答案a转化为候选答案单词序列[a1,a2,a3,…,am],m为候选答案a中候选答案单词的总个数;
然后使用bert神经网络进行编码,候选答案单词序列进行编码之后输出为
用fext(qi,aj|q,a)来评量词对<qi,aj>的相似性。
在本发明的一种优选实施方式中,在步骤s2中词对<qi,aj>的相似性的计算方法为:
其中,fext(qi,aj|q,a)表示评量词对<qi,aj>的相似性;
在本发明的一种优选实施方式中,在步骤s2中还包括问答对之间的匹配程度;
其问答对之间的匹配程度的计算方法为:
其中,fint(qi|q)表示给定问题q中问题单词qi的权重;
max表示选取最大的值;
其fext(qi,aj|q,a)在当qi在a中出现,所述i为小于或者等于n的正整数,此时qi为内部词;并在条件1≤j≤m,
当φ=j时,i(φ=j)=1,否则i(φ=j)=0;
使用标准的交叉熵损失函数:
sspm(q,a+)表示<q,a+>对的软匹配分数;
sspm(q,a)表示<q,a>对的软匹配分数;
最小化损失函数就是我们的目标函数:
其中,min表示选取最小的值,
θ表示网络里训练得到的参数。
在本发明的一种优选实施方式中,在步骤s3中包括:
设内部词集合为
设外部词集合为
存在候选答案集合为c={c1,c2,c3,…,cu},u为候选答案的总个数,求相似度最高的答案;这个问题用数学公式表示如下:
p()表示概率;
其中,argmax表示求出的最大值的集合;
c表示候选答案集合中的一个候选答案;
d表示关键词;
其中,
对候选答案集合c中的每个候选答案,计算p(d|c)p(c)/p(d)的值,然后选取最大值对应的那个答案cmax,该cmax就是最优解
假设关键词之间相互独立,则公式可以改写为:
其中,qi表示关键词;
η表示关键词集合;
wi表示关键词权重;
由于每个概率很小,避免计算过程中出现下溢,引入对数函数,得到下面公式:
由于关键词分为外部词和内部词,所以分开计算然后求和作为候选答案的得分,最高得分的候选答案便是最符合要求的答案,
尽管已经示出和描述了本发明的实施例,本领域的普通技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!