一种基于时空自编码器网络和时空CNN的行为异常检测方法与流程
本发明涉及计算机视觉领域,具体涉及一种基于时空自编码器网络和时空cnn的行为异常检测方法。
背景技术:
近年来,随着视频监控数据的急剧增加和全民对于公共安全的日益重视,异常行为的检测得到了越来越广泛的关注。自然场景中人群异常行为的检测是异常检测技术的重要组成部分,在智能视频监控、保障社会公共安全中有重要作用。该技术利用从视频图像中提取的特征,达到检测和定位异常人群行为的目的。
传统的异常人群行为检测采用轨迹追踪或基于时空特征检测的方法。轨迹追踪法通常提取各类轨迹特征,利用聚类算法认定异常行为,具有很高的计算成本,在拥挤的复杂环境中也难以有效提取轨迹信息。基于时空特征的方法着重于提取时间、空间维度的特征来表征运动状态,忽略了视频图像的高级语义特征。同时,大多数算法仅使用正常样本来训练模型,忽略了异常行为信息,不利于模型检测精度的进一步提高,无法实现高精度的实时检测。
近年来随着深度学习的飞速发展,cnn已广泛应用于图像分类,目标检测,行人识别等计算机视觉领域,也在异常检测表现出独特优势。cnn可以自动提取视频图像中的高级语义特征,无需手动定义和提取特征。
卷积神经网络的应用使得异常人群行为的检测有了新的发展,但是现实世界中,异常行为的定义由于环境的不同仍然表现出复杂性。另外,大多数现有的异常行为检测算法具有很高的计算复杂度,不能实时检测异常,检测准确度仍待提高,限制了异常行为检测在现实世界中的应用。
技术实现要素:
有鉴于此,本发明的目的是提供一种基于时空自编码器网络和时空cnn的视频异常检测方法,能够同时获得较高的检测准确率、定位准确率和较快的检测速度。
一种行为异常检测方法,包括如下步骤:
步骤1、获得人群行为的视频数据;
步骤2、构建时空自编码器网络,并将步骤1中不含异常行为的视频数据输入该网络,进行训练;
其中,时空自编码器网络的第一和第二层使用卷积方法对视频中的图像进行操作;第六和第七层使用反卷积方法对视频中的图像进行操作;第三、第四和第五层使用卷积长短期记忆网络;
步骤3、将步骤1中包括正样本和负样本的视频数据同时输入到步骤2训练的时空自动编码器网络,计算得到所有样本的重构误差;将重构误差大于设定阈值的样本被定义为异常行为,并将其筛选为最终的负样本,基于最终的负样本,扩充负样本的数量;
步骤4、构建时空cnn,并采用步骤1中获得的正样本以及经过步骤3筛选后的负样本训练该时空cnn,生成用于异常检测的最终模型;
步骤5、将待检测视频数据输入到步骤4的所述最终模型中进行异常行为检测。
进一步的,对步骤1的视频数据和步骤5的待检测视频数据进行预处理,包括:
先将视频中每帧的像素大小进行统一;然后每帧视频切分成图像块,则取设定帧数的视频,组成三维视频块。
较佳的,图像块的最小尺寸为15×15像素。
较佳的,所述设定帧数最小取10帧。
进一步的,所述预处理还包括将视频帧转换为灰度图像以及归一化处理。
较佳的,所述步骤3中,通过对最终的负样本进行镜像处理,以此扩充负样本的数量。
较佳的,所述时空cnn网络的前三层是卷积层,最后两层是全连层。
较佳的,所述时空cnn网络的前四层使用relu作为激活函数,最后一层使用softmax函数进行分类。
较佳的,如果检测到异常人群行为,则在异常行为发生位置绘制一个矩形框,矩形框上方将显示包含异常行为的可能性。
本发明具有如下有益效果:
本发明考虑群体异常行为稀少并且难以界定,检测模型难以学习到异常行为的特征信息,先用正样本训练时空自编码器网络,再将包含异常行为的视频输入时空自编码器网络,通过选择重建误差阈值筛选负样本,对筛选后负样本再进行扩充,减轻正负样本不均衡的程度;通过筛选后的负样本和原有正样本训练时空cnn,得到最终的检测模型;通过构建时空自编码器网络网络和时空cnn,这两个网络都可以从视频中提取高级语义特征,实现了视频图像中异常人群行为的检测,并提高了该算法在各种场景下的适用性。由于时空cnn模型结构简单,可以在仅使用cpu的环境中实现高精度的实时检测。
通过对视频进行分块和预处理,以便使数据更好的适应于模型,并在一定程度上降低算法的计算成本。
附图说明
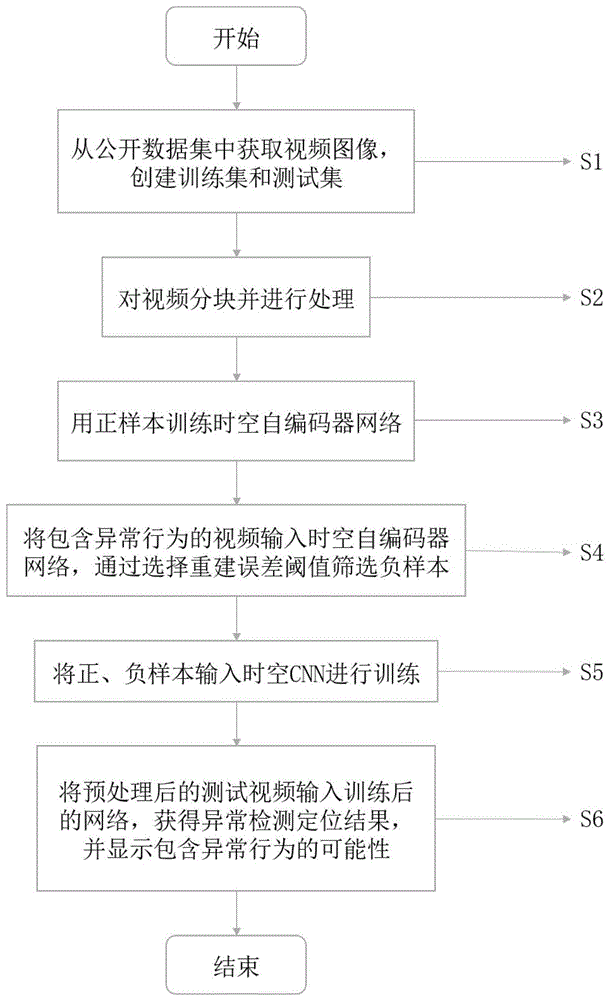
图1是本发明的基于时空自编码器网络和时空cnn的异常检测方法的流程图。
图2是视频分块示例图。
图3是时空自编码器网络结构。
图4是时空cnn网络结构。
图5是ucsd数据集异常检测实例。
具体实施方式
下面结合附图并举实施例,对本发明进行详细描述。
本发明提出的一种基于时空自编码器网络和时空cnn的异常行为检测方法包括:从公开数据集中获取视频图像,创建训练集和测试集;对视频分块并进行预处理;用正样本训练时空自编码器网络;将包含异常行为的视频输入时空自编码器网络,通过选择重建误差阈值筛选负样本;将正、负样本输入时空cnn进行训练;将预处理后的测试视频输入训练后的网络,获得异常检测定位结果,并显示包含异常行为的可能性。
在获取数据集步骤中,如公开数据库中没有给出训练集和测试集,需自行划分,训练集和测试集应独立同分布且均为样本集的子集。
在对视频分块并进行预处理步骤中,统一裁定视频图像大小,并转化为灰度图,利用整个视频的图像灰度均值将所有像素值归一化。目的是减少图像维度,利于后续模型训练。
在构建和训练时空自编码器网络的步骤中,利用卷积和反卷积的方法学习视频的空间特征;引入卷积长短期记忆网络同时建立时序关系、刻画局部空间特征。
在通过时空自编码器网络筛选异常行为样本的步骤中,通过设定重建误差的阈值来定义异常行为,将样本做镜像翻转来扩大含有异常样本的数据数量。
在时空cnn的搭建和训练步骤中,使用三维卷积同时提取视频序列的时间和空间特征,将包含正负样本的训练集输入该时空cnn网络,通过最小化损失函数将网络结构参数调至最优。
在测试集输入时空cnn获得异常检测结果的步骤中,根据样本的索引号,可以确定其在视频序列中的位置,从而定位异常行为。正对检测到的异常行为,绘制一个位于发生位置的矩形框,矩形框上部显示异常行为发生概率。
图1是根据本发明的实施例的基于时空自编码器网络和时空cnn的异常检测方法流程图。参照图1,在步骤s1,首先从人群行为公开数据库中下载图片集,包括训练集和测试集。如公共数据库不提供训练集和测试集,则需要自行划分,训练集和测试集应独立同分布且均为样本集的子集。
在步骤s1获取训练集和测试集后,在步骤s2中,对视频进行分块和预处理,以便使数据更好的适应于模型,并在一定程度上降低算法的计算成本。
更加详细地,首先,将视频中每帧的大小统一为180×120;基于此,当视频比例发生变化时,由于像素值是统一的,因此构建的网络仍然有效。其次,我们将rgb格式的视频帧转换为灰度图像,减少视频帧的尺寸。然后从每个视频帧中减去整个视频的平均图像并归一化,以保证每个像素值都落在[0,1]中。最后,将视频序列剪切并分为15×15×10的视频块,如图2所示。15表示空间维度,15×15的像素区域可以包含最小的异常行为。10表示时间维度,少于10帧的片段几乎没有实际意义。预处理后,视频块作为输入可用于训练和测试阶段。
在步骤s2得到预处理后的视频图像之后,在步骤s3中,构建时空自编码器网络,并将不含异常行为的视频,经预处理后输入该网络,训练此模型。
具体地,为了分析空间维度的特征,网络的第一和第二层以及网络的第六和第七层分别使用卷积和反卷积方法对视频中的图像进行操作。卷积的过程等效于对视频中的图像进行编码,从而减小数据的尺寸。解卷积的过程等效于解码编码的数据以恢复数据的维数。通过此过程,网络将学习视频的空间尺寸特征。
为了分析时间维度的特征,网络的第三,第四和第五层使用卷积长短期记忆网络(convlstm),在递归神经网络中,由于梯度消失的问题,信息只能在相对较短的距离内流动。lstm可以有选择地传输信息,从而在一定程度上解决了梯度消失的问题。与处理时间序列(例如语音和文本)不同,在分析视频序列时需要进行大量的卷积运算。因此,选用convlstm来分析视频。由于输入视频块的像素值较低(15×15×10),因此使用3×3大小的滤波器。本实施例中改进cnn网络结构如图3,经调试后确定网络参数。
在步骤s3获得最优网络结构参数后,在步骤s4中,将经过预处理的视频数据输入到带有最优参数的时空自编码器网络中,计算每个视频块的重构误差,选择阈值以对正样本和负样本进行分类(例如0.035),大于阈值定义为异常行为。阈值越大(例如0.05),异常行为的定义越窄,因此异常行为的数量越少。将正样本和负样本同时输入到时空自动编码器网络,并计算所有样本的重构误差。重构误差大于阈值的样本被定义为异常行为,由此对负样本进行了筛选。通过镜像上述样本,我们可以进一步增加包含异常行为的样本数量。
在步骤s5中,构建时空cnn。使用监督学习方法来学习标记的正样本和负样本(上一步骤中筛选后的负样本),生成用于异常检测的最终模型。不同于二维卷积,时空卷积的卷积核和特征图都是三维的,可以同时提取视频序列的空间和时间特征。式(1)定义了视频块和卷积核的三维卷积过程,其中i,j,k分别表示卷积核的时间维度的长度,宽度和长度。x×y×t表示视频块的大小,对应于上文所述的15×15×10。
具体地,时空cnn的输入是15×15×10视频块,输出将输入分为两类。由于输入大小较小,因此网络不需要使用池化层。网络的前三层是卷积层,用于提取视频块的特征。第一层使用32(3×3×3)个卷积内核对输入进行卷积,以生成32(13×13×8)个特征块。该层的dropout比率为0.25。第二层使用64(3×3×3)卷积内核对第一层输出的特征块进行卷积,以生成64(11×11×6)个特征块。该层的dropout比率为0.25。第三层使用128(3×3×1)个卷积内核对第二层输出的特征块进行卷积,以生成128(9×9×6)个特征块。该层的dropout比率为0.4。网络的最后两层是全连层,根据从前三层提取的特征对视频块进行分类。网络的前四层使用relu作为激活函数,最后一层使用softmax函数进行分类。网络结构及参数如图4所示。
该模型充分利用了正常和异常行为的信息,因此具有鲁棒性。同时,模型网络结构简单,可以实现异常行为的实时检测和定位。将包含正负样本的视频数据输入该网络,对模型进行训练,得到网络模型的最优参数。
在步骤s5获得优化后的时空cnn模型后,在步骤s6中,将待检测的经预处理被分割为15×15×10个视频块的视频序列输入训练完成的时空cnn。根据样本的索引号,可以确定其在视频序列中的位置,从而可以定位异常人群行为。每10帧执行一次检测结果。如果检测到异常人群行为,则在异常行为发生位置绘制一个矩形框,矩形框上方将显示包含异常行为的可能性,如图5所示。
综上所述,以上仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!