一种使用对抗式3D分层网络进行手部姿态估计的方法及系统与流程
本发明涉及一种使用对抗式3d分层网络进行手部姿态估计的方法及系统,属于生物肢体语言检测与行为分析领域。
背景技术:
手部姿态估计任务,指的是从包含手部区域的深度图中,定位出手的各个关节点在世界坐标系下的坐标(x,y,z)。随着人工智能的发展,手部姿态估计任务在计算机视觉中的地位越发重要。精准的手部姿态估计,对于虚拟现实、手势识别以及人机交互而言是关键的一环。尽管对该领域的研究已经持续了数十年,但是由于手的自由度高、各个手指的相似性以及手指之间的遮挡,使得手部姿态估计任务依然面对着极大的挑战。
传统的基于卷积神经网络的方法,是将深度图作为2d数据输入到2d卷积神经网络中,直接回归出关节点的位置。但是深度图实际上代表的是2.5d数据,直接将其视作2d数据并且采用2d卷积神经网络进行处理,并不能很好地提取到深度图中的关键信息。除此之外,直接回归关节点的位置是一个高度非线性过程,会增加网络的学习难度。
技术实现要素:
发明目的:一个目的是提出一种使用对抗式3d分层网络进行手部姿态估计的方法,以解决现有技术存在的上述问题。进一步目的是提出一种实现上述方法的系统。
技术方案:一种使用对抗式3d分层网络进行手部姿态估计的方法,包括以下步骤:
步骤1、利用3d分层预测网络对各个关节点预测;
步骤2、利用姿态判别网络对输入的手部姿态的合理性进行判断;
步骤3、3d分层预测网络和姿态判别网络对抗训练。
在进一步的实施例中,所述步骤1进一步包括:
步骤1-1、将包含手部特征的原始深度图中的数据投影到3d空间;投影到3d空间的数据根据预设的体素值进行离散化处理;体素各个位置的值v(i,j,k)根据该位置是否被离散的点所覆盖被设为1或者0;
步骤1-2、3d分层预测网络通过第一部分对手部进行特征提取和连续的下采样与上采样操作,获取手部的全局信息:
特征提取:使用卷积神经网络的卷积操作,来实现对特征的提取;
下采样:采用最大池化操作来实现下采样,对于尺寸为m*n的图像进行下采样,求出m和n的公约数a,以该公约数a作为下采样倍率,将原始图像a*a的窗口内的所有像素的最大值作为代表值,以使得图像符合显示区域的大小;
上采样:利用待求像素四个邻像素a(x1,y1)、b(x1,y2)、c(x2,y1)、d(x2,y2)的灰度在x方向上作线性内插,得到:
式中,a像素点和c像素点共处x方向,b像素点和c像素点共处x方向;(x,y1)表示a像素点和c像素点之间的插值像素坐标,(x,y2)表示b像素点和d像素点之间的插值像素坐标;
接着在y方向作线性内插,最终得到:
式中,(x,y)表示进一步计算出的(x,y1)和(x,y2)在y方向上的插值像素点;
步骤1-3、3d分层预测网络通过第二部分将手部姿态估计任务分解成多个子任务,一个子任务负责一个关节点位置的预测,形成和关节点数目一样的分支,每个分支对应一个子任务来负责提取关节点周围的局部信息;
步骤1-4、在3d分层预测网络分解子任务后,预测结果和实际结果会有偏差,损失项如下:
式中,hj和cj分别表示由真实的各个关节点位置以及预测的关节点位置生成的3d热图,j表示关节节点总数;
步骤1-5、将步骤1-4获得的损失项作为监督项,就可对3d分层预测网络进行监督训练;
步骤1-6、将步骤1-4预测的3d热图进行处理,就可以得到关节点的坐标:
在得到预测的各个关节点的3d热图之后,取该热图中最大值所在的位置,即可获得关节点相对于热图的坐标,然后根据原图到热图的换算比例,即可得到在原始深度图中,各个关节点的3d坐标,从而得到预测的手部姿态;
在进一步的实施例中,所述步骤2进一步包括:
步骤2-1、利用姿态判别网络对步骤1中的预测结果添加物理约束,输入真实手部姿态和预测手部姿态,将真实手部姿态判为真,预测手部姿态判为假;
其中,真实手部姿态的算法如下:
式中,hj表示由真实的各个关节点位置生成的3d热图,j表示关节节点总数;
预测手部姿态的算法如下:
式中,cj表示由预测的各个关节点位置生成的3d热图,j表示关节节点总数。
在进一步的实施例中,所述步骤3进一步包括:
步骤3-1、3d分层预测网络单独训练,当预测的结果较为准确,即得到的3d热图的锋利度达到阈值的时候,3d分层预测网络和姿态判别网络进行对抗训练;
步骤3-2、姿态判别网络通过最小化损失函数来实现对输入的姿态进行区分:
姿态判别网络会交替地输入真实的手部姿态以及预测的手部姿态,并输出分类结果来代表去输入的判定,其采用交叉熵损失作为损失函数:
lcritic=-[y×log(x)+(1-y)×log(1-x)]
式中,x表示输入的手部姿态,可以为真实的手部姿态与预测的手部姿态,y表示对输入的分类结果,如果输入的是真实的手部姿态,y为1,反之为0;
步骤3-3、3d分层网络使预测的结果尽可能地接近真实的手部姿态,来迷惑姿态判别网络,3d分层网络求解损失最小问题来使得预测的结果更加合理:
所述在对抗训练过程中,3d分层预测网络的损失函数为:
l=α1×lme+α2×lcritic
式中,第二项中的y为1,目的是希望3d分层预测网络预测的手部姿态能够尽可能迷惑姿态判别网络;
步骤3-4、重复步骤3-1至3-3,使得姿态判别网络为3d分层网络的预测结果添加物理约束。
一种使用对抗式3d分层网络进行手部姿态估计的系统,包括用于对各个关节点预测的3d分层预测网络模块;用于对输入的手部姿态的合理性进行判断的姿态判别网络模块;以及用于促使3d分层预测网络和姿态判别网络进行对抗训练的对抗训练模块。
在进一步的实施例中,所述3d分层预测网络模块进一步包括第一部分和第二部分,所述第一部分呈沙漏结构,通过该部分的下采样和上采样操作以获得充分的全局信息;所述第二部分用于进行分层操作,在该第二部分中,手部姿态估计任务被解耦成多个子任务,一个子任务负责一个关节点位置的预测,形成和关节点数目一样的分支,每个分支对应一个子任务来负责提取关节点周围的局部信息;所述3d分层预测网络模块进一步用于预测出各个关节点的坐标,以从深度图转化来的体素化的手部区域为输入,经过3d卷积神经网络,输出代表关节点概率分布的3d热图;
所述姿态判别网络模块进一步以真实和预测的手部姿态作为输入,并将前者判为真后者判为假;
所述对抗训练模块进一步监测3d分层预测网络模块的预测结果,当预测结果的准确度达到阈值,即得到的3d热图的锋利度达到阈值时,对抗训练模块促使3d分层预测网络和姿态判别网络进行对抗训练,在对抗训练的过程中,姿态判别网络的目的是尽可能的将预测的手部姿态与真实的手部姿态区分开,而3d分层预测网络的目的则是使预测的结果尽可能地接近真实的手部姿态,来迷惑姿态判别网络。
在进一步的实施例中,所述3d分层预测网络模块进一步将包含手部特征的原始深度图中的数据投影到3d空间;投影到3d空间的数据根据预设的体素值进行离散化处理;体素各个位置的值v(i,j,k)根据该位置是否被离散的点所覆盖被设为1或者0;
3d分层预测网络通过第一部分对手部进行特征提取和连续的下采样与上采样操作,获取手部的全局信息:
特征提取:使用卷积神经网络的卷积操作,来实现对特征的提取;
下采样:采用最大池化操作来实现下采样,对于尺寸为m*n的图像进行下采样,求出m和n的公约数a,以该公约数a作为下采样倍率,将原始图像a*a的窗口内的所有像素的最大值作为代表值,以使得图像符合显示区域的大小;
上采样:利用待求像素四个邻像素a(x1,y1)、b(x1,y2)、c(x2,y1)、d(x2,y2)的灰度在x方向上作线性内插,得到:
式中,a像素点和c像素点共处x方向,b像素点和c像素点共处x方向;(x,y1)表示a像素点和c像素点之间的插值像素坐标,(x,y2)表示b像素点和d像素点之间的插值像素坐标;
接着在y方向作线性内插,最终得到:
式中,(x,y)表示进一步计算出的(x,y1)和(x,y2)在y方向上的插值像素点;
3d分层预测网络通过第二部分将手部姿态估计任务分解成多个子任务,一个子任务负责一个关节点位置的预测,形成和关节点数目一样的分支,每个分支对应一个子任务来负责提取关节点周围的局部信息;
在3d分层预测网络分解子任务后,预测结果和实际结果会有偏差,损失项如下:
式中,hj和cj分别表示由真实的各个关节点位置以及预测的关节点位置生成的3d热图,j表示关节节点总数;
在得到预测的各个关节点的3d热图之后,取该热图中最大值所在的位置,即可获得关节点相对于热图的坐标,然后根据原图到热图的换算比例,即可得到在原始深度图中,各个关节点的3d坐标,从而得到预测的手部姿态;
所述姿态判别网络模块进一步利用姿态判别网络对3d分层预测网络中的预测结果添加物理约束,输入真实手部姿态和预测手部姿态,将真实手部姿态判为真,预测手部姿态判为假;
其中,真实手部姿态的算法如下:
式中,hj表示由真实的各个关节点位置生成的3d热图,j表示关节节点总数;
预测手部姿态的算法如下:
式中,cj表示由预测的各个关节点位置生成的3d热图,j表示关节节点总数;
所述对抗训练模块进一步监测3d分层预测网络,首先由3d分层预测网络单独训练,当预测的结果较为准确,即得到的3d热图的锋利度达到阈值的时候,3d分层预测网络和姿态判别网络进行对抗训练:
姿态判别网络会交替地输入真实的手部姿态以及预测的手部姿态,并输出分类结果来代表去输入的判定,其采用交叉熵损失作为损失函数:
lcritic=-[y×log(x)+(1-y)×log(1-x)]
式中,x表示输入的手部姿态,可以为真实的手部姿态与预测的手部姿态,.y表示对输入的分类结果,如果输入的是真实的手部姿态,y为1,反之为0;
3d分层网络使预测的结果尽可能地接近真实的手部姿态,来迷惑姿态判别网络,3d分层网络求解损失最小问题来使得预测的结果更加合理:
l=α1×lme+α2×lcritic
式中,第二项中的y为1,目的是希望3d分层预测网络预测的手部姿态能够尽可能迷惑姿态判别网络。
有益效果:本发明提出了一种使用对抗式3d分层网络进行手部姿态估计的方法及系统,包括一个对抗式3d分层网络,对抗式3d分层网络主要包括两个部分:3d分层预测网络(3dhnet)负责各个关节点的预测,3dhnet相比传统的2d卷积神经网络能够提取到深度图中的关键信息,姿态判别网络(pdnet)负责对输入的手部姿态的合理性进行判断。通过将3dhnet和pdnet进行对抗训练,在对抗训练的过程中,pdnet的目的是尽可能的将预测的手部姿态与真实的手部姿态区分开,而3dhnet的目的则是使预测的结果尽可能地接近真实的手部姿态,来迷惑pdnet,通过这种对抗训练的方式,pdnet以一种自适应的方式为3dhnet的预测结果添加了物理约束,来使得3dhnet的预测结果更加的合理和准确。
附图说明
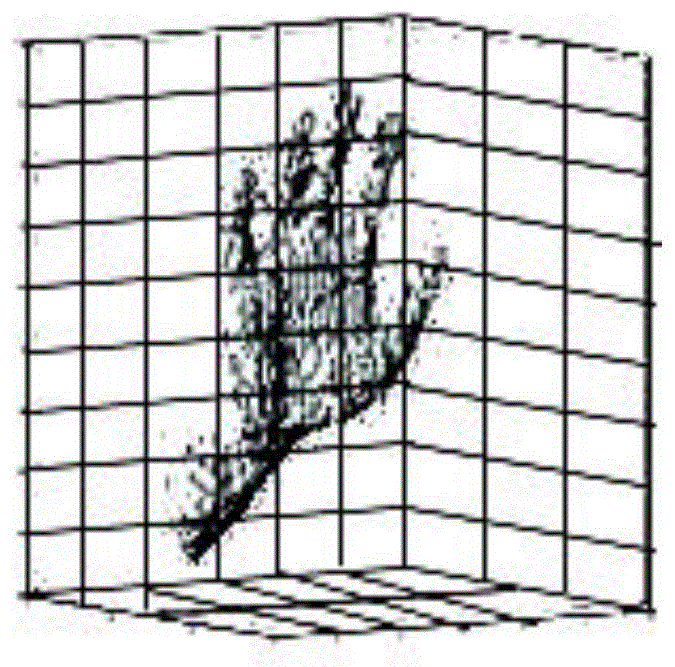
图1为本发明步骤1中体素化后得到的手部区域示意图。
图2为本发明考虑预测出的关节点所形成的手部姿态是否合理的示意图。
图3为本发明中由3dhnet和pdnet组成的对抗式3d分层网络的整体结构示意图。
图4为本发明中3d分层预测网络(3dhnet)的结构示意图。
图5为本发明中姿态判别网络(pdnet)的结构示意图。
图6为本发明引入pdnet前后的预测结果变化示意图。
具体实施方式
申请人认为,针对传统的手部姿态估计方法存在的问题,目前比较有效的方式采取体素化的输入形式,使用3d卷积神经网络进行特征提取,预测表示关节点位置概率分布的3dheatmap(3d热图)能够使得关节点预测达到较高的精度。将原始的深度图转化成体素化的输入,需要四步:第一步,深度图中的数据会被投影到3d空间;第二步,投影到3d空间的数据会根据预设的体素大小进行离散化处理;第三步,体素各个位置的值v(i,j,k)将根据该位置是否被离散的点所覆盖被设为1或者0。体素化后的手部区域如图1所示,其中蓝色的点表示该位置的值为1。
手是一个结构化物体,各个关节点通过骨骼连接形成的手部姿态需要满足物理学约束。所以在手部姿态估计任务中,除了要考虑预测的关节点位置的准确性,还需要考虑预测出的关节点所形成的手部姿态是否合理。
如图2所示,右图拇指的关节点位置和左图十分接近,但是右图的拇指弯曲程度却是不合理的。所以可以采取类似生成式对抗网络(gan)中的思想,来对预测出的关节点位置添加一定的物理约束,来保证手部姿态的合理性。
实施例一:
生成式对抗网络(gan)包括生成网络和判别网络,其中生成网络负责以随机噪声为输入,生成图片;判别网络以真实的图片或者生成的图片为输入,判别其真假。生成网络的目的生成与真实图片尽可能接近的图片来迷惑判别网络,而判别网络则是尽可能地将生成图片判为假,真实图片判为真。所以可以借鉴生成式对抗网络的思想,将姿态估计网络视为生成网络,以预测的姿态与真实姿态作为判别网络输入,通过对抗学习来达到以自适应的方式对预测结果添加物理约束的目的。
在本发明中,申请人提出一个对抗式3d分层网络(pean)用于准确而合理的手部姿态估计。对抗式3d分层网络主要包括两个部分:3d分层预测网络(3dhnet)负责各个关节点的预测;姿态判别网络(pdnet)负责对输入的手部姿态的合理性进行判断。整体的网络结构如图3所示。
3dhnet的目标是预测出各个关节点的坐标,它以从深度图转化来的体素化的手部区域为输入,经过3d卷积神经网络,输入代表关节点概率分布的3dheatmap。考虑到手是一个结构化的物体,实现准确的位置估计,不仅需要充分的全局信息,还需要一定的局部信息,所以3dhnet采取了一种分层的结构。如图4所示,3dhnet的结构主要包括两个部分。第一个部分是一个类似于沙漏的结构,通过该部分的下采样和上采样操作,网络能够获得充分的全局信息。第二个部分则是进行了分层的操作,在该部分,手部姿态估计任务被解耦成了多个子任务,一个子任务负责一个关节点位置的预测,所以会形成和关节点数目一样的分支,每个分支对应一个子任务来负责提取关节点周围的局部信息。通过这样一个在网络尾部分层的操作,使得3dhnet既获得了充分的全局信息,也获得了判别性的局部信息,从而提升了预测结果的精度。
具体的,所述3dhnet进一步将包含手部特征的原始深度图中的数据投影到3d空间;投影到3d空间的数据根据预设的体素值进行离散化处理;体素各个位置的值v(i,j,k)根据该位置是否被离散的点所覆盖被设为1或者0;
3dhnet通过第一部分对手部进行下采样和上采样操作,获取手部的全局信息:
下采样:对于尺寸为m*n的图像进行下采样,求出m和n的公约数a,以该公约数a作为下采样倍率,将原始图像a*a的窗口内的所有像素求均值并合并为一个像素,以使得图像符合显示区域的大小;
上采样:利用待求像素四个邻像素a(x1,y1)、b(x1,y2)、c(x2,y1)、d(x2,y2)的灰度在x方向上作线性内插,得到:
式中,a像素点和c像素点共处x方向,b像素点和c像素点共处x方向;(x,y1)表示a像素点和c像素点之间的插值像素坐标,(x,y2)表示b像素点和d像素点之间的插值像素坐标;
接着在y方向作线性内插,最终得到:
式中,(x,y)表示进一步计算出的(x,y1)和(x,y2)在y方向上的插值像素点;
3dhnet通过第二部分将手部姿态估计任务分解成多个子任务,一个子任务负责一个关节点位置的预测,形成和关节点数目一样的分支,每个分支对应一个子任务来负责提取关节点周围的局部信息;
在3d分层预测网络分解子任务后,预测结果和实际结果会有偏差,损失项如下:
式中,hj和cj分别表示由真实的各个关节点位置以及预测的关节点位置生成的3d热图,j表示关节节点总数;
在得到预测的各个关节点的3d热图之后,取该热图中最大值所在的位置,即可获得关节点相对于热图的坐标,然后根据原图到热图的换算比例,即可得到在原始深度图中,各个关节点的3d坐标,从而得到预测的手部姿态。
3dhnet负责的是对关节点位置的预测,在整个预测的过程中,并没有对手部姿态添加显式或者隐式的物理约束,这使得预测结果所形成的手部姿态的合理性无法得到保证。所以,通过对抗学习的方式引入了pdnet,利用一种自适应的方式为预测结果添加物理约束,来使得预测的结果更加准确和合理。
pdnet是一个轻量级的网络,结构如图5所示,它以真实或预测的手部姿态作为输入,并将前者判为真后者判为假。真实的手部姿态指的是由真实的各个关节点位置生成的3dheatmap平方后相加得到的,而预测的手部姿态则是由预测的heatmap平方相加得到。采取3dheatmap平方后相加的结果作为手部姿态有两个优势,一个是只需要很小的计算量就可以得到手部姿态,另一个则是这种形式的手部姿态可以直观地表示出各个关节点的位置以及它们之间的相互关系。
具体的,pdnet利用姿态判别网络对步骤1中的预测结果添加物理约束,输入真实手部姿态和预测手部姿态,将真实手部姿态判为真,预测手部姿态判为假;
其中,真实手部姿态的算法如下:
式中,hj表示由真实的各个关节点位置生成的3d热图,j表示关节节点总数;
预测手部姿态的算法如下:
式中,cj表示由预测的各个关节点位置生成的3d热图,j表示关节节点总数。
3dhnet与pdnet以对抗学习的方式结合在一起。首先3dhnet会单独训练,当预测的结果较为准确,即得到的3dheatmap较为锋利的时候,3dhnet将会和pdnet进行对抗训练。在对抗训练的过程中,pdnet的目的是尽可能的将预测的手部姿态与真实的手部姿态区分开,而3dhnet的目的则是使预测的结果尽可能地接近真实的手部姿态,来迷惑pdnet。通过这种对抗训练的方式,pdnet以一种自适应的方式为3dhnet的预测结果添加了物理约束,来使得3dhnet的预测结果更加的合理和准确。
具体的,对抗训练的过程如下:
首先,3d分层预测网络单独训练,当预测的结果较为准确,即得到的3d热图的锋利度达到阈值的时候,3d分层预测网络和姿态判别网络进行对抗训练:
接着,姿态判别网络通过最小化损失函数来实现对输入的姿态进行区分,姿态判别网络会交替地输入真实的手部姿态以及预测的手部姿态,并输出分类结果来代表去输入的判定,其采用交叉熵损失作为损失函数:
lcritic=-[y×log(x)+(1-y)×log(1-x)]
式中,x表示输入的手部姿态,可以为真实的手部姿态与预测的手部姿态,y表示对输入的分类结果,如果输入的是真实的手部姿态,y为1,反之为0;
接着,3d分层网络使预测的结果尽可能地接近真实的手部姿态,来迷惑姿态判别网络,3d分层网络求解损失最小问题来使得预测的结果更加合理:
l=α1×lme+α2×lcritic
式中,第二项中的y为1,目的是希望3d分层预测网络预测的手部姿态能够尽可能迷惑姿态判别网络;
重复上述步骤,使得姿态判别网络为3d分层网络的预测结果添加物理约束。
在多个手部姿态数据集上的实验表明,我们的pean的整体预测精度达到了领先的水平,并且如图6所示,对比引入pdnet前后的预测结果,可以看出,在3dhnet与pdnet进行对抗学习之后,原本预测的不合理变得更加的合理和准确。
实施例二:
在3d分层预测网络分解子任务后,且计算出损失项之后,将获得的损失项进行在线加强,整个网络的总损失函数如下:
lossa=losst+lossf+lossm+lossn+lossl+λr(ω)
式中,losst表示大拇指关节的损失,lossf表示食指关节的损失,lossm表示中指关节的损失,lossn表示无名指关节的损失,lossl表示小拇指关节的损失,lossa为整个网络的总损失;losst、lossf、lossm、lossn、lossl分别满足步骤1-4中的公式计算,losst包含两个关节节点,lossf、lossm、lossn、lossl包含三个关节节点;
将输出的3d热图和3d方向矢量进行后处理,得到深度图像上的点到关节处的偏移矢量:
eij=l(1-hij)dij
其中,l表示以关节位置为球心做出的球体半径长度,hij表示从第i个关节节点到第j个关节节点的3d热图,dij表示从第i个关节节点到第j个关节节点的3d方向矢量,eij表示从第i个关节节点到第j个关节节点的偏移矢量;
通过预测候选关节节点与实际关节节点像素加权融合得到修正后的关节坐标:
式中,ekj表示预测候选关节节点的第k个候选节点到第j个候选节点的偏移矢量,pk为第k个候选节点的坐标,ωk表示第k个候选节点的权重值,k表示预测候选节点总数,选取数值为4,fj表示最终获得的第j个关节节点的3d坐标。
3dhnet负责的是对关节点位置的预测,在整个预测的过程中,并没有对手部姿态添加显式或者隐式的物理约束,这使得预测结果所形成的手部姿态的合理性无法得到保证。所以,通过对抗学习的方式引入了pdnet,利用一种自适应的方式为预测结果添加物理约束,来使得预测的结果更加准确和合理。
pdnet是一个轻量级的网络,结构如图5所示,它以真实或预测的手部姿态作为输入,并将前者判为真后者判为假。真实的手部姿态指的是由真实的各个关节点位置生成的3dheatmap平方后相加得到的,而预测的手部姿态则是由预测的heatmap平方相加得到。采取3dheatmap平方后相加的结果作为手部姿态有两个优势,一个是只需要很小的计算量就可以得到手部姿态,另一个则是这种形式的手部姿态可以直观地表示出各个关节点的位置以及它们之间的相互关系。
具体的,pdnet利用姿态判别网络对步骤1中的预测结果添加物理约束,输入真实手部姿态和预测手部姿态,将真实手部姿态判为真,预测手部姿态判为假;
其中,真实手部姿态的算法如下:
式中,hj表示由真实的各个关节点位置生成的3d热图,j表示关节节点总数;
预测手部姿态的算法如下:
式中,cj表示由预测的各个关节点位置生成的3d热图,j表示关节节点总数。
3dhnet与pdnet以对抗学习的方式结合在一起。首先3dhnet会单独训练,当预测的结果较为准确,即得到的3dheatmap较为锋利的时候,3dhnet将会和pdnet进行对抗训练。在对抗训练的过程中,pdnet的目的是尽可能的将预测的手部姿态与真实的手部姿态区分开,而3dhnet的目的则是使预测的结果尽可能地接近真实的手部姿态,来迷惑pdnet。通过这种对抗训练的方式,pdnet以一种自适应的方式为3dhnet的预测结果添加了物理约束,来使得3dhnet的预测结果更加的合理和准确。
对抗训练还可以采用如下方法:
首先,3d分层预测网络单独训练,当预测的结果较为准确,即得到的3d热图的锋利度达到阈值的时候,3d分层预测网络和姿态判别网络进行对抗训练:
接着,姿态判别网络训练最大化损失函数建立对抗样本:
式中,j(x,y)max表示最大损失函数,j表示交叉熵损失,
接着,姿态判别网络对3d分层预测网络添加平滑扰动,平滑锋利的3d热图,将预测的手部姿态与真实的手部姿态区分开,平滑扰动函数如下:
式中,ri,j表示坐标(i,j)处rgb三个通道像素值的平均值:
ri+1,j表示ri,j坐标横向平移一个像素之后的rgb三个通道像素值的平均值,ri,j+1表示ri,j坐标纵向平移一个像素之后的rgb三个通道像素值的平均值;
接着,3d分层网络使预测的结果尽可能地接近真实的手部姿态,来迷惑姿态判别网络,3d分层网络求解多目标优化问题寻找扰动:
argmin(x*+kt)
式中,k表示多目标函数平衡系数,argmin()表示对括号内的目标函数取最小值时的变量值;
重复上述步骤,使得姿态判别网络为3d分层网络的预测结果添加物理约束。
在多个手部姿态数据集上的实验表明,我们的pean的整体预测精度达到了领先的水平,并且如图6所示,对比引入pdnet前后的预测结果,可以看出,在3dhnet与pdnet进行对抗学习之后,原本预测的不合理变得更加的合理和准确。
- 还没有人留言评论。精彩留言会获得点赞!