一种面向电力科技成果的知识图谱可视化方法与流程
本发明涉及语义分析技术领域,具体来说是一种面向电力科技成果的知识图谱可视化方法。
背景技术:
随着电力信息化的不断深入和电力科技的不断发展,电力科技成果正以前所未有的速度增长,迫切需要电力科技成果的有效管理。然而由于各级电力企业在电力科技成果管理过程中缺乏标准化的数据输出格式的规定,使得数据来源种类不一、数据表示格式多样,科技成果之间的关系也错综复杂。如何高效、灵活地表示电力科技成果内在的关系和潜在的知识,是实现电力科技成果高效管理、转化价值最大化的基础。
结构化的知识图谱包含了大量的语义信息,是有效解决电力科技成果海量知识挖掘分析的重要技术手段之一。知识图谱的知识表示方法是整个知识图谱构建的基础性的重要技术,是贯穿知识图谱构建于应用的关键点。知识表示方法能够在低维语义空间中高效计算实体和关系的语义联系,可充分利用大规模知识图谱,提升相关领域的服务水平。
随着知识图谱表示方法的广泛应用,各种各样的知识表示方法也被提出,特别是多种模型方法,例如:距离模型可以利用学习到的知识表示,实现两实体之间关系的捕捉,但协同性差;张量神经模型可以大大增强不同实体之间的语义联系,但是需要大量的三元组样例学习,模型计算要求高,难以在大规模稀疏的知识图谱上实现;transe模型计算复杂度低,但在解决复杂关系问题上存在局限性;transh、transr模型通过调整模型,关注训练实体间的结构信息,可处理知识表示中的复杂关系。但是,对日益庞大、形式多样、跨多专业的电力科技成果知识图谱,仅仅关注实体间的关系而忽略具有丰富语义的实体描述文本,难以实现精准高效的知识表示。
同时,电力科技成果领域的数据具有复杂关系、庞大的数据等特点,传统的知识表示方法针对大规模电力科技成果数据,其方法实现需要计算大量数据、计算复杂度高,往往会忽略数据中的丰富信息。
因此,如何开发出一种对电力科技成果数据进行有效语义分析已经成为急需解决的技术问题。
技术实现要素:
本发明的目的是为了解决现有技术中电力科技成果数据量庞杂难以进行语义分析的缺陷,提供一种面向电力科技成果的知识图谱可视化方法来解决上述问题。
为了实现上述目的,本发明的技术方案如下:
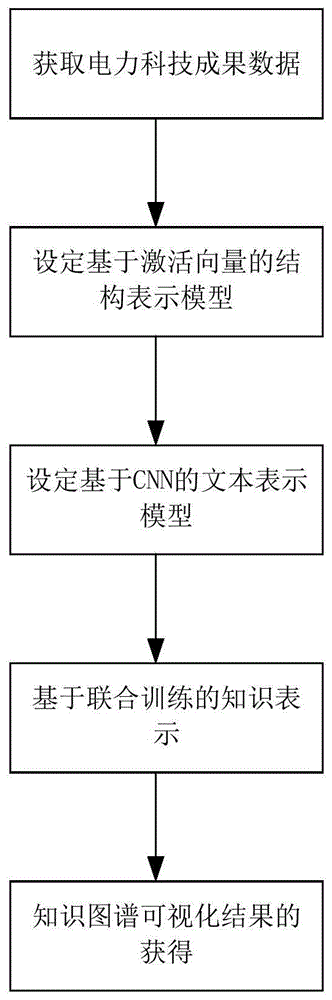
一种面向电力科技成果的知识图谱可视化方法,包括以下步骤:
获取电力科技成果数据:获取电力科技成果数据三元组(h,r,t);
设定基于激活向量的结构表示模型:利用基于激活向量的结构表示模型实现基于三元组结构信息的向量表示,并对其进行向量化处理,所述的向量化处理为对给定电力科技成果数据三元组(h,r,t)进行训练,向量化结果为(h,r,t),其中:
设定基于cnn的文本表示模型:预处理原始文本后,并将某个实体的全文信息作词向量化处理后作为输入,生成该实体基于文本的向量表示;
基于联合训练的知识表示:设定融合上述两种实体表示学习方法的损失函数,并融合两种实体表示方法至相同的连续向量空间中,并与激活向量在基于激活向量的结构表示模型进行联合训练,实现知识表示并得到正确的三元组;
知识图谱可视化结果的获得:使用图数据库neo4j保存融合实体表示和基于激活向量后正确的三元组,将需要可视化展示的数据取出,转成json格式,利用d3.js在网页端进行可视化展示,实现电力科技成果知识图谱的可视化。
所述设定基于激活向量的结构表示模型包括以下步骤:
设定激活向量
设定关系r下被激活向量激活的头实体、尾实体分别表示为:
其中:
设定基于激活向量的损失函数,其表达式如下:
对该结构模型进行训练时,设定约束条件如下:即对任意的向量h,r,t,其约束条件为:
‖h‖2≤1,‖t‖2≤1,‖r‖2≤1
‖hr‖2≤1,‖tr‖2≤1,‖rr‖2≤1。
所述设定基于cnn的文本表示模型包括以下步骤:
设定cnn的输入层与卷积层:
首先预处理原始文本后,将某个实体的全文信息作词向量化处理得到x(l),并作为cnn架构的卷积层输入,z(l)为输出结果;
设定x(1)为第l层卷积层的输入向量,表示单词的词向量,设定滑动窗口为k,经过滑动窗口的结果为
z(l)为第l层卷积层的输出,第i个输出向量
其中
设定最大池化层:使用最大池化策略保留文本中的强特征,选择每个窗口中特征值中的最大特征,构建一个新的特征向量
其中,
设定平均池化层:使用平均池化策略关注句子的局部特征,使用大小为m,互不重叠的窗口将卷积层的输出向量
其中
设定模型优化方法及目标函数:使用反向传播的随机梯度下降法,即从输出层到第二层平均池化层,再到第二层卷积层,再到第一层最大池化层,再到第一层卷积层,最后到词向量,参数从后向前依次调整;
设定训练的目标函数为:
其中[x]+=max(0,x)表示返回0和x之间较大的那个值;γ>0为间隔超参数,表示正确三元组损失函数值与错误三元组损失函数值之间的间隔距离,f(h,t,r)表示为正确三元组的损失函数,f(h′,t′,r′)为错误三元组的损失函数,s为正确三元组的集合,s-为错误三元组的集合,错误三元组是通过将正确三元组中的头实体、尾实体或者关系交替来构成。
所述基于联合训练的知识表示包括以下步骤:
设定融合文本信息和结构信息的评分函数:
将上述的实体表示与二值激活向量在基于激活向量的结构表示模型下进行联合训练,并将基于激活向量的结构表示模型的评分函数定义如下:
e=es+et
其中es是基于结构表示的评分函数fr(h,t),et是基于文本表示的评分函数。
et公式如下
et=ett+ets+est
其中:
评分函数et将两种实体表示学习方法融合在一起,将实体表示投影到相同的向量空间,使得两种表示学习相互影响,共同作用,最终得到融合文本信息和结构信息的知识表示;
在评分函数的规定阈值内,整理得出正确的三元组。
有益效果
本发明的一种面向电力科技成果的知识图谱可视化方法,与现有技术相比提出融合基于激活向量的结构知识表示方法和基于cnn的文本信息知识表示方法,可以有效地减少计算参数、模型运行高效,有效地获取文本结构、文本信息中的特征,使得表达结果更加准确。
本发明突破现有方法仅仅关注结构信息,忽略文本中的语义信息等缺陷,处理大规模知识图谱中的复杂关系,通过可视化准确、高效地表示了电力科技成果知识图谱的知识,对构建高质量高水平的电力科技成果知识图谱具有重要意义。
附图说明
图1为本发明的方法顺序图。
具体实施方式
为使对本发明的结构特征及所达成的功效有更进一步的了解与认识,用以较佳的实施例及附图配合详细的说明,说明如下:
如图1所示,本发明所述的一种面向电力科技成果的知识图谱可视化方法,包括以下步骤:
第一步,获取电力科技成果数据:获取电力科技成果数据三元组(h,r,t)。
第二步,设定基于激活向量的结构表示模型。利用基于激活向量的结构表示模型实现基于三元组结构信息的向量表示,并对其进行向量化处理,所述的向量化处理为对给定电力科技成果数据三元组(h,r,t)进行训练,向量化结果为(h,r,t),其中:
传统的基于结构的表示模型,对同一实体在不同关系下的各个维度均为同等对待,具体表现为在处理数据中一对多、多对一等复杂关系时性能不佳。本发明设定二值激活向量,使得该表示模型对同一实体在不同关系下得到不同的关注度,即只有部分维度会被具体的关系所影响,其他无关或关联程度较小的维度可被认定为噪声。激活向量的设定,保证同一实体在不同关系下具有不同的表达,提高模型的表达性能。
设定基于激活向量的结构表示模型的具体步骤如下:
(1)设定激活向量
(2)设定关系r下被激活向量激活的头实体、尾实体分别表示为:
其中:
(3)设定基于激活向量的损失函数,其表达式如下:
对该结构模型进行训练时,设定约束条件如下:即对任意的向量h,r,t,其约束条件为:
‖h‖2≤1,‖t‖2≤1,‖r‖2≤1
‖hr‖2≤1,‖tr‖2≤1,‖rr‖2≤1。
其中,hr,tr,rr分别表示为在关系r下被激活后的头实体、尾实体、关系的向量表示;l1、l2为l1范数、l2范数。
第三步,设定基于cnn的文本表示模型:预处理原始文本后,并将某个实体的全文信息作词向量化处理后作为输入,生成该实体基于文本的向量表示。
传统表示模型大多依据实体与关系之间的结构信息来学习实体和关系的表示,而往往忽略了实体的文本信息。本发明针对电力科技成果数据的多样性及丰富性,提出基于文本信息的表示模型,有助于更准确地学习知识表示。
设定基于cnn的文本表示模型具体步骤如下:
(1)设定cnn的输入层与卷积层:
首先预处理原始文本后,将某个实体的全文信息作词向量化处理得到x(l),并作为cnn架构的卷积层输入,z(l)为输出结果;
设定x(1)为第l层卷积层的输入向量,表示单词的词向量,设定滑动窗口为k,经过滑动窗口的结果为
z(l)为第l层卷积层的输出,第i个输出向量
其中
(2)设定最大池化层:使用最大池化策略保留文本中的强特征,选择每个窗口中特征值中的最大特征,构建一个新的特征向量
其中,
(3)设定平均池化层:使用平均池化策略关注句子的局部特征,使用大小为m,互不重叠的窗口将卷积层的输出向量
其中
(4)设定模型优化方法及目标函数:使用反向传播的随机梯度下降法,即从输出层到第二层平均池化层,再到第二层卷积层,再到第一层最大池化层,再到第一层卷积层,最后到词向量,参数从后向前依次调整;
设定训练的目标函数为:
其中[x]+=max(0,x)表示返回0和x之间较大的那个值;γ>0为间隔超参数,表示正确三元组损失函数值与错误三元组损失函数值之间的间隔距离,f(h,t,r)表示为正确三元组的损失函数,f(h′,t′,r′)为错误三元组的损失函数,s为正确三元组的集合,s-为错误三元组的集合,错误三元组是通过将正确三元组中的头实体、尾实体或者关系交替来构成。
第四步,基于联合训练的知识表示:设定融合上述两种实体表示学习方法的损失函数,并融合两种实体表示方法至相同的连续向量空间中,并与激活向量在基于激活向量的结构表示模型进行联合训练,实现知识表示并得到正确的三元组。其具体步骤如下:
(1)设定融合文本信息和结构信息的评分函数:
将上述的实体表示与二值激活向量在基于激活向量的结构表示模型下进行联合训练,并将基于激活向量的结构表示模型的评分函数定义如下:
e=es+et
其中es是基于结构表示的评分函数fr(h,t),et是基于文本表示的评分函数。
et公式如下
et=ett+ets+est
其中:
评分函数et将两种实体表示学习方法融合在一起,将实体表示投影到相同的向量空间,使得两种表示学习相互影响,共同作用,最终得到融合文本信息和结构信息的知识表示;
(2)在评分函数的规定阈值内,整理得出正确的三元组。
第五步,知识图谱可视化结果的获得:使用图数据库neo4j保存融合实体表示和基于激活向量后正确的三元组,将需要可视化展示的数据取出,转成json格式,利用d3.js在网页端进行可视化展示,实现电力科技成果知识图谱的可视化。
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是本发明的原理,在不脱离本发明精神和范围的前提下本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明的范围内。本发明要求的保护范围由所附的权利要求书及其等同物界定。
- 还没有人留言评论。精彩留言会获得点赞!