混合云环境下含隐私数据的Spark任务的调度方法与流程
本发明涉及一种混合云环境下含隐私数据的spark任务的调度方法,属于云计算资源调度技术领域。
背景技术:
混合云是私有云与公有云资源的组合,在私有云资源不足以满足当前所处理任务的约束时,可通过租赁公有云资源的方式扩充计算资源,更符合企业资源使用的实际情况。然而,混合云环境面临着安全和隐私问题。对于含隐私数据的任务,由于公有云环境并不提供可靠性保证,因此并不提倡将隐私数据直接放到公有云环境执行。因此,如何在混合云环境下实现隐私数据保护已成为工业界关注的重要问题。
目前在云计算环境下解决含隐私数据的任务处理主要有以下几种方式:1)任务只在私有云环境下处理。由于私有资源计算能力的局限性,该种方式往往不能保证任务执行时间,可能会违反应用的截止期约束。2)数据加密。在将数据交由云计算资源处理前,对数据进行加密操作。3)数据分割。将数据按隐私数据和非隐私数据分为两部分,隐私数据和相关操作仅在私有云上执行。这种方式可在充分利用私有云资源的前提下,通过租赁公有云资源以执行非隐私数据的相关操作,从而满足用户的资源请求和qos约束。
对于大数据处理平台方面,面对日益增长的数据量和快速处理的要求,spark处理平台具有良好的处理性能。spark基于mapreduce发展而来,提供了一个分布式计算平台,能够快速、高效、容错和可伸缩地处理大型、复杂和海量的数据。spark基于内存进行计算,其通过将所有需要处理的数据划分成rdd(弹性式分布数据集),完成用户提交的应用程序(application)。
在使用spark处理平台进行大数据计算时,由于spark本身调度方法的局限性,没有考虑含隐私数据的任务的调度方法。
技术实现要素:
发明目的:针对现有技术中存在的问题与不足,区别于spark中默认调度方法,本发明提供一种混合云环境下含隐私数据的spark任务的调度方法,本发明考虑用户提交数据的隐私性,在调度过程中通过考虑任务的隐私性,增加隐私数据聚集的操作,实现降低应用完工时间和降低资源租赁成本。有效调度混合云资源,最小化租赁成本,保证用户投资和用户数据的隐私。
技术方案:一种混合云环境下含隐私数据的spark任务的调度方法,首先,确定stage(任务)的子截止期;对任务打隐私标签;其次,采用stage排序策略,确定待调度任务序列;再次,采用数据聚集策略,对隐私数据进行聚集操作;最后,依次调度敏感任务集合和非敏感任务集合;调度敏感任务时,选择私有云资源调度方法;调度非敏感任务集合时,根据私有云资源的可用区间和当前任务的预计执行时间,优先选择在私有云中调度;如果私有云资源不足以满足任务子截止期,则采用公有云租赁策略,从公有云中租赁满足子截止期的资源。该方法包括以下步骤:
步骤1,确定任务的子截止期。根据用户提交的截止期约束和云环境中虚拟机资源的执行速度以及job、stage间的拓扑顺序,确定每个stage的子截止期。初始化私有云中资源的可用区间。初始化任务的最早开始时间,最晚开始时间,最早结束时间,最晚结束时间参数。
步骤2,判断未调度job队列是否为空;如果为空,则结束方法;否则转步骤3;
步骤3,通过对用户提交的应用进行排序选择,得到待调度task集合。
步骤4,调度待调度task集合中的task;
步骤5,等待待调度task序列中任务执行完;转步骤2。
在以上步骤中,所属私有云中服务资源,待处理job列表,待处理stage列表,待处理task列表和私有云中服务资源的可用区间表,具体为:
私有云中服务资源
待处理job列表用
待处理stage列表用
待处理task列表用
私有云中服务资源的可用区间表表示某私有云虚拟机可执行任务的时间段。
所述步骤1中,根据任务大小和资源情况,初始化任务参数:est,eft等。可设使用最快资源,计算上述参数。在确定各stage的子截止期时,首先根据任务在spark应用中的位置,确定其距离起始节点的距离,即为该任务所在的层次
所述步骤4具体包括:
步骤41,计算隐私数据聚集所需要的时间成本,判断其是否小于预估的该层的任务调度成本。若小于,转步骤42;否则转步骤43;
步骤42,进行数据聚集操作;并对该层任务隐私性进行重新标签;
步骤43,将任务按敏感任务和非敏感任务拆成两个队列
步骤44,判断
步骤45,取队首元素在私有云中分配资源;
步骤46,更新私有云中服务的可用区间;将该任务从队列移除;转步骤44;
步骤47,判断非敏感队列是否为空,如果为空,若未调度stage不为空,添加就绪stage到待调度stage列表中,重复调度任务;若未调度stage为空,再判断未处理job列表,添加就绪job;否则,转步骤48;
步骤48,在私有云中调度队首任务;
步骤49,判断该任务是否<=子截止期;若小于等于,在私有云上调度该任务;转步骤411;否则,转步骤410;
步骤410,在公有云中调度该任务,转步骤411。
步骤411,更新该任务所在stage的实际完工时间aft;若其所在stage中所有task完成调度,再更新后继stage的最早开始时间est;将已调度任务从所在队列删除。
有益效果:与现有技术相比,本发明提供的混合云环境下含隐私数据的spark任务的调度方法,通过实现合理的任务调度方法,优化了租赁成本,并保证了数据隐私性。
另外,本发明通过对spark任务的聚集和对私有云资源的检测,判断其是否能够满足资源调度的要求,如果不能,则租赁公有云中服务,权衡租赁成本和任务完工时间,租用最少的服务,使得租赁成本最小化,增加了灵活性和资源利用率。
附图说明
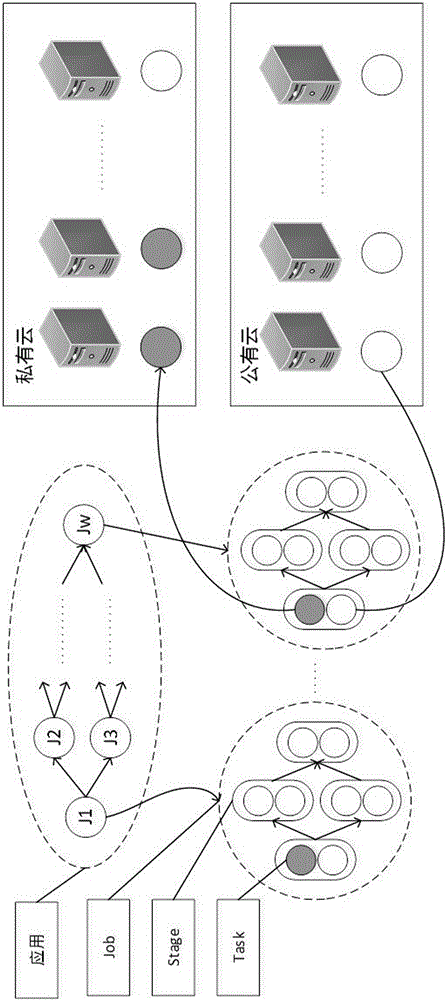
图1是本发明实施例中实现混合云环境下含隐私数据的spark任务的调度方法的结构图;
图2是本发明实施例中spark任务调度的流程图;
图3是本发明实施例中spark任务调度的具体步骤流程图,由于流出图较大,将其分成(a)和(b)两部分,其中(b)是(a)的延续。
具体实施方式
下面结合具体实施例,进一步阐明本发明,应理解这些实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
如图1所示,实现混合云环境下含隐私数据的spark任务的调度方法的结构,包括私有云,公有云和待调度的应用。本实施例中设私有云和公有云中的服务包含三种处理速度不同的虚拟机资源:高性能虚拟机,中性能虚拟机和低性能虚拟机。私有云中的资源用
混合云环境下含隐私数据的spark任务的调度方法,首先,指定子截止期划分策略,确定stage的子截止期;采取隐私性标签策略,对任务打隐私标签。其次,采用stage排序策略,确定一组合适的待调度任务序列。再次,采用数据聚集策略,对隐私数据进行聚集操作。数据聚集操作即根据stage中各任务隐私数据的分布情况,移动同一个stage中的不同分片中的隐私数据,目的是为了将隐私数据聚集到少数几个分片中。
最后,依次调度敏感任务集合和非敏感任务集合。调度敏感任务时,选择合适的私有云资源调度方法,确定调度方案;调度非敏感任务集合时,根据私有云资源的可用区间和当前任务的预计执行时间,优先选择在私有云中调度;如果私有云资源不足以满足任务子截止期,则采用公有云租赁策略,从公有云中租赁满足子截止期的资源。综合考虑租赁成本,根据截止期和数据隐私程度,设计有效的调度方案。
如图2-3所示,混合云环境下含隐私数据的spark任务的调度方法,具体步骤如下:
步骤s201,初始化任务的参数:最早开始时间est,最晚开始时间eft,最早结束时间est,最晚结束时间eft;计算stage的子截止期;
步骤s202,根据提交数据的隐私性,对任务打隐私标签;
步骤s203,初始化私有云资源的可用区间;
步骤s204,对用户提交的应用进行调度;
步骤s301,将用户提交的应用中的所有job加入未处理job列表;
步骤s302,判断未处理job列表中是否有job,如果没有job,方法结束;如果有,转步骤s303;
步骤s303,将未处理job列表中前驱job已完成或没有前驱job的加入待处理job列表,并将其从未处理job列表中删除;
步骤s304,判断待处理job列表是否为空,如果为空,则转步骤s302;如果不为空,转步骤s305;
步骤s305,将待处理job列表中包含的所有stage加入未调度stage列表;
步骤s306,判断未调度stage列表是否为空,如果为空,则转步骤s302;否则,转步骤s307;
步骤s307,将未调度列表中,前驱stage已完成或没有前驱stage的stage加入待调度stage列表,并将其从未调度stage列表删除;
步骤s308,判断待调度stage列表是否为空,如果为空,转步骤s306;否则转步骤s309;
步骤s309,将待调度stage列表中的所有task加入待调度task列表;
步骤s310,根据待调度task列表中任务中的数据隐私情况,计算如果进行数据聚集操作,进行隐私数据聚集的时间成本。对于同属一个stage的task,假设将其中分布在多个task中的隐私数据聚集到少数几个分片中,数据聚集的成本即数据移动时花费的时间:
步骤s311,将进行隐私数据聚集时的任务调度时间与不进行隐私数据聚集时的任务调度时间进行比较,进行隐私数据聚集时的任务调度时间包括对隐私数据聚集时间和聚集后进行调度的时间。如果进行隐私数据聚集时的任务调度时间小于不进行隐私数据聚集时的任务调度时间,转步骤s312;如果行隐私数据聚集时的任务调度时间大于等于不进行隐私数据聚集时的任务调度时间,转步骤s314;此步骤是在仅使用私有云资源且在不改变已调度任务的前提下,计算模拟进行隐私数据聚集的任务调度时间和计算模拟不进行隐私数据聚集时的任务调度时间。
步骤s312,进行隐私数据聚集;
步骤s313,对任务进行再标签,用于区分隐私数据和非隐私数据;
步骤s314,按照敏感型和非敏感型,将任务分成敏感任务队列
步骤s315,判断
步骤s316,取
步骤s317,更新私有云资源的可用区间列表;更新所在stage的实际完工时间aft;若所在stage中所有task完成调度,再更新后继stage的最早开始时间est参数;将该任务从
步骤s318,判断
步骤s319,取
步骤s320,判断此次分配是否满足该任务的子截止期约束;如果小于等于子截止期,在私有云上调度该任务,转步骤s322;如果大于,转步骤s321;
步骤s321,租赁公有云资源,分配该任务;
步骤s322,更新所在stage的实际完工时间aft;若其所在stage中所有task完成调度,再更新后继stage的最早开始时间est;将已调度任务从队列
- 还没有人留言评论。精彩留言会获得点赞!