一种基于深度学习与OCR技术相结合的污损遮挡号牌识别方法与流程
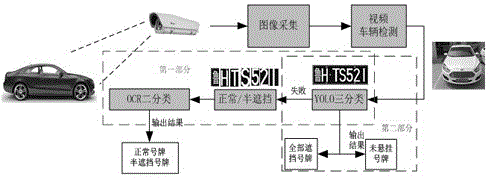
本发明属于道路交通安全技术领域,涉及一种污损遮挡号牌识别方法,具体涉及一种基于深度学习与ocr技术相结合的污损遮挡号牌识别方法。
背景技术:
进入21世纪以来,随着人们生活水平的提高以及国家对交通道路的大力建设,汽车已经成为人们日常生活中的必需用品。汽车数量急剧增加,引发城市道路拥堵、交通事故等一系列问题,给城市交通发展带来了巨大的压力。为了解决这些交通问题,各种人工智能算法应运而生,不仅能够实现对交通违法行为的识别,也方便了道路交通管理,提高了工作效率。
车牌识别系统是智能交通系统中的一个不可分割的重要组成部分,该系统能够综合利用目标检测、视频图像处理以及模式识别等技术,实现对号牌的定位和识别,最终完成对车牌信息的提取和分类。目前车牌识别系统已经在众多场合中得到了应用,比如,公安交警通常会在重要路口架设监控摄像头,对于违反交通规则的车辆以及涉及不法案件的肇事车辆,通过车牌识别系统进行违法判别。但遗憾的是,目前研究人员只能针对清晰车牌图像设计识别系统,而不能实现对遮挡或者污损的车牌图像进行分类和判别。而且现有方法应用于车牌分类有很大的局限性,例如对完全遮挡和未悬挂车牌这类具有干扰复杂的样本图片往往不能通过识别的手段来对结果进行分类。
针对国内日益不断增长的车辆,智能交通在车辆号牌信息提取方面的需求日益增长,然而传统分类方法流程复杂,并且对于复杂背景和不规范的场景识别准确率低。
现有技术的主要缺点表现在以下几个方面:
(1)ocr技术在车牌识别方面有很多的应用,但该技术受车牌号是否完整、是否污损、光照等条件影响较大。在未悬挂车牌和车牌号被全部遮挡的情况下,难以检测到车牌的位置,因此无法准确的识别车牌。
(2)号牌分为正常号牌、部分污损或遮挡号牌、未悬挂号牌和全部污损或遮挡号牌等四类。基于深度学习的方法可以准确的检测到车牌位置,但对于车牌字符的识别效果不佳。
基于以上缺陷,急需开发一种高效、准确实现污损遮挡号牌识别的方法。
技术实现要素:
为了弥补现有技术的不足,本发明提供了一种基于深度学习与ocr技术相结合的污损遮挡号牌识别方法,该方法针对ocr技术不能检测到全部污损或遮挡车牌和未悬挂车牌的缺陷,采用深度学习技术和ocr技术相结合的方法,充分结合了深度学习技术与传统ocr车牌识别技术的优点,能够提高对污损遮挡号牌识别的准确性。
本发明公开了一种基于深度学习与ocr技术相结合的污损遮挡号牌识别方法,此方法包括以下步骤:
(1)采用yolo网络结构进行车牌定位和识别:
(1.1)搜集各种场景下的车头图片,对所述图片中的车牌位置进行标注,得到标注数据,之后将所述标注数据划分为两部分,一部分为训练集和测试集,用于模型的训练过程中,所述训练集对模型不断训练,每训练一个阶段后,所述测试集验证效果,并再次进行训练,直到模型达到最优的拟合;另外一部分为验证级,用于模型训练完成后具体效果的测试,主要用于模型完成后;
(1.2)使用所述训练集对神经网络模型进行训练,并根据训练结果不断调整模型参数,直至得到最优模型;
(1.3)使用训练出的所述最优模型对车牌位置进行定位,并按照未悬挂车牌、全部污损或遮挡车牌、其他类车牌的分类方法输出车牌所属类别;
(2)采用ocr技术对所述其他类车牌的车牌号码进行识别:
(2.1)根据步骤(1)中获取的所述车牌位置,对车牌上的字符进行分割,得到分割字符;
(2.2)其次,根据分割字符是汉字、字母或数字的不同复杂度设置不同的阈值,识别车牌上的字符并输出每一位字符的置信度;
(2.3)再次,根据置信度不同识别车牌,得到车牌字符长度,并将所述车牌字符长度与正常号牌长度进行对比:如果相符即为正常号牌,如果不相符则为不符合长度的车牌;具体过程为:根据已经得到的各个阈值判断识别到的字符、数字和字母,首先利用阈值0.5判断长度,等于号牌长度的为正常号牌,进一步按照各个字符、数字和字母的不同阈值判断是否为半遮挡号牌和污损造成的号牌;
(2.4)最后,将筛选出的所述不符合长度的车牌,通过实验大量开源网站上的图片,首先选用的阈值大小为0.50,之后通过阈值调整筛选出污损车牌。
进一步的,步骤(2.2)中所述根据分割字符是汉字、字母或数字的不同复杂度设置不同的阈值是指,一是汉字较为复杂,在实验过程中采取放低阈值的方法,能提高识别的准确率;二是字母和数字较为简单,在实验过程中采取适当提高阈值的方法,有助于降低识别错误率。
进一步的,步骤(2.2)中所述根据分割字符是汉字、字母或数字的不同复杂度设置不同的阈值中汉字的阈值为0.870,字母或数字的阈值都为0.920。
进一步的,步骤(1)中所述yolo网络结构是指yolov3实验模型。
进一步的,步骤(1.3)中所述其他类车牌是指正常号牌和部分遮挡号牌。
进一步的,步骤(2.4)中所述阈值调整是指通过每次0.02的增幅调节阈值进行筛选。
本发明还公开了一种应用,即所述一种基于深度学习与ocr技术相结合的污损遮挡号牌识别方法应用于对污损遮挡号牌的识别。
本发明的有益效果在于:
①在传统算法上,各种各样复杂和多样的样本图片往往不能满足对车牌高像素的基本要求,为了弥补传统算法的缺点,本发明提供的一种基于深度学习与ocr技术相结合的污损遮挡号牌识别方法利用卷积神经网络来解决这一问题,卷积神经网络是一类包含卷积计算且具有深度结构的前馈神经网络,其隐含层内的卷积核参数共享和层间连接的稀疏性使得卷积神经网络能够以较小的计算量对格点化(grid-liketopology)特征进行学习,越是大量的复杂多样的样本,能够学习到的特征越显著,模型对车牌点定位、分类的效果越好,因此,本文提出卷积神经网络和传统算法相结合的思路来提高分类效果。
②本发明提供了一种结合传统ocr技术的污损车牌识别的分类算法,将污损遮挡违法号牌分为部分遮挡号牌、全部遮挡号牌和未悬挂车牌三类。首先通过目标检测算法yolo对车辆号牌区域进行定位,将号牌进行三分类,识别结果分为未悬挂号牌、全部遮挡号牌和正常与部分遮挡号牌三类;将未分类的车辆图片进一步通过采用ocr算法重新对图片上的车牌定位、二分类,利用对车辆号牌字符的识别,实现对正常号牌和半遮挡号牌的分类,从而实现对全部遮挡与未悬挂的分类,最终完成对污损遮挡号牌的分类。
③为了能提高对污损遮挡号牌识别的准确性,本发明提供了一种充分结合了深度学习技术与传统ocr车牌识别技术的优点的基于深度学习与ocr技术相结合的污损遮挡号牌识别方法。首先,利用深度学习的网络框架训练出可以定位车牌位置以及识别车牌类别的模型,主要能够识别未悬挂车牌、全部污损或遮挡车牌和正常车牌和部分污损或遮挡车牌;其次,使用ocr技术去识别正常号牌和部分遮挡号牌上的字符,对其进行二分类的训练,根据识别到的字符个数来准确的区分正常车牌和被部分污损或遮挡的车牌。
④本发明提供的一种基于深度学习与ocr技术相结合的污损遮挡号牌识别方法采用深度学习方法和ocr技术相结合的分析方法,实现对污损遮挡号牌的识别,与单纯使用ocr技术识别车牌号的方法相比,具有可以实现对非正常车牌的准确定位的优势,具有能够识别出未悬挂车牌和全部遮挡车牌的优势,结合两种方法后的算法识别准确度更高。
附图说明
图1是本发明的一种基于深度学习与ocr技术相结合的污损遮挡号牌识别方法的过程示意图;
图2是本发明实施例1中的部分遮挡号牌示意图;
图3是本发明实施例1中的正常号牌示意图;
图4是本发明实施例1中的一种基于深度学习与ocr技术相结合的污损遮挡号牌识别方法的第二步的流程示意图;
图5是本发明实施例1中的一种基于深度学习与ocr技术相结合的污损遮挡号牌识别方法的流程示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1
参考图1,一种基于深度学习与ocr技术相结合的污损遮挡号牌识别方法,包括以下步骤:
(1)采用yolo网络结构(所述yolo网络结构是指yolov3实验模型)进行车牌定位和识别:
(1.1)搜集各种场景下的车头图片,对所述图片中的车牌位置进行标注,得到标注数据,之后将所述标注数据划分为两部分,一部分为训练集和测试集,用于模型的训练过程中,所述训练集对模型不断训练,每训练一个阶段后,所述测试集验证效果,并再次进行训练,直到模型达到最优的拟合;另外一部分为验证级,用于模型训练完成后具体效果的测试,主要用于模型完成后;
(1.2)使用所述训练集对神经网络模型进行训练,并根据训练结果不断调整模型参数,直至得到最优模型;
(1.3)使用训练出的所述最优模型对车牌位置进行定位,并按照未悬挂车牌、全部污损或遮挡车牌、其他类车牌的分类方法输出车牌所属类别;
(2)采用ocr技术对所述其他类车牌(所述其他类车牌是指图3所示的正常号牌和图2所示的部分遮挡号牌)的车牌号码进行识别,具体流程参见图4:
(2.1)首先,根据步骤(1)中获取的所述车牌位置,对车牌上的字符进行分割,得到分割字符;
(2.2)其次,根据分割字符是汉字、字母或数字的不同复杂度设置不同的阈值,识别车牌上的字符并输出每一位字符的置信度;所述根据分割字符是汉字、字母或数字的不同复杂度设置不同的阈值是指,一是汉字较为复杂,设置阈值为0.870,在实验过程中采取放低阈值的方法,能提高识别的准确率;二是字母和数字较为简单,设置阈值为0.920,在实验过程中采取适当提高阈值的方法,有助于降低识别错误率;
(2.3)再次,根据置信度不同识别车牌,得到车牌字符长度,并将所述车牌字符长度与正常号牌长度进行对比:如果相符即为正常号牌,如果不相符则为不符合长度的车牌;具体过程为:根据已经得到的各个阈值判断识别到的字符、数字和字母,首先利用阈值0.5判断长度,等于号牌长度的为正常号牌,进一步按照各个字符、数字和字母的不同阈值判断是否为半遮挡号牌和污损造成的号牌;
(2.4)最后,将筛选出的所述不符合长度的车牌,通过实验大量开源网站上的图片,首先选用的阈值大小为0.50,之后通过阈值调整(阈值调整是指通过每次0.02的增幅调节阈值)筛选出污损车牌。
应当理解,以上所描述的具体实施例仅用于解释本发明,并不用于限定本发明。由本发明的精神所引伸出的显而易见的变化或变动仍处于本发明的保护范围之中。
- 还没有人留言评论。精彩留言会获得点赞!