用于在现实场景中叠加直播人物影像的方法和电子设备与流程
本发明涉及增强现实技术领域,尤其涉及一种用于在通过设备观察到的现实场景中叠加直播人物影像的方法和电子设备。
背景技术:
本部分的陈述仅仅是为了提供与本申请的技术方案有关的背景信息,以帮助理解,其对于本申请的技术方案而言并不一定构成现有技术。
在政务大厅、银行网点、展览馆、景区、商场、超市、机场、车站等场所,经常需要安排一些服务人员在一些特定地点为用户提供现场讲解或咨询服务,例如,在政务大厅为用户提供政策咨询服务,在银行网点为用户提供各种理财产品的介绍,在超市货架旁边为用户介绍各种商品,等等。
然而,以这种传统的服务方式,需要服务人员和用户之间面对面的近距离(通常1米左右甚至更近)口头交流,这在存在传染疫情时会极大地增加交叉感染的风险,并影响许多产业(特别是需要现场讲解人员或服务人员的产业)的顺利复工复产。尽管强制服务人员和用户佩戴口罩等防护设施可以降低该风险,但这相对而言会影响交流的顺畅度并需要花费额外的防护成本。另外,心理学研究表明,在面对面的对话交流过程中,信息的传递实际上是在语言和非语言两个层次上同时进行的,通常,通过非语言(例如,面部表情、长相、姿态、手势等)传达的信息占整个交流过程总信息量的比例超过50%,而其中面部表情和长相是非常重要的部分。而在佩戴口罩等防护设施的情况下,通过面部表情和长相等传达的信息大部分被阻隔而无法被传递,从而影响面对面交流的效果。
另外,以上述传统的服务方式,通常同一服务人员仅能负责一个地点的用户。以银行网点为例,即使在银行网点a的工作人员a当前空闲,在银行网点b的工作人员b很忙碌,工作人员a也不能服务当前正在银行网点b处等待的其他用户。因此,上述传统服务方式是低效并且成本高昂的。随着老龄化社会的快速到来以及人力成本的不断提高,上述传统服务方式的弊端也会越来越明显。
为了解决上述问题中的至少一个,本申请提供了一种用于在设备观察到的现实场景中叠加直播人物影像的方法和电子设备。
技术实现要素:
本发明的一个方面涉及一种用于在现实场景中叠加直播人物影像的方法,包括:确定设备在空间中的位置和姿态,其中,所述设备具有图像采集器件和显示媒介;获得为所述直播人物影像设置的空间位置;基于所述设备的位置和姿态以及所述直播人物影像的空间位置,确定所述直播人物影像在所述设备的显示媒介上的呈现位置;在所述设备的显示媒介上呈现所述设备的图像采集器件采集的现实场景;以及接收所述直播人物影像并在所述显示媒介上的所述呈现位置处叠加所述直播人物影像。
可选地,其中,所述设备接收的所述直播人物影像是背景透明的直播人物影像或者无背景的直播人物影像;或者,所述设备处理所接收的所述直播人物影像以生成背景透明的直播人物影像或者无背景的直播人物影像。
可选地,所述方法还包括:确定要为所述设备呈现的直播人物影像。
可选地,其中,通过所述设备在空间中的位置来确定要为所述设备呈现的直播人物影像。
可选地,其中,通过所述设备在空间中的位置和姿态来确定要为所述设备呈现的直播人物影像。
可选地,所述方法还包括:获得为所述直播人物影像设置的在空间中的姿态。
可选地,所述方法还包括:基于所述设备的位置和姿态以及所述直播人物影像的姿态,确定所述直播人物影像在所述设备的显示媒介上的呈现姿态。
可选地,其中,使得所述直播人物影像的正面始终朝向所述设备。
可选地,所述方法还包括:采集所述设备的用户的影像、声音或文字输入;以及将所述影像、声音或文字输入发送给提供所述直播人物影像的直播者。
可选地,所述方法还包括:在所述设备的显示媒介上叠加所述直播人物影像之后,根据所述设备的新的位置和姿态以及所述直播人物影像的空间位置,确定所述直播人物影像在所述设备的显示媒介上的新的呈现位置。
可选地,所述方法还包括:在所述设备的显示媒介上叠加所述直播人物影像之后,所述直播人物影像在所述显示媒介上的呈现位置保持不变。
可选地,所述方法还包括:在所述设备的显示媒介上叠加所述直播人物影像之后,根据所述设备的用户的指示使得所述直播人物影像在所述显示媒介上的呈现位置保持不变。
可选地,其中,所述确定设备在空间中的位置和姿态包括:通过所述设备扫描部署在现实场景中的光通信装置来确定所述设备在空间中的初始位置和姿态,并持续跟踪所述设备在空间中的位置和姿态变化。
可选地,所述方法还包括:所述设备获得所述光通信装置的标识信息,并通过所述标识信息确定要为所述设备呈现的直播人物影像。
可选地,其中,在所述设备的显示媒介上叠加至少两个直播人物影像。
可选地,其中,所述直播人物影像是二维人物影像或者三维人物影像。
可选地,所述方法还包括:在接收所述直播人物影像之前,指示与所述直播人物影像关联的直播者提供所述直播人物影像。
本发明的另一个方面涉及一种存储介质,其中存储有计算机程序,在所述计算机程序被处理器执行时,能够用于实现上述的方法。
本发明的再一个方面涉及一种电子设备,其包括处理器和存储器,所述存储器中存储有计算机程序,在所述计算机程序被处理器执行时,能够用于实现上述的方法。
通过本发明的方案,实现了一种基于现实场景中的位置或者与现实场景中的位置绑定的直播交互方法,使得设备用户能够体验到类似于真人现场服务的非接触式场景服务,而并不需要服务人员和用户进行面对面的近距离口头交流,从而在存在传染疫情时可以极大地降低交叉感染的风险,并帮助相关产业顺利复工复产。另外,通过该方案,同一服务人员可以为不同位置的用户服务,从而可以打破地理局限性、节省人力成本、提高服务效率。
附图说明
以下参照附图对本发明的实施例作进一步说明,其中:
图1示出了根据一个实施例的用于在通过设备观察到的现实场景中叠加直播人物影像的方法;
图2示出了用户在现实场景中观看直播人物影像的示意图;
图3示出了用于提供图2所示的现实场景中的直播人物影像的直播者和摄像设备;
图4示出了在用户的设备的显示媒介上呈现的示意图像;
图5是用于示出本发明的实际效果的一个示例真实图像;
图6示出了一种示例性的光标签;
图7示出了一种示例性的光标签网络。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图通过具体实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限制本发明。
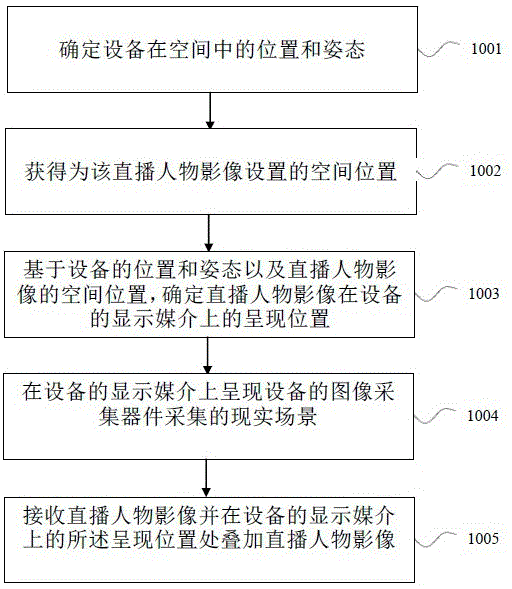
图1示出了根据一个实施例的用于在通过设备观察到的现实场景中叠加直播人物影像的方法。设备例如可以是用户携带或控制的设备(例如,手机、平板电脑、智能眼镜、ar/vr眼镜、ar/vr头盔、智能手表等等),并且具有图像采集器件(例如摄像头)和显示媒介(例如屏幕)。该方法可以包括如下步骤:
步骤1001:确定设备在空间中的位置和姿态。
可以使用各种可行的方式来确定设备在空间中的位置和姿态,例如,可以在空间中布置视觉标志并通过分析设备采集到的视觉标志的图像来确定设备的位置和姿态;可以建立现实场景的三维模型或者点云数据,并通过分析设备采集到的场景图像来确定设备的位置和姿态;可以使用高精度陀螺仪等来确定设备的位置和姿态;可以在空间中布置可以发射无线电信号的信标,并通过分析设备接收到的无线电信号来确定设备的位置和姿态;可以使用卫星定位信号来确定设备的位置并使用陀螺仪等来确定设备的姿态;以及上述各种方式的结合;等等。
步骤1002:获得为该直播人物影像设置的空间位置。
例如,可以由政务大厅、银行网点、展览馆、景区、商场、超市、机场、车站等的服务人员(在本文中可以被称为“直播者”)来实时地提供直播人物影像,该直播人物影像用于向设备用户提供内容讲解、答复设备用户的咨询、等等。通过使用直播人物影像,使得服务人员可以远程地且实时地向用户讲解,并能回答用户的咨询等,而并不需要与用户进行近距离的面对面交流,也不需要将服务人员局限于某个固定地点。
可以例如由直播人物影像上的一个点的空间位置、多个点(例如,直播人物影像的轮廓上的多个点)的空间位置、或者整个直播人物影像区域的空间位置来表示或者定义直播人物影像的空间位置(也即,直播人物影像在空间中的呈现位置)。例如,如果直播人物影像是一个具有矩形形状的影像,可以例如使用矩形影像的中心点在空间中的位置坐标来定义矩形影像的空间位置,可以例如使用矩形影像的某个角(例如,左上角、左下角、右上角、右下角)在空间中的位置坐标来定义矩形影像的空间位置,可以例如使用矩形影像的两个对角(例如,左上角与右下角,或者左下角与右上角)在空间中的位置坐标来定义矩形影像的空间位置,等等。
在获得为直播人物影像设置的空间位置之前,可以使用各种方式确定要为设备呈现的直播人物影像。在一个实施例中,可以通过设备在空间中的位置以及可选的姿态来确定可以为设备呈现的直播人物影像。例如,设备可以扫描安装于展览馆中的某个视觉标志以确定设备在展览馆中的位置以及可选的姿态,通过设备在展览馆中的位置以及可选的姿态,可以进行查询以确定当前可以为设备呈现的直播人物影像(例如,用于某个展品的介绍的直播人物影像)。
在一个实施例中,可以通过其他信息来确定要为设备呈现的直播人物影像,例如,可以通过设备获得的视觉标志的标识信息来进行查询以确定当前可以为设备呈现的直播人物影像。
在一个实施例中,可能获得多个可以为设备呈现的直播人物影像,并且可以由设备用户从中选择以确定当前要呈现的直播人物影像。例如,对于当前在政务大厅中的设备用户,可以提示用户目前有涉及多种业务的多个直播人物影像可供呈现,用户可以根据需要(例如,根据其想要办理的业务)选择其感兴趣的直播人物影像。
在一个实施例中,可以基于与设备或者设备用户相关的信息(例如,用户的年龄、性别、职业等信息)筛选直播人物影像,从而可以根据设备用户的偏好向其呈现其可能喜欢的直播人物影像。
在一个实施例中,在确定要为设备用户呈现的直播人物影像之后或者在接收该直播人物影像之前,可以例如通过设备将相应的指示或者消息发送给用于提供该直播人物影像的直播者,以使得直播者可以开启直播并向设备发送直播人物影像。
在一个实施例中,一个直播者可以与多个直播人物影像相关联,例如,一个直播者可以负责与展厅中的多个展品对应的多个直播人物影像。在这种情况下,发送给直播者的指示或者消息中可以标识出相应的直播人物影像(例如,在发送给直播者的指示或者消息中包含相应直播人物影像的标识信息),以使得直播者知悉,例如,使得直播者知悉当前应该为哪个展品提供相应的直播人物影像。
在一个实施例中,一个直播人物影像可以与多个直播者相关联,多个直播者中的任何一个空闲的直播者可以提供该直播人物影像。在一个实施例中,可以由设备用户来选择其喜欢的直播者,或者可以由最早对设备用户的请求作出应答的直播者来提供该直播人物影像。
在一个实施例中,还可以获得为要呈现的直播人物影像设置的在空间中的姿态,其例如可以用于定义直播人物影像在空间中的朝向等。
步骤1003:基于设备的位置和姿态以及直播人物影像的空间位置,确定直播人物影像在设备的显示媒介上的呈现位置。
在确定了设备在空间中的位置和姿态之后,实际上可以确定设备的图像采集器件的当前视野范围。进一步地,基于直播人物影像的空间位置可以确定该直播人物影像是否位于设备的图像采集器件的当前视野范围内,以及位于该视野范围内的什么位置,从而可以确定直播人物影像在设备的显示媒介上的呈现位置。
在一个实施例中,在直播人物影像具有空间中的姿态的情况下,可以进一步基于设备的位置和姿态以及直播人物影像的姿态来确定在设备的显示媒介上呈现的直播人物影像的姿态。
在一个实施例中,可以使得直播人物影像的某个方向始终面向观察该直播人物影像的用户的设备。例如,对于二维直播人物影像,可以使得直播人物影像的正面始终朝向用户的设备,如此,即使设备用户处于不同的位置或者改变位置,也能感觉到直播人物影像中的人物始终在面向自己进行讲解。
步骤1004:在设备的显示媒介上呈现设备的图像采集器件采集的现实场景。
设备可以通过其图像采集器件实时地采集现实场景,并将现实场景的图像呈现到设备的显示媒介上。
步骤1005:接收直播人物影像并在设备的显示媒介上的所述呈现位置处叠加直播人物影像。
通过这种方式,实际上可以将直播人物影像叠加到通过设备观察到的现实场景中的合适位置,从而可以向设备用户提供与现实场景紧密结合的直播人物影像,以例如向设备用户进行讲解、答复咨询等。
在一个实施例中,设备接收的直播人物影像可以是背景透明的直播人物影像(例如,带alpha透明通道的直播人物影像)或者是无背景的直播人物影像。例如,可以在采集直播人物影像之后或者在传输直播人物影像的过程中处理该直播人物影像以产生背景透明的直播人物影像,并将其发送给设备。在一个实施例中,设备可以接收包含不透明背景的直播人物影像并处理该直播人物影像以生成背景透明的直播人物影像或者无背景的直播人物影像。为了便于产生背景透明的直播人物影像或者无背景的直播人物影像,可以在拍摄直播人物影像时为人物布置单色背景,例如绿布。通过这种方式,可以使得叠加于现实场景中的直播人物影像看起来只有人物,而不具备拍摄人物时的原始背景。如此,当用户通过设备的显示媒介观察直播人物影像时,仅会观察到人物,而不会观察到人物的原始背景,就好像人物真实地位于现实场景中一样,从而可以实现更好的用户体验。
在一个实施例中,为了实现设备用户与直播者之间的更好的交流,可以通过设备采集设备用户的影像、声音、或者文字输入中的至少一项,并将其发送给直播者,以使得双方可以实时交互。
图2示出了用户在现实场景中观看直播人物影像的示意图。在该现实场景中包括货架202,用户201持有设备203并通过设备203的显示媒介观看布置于或者嵌入于该现实场景中的直播人物影像,该直播人物影像在现实场景中的部署位置例如由虚线框204所示。可以由虚线框204上的一个或多个点的空间位置来定义整个虚线框204在空间中的位置。虚线框204可以具有预设的或者默认的姿态,例如默认虚线框204与地面垂直。
图3示出了用于提供图2所示的现实场景中的直播人物影像的直播者302,以及用于采集直播者302的影像以生成直播人物影像的摄像设备301。
图4示出了在用户201的设备203的显示媒介上呈现的示意图像,其中,通过设备203的图像采集器件获得了现实场景的图像(其中包括货架202),并将其呈现在设备203的显示媒介上。另外,设备203还接收到由直播者302的摄像设备301提供的直播人物影像,并根据设备203的位置和姿态以及为该直播人物影像设置的空间位置,在设备203的显示媒介上的相应呈现位置处叠加背景透明的包含直播者302的直播人物影像,从而实现了直播者302与现实场景的完美融合。
图5是用于示出本发明的实际效果的一个示例真实图像。该真实图像所示出的现实场景中包括货架,当用户使用手机观察该现实场景时,可以在用户手机屏幕所呈现的现实场景中叠加背景透明的包含讲解员的直播人物影像。如此,用户感觉到就好像有一个真实的讲解员在货架前给其介绍各种商品一样。
在一个实施例中,在直播人物影像中可以包括两个或者两个以上的人物,并且该两个或者两个以上的人物可以进行语言或肢体互动,以向用户提供更详细的讲解。
在一个实施例中,可以为现实场景布置至少两个直播人物影像,并且可以在设备的显示媒介上叠加至少两个直播人物影像。至少两个直播人物影像可以同时呈现或者依次呈现在设备的显示媒介上。
在一个实施例中,直播人物影像可以是二维人物影像。在一个实施例中,直播人物影像可以是三维人物影像。例如,在拍摄人物影像时,可以使用位于人物周围的多个摄像设备从多个不同角度拍摄,从而提供三维人物影像。
在一个实施例中,还可以设置或者调整直播人物影像的尺寸,例如调整以使得其中的人物具有与真人类似的大小。
在一个实施例中,在设备的显示媒介上叠加直播人物影像之后,可以跟踪设备的位置和姿态变化,并根据设备的新的位置和姿态以及直播人物影像的空间位置,实时地确定直播人物影像在设备的显示媒介上的新的呈现位置。类似地,也可以根据设备的新的位置和姿态以及为直播人物影像设置的在空间中的姿态,实时地确定直播人物影像在设备的显示媒介上的新的呈现姿态。这种方式可以实现很好的增强现实效果,使设备用户感觉到直播者好像真实地位于现实场景中。
在一个实施例中,在设备的显示媒介上叠加了直播人物影像之后,可以使得直播人物影像在显示媒介上具有固定的呈现位置和/或呈现姿态。
在一个实施例中,当在设备的显示媒介上叠加了直播人物影像之后,可以根据设备用户的指示使得直播人物影像在显示媒介上具有固定的呈现位置和/或呈现姿态。如此,即使设备用户移动(例如,离开当前位置)时,也可以通过设备的显示媒介以期望的呈现位置和/或呈现姿态观看直播人物影像。例如,当在设备的显示媒介上叠加了直播人物影像之后,设备用户可以改变设备在空间中的位置和/或姿态,从而使得叠加在设备显示媒介上的直播人物影像具有设备用户期望的呈现位置和/或呈现姿态,此时,设备用户可以发送指示(例如通过点击在设备显示媒介上呈现的按钮)来使得直播人物影像的当前呈现位置和/或呈现姿态在此后保持不变,即使设备在空间中改变位置或姿态。
在一个实施例中,可以通过布置在空间中的光通信装置来确定设备在空间中的位置和姿态。光通信装置也称为光标签,这两个术语在本文中可以互换使用。光标签能够通过不同的发光方式来传递信息,其具有识别距离远、可见光条件要求宽松的优势,并且光标签所传递的信息可以随时间变化,从而可以提供大的信息容量和灵活的配置能力。
光标签中通常可以包括控制器和至少一个光源,该控制器可以通过不同的驱动模式来驱动光源,以向外传递不同的信息。图6示出了一种示例性的光标签100,其包括三个光源(分别是第一光源101、第二光源102、第三光源103)。光标签100还包括控制器(在图6中未示出),其用于根据要传递的信息为每个光源选择相应的驱动模式。例如,在不同的驱动模式下,控制器可以使用不同的驱动信号来控制光源的发光方式,从而使得当使用具有成像功能的设备拍摄光标签100时,其中的光源的成像可以呈现出不同的外观(例如,不同的颜色、图案、亮度、等等)。通过分析光标签100中的光源的成像,可以解析出各个光源此刻的驱动模式,从而解析出光标签100此刻传递的信息。可以理解,图6所示的光标签仅仅用作示例,光标签可以具有与图6所示的示例不同的形状,并且可以具有与图6所示的示例不同数量和/或不同形状的光源。
为了基于光标签向用户提供相应的服务,每个光标签可以被分配一个标识信息(id),该标识信息用于由光标签的制造者、管理者或使用者等唯一地识别或标识光标签。通常,可由光标签中的控制器驱动光源以向外传递该标识信息,而用户可以使用设备对光标签进行图像采集来获得该光标签传递的标识信息,从而可以基于该标识信息来访问相应的服务,例如,访问与标识信息相关联的网页、获取与标识信息相关联的其他信息(例如,与该标识信息对应的光标签的位置信息)等等。设备可以通过图像采集器件对光标签进行图像采集来获得包含光标签的图像,并通过分析图像中的光标签(或光标签中的各个光源)的成像以识别出光标签传递的信息。
可以将与每个光标签相关的信息存储于服务器中。在现实中,还可以将大量的光标签构建成一个光标签网络。图7示出了一种示例性的光标签网络,该光标签网络包括多个光标签和至少一个服务器。可以在服务器上保存每个光标签的标识信息(id)或其他信息,例如与该光标签相关的服务信息、与该光标签相关的描述信息或属性,如光标签的位置信息、型号信息、物理尺寸信息、物理形状信息、姿态或朝向信息等。光标签也可以具有统一的或默认的物理尺寸信息和物理形状信息等。设备可以使用识别出的光标签的标识信息来从服务器查询获得与该光标签有关的其他信息。光标签的位置信息可以是指该光标签在物理世界中的实际位置,其可以通过地理坐标信息来指示。服务器可以是在计算装置上运行的软件程序、一台计算装置或者由多台计算装置构成的集群。光标签可以是离线的,也即,光标签不需要与服务器进行通信。当然,可以理解,能够与服务器进行通信的在线光标签也是可行的。
在一个实施例中,设备可以通过采集包括光标签的图像并分析该图像(例如,分析图像中的光标签的成像的大小、透视变形等)来确定其相对于光标签的位置,该相对位置可以包括设备相对于光标签的距离和方向。在一个实施例中,设备还可以通过采集包括光标签的图像并分析该图像来确定其相对于光标签的姿态。例如,当光标签的成像位置或成像区域位于设备成像视野的中心时,可以认为设备当前正对着光标签。
在一些实施例中,设备可以通过扫描光标签来识别光标签传递的标识信息,并可以通过该标识信息来获得(例如通过查询)光标签在现实场景坐标系中的位置和姿态信息。现实场景坐标系例如可以是某个场所坐标系(例如,针对某个房间、建筑物、园区等建立的坐标系)或者世界坐标系中。如此,基于光标签在现实场景坐标系中的位置和姿态信息以及设备相对于光标签的位置或姿态信息,可以确定设备在现实场景坐标系中的位置或姿态信息。因此,所确定的设备在空间中的位置或姿态可以是设备相对于光标签的位置或姿态,但也可以是设备在现实场景坐标系中的位置或姿态。
在一个实施例中,设备可以通过扫描光标签来识别光标签传递的标识信息,并通过该标识信息确定该光标签所在现实场景的场景信息,该场景信息例如可以是现实场景的三维模型信息、现实场景的点云信息、光标签周围的辅助标志的信息以及其他信息等。之后,基于所确定的场景信息以及设备所采集的现实场景的图像可以通过视觉定位来确定设备在现实场景中的位置和/或姿态。
在通过扫描光标签确定设备在空间中的位置和/或姿态之后,设备可能会发生平移和/或旋转,在这种情况下,可以例如使用设备内置的各种传感器(例如,加速度传感器、磁力传感器、方向传感器、重力传感器、陀螺仪、摄像头等)通过本领域已知的方法(例如,惯性导航、视觉里程计、slam、vslam、sfm等)来测量或跟踪其位置变化和/或姿态变化,从而确定设备的实时位置和/或姿态。在一个实施例中,设备可以在光标签处于其摄像头视野中时重新扫描光标签以校正或者重新确定其位置或姿态信息。
在一个实施例中,设备可以获得光标签的标识信息,之后,设备可以通过该标识信息来查询确定要呈现的直播人物影像,并获得为该直播人物影像设置的空间位置。例如,设备可以扫描安装于超市某个货架的光标签并识别该光标签的标识信息,通过该光标签的标识信息,可以查询确定当前要为设备呈现的直播人物影像是用于介绍该货架上的商品的直播人物影像,并可以获得该直播人物影像的空间位置。
在本申请的一些实施例中以服务人员作为直播者进行了描述,但可以理解,本申请并不局限于此,直播者可以是希望向其他人提供直播人物影像的任何人,例如,演讲者、讲解者、视频会议参与者、教师、使用各种直播app的直播者、等等。
在本发明的一个实施例中,可以以计算机程序的形式来实现本发明。计算机程序可以存储于各种存储介质(例如,硬盘、光盘、闪存等)中,当该计算机程序被处理器执行时,能够用于实现本发明的方法。
在本发明的另一个实施例中,可以以电子设备的形式来实现本发明。该电子设备包括处理器和存储器,在存储器中存储有计算机程序,当该计算机程序被处理器执行时,能够用于实现本发明的方法。
本文中针对“各个实施例”、“一些实施例”、“一个实施例”、或“实施例”等的参考指代的是结合所述实施例所描述的特定特征、结构、或性质包括在至少一个实施例中。因此,短语“在各个实施例中”、“在一些实施例中”、“在一个实施例中”、或“在实施例中”等在整个本文中各处的出现并非必须指代相同的实施例。此外,特定特征、结构、或性质可以在一个或多个实施例中以任何合适方式组合。因此,结合一个实施例中所示出或描述的特定特征、结构或性质可以整体地或部分地与一个或多个其他实施例的特征、结构、或性质无限制地组合,只要该组合不是不符合逻辑的或不能工作。本文中出现的类似于“根据a”、“基于a”、“通过a”或“使用a”的表述意指非排他性的,也即,“根据a”可以涵盖“仅仅根据a”,也可以涵盖“根据a和b”,除非特别声明其含义为“仅仅根据a”。在本申请中为了清楚说明,以一定的顺序描述了一些示意性的操作步骤,但本领域技术人员可以理解,这些操作步骤中的每一个并非是必不可少的,其中的一些步骤可以被省略或者被其他步骤替代。这些操作步骤也并非必须以所示的方式依次执行,相反,这些操作步骤中的一些可以根据实际需要以不同的顺序执行,或者并行执行,只要新的执行方式不是不符合逻辑的或不能工作。
由此描述了本发明的至少一个实施例的几个方面,可以理解,对本领域技术人员来说容易地进行各种改变、修改和改进。这种改变、修改和改进意于在本发明的精神和范围内。虽然本发明已经通过优选实施例进行了描述,然而本发明并非局限于这里所描述的实施例,在不脱离本发明范围的情况下还包括所作出的各种改变以及变化。
- 还没有人留言评论。精彩留言会获得点赞!