基于多自注意力机制深度学习的医疗行为识别方法与流程
本发明涉及视频内容理解技术,尤其涉及面向行为分析的基于多自注意力机制深度学习的医疗行为识别方法。
背景技术:
随着21世纪信息时代的到来,各种各样的视频信息充斥着我们的生活。动作识别是计算机视觉中的一个重要问题,在视觉监控、人机交互、智慧、智能机器人、无人驾驶等领域有着广泛的应用。一方面,利用人工智能、模式识别等技术,来观察分析医护人员是否佩戴完备的医疗防护用具,从而判断或提醒医护人员的卫生规范性。另一方面,可以检测进入医院的人员或病人是否按照规定佩戴口罩等防护用具,提示医疗的安全性。
在合理的患者知情同意告知前提下,可以通过对患者全方位视频进行智能分析人体行为动作识别,从而可以研究该患者个体的生活习惯、饮食特征、运动模式从而更科学更细致把握了解病人的身体状况,为科学的行为干预提供依据。
人体动作识别,目的在于通过对摄像头拍摄的视频的智能理解,从而对人体的动作进行分类识别研究。其研究对象往往是视频信息,而不再局限于单帧的图像分析。因此,一套完整有效的动作识别系统依赖于对视频序列中的时间、空间特征进行有效的特征提取与分类。
这是一项非常具有挑战性的工作,主要存在以下几方面的难题:(1)相同的动作,个体之间存在明显的差异。针对同一类动作,由于具体场景的不同,不同的个体可能会有不同的表现。即使是相同个体,在做同一类动作时也可能会有不同的表现。具体表现为行为动作的运动轨迹、运动速度以及运动幅度存在较大差异。(2)动态视频中往往存在许多干扰信息,比如动作相同但环境背景不同,以及个体与背景环境之间发生的相对运动、视频序列中的光照强度的变化,视频拍摄过程中镜头的抖动等等。这些难点均使得视频序列中的动作识别研究具有极大的挑战性。
技术实现要素:
为了克服上述问题,本发明提供了一种基于多自注意力机制深度学习的医疗行为识别方法,包括以下步骤:
步骤1、读取视频,将视频分解为若干个单帧图像,然后将l个单帧图像进行堆叠,得到一个图像序列结构,同时为每个序列结构确定对应的动作分类标签;
步骤2、设计卷积神经网络,将序列中的单帧图像抽取出来作为视频单元,输入到该卷积神经网络中,通过多层计算得到视频单元的空间特征,维度为m;然后将一个序列中的l个视频单元特征进行堆叠,得到l×m的特征结构;
步骤3、设计循环神经网络结构,将步骤2中得到的l×m的特征结构作为单元,输入到该循环神经网络中捕捉时间维度上的特征,通过计算得到l×d维向量输出;
步骤4、设计多头自注意力模型,将步骤3中的得到的l×d维特征结构作为单元,输入到多头自注意力模型中,通过一系列计算得到l×d维的特征结构;然后通过平均池化和两层全连接层,最终得到n维向量输出。
步骤5、结合最终的n维向量输出和输入样本对应的标签,构建损失函数,通过最小化损失函数,训练卷积神经网络、循环神经网络和多头自注意力模型;
步骤6、得到效果最好的网络模型后,通过迁移学习将n分类模型学到的知识迁移到二分类模型上重新训练二分类模型。
步骤7、训练好最终的结合迁移学习的二分类模型后,用于医疗行为动作识别。
进一步的,所述步骤1中序列结构的获取方法如下:
在原始视频数据中每x帧读取一次图像,作为一个视频单元;将l个视频单元在时间维度上进行堆叠,得到许多能完整呈现一个动作的大小为l×c×h×w的序列结构,其中c代表图像的通道数,h代表图像的高度,w代表图像的宽度,l代表时间轴上的长度,也就是视频单元的个数;同时,为每个序列结构确定对应的动作分类标签。
进一步的,所述步骤2设计的卷积神经网络结构为:
卷积神经网络的整体结构由resnet和最后的数层全连接层构成;其中经过预训练resnet用于提取图像的空间特征信息,通过152层卷积操作,得到多个特征图;再经过两层全连接层,每层之后使用batchnorm方法,以及relu激活函数进行非线性变换,并使用dropout方法,得到初步的特征向量;再经过一层维度为m的全连接层,得到m维的特征向量;然后将l个视频单元特征进行堆叠,得到l×m的特征结构。
进一步的,所述步骤3所设计的循环神经网络结构为:
循环网络的基本单元为lstm,单元节点数为l,隐藏状态的维度为d;取所有的l个隐藏单元的状态作为输出,得到维度为l×d的特征结构f。
进一步的,所述步骤4所设计的多头自注意力模型结构为:
设定注意力头的个数为h;对于每一个注意力头,设计三个权重矩阵wq,wk,wv,维度均为d×d,其中
上式中,q、k、v为步骤4中得到的特征向量,d为特征向量的第二个维度大小,ai代表第i个注意力头,维度为l×d,t为转置符号,softmax为多元逻辑回归函数。
进一步的,将以上所有的注意力头在第二个维度上拼接起来,得到维度为l×d的多头注意力矩阵a;再计算最终的特征矩阵f′,公式如下:
f′=wa+f
上式中,w为维度为d×d的权重矩阵,a为步骤4中得到的多头注意力矩阵,f为步骤3中得到的特征结构,f′为得到的维度为l×d的特征矩阵。
进一步的,将特征矩阵f′作为单元,经过平均池化得到d维的特征向量;再经过一层全连接层,并使用batchnorm方法,以及线性整流函数relu进行非线性变换,得到初步的特征向量;再经过一层维度为n的全连接层,并借助softmax函数得到最终的n维向量,对应为对输入样本n分类的相应归属概率:
上式中,zi代表softmax前的输出值,p(zi)代表输入样本属于第i类动作的概率。
进一步的,所述步骤5构建损失函数的具体过程为:
选择平均交叉熵作为损失函数,即:
上式中,s代表一个batch的样本总量,p(xi)代表第i个样本预测类别为真实动作类别的概率。
进一步的,所述步骤6迁移学习的具体过程为:
变更最后一层维度为n的全连接层的结构,重新训练这个二分类模型,挑选出分类结果最好的网络模型作为最终的二分类模型。
本发明所具有的有益效果包括:
(1)本发明所述方法只需提取少量的视频信息,加快了运算速度;
(2)采用了卷积神经网络和循环神经网络同时提取视频的空间和时间特征;
(3)本发明采用的自注意力机制可以更充分的关注视频序列中的关键信息;
(4)本发明设计的多头注意力模型可以提取非局部的时间特征,将整个序列的信息充分的融合。
总之,本发明以视频中人体动作的识别为主,针对原始视频数据,使用深度学习中的卷积神经网络和循环神经网络模型分别提取视频序列的空间、时间特征,并结合多头注意力模型提取非局部的时间特征,将整个序列的信息充分的融合,最终通过分类器得到动作类别。
附图说明
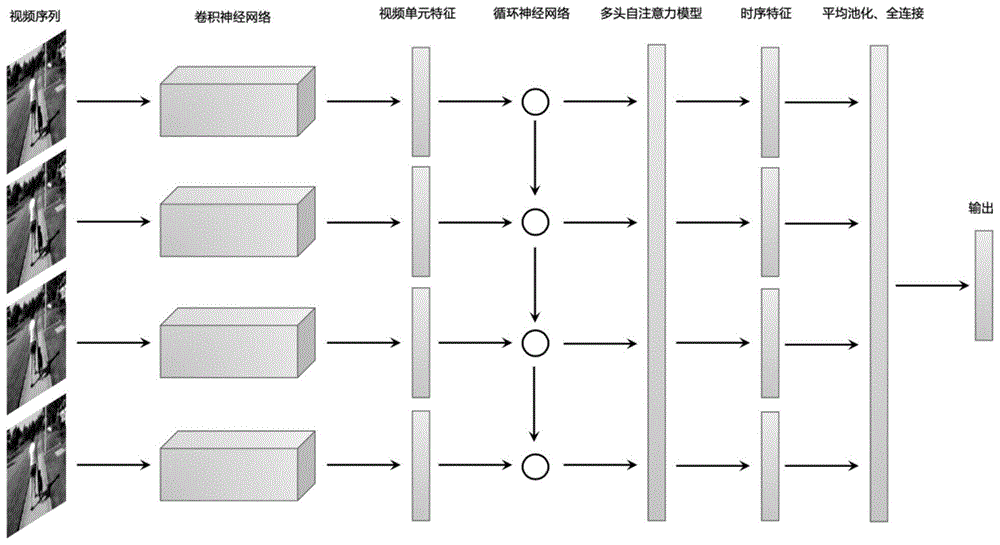
图1为本发明所述方法的流程示意图;
图2为卷积神经网络模型结构示意图;
图3为循环神经网络模型和多头自注意力模型结构示意图;
图4为实验例得到的map%-epoch曲线。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述,显然,所描述的实施例仅为本发明的一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域的普通技术人员在不付出创造性劳动的前提下所获得的所有其他实施例,都属于本发明的保护范围。
本发明主要关注视频分析中的动作识别任务,即给定一段人体动作视频,识别出当前视频中的人体动作类别。
如图1所示,本发明基于多自注意力机制深度学习的医疗行为识别方法具体实现如下步骤:
步骤1、读取视频数据。
根据本发明一种优选的实施方式,对视频每6帧读取一次,作为一个视频单元,将4个视频单元堆叠在一起,组成一个视频序列。
视频序列的维度为4×c×h×w,其中c代表图像的通道数,h代表图像的高度,w代表图像的宽度,4为时间轴上的长度,也就是视频单元的个数。
由于本视频的输入图像为rgb图像,所以图像通道数为3。
根据本发明一种优选的实施方式,将图像宽度和高度均resize改变大小到224。
于是,视频序列的维度变为4×3×224×224。
同时,为每个视频序列确定动作分类标签,标签编码为0到n-1。
步骤2、利用卷积神经网络结构提取视频序列的空间特征,网络结构如图2所示。
根据本发明一种优选的实施方式,步骤2包括以下子步骤:
步骤2-1、将视频序列中每一个视频单元抽取出来,维度为3×224×224。
步骤2-2、将视频单元输入预训练好的resnet中,得到512维的特征向量。
步骤2-3、经过两层维度均为1024的全连接层。
步骤2-4、在每层全连接层之后使用batchnorm方法,具体公式如下:
上式中,z代表batchnorm操作前的输出值,μ为一个batch中所有z的均值,σ2为batch中z的方差,ε为一个极小值,避免分母为零;γ和β为可学习的参数,默认值分别被设为1、0。
步骤2-5、在batchnorm操作之后使用线性整流函数(relu)作为激活函数进行非线性变换,relu函数如下:
f(z)=max(0,z)
上式中,z代表relu操作前的输出值。
步骤2-6、在每层全连接层之后使用dropout方法。
步骤2-7、经过最后一层全连接层,得到1024维的特征向量,作为视频单元的特征。
步骤2-8、将视频序列中4个视频单元的特征堆叠在一起,得到4×1024的特征向量,作为视频序列的特征。
步骤3、利用循环神经网络提取视频序列的时间特征。
使用lstm作为基本的循环神经网络单元,单元节点数l=4,隐藏状态的维度d=2048;取所有的4个隐藏单元的状态作为输出,得到维度为4×2048的特征结构f。
步骤4、利用多头自注意力模型、平均池化层和两层全连接层,得到最终的n维输出向量,模型结构如图3所示。
根据本发明一种优选的实施方式,步骤4包括以下子步骤:
步骤4-1、设定注意力头的个数h=8;对于每一个注意力头,设计三个权重矩阵wq,wk,wv,维度均为2048×d,其中
步骤4-2、将步骤3中得到的4×2048的特征结构f分别与上述三个权重矩阵相乘,得到三个特征向量分别为q、k、v,维度均为4×256;然后计算注意力头,公式如下:
上式中,q、k、v为步骤4中得到的特征向量,d为特征向量的第二个维度大小,ai代表第i个注意力头,维度为4×256,t为转置符号,softmax为多元逻辑回归函数,用于求得归一化的概率。
步骤4-3、将以上所有的8个注意力头在第二个维度上拼接起来,得到维度为4×2048的多头注意力矩阵a;再计算最终的特征矩阵f′,公式如下:
f′=wa+f
上式中,w为维度为2048×2048的权重矩阵,a为步骤4中得到的多头注意力矩阵,f为步骤3中得到的特征结构,f′为得到的维度为4×2048的特征矩阵。
步骤4-4、将特征矩阵f′作为单元,对一个维度上做平均池化,得到2048维的特征向量。
步骤4-5、再经过一层全连接层,并使用batchnorm方法,以及relu激活函数进行非线性变换,得到初步的特征向量;
步骤4-6、最后经过一层维度为n的全连接层,并借助softmax函数得到最终的n维向量,对应为对输入样本n分类的相应归属概率:
上式中,n代表一个batch的样本总量,zi为全连接层的输出,p(zi)代表第i个样本预测类别为真实动作类别的概率。
步骤5、训练卷积神经网络、循环神经网络和多头自注意力模型。
根据本发明一种优选的实施方式,步骤5包括以下子步骤:
步骤5-1、将数据分成若干个batch,每一个batch包含32个数据。
步骤5-2、将每一个batch中的所有数据传入卷积神经网络、循环神经网络和多头自注意力模型,得到输出。
步骤5-3、选择平均交叉熵作为损失函数计算损失,即:
上式中,s代表一个batch的样本总量,p(xi)代表第i个样本预测类别为真实动作类别的概率。
步骤5-4、反向传播计算梯度,再采用adam优化方法对模型中的参数进行更新。
步骤5-5、每完成一次训练迭代,将模型在测试集上测试一次。
步骤5-6、测试时,通过max函数得到概率最大的动作类别作为预测,并计算总的准确率。
步骤5-7、当测试准确率大于最好的准确率时,我们保存当前模型;否则,执行学习率衰减。
步骤6、迁移学习训练二分类模型。
根据本发明一种优选的实施方式,步骤6包括以下子步骤:
步骤6-1、将最后一层全连接层的维度改为2。
步骤6-2、保存模型参数用于迁移学习。
步骤6-3、在医疗行为数据集上重新进行训练。
步骤7、训练好最终的结合迁移学习的二分类模型后,用于医疗行为动作识别。
(1)本发明所述方法只需提取少量的视频信息,加快了运算速度;
(2)本发明采用的多注意力模型可以提取非局部的时间特征,将整个序列的信息充分的融合。
(3)循环卷积网络和多注意力模型相互补充,训练速度更快并且准确率显著提升。
(4)采用迁移学习,只需要少量的训练即可得到高准确度的模型。
实验例1
在实验中,本发明将youtubeaction数据集随机分割为训练集和测试集,比例为8:2。首先在训练集上对模型进行训练:为防止过拟合,设置dropout系数为0.5;选择adam作为优化函数,学习率为1e-4,其中,当模型准确率低于最高准确率时,学习率衰减为一半。
实验效果评估
在测试集上对模型进行测试,得到预测的动作标签后与真实动作数据进行对比,其中,使用map%-epoch作为评价指标,评价指标分析方法说明:
map%-epoch曲线:纵轴map%为多物体类别平均准确率,横轴epoch为训练时模型迭代次数。
采用本发明实施例所述的方法以及cnn_transformer和cnn_rnn方法分别对youtubeaction数据集进行训练和预测,验证其效果,结果如图4所示。
如图4可以看出,(1)本发明的训练速度最快,在3个epoch时,准确率已经达到了92%,对比75%(cnn_transformer)和54%(cnn_rnn)分别提高了17%和38%。(2)本发明的准确率最高,在8个epoch之后准确率稳定在95%,模型最高准确率可以达到97%,对比81%(cnn_transformer)和60%(cnn_rnn)分别提高了16%和37%。
因此,本发明所述方法,不仅可以提升训练速度,还可以显著的提高准确率,模型的效果得到了验证。
以上结合了优选的实施方式对本发明进行了说明,不过这些实施方式仅是范例性的,仅起到说明性的作用。在此基础上,可以对本发明进行多种替换和改进,这些均落入本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!