一种基于Flink的医学图像实时检索方法与流程
本发明涉及一种检索方法,具体是一种基于flink的医学图像实时检索方法,属于计算机视觉处理技术领域。
背景技术:
医学图像检索技术是图像检索技术在医学图像领域的应用,其经历了三次变化,分别为基于文本、内容和语义的医学图像检索。其中,效率较高且应用最为广泛的是基于内容的医学图像检索技术(content-basedimageretrieval,cbir),是通过在现有数据库中检索视觉上相似的图像,从而根据检索到的图像来探索其高级描述和解释。
目前的医学图像检索工作大多数基于离线数据库进行编码,没有考虑到在实际应用过程中多用户场景下的实时计算部分。在这种情况下,如果只通过批量构建现有数据库中的图像特征编码,用户则只能检索到截止批量构建前的图像数据,不能检索到同时在线的其他用户新上传的图像,而在实时计算过程中高并发的医学图像上传,为服务器集群和实时响应带来了极大的难度。因此,如何克服上述困难,提供一种能够检索到其他用户实时上传的图像的方法,成为目前亟需解决的技术问题。
技术实现要素:
针对上述现有技术存在的问题,本发明提供一种基于flink的医学图像实时检索方法,能够在多用户场景下实时提取用户上传的图像,实现实时在线检索医学图像。
本发明一种基于flink的医学图像实时检索方法,包括并行运行的步骤s1和步骤s2;
s1图像上传部分:基于flink进行图像实时上传特征编码及批量导入图像特征编码,包括以下两种场景:
s1.1针对多用户实时在线场景,利用flink流处理模型结合改进部分语义加权聚合模型对上传图像进行深度特征提取,并对其进行图像特征编码,再将该特征编码进行聚类存储至hbase中的图像特征编码距离查找表中;
s1.2针对图像批量导入场景,利用flink分布式模型结合改进部分语义加权聚合模型对批量导入的图像进行深度特征提取,并对其进行图像特征编码,再将该特征编码进行聚类存储至hbase中的图像特征编码距离查找表中;
s2图像检索部分:上传待检索图像后,通过改进部分语义加权聚合模型对该图像进行深度特征提取,并对其进行图像特征编码;然后,开启flink批处理任务,根据步骤s1中图像特征编码距离查找表,计算待检索图像的图像特征向量与图像特征编码距离查找表中的各图像的图像特征向量聚类中心的非对称距离,并对盖非对称距离最近的图像特征聚类,返回距离最靠前的m张图像作为最相似的图像查询结果,完成检索。
与现有技术相比,本发明通过基于改进部分语义加权聚合深度特征提取模型对医学图像进行深度特征提取,保证了提取特征对原图像关键信息的保留,基于hbase的医学图像及特征编码存储,提高了平台的可扩展性和数据存储效率;通过基于flink的实时计算和批量计算,提供了面向多用户、多场景的医学图像检索服务,提高了图像编码检索效率。本发明不仅适用于医学图像的检索,同时也适用于其他图像的检索。
附图说明
图1为发明中的系统架构图;
图2为发明的总体步骤示意图;
图3为基于flink的医学图像实时上传编码和批量导入编码过程示意图;
图4为将图像特征编码进行聚类存储至hbase中的图像特征编码距离查找表的过程示意图;
图5为基于flink的医学图像并行检索过程示意图;
图6为改进部分语义加权聚合医学图像深度特征提取过程实施例示意图。
具体实施方式
下面结合附图对本发明作进一步说明。
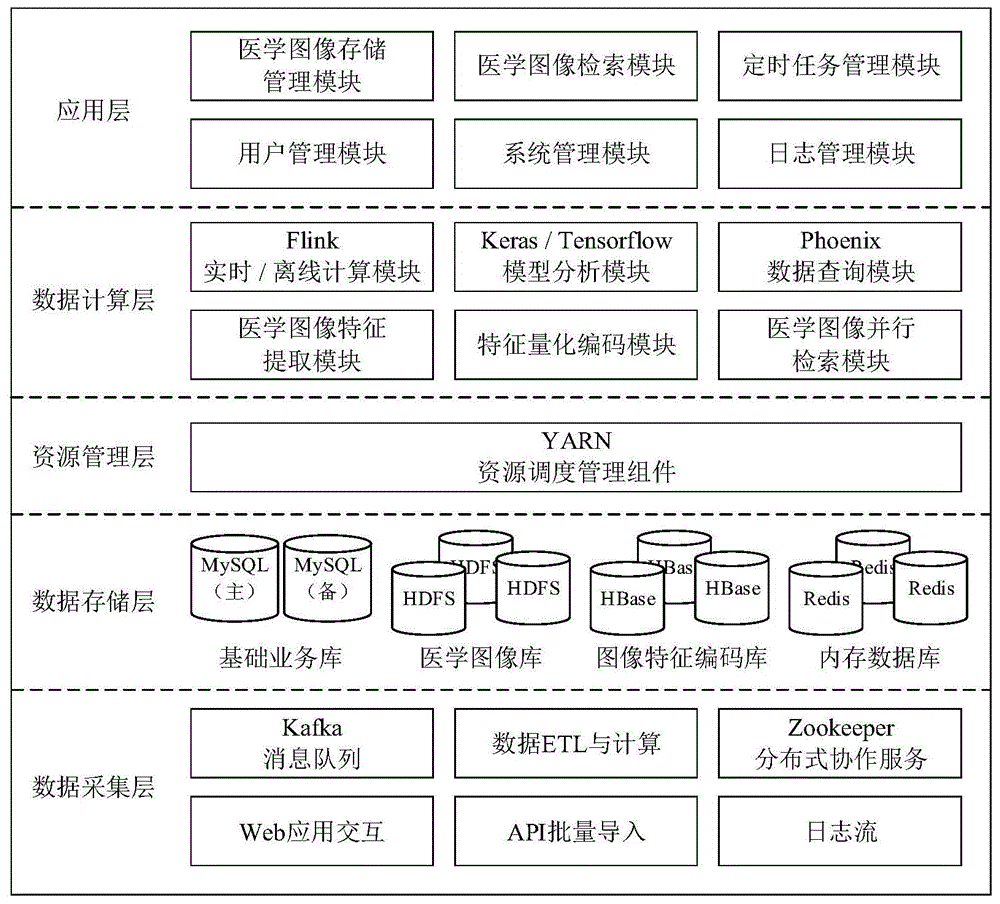
如图1所示,本发明一种基于flink的医学图像实时检索系统,其总体架构主要包括5部分:
(1)数据采集层
数据采集层的数据源包括用户通过web界面上传医学图像、通过api批量导入的医学图像和系统操作日志流。
对于实时产生的数据,首先传送至kafka消息队列进行缓冲中作为后续计算,通过zookeeper分布式协作服务对kafka服务器消费生产速度进行同步。此外,还可以通过数据抽取、转换、装载(extract,transformandload,etl)导入数据作为系统的数据源。
(2)数据存储层
数据存储层根据数据类型和应用场景包括基础业务库、医学图像库、图像特征编码库和内存数据库;
基础业务库通过mysql存放系统的结构化信息,如:人员列表、组织架构、图像基础信息等;医学图像库通过hadoop平台的hbase进行存储,图像id对应mysql中的图像基础信息表的记录,同时,该图像id的特征索引存储在hbase数据库中。图像特征编码库用于存放图像特征编码。此外,服务器将经常访问的热区数据如hbase中的图像特征编码距离查找表等缓存在内存数据库redis中,从而提高访问速度和计算效率。
(3)资源管理层
资源管理层包括yarn资源调度管理组件,系统通过由yarn资源调度管理组件进行资源管理,负责在有数据计算请求时根据集群状况分配计算资源和计算节点,从而提供mapreduce、spark、flink等组件的计算环境。
(4)数据计算层
数据计算层包括医学图像特征提取模块、特征量化编码模块、医学图像并行检索模块、flink实时计算/离线计算模块、keras/tensorflow模型分析模块、phoenix数据查询模块;系统首先基于keras/tensorflow模型分析模块构建深度特征提取模型,对于用户输入的医学图像通过flink进行特征提取,根据图像上传形式通过flink实时计算/离线计算模块,将该上传图像分为flink实时计算和离线批量计算两种;通过医学图像特征提取模块对上传的图像进行图像特征提取,然后对上传的图像通过特征量化编码模块进行特征量化编码,该编码存储在hbase中,便于检索,并由phoenix数据查询模块在hbase中进行数据的查询计算;在用户需要检索时,通过医学图像并行检索模块比对特征相似度计算返回检索结果。
(5)应用层
应用层包括用户管理模块、系统管理模块、日志管理模块、医学图像存储管理模块、医学图像检索模块和定时任务管理模块;系统通过web的形式提供用户管理模块、系统管理模块、日志管理模块、医学图像存储管理模块、医学图像检索模块和定时任务管理模块的用户交互界面,实现对用户管理、系统管理、日志管理、医学图像存储管理、医学图像检索操作、定时任务管理。
如图2所示,本发明一种应用上述系统的实时检索方法,包括并行运行的步骤s1和s2;
s1图像上传部分:基于flink进行医学图像实时上传特征编码及批量导入图像特征编码,如图3所示,包括以下两种场景:
s1.1针对多用户实时在线场景,利用flink流处理模型结合改进部分语义加权聚合模型对上传的医学图像进行深度特征提取,并对其进行图像特征编码,再将该特征编码进行聚类存储至hbase中的图像特征编码距离查找表中;
利用flink流处理模型进行医学图像实时特征编码的具体步骤如下:
1)基于kafka构建消息订阅发布模式的医学图像实时处理消息队列;
2)web服务器端响应用户的医学图像上传请求,并进行消息生产操作;
3)通过flink对接kafka消息队列,对消息进行实时消费,执行记录图像信息的存储和记录。
其中,web服务器端响应用户的图像上传请求,并进行消息生产操作,包括如下步骤:
1)web服务响应用户的上传请求,并判断表单信息完整性和规范性,然后将图像基本信息以及图像字节码提交到kafka;
2)创建kafka的生产者,由kafka生产者将图像上传消息类进行序列化,包括图像的信息及图像字节码;
3)通过kafkaproducer类将消息发送到kafkabroker接受的名为“imageupload”的topic中;
4)利用生产者的回调函数监测是否发送成功,异常则触发报警。
所述通过flink对接kafka消息队列,对消息进行实时消费,执行记录图像信息的存储和记录,包括如下步骤:
1)配置flink流式处理环境:设置flink定期执行checkpoint将数据持久化到内存中、设置检查点模式为exactly-once、设置若执行checkpoint时间超过60s,则丢弃该检查点,从而保证数据容错性;通过flink框架的kafkaflinkconnectorapi实现kafka的消费者进行实时流式处理,配置kafka的相关信息,包括:zookeeper集群、kafkabroker集群以及kafka消息者组;
2)配置kafka消息数据格式:配置kafka消息的<key,value>格式,使用其对应自定义数据结构类的反序列化形式作为flink的数据格式schema,从而便于其在网络上进行传输和解析;
3)执行map过程处理:添加配置kafka消息的数据源作为flink流式环境的source,执行datastream流的map过程对每一条消息进行处理,执行记录图像信息(描述、类型、日期、上传人等)到业务库,并将提取的图像特征、存储图像字节码和图像特征编码存储到hbase的图像存储表中,根据图像字节码使用改进部分语义加权聚合模型对图像进行深度特征提取,并对该图像特征进行编码,形成图像特征编码,所述图像特征存储至图像编码特征集,图像字节码存储至图像字节码表,图像特征编码聚类情况存储至图像特征编码距离查找表中;
4)更新图像特征编码距离查找表:计算新增图像特征编码与现有数据库中的图像特征编码的非对称距离,并将其归到距离最近的聚类中心所属类中,更新图像特征编码距离查找表。若图像特征编码距离查找表为空,即在首张图像上传时,建立图像特征编码距离查找表,则新增图像特征编码自成一类;
s1.2针对图像批量导入场景,利用flink分布式模型对批量导入的图像进行批量图像特征编码,再将该特征编码进行聚类存储至hbase中的图像特征编码距离查找表中;
利用flink分布式模型进行批量图像特征编码的具体步骤如下:
1)用户通过web填写外部数据库的连接信息,包括:数据库地址、数据库用户名及密码、数据表和相关字段的对应关系;
2)系统将外部数据库的数据导入到业务库临时表中,同时通过flink-jdbc对该外部数据库进行连接,将mysql数据表的相关字段查询作为flink的datasource;
3)开启flink读取mysql的批处理任务,通过map算子对每条记录分别处理,执行记录图像信息到业务库,并将提取的图像特征、存储图像字节码和图像特征编码存储到hbase的图像存储表中。根据图像字节码使用改进部分语义加权聚合模型对图像进行深度特征提取,并对该图像特征进行编码,形成图像特征编码,所述图像特征存储至图像编码特征集,图像字节码存储至图像字节码表,图像特征编码聚类情况存储至图像特征编码距离查找表中;
4)计算每个新增图像特征编码与现有数据库中的图像特征编码的非对称距离,并将其归到距离最近的聚类中心所属类中,更新图像特征编码距离查找表。
如图4所示,通过以下步骤将图像特征编码进行聚类存储至hbase中的图像特征编码距离查找表:
s2.1在mysql业务库中创建上传图像信息,并在业务库中将该图像id关联到hbase中的图像存储记录;
s2.2在hbase中创建hbase医学图像存储表,包括3个列族,分别为:用于存放图像特征编码聚类非对称距离的图像特征编码距离查找表、用于存储图像字节码的图像字节码表、用于存放图像特征编码的图像特征编码集;
其中,步骤s1.1在首张图像上传时,建立图像特征编码距离查找表,并将上传图像的特征编码存储至图像特征编码距离查找表中;步骤s1.2在首次批量导入时,建立图像特征编码距离查找表,并将该批量上传图像的图像特征编码存储至图像特征编码距离查找表中;
s2.3通过对hbase表进行表预分区设计和rowkey设计,设计共9个分区,指定每个分区的rowkey范围('0000|','0001|',……,'000n|'),根据该图像id作为rowkey将图像字节码和图像信息存放到相应的预分区中;
s2图像检索部分:基于flink并行检索,返回近似结果查询,如图5所示:上传待检索图像后,通过改进部分语义加权聚合模型对该图像进行深度特征提取,并对其进行图像特征编码;然后,开启flink批处理任务,根据步骤s1中图像特征编码距离查找表计算待检索图像的图像特征向量与图像特征编码距离查找表中的各图像的图像特征向量聚类中心的非对称距离,并返回特征编码集中距离最靠前的20张医学图像作为最相似的图像查询结果,完成检索。
简单讲,在实际使用本发明的方法进行检索时,用户将待检索的医学图像上传至系统中,系统根据该医学图像的图像字节码提取图像特征,并进行图像特征编码,根据图像特征编码比对图像特征编码距离查找表,找到特征编码集中近似的图像特征编码,再找到这些编码对应的图像字节码返回显示出来,即可完成检索。
所述改进部分语义加权聚合模型对医学图像进行深度特征提取,如图6所示,具体步骤如下:
1)通过vgg-16模型提取医学图像深度特征,获取网络pool-5层的特征输出,具体如下:
对于输入待检索的图像i,首先传递到预训练的深度网络vgg-16模型提取深度卷积层特征f(提取pool-5层特征,由c个通道特征图组成,每个特征图高度为h、宽度为w),该图像通过n个筛选出来的卷积层通道特征加权聚合表示,即为n*c维的矢量表示,n>0,c>0;
2)通过计算每个特征点的局部异常因子lof,比较每个特征点与其邻域特征点的密度,检测并排除通道特征中的异常特征点;对各通道方差进行排序,筛选出方差最大的前n个判别式卷积层通道特征,具体如下:
卷积层通道特征的选择基于医学图像特征数据集进行训练,通过计算特征图通道方差筛选具有更大差异的显著特征。因此,对于数据库中d个特征,通过计算每个通道特征的方差,即c维向量gi(i=1,2,...,d)的c通道方差v={v1,v2,...,vc,...,vc},其中
通过pwa算法对c通道的方差{v1,v2,...,vc}进行排序,筛选出方差最大的前n个判别式卷积层通道,即认为方差越大的通道具有更显著的语义表示。然而这种直接按方差排序的筛选方式忽略了图像背景的干扰,很容易将包含较大差异性的背景通道筛选出来。因此,本方法对筛选卷积层通道环节进行优化,在计算每个通道方差之前采用局部异常因子算法(localoutlierfactor,lof)进行离群点检测,并将异常的离群点剔除,从而防止其对筛选结果的干扰,其中,检测离群点的方法如下:
定义k距离:对于每个特征图单个通道中的一个特征点p,将其他特征点与该特征点p的距离进行从小到大排序,设第k个为特征点p的k距离:
k_dis(p);
定义第k距离邻域nk(p):到特征点p的距离小于等于k距离的特征点,即特征点p的第k距离及以内的所有特征点,包括第k距离。
定义可达距离:特征点o到特征点p的第k可达距离定义为:
reach_dis(o,p)=max{k_dis(o),dis(o,p)}
即若o到特征点p的实际距离小于o的第k距离,则特征点o到特征点p的第k可达距离为特征点o的第k距离,反之为特征点o到特征点p的实际距离dis(o,p)。
定义特征点p的局部可达密度表示如下式,即邻域内特征点到特征点p可达距离平均值的倒数:
其中,|nk(p)|表示特征点p的第k距离邻域点的个数,即特征点p的第k距离即以内的所有点,包括第k距离;
通过以上定义计算特征点p的局部离群因子(lof):领域内点的局部可达密度的均值除以特征点p的局部可达密度,其计算公式为:
其中,lrd(p)表示特征点p的局部可达密度,
本方法设置k为20,计算所得lof的大小代表该特征点为离群点的可信度,即因子越大,该点越可能是离群点,若lof值越接近1,则特征点p与其邻域点密度越相近,和邻域同属一簇的可能性较大;若lof值小于1,则特征点p的密度相比邻域特征点密度更高,即特征点p为密集点;若lof值大于1,则特征点p的密度小于其邻域特征点的密度,则特征点p是异常点,对该异常点进行排除。
经过lof离群点检测后排除异常特征点,再对c通道的方差{v1,v2,...,vc}进行排序,筛选出方差最大的前n个判别式卷积层通道特征,从而防止其对筛选结果的干扰。
3)通过无监督策略生成概率权值方案,利用权值方案对筛选出的判别式卷积层通道特征进行加权表示,构造深度卷积特征的加权和集,得到特征全局向量表示。
4)通过后处理对全局向量表示依次执行l2-归一化、主成分分析压缩和白化,并获得最终的图像特征表示。
传统的图像检索只能在现有数据库中存储的图像进行检索,且现有的数据库无法实现实时更新,只能通过工作人员定期批量的将医学图像导入至数据库中,对数据库进行更新,而本发明实现了对医学图像进行实时上传的功能,用户在进行医学图像实时检索时,可以检索到其他用户实时上传的医学图像,提高了医学图像检索的效率。
- 还没有人留言评论。精彩留言会获得点赞!