基于多任务骨架姿态划分部件的行人重识别方法与流程
本发明涉及计算机视觉技术领域,具体涉及一种基于多任务骨架姿态划分部件的行人重识别方法。
背景技术:
行人重识别是指从不同摄像机捕获的行人图像中识别这个行人的身份,旨在弥补目前固定的摄像头的视觉局限,并与行人检测/行人跟踪技术相结合,可广泛应用于智能视频监控、智能安防等领域。给定包含目标行人(查询)的图像,行人重识别(re-identification,reid)技术尝试从大量行人图像(图库)中搜索包括相同行人的图像,广泛被认为是一个图像检索的子问题;reid因其重要的理论价值和广阔的应用前景,受到了学术界和工业界的极大关注。
近年来reid技术发展的很快,但是由于摄像机视角、高度、行人姿态、复杂背景、分辨率等的显著变化,使得reid仍然是一项非常具有挑战性的任务。与人脸识别任务相比较,reid的场景更加复杂,有一些困难的问题没有解决,尤其是当行人着装等外观特征很相似时的识别更是一件困难的任务,且已有的细节特征提取多是基于均匀分块的方法,精细度不够。
技术实现要素:
本发明的目的是针对现有行人重识别技术的不足,提供一种基于多任务骨架姿态划分部件的行人重识别方法,具体包括如下步骤:
步骤(1)数据预处理。
对样本图像进行归一化处理,以512×512大小的输入图像为例,如果样本图像大于该尺寸,则进行随机裁剪得到,如果样本图像大小比该尺寸小,则进行等比例放大后再进行裁剪。
步骤(2)设计网络模型进行特征提取。
基于多任务骨架姿态划分的行人重识别模型包含两个分支:行人特征提取分支和骨架关键点检测分支。
其中行人特征提取分支为主网络,采用了改进的inceptionresnetv2作为骨干网,将原来inceptionresnetv2最后一个下采样层暂时丢弃掉,得到空间张量特征集合(tensort),从而可得到行人的全局特征。
其中骨架关键点检测分支采用vgg网络结构,网络末端通过1*1卷积输出一个置信图,置信图的层数与人体关节点的个数相同,每一层表示一个关节点的热图。借助骨架关键点检测分支得到的骨架关键点进行部件划分,按照水平方向分成七部分,即七个空间张量α,得到行人的局部特征。
将全局特征和局部特征采用按向量拼接的方式进行融合,如若这两个特征向量的维度是相同的,则直接采用按向量拼接的方式进行融合;如果是不同维度,则可以通过线性变换转换成同维向量,再用按向量拼接的方式进行融合以增强特征的表达能力,得到七个空间张量μ。
最后再将七个空间张量μ各自进行平均汇合(averagepooling)得到七个列向量β,利用1*1卷积进行通道降维后得到七个列向量γ,七个列向量γ接7个全连接层(fclayer),通过softmax进行分类得到七个特征向量,整个过程权值不共享。
步骤(3)采用标签平滑损失函数对模型进行训练,使得网络参数最优。
根据骨架姿态在imagenet数据库上进行训练得到一个预训练网络,然后将步骤(2)产生的七个特征向量(权值不共享)输入到标签平滑损失函数中得到七个损失函数,并利用反向传播算法对定义的骨架姿态划分部件的行人重识别的模型参数进行训练,直至整个网络模型收敛。
步骤(4)测试时,将七个列向量γ采用按点逐位相加的方式组合成(concatenation)一个特征向量,计算查询集中指定对象和候选集中的每一个对象的欧式距离,接着对所计算得到的距离进行升序排序,获得识别结果。
本发明的有益效果:本发明提出的方法能够根据人的形体自适应地进行区域分块,与已有的方法相比,提高了细节特征提取的精细度,适合于解决外观特征相似、需要借助于外观细节进行辨识的行人reid问题。
附图说明
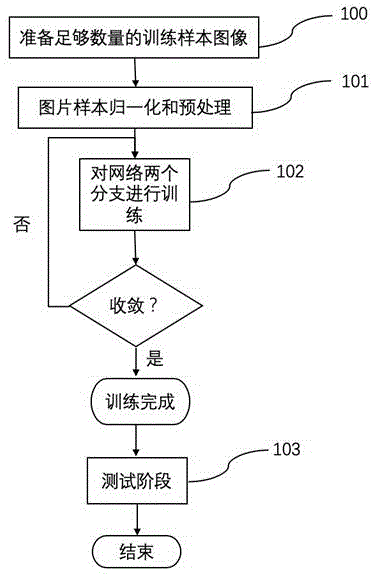
图1为根据本发明的的流程图;
图2为根据本发明的总体网络结构图。
具体实施方式
为了更为具体地描述本发明,下面结合附图及具体实施方式对本发明的技术方案进行详细说明,该方法一实施例的流程如图1所示。本发明基于骨架姿态划分部件的行人重识别方法,包括如下步骤:
步骤(1)、数据预处理
获取足够数量的样本图像(100),图像可以从网络下载(market1501,dukemtmc-reid,cuhk03),也可以自行拍摄处理。
对样本图像进行归一化处理(101),以512×512大小的输入图像为例,如果样本图像大于该尺寸,则进行随机裁剪得到,如果样本图像大小比该尺寸小,则进行等比例放大后再裁剪得到。
步骤(2)、设计网络模型进行特征提取
输入图片数据进入采用了改进的inceptionresnetv2作为骨干网,inceptionresnetv2可以在训练时融合不同尺度的featuremap。
改进的inceptionresnetv2输入首先经过stem结构(202),也就是输入为3通道,即图片的rgb通道,经过stem网络结构,输出为256通道。
再将stem网络输出的256通道数据输入到5个inception-resnet-a(203)网络中,输出依旧为256通道。
将5个inception-resnet-a网络中的输出的通道数为256,输入到reduction-a(204)中,输出为通道数为896的卷积。
将从reduction-a中输出的结果,输入到10个inception-resnet-b(205)中,得到通道数为896的卷积。
将inception-resnet-b的输出结果输入到reduction-a(206)中,得到输出通道数为1792的卷积。
将reduction-a的结果输入到5个inception-resnet-c(207)中,得到通道数为1792的卷积,即得到空间张量特征集合tensort,也就是行人的全局特征。
然后借助骨架关键点检测网络分支(208)得到的骨架关键点进行7个部件划分,按照水平方向分成7部分,即7个空间张量α,得到行人的局部特征。基于多任务骨架姿态划分的行人重识别方法对行人采用7个部件进行划分是利用了14个人体关键点来提取局部特征来提高行人重识别的准确率,7个部件分别是头,上半身根据行人手肘的关键点分成两部分,胯为一部分,腿根据膝关节分成两部分,然后脚为一部分,总共将人体分为7个部件,这样有助于在不破坏行人的重要特征下,提取行人的局部特征。
再将全局特征和局部特征采用按向量拼接的方式进行融合,如若这两个特征向量的维度是相同的,则直接采用按向量拼接的方式进行融合;如果是不同维度,则可以通过线性变换转换成同维向量,再用按向量拼接的方式进行融合以增强特征的表达能力,得到7个空间张量μ。
最后再将7个空间张量μ各进行平均池化(averagepooling),得到7个列向量β。使用1*1卷积对β降维通道数得到7个列向量γ,然后接7个全连接层,softmax进行分类得到7个特征向量(209),整个过程权值不共享,训练时就相当于有7个损失。
在输入图片通过骨架关键点检测分支(208),输入图片经过经典vgg结构,并用1*1卷积,输出一个置信图,如果人体有p个关节点,那么置信图有p层,每一层表示一个关节点的热图。置信图与标签计算该阶段的损失,并存储起来,在网络末尾将每一层的损失加起来作为总损失用于反向传输,实现中间监督,避免梯度消失。
步骤(3)、模型训练(102)
根据行人特征提取分支和骨架关键点检测分支(208)进行联合训练,将网络产生的特征向量按向量拼接的方式进行特征融合输入到标签平滑损失损失函数中,并利用反向传播算法对定义的行人重识别的网络模型参数进行训练,使得网络模型的参数最优,其中模型训练采用的是标签平滑损失。
行人重识别的分类常使用交叉熵损失函数:
其中n为总的行人数,是行人标签。当输入图像i时,yi是图像中行人的标签,若yi为类别i,其值为1,否则为0。pi是网络预测该行人属于标签i行人的概率。
引入标签平滑损失函数的原因是交叉熵损失函数过度依赖正确的行人标签,容易造成训练过拟合的现象,为了避免训练过程出现过拟合现象。在行人训练样本中可能会存在少量的错误标签,这些错误标签会在一定程度上对预测结果产生一定影响,标签平滑损失函数还可用来防止模型在训练过程中过度依赖标签。故行人标签平滑处理就是在训练过程中,给标签设置一个错误率ε,以1-ε作为真实标签进行训练。
其中n为总的行人数,是行人标签。当输入图像i时,yi是图像中行人的标签,若yi为类别i,其值为1,否则为0。pi是网络预测该行人属于标签i行人的概率。ε为标签错误率。
步骤(4)、模型测试(103)
针对行人重识别数据集中包含的查询集和候选集,计算查询集中指定对象和候选集中的每一个对象的欧式距离,测试时是将7个列向量γ按向量拼接的方式合并在一起,再算相似度。接着对所计算得到的距离进行升序排序,获得行人重识别的排序结果,获得行人重识别结果。
综上,本发明根据大量不受控制的变化源,例如姿势和视点的显着变化,照明的复杂变化以及较差的图像质量,reid面临的挑战性,提供一种新的基于骨架姿态对行人部件划分进行划分提取局部特征而不借助分割估计进行重识别的方法。本发明利用卷积神经网络的方法从单目rgb图像中内隐地利用图像的feature与图像相关的空间模型学习了人体姿态来划分人体部件,提出基于骨架姿态划分部件的行人重识别的方法,带来一定的准确率的提高,而且这也是进行行人识别的过程中一个合理的方式。
- 还没有人留言评论。精彩留言会获得点赞!