本发明涉及视频数据挖掘
技术领域:
的一种图像处理方法,尤其涉及一种面向双光子钙成像视频数据的自适应图像分割方法。
背景技术:
:双光子钙成像视频通常具有高分辨率、高帧数、高数位深度的特性。以美国艾伦脑科学研究院开源提供的小鼠脑神经双光子钙成像视频为例,单个视频中总帧数超过10万帧,每帧图像分辨率为512×512像素点,视频的数据容量超过56gb。如此巨量的数据,再加上视频中记录的脑神经元数量大、活动规律复杂,根本无法采用人工方法进行数据挖掘,因此必须研究设计一套高效的自动化数据挖掘方案。自适应图像分割方法就是一种可用于双光子钙成像视频自动化数据挖掘的技术。通过对双光子钙成像视频数据样本进行学习,先构建出视频的背景模型,再通过比较指定图像帧与背景模型的差异,即可快速准确地分割出指定图像帧中所有的活跃性神经元,进而实现对神经元活动状态的全自动实时监测,特别是实现对神经元异常状态的检测。然而,专门针对双光子钙成像视频的数据特性而设计的自适应图像分割方法目前还较少。现有方法主要可以分为两大类。一类方法是来源于传统的针对单幅静态图像的图像分割方法,这种方法的问题在于:将具有时间连贯性的视频图像序列视为孤立无关的单幅图像进行处理,仅仅利用了单幅图像内部的空间信息,而完全丢失了视频图像序列的时间维度信息,因此无法充分挖掘并利用双光子钙成像视频中脑神经元的隐含动态性信息。另一类方法是来源于传统的智能视频监控领域的图像分割方法,这些方法的问题在于:缺少对双光子钙成像视频数据特性的适应与利用。仍以艾伦脑科学研究院的小鼠脑神经双光子钙成像视频为例,其视频数据均为16位深度(即像素值的值域为0~65535),而目前所有智能视频监控领域的视频数据只有8位深度(即像素值的值域为0~255)。大多数基于8位数据深度的图像分割方法,要么根本无法处理16位深度数据,要么会出现运算性能坍塌问题。此外,智能视频图像分割方法中通常使用多模态背景模型框架,而上述双光子钙成像视频的背景模型均为单模态,如果强行使用多模态背景模型框架,不仅会造成显著的运算效率损失,还可能造成对活跃性神经元的检测灵敏度下降。综上所述,如果盲目移植了不匹配的自适应图像分割方法,不仅无法真正有效地实现对双光子钙成像视频的数据挖掘,而且严重的还会造成对实验结果的误判。因此,目前在面向双光子钙成像视频的自动化数据挖掘领域,亟需针对双光子钙成像视频数据特性而专门设计有效、高效的自适应图像分割方法。技术实现要素:针对现有
技术领域:
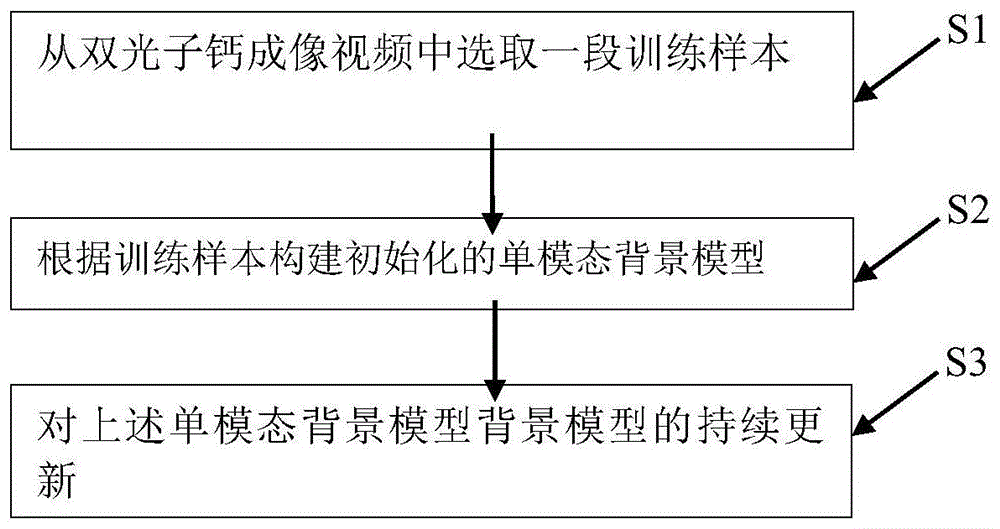
存在的问题,本发明提供一种面向双光子钙成像视频数据的自适应图像分割方法。该方法是根据双光子钙成像视频数据特性而专门设计的,不仅针对此类视频的背景特性进行了背景模型框架优化,而且所设计的在线更新模式也完全满足处理16位深度视频数据的准确性、实时性及精度等各种性能要求。本发明方法,包括以下步骤:s1:从双光子钙成像视频中选取第k帧到第n帧构建训练样本;s2:根据训练样本构建初始化的单模态背景模型;s3:对上述单模态背景模型的持续实时更新;s4:利用实时更新的单模态背景模型对实时输入的图像进行分割检测。所述的双光子钙成像视频可以是由脑神经元经双光子荧光钙成像采集获得。所述步骤s1包括以下步骤:s11:选取双光子钙成像视频中的第k帧到第n帧,作为训练样本;s12:对训练样本进行图像增强处理,具体对训练样本中所有像素点的值进行以下公式的图像增强变换:其中,v代表双光子钙成像视频中像素值的值域上限值,i(x,y)为原始的图像中像素点(x,y)的像素值,j(x,y)为图像增强后的图像中像素点(x,y)的像素值;max表示训练样本中的全局最大图像像素值,min表示训练样本中的全局最小图像像素值。所述步骤s2包括以下步骤:s21:对视频中的每一个像素点(x,y),计算生成像素点(x,y)位置上的初始化的单模态背景模型的中心值,方法如下:(1)对视频四周边缘上的每一个像素点(x,y),计算其在训练样本所有帧图像内的所有像素值j(x,y)k,j(x,y)k+1,...,j(x,y)n的中位数,j(x,y)k表示第k幅图像的像素点(x,y)的像素值,将该中位数作为像素点(x,y)位置上的初始化单模态背景模型中心值c(x,y)n;(2)对视频中非四周边缘位置上的每一个像素点(x,y),计算以该像素点为中心在训练样本所有幅图像内的3×3邻域内的所有像素值的中位数与众数,每幅图像的3×3邻域内共九个像素点,在训练样本共有n-k+1幅图像,共计有9×(n-k+1)个像素值,将该中位数作为像素点(x,y)位置上的初始化的单模态背景模型额中心值c(x,y)n;s22:对视频中的每一个像素点(x,y),计算生成像素点(x,y)位置上的初始化的单模态背景模型的半径值,计算方法如下:其中,m和n分别为视频一帧图像的高与宽,rn是像素点位置上的初始化单模态背景模型的半径值,rn与像素点位置无关,即所有像素点的rn是相同的,z表示图像的序数,z=k,...,n-1;具体实施中,可以将rn的下标n代表为第n幅图像时的半径值,这个值是由k~n幅图像数据累积计算所得。初始化模型的半径就是看(累积到)第n幅图像时的rn,求出了rn后,就可以在n+1帧时用rn去迭代更新背景模型半径rn+1。也就是说,k~n帧内,背景模型半径不需要用迭代的方法计算获得。从n+1帧开始,才使用迭代的方法计算背景模型半径。s23:视频中每一个像素点(x,y)位置上的初始化的单模态背景模型结构如下:初始化的单模态背景模型是一个以c(x,y)n为中心值、rn为半径的值域范围,表示为[c(x,y)n-rn,c(x,y)n+rn];s24:计算生成单模态背景模型的学习率,方法如下:在训练样本范围内,对视频中所有像素点的像素值从θ1灰阶跃迁为θ2灰阶的概率进行计算,生成视频中所有像素点共享的第n帧时的单模态背景模型学习率f(θ1,θ2)n,共享是指同一幅视频帧内所有像素点的单模态背景模型的学习率都相同其中θ1,θ2∈[0,v],其中θ1表示像素值跃迁前的灰阶等级,θ2表示像素值跃迁后的灰阶等级,v代表双光子钙成像视频中像素值的值域上限值同公式1。所述步骤s3包括以下步骤:s31:对单模态背景模型的中心值进行持续更新,方法如下:在新读入n+1帧图像时,对图像内的每一个像素点(x,y),更新该像素点(x,y)位置上的单模态背景模型中心值:c(x,y)n+1=c(x,y)n+[j(x,y)n+1-c(x,y)n]×f(θ1,θ2)n其中,c(x,y)n+1是像素点(x,y)在n+1帧图像时的单模态背景模型中心值,c(x,y)n和f(θ1,θ2)n分别是像素点(x,y)在n帧图像时的单模态背景模型中心值和背景模型学习率,j(x,y)n+1则是(x,y)在n+1帧图像时的像素值,θ1的取值为c(x,y)n,θ2的取值为i(x,y)n+1;s32:对单模态背景模型的半径值进行持续更新,方法如下:在新读入n+1帧图像时,对图像内的每一个像素点(x,y),更新其位置上的单模态背景模型半径值其中,rn+1是任意像素点上在n+1帧时的单模态背景模型半径值;s33:在新读入n+1帧图像时,图像内的每一个像素点(x,y)位置上的单模态背景模型更新如下:该背景模型是一个以c(x,y)n+1为中心值、rn+1为半径的值域范围,即[c(x,y)n+1-rn+1,c(x,y)n+1+rn+1];s34:单模态背景模型的学习率进行持续更新,方法如下:在新读入n+1帧图像时,计算图像内所有位于偶数行、偶数列的像素点的像素值在k+1至n+1帧图像内从θ1灰阶跃迁为θ2灰阶的概率,生成视频内所有像素点共享的第n+1帧图像时的单模态背景模型的学习率f(θ1,θ2)n+1。以此类推,在新读入n+i帧时,采用与上述步骤s31~s34中相同的方法,持续更新n+i帧时刻的单模态背景模型,该背景模型是一个以c(x,y)n+i为中心值、rn+i为半径的值域范围,即[c(x,y)n+i-rn+i,c(x,y)n+i+rn+i],同时更新单模态背景模型学习率f(θ1,θ2)n+i。所述步骤s4具体是利用单模态背景模型的值域范围对图像的每个像素点进行处理判断:若像素点的像素值在单模态背景模型的两个值域范围内,则该像素点作为背景;若像素点的像素值不在单模态背景模型的两个值域范围内,则该像素点作为前景。具体实施中,针对脑神经元的双光子图像进行实时检测,能够判断出活性神经元和非活性神经元,若像素点的像素值在单模态背景模型的两个值域范围内,则该像素点作为非活性神经元;若像素点的像素值不在单模态背景模型的两个值域范围内,则该像素点作为活性神经元。本发明的实质有益效果是:本发明方法缓解了该领域缺少针对双光子钙成像视频数据特性而专门设计自适应图像分割的问题。同时,本发明提供的方法克服了一些现有方法无法适应与利用双光子钙成像视频数据特性的问题:(1)本方法专门用于挖掘双光子钙成像视频数据,能够充分利用视频图像序列的时间维度信息,从而有效挖掘出双光子钙成像视频中脑神经元的隐含动态性信息;(2)本方法专门用于挖掘双光子钙成像视频数据,真正适用于具有16位深度的双光子钙成像视频数据,不会出现运算性能坍塌问题;(2)本方法专门针对双光子钙成像视频数据中背景的固有特性,设计了单模态的背景模型框架与在线更新机制,有效保证了背景模型计算的准确性和运算效率,从而提高了图像分割的准确性。附图说明图1是本发明方法的流程示意图。图2是本发明方法中所用训练样本的示例。图3是本发明方法中对训练样本进行图像增强处理所得结果的示例图。图4是本发明方法根据实施例所取得的结果示例。图5是某种通用智能视频监控领域的图像分割方法根据实施例所取得的结果示例。图6是某种通用面向单幅图像的静态图像分割方法根据实施例所取得的结果示例。图7是本发明方法中背景模型学习率获取方法的示意图。表1是本发明方法与其他通用方法的图像分割结果定性对比。具体实施方式下面通过实施例,并结合附图,对本发明的技术方案作进一步具体的说明。如图1所示,本发明的实施例如下:以一个美国艾伦脑科学研究院提供的小鼠脑神经双光子钙成像视频为例,该视频只有单通道(即像素值仅有灰度信息),包含有115461幅图像,每帧图像分辨率为512×512,数据深度为16位,像素值的值域为0~65535。图2展示了一幅训练样本图像的示例。本实施例具体过程如图1所示,包括以下步骤:s1:从双光子钙成像视频中选取第k=1帧到第n=100帧构建训练样本:s11:选取双光子钙成像视频中的第1帧到第100帧,作为训练样本;s12:对训练样本进行图像增强处理,具体对训练样本中所有像素点的值进行以下公式的图像增强变换:本发明方法根据实施例对图2中所示训练样本图像进行图像增强处理后所得的结果如图3所示。s2:根据训练样本构建初始化的单模态背景模型:s21:对训练样本每帧图像内的每一个像素点(x,y),计算生成像素点(x,y)位置上的初始化的单模态背景模型的中心值,方法如下:(1)对图像四周边缘上的每一个像素点(x,y),计算其在训练样本所有帧图像内的所有像素值j(x,y)1,j(x,y)2,...,j(x,y)100的中位数,将该中位数作为像素点(x,y)位置上的初始化单模态背景模型中心值c(x,y)100;(2)对视频帧图像非四周边缘位置上的每一个像素点(x,y),计算以该像素点为中心在训练样本所有100幅图像内的3×3邻域内的所有100个像素值的中位数与众数,每幅图像的3×3邻域内共九个像素点,在训练样本共有100幅图像,共计有9*100个像素值,将该中位数作为像素点(x,y)位置上的初始化的单模态背景模型额中心值c(x,y)100;s22:对视频图像内的每一个像素点(x,y),在训练样本的第帧图像内计算生成像素点(x,y)位置上的初始化的单模态背景模型的半径值,共享是指同一幅视频帧内所有像素点的单模态背景模型的半径值相同,计算方法如下公式:s23:图像内的每一个像素点(x,y)位置上的初始化的单模态背景模型结构如下:初始化的单模态背景模型是一个以c(x,y)100为中心值、r100为半径的值域范围,表示为[c(x,y)100-r100,c(x,y)100+r100];s24:计算生成单模态背景模型的学习率,方法如下:在训练样本所有帧图像,对图像内所有像素点的像素值从θ1灰阶跃迁为θ2灰阶的概率进行计算,生成视频内所有像素点共享的第n帧时的单模态背景模型学习率f(θ1,θ2)n,共享是指固定位置的一个像素点在各幅图像的单模态背景模型的学习率相同,其中θ1,θ2∈[0,v],θ1,θ2∈[0,65535]。本发明方法中背景模型学习率f(θ1,θ2)n的示意图如图7所示。作为优选,单模态背景模型学习率f(θ1,θ2)100的计算可采用如下的迭代算法:θ1=i(x,y)k,θ2=i(x,y)k+1;e(θ1→θ2)=1;h(θ1,θ2)k+1=∑e(θ1→θ2);其中,i(x,y)k和i(x,y)k+1分别代表视频内任意像素点(x,y)在第k帧和第k+1帧中的像素值,并分别简记为θ1和θ2,由于视频中像素值为隶属于[0,65535]的自然数,故有:θ1∈[0,65535],θ2∈[0,65535];e(θ1→θ2)=1表示检测到以下的事件1次:(x,y)的像素值从k帧中的θ1灰阶跳变为k+1帧中的θ2灰阶;∑e(θ1→θ2)是统计视频内所有像素点的像素值从k帧中的θ1灰阶跳变为k+1帧中的θ2灰阶的次数,将∑e(θ1→θ2)的值记录在方阵h的对应单元h(θ1,θ2)k+1中;方阵z(θ1,θ2)100是对视频训练样本的1~100帧内h(θ1,θ2)k+1值的累加,z(θ1,θ2)100中记录了视频训练样本内检测到的像素值从θ1灰阶跳变为θ2灰阶的总次数;将z(θ1,θ2)100的值归一化为[0,1]之间的概率值,即得到单模态背景模型的学习率f(θ1,θ2)100,f(θ1,θ2)|100是大小为65535×65535的方阵。s3:对上述单模态背景模型的持续实时更新:s31:对单模态背景模型的中心值进行持续更新,方法如下:在新读入101帧时,对视频图像内的每一个像素点(x,y),更新其位置上的单模态背景模型中心值:c(x,y)101=c(x,y)100+[i(x,y)101-c(x,y)100]×f(θ1,θ2)100其中,c(x,y)101是像素点(x,y)在101帧时的单模态背景模型中心值,c(x,y)100和f(θ1,θ2)100分别是像素点(x,y)在100帧时的单模态背景模型中心值和背景模型学习率,i(x,y)101则是(x,y)在101帧时的像素值,θ1的取值为c(x,y)100,θ2的取值为i(x,y)101;s32:对单模态背景模型的半径值进行持续更新,方法如下:在新读入101帧时,对视频图像内的每一个像素点(x,y),更新其位置上的单模态背景模型半径值:其中,r101是任意像素点上在101帧时的单模态背景模型半径值;s33:在新读入101帧时,视频图像内的每一个像素点(x,y)位置上的单模态背景模型更新如下:该背景模型是一个以c(x,y)101为中心值、r101为半径的值域范围,即[c(x,y)101-r101,c(x,y)101+r101];s34:单模态背景模型的学习率进行持续更新,方法如下:在新读入101帧时,计算视频内所有位于偶数行、偶数列的像素点的像素值在2至101帧内从θ1灰阶跃迁为θ2灰阶的概率,生成视频内所有像素点共享的第101帧时的单模态背景模型学习率f(θ1,θ2)101;以此类推,在新读入100+i帧时,采用与上述步骤s31~s34中相同的方法,持续更新100+i帧时刻的单模态背景模型,该背景模型是一个以c(x,y)100+i为中心值、r100+i为半径的值域范围,即[c(x,y)100+i-r100+i,c(x,y)100+i+r100+i],同时更新单模态背景模型学习率f(θ1,θ2)n+i。如前所述,f(θ1,θ2)100是大小为65535×65535的方阵,由于θ1、θ2分别是该方阵的行坐标和列坐标,因此将θ1、θ2的具体值代入f(θ1,θ2)100即可获取方阵中第θ1行、第θ2列的单元位置上对应的背景模型学习率;根据图3的示例,f(3000,2000)100的值就是该方阵中第3000行、第2000列的单元位置上对应的背景模型学习率,即0.5。s4:利用实时更新的单模态背景模型对实时输入的图像进行分割检测。具体实施中,针对脑神经元的双光子图像进行实时检测,能够判断出活性神经元和非活性神经元,若像素点的像素值在单模态背景模型的两个值域范围内,则该像素点作为非活性神经元;若像素点的像素值不在单模态背景模型的两个值域范围内,则该像素点作为活性神经元。本发明方法根据实施例所取得的结果如图4所示。可以看到,由于本方法是针对双光子钙成像视频数据特性而设计的,做了专门的特殊优化处理,因此总体上分割出的前景(即白色像素点区域)与待检测目标物体(即活性神经元)比较一致,漏检(即应该被标记为白色的前景像素点却被标记为了代表背景的黑色)和误检(即应该被标记为黑色背景的像素点却被标记为了代表前景的白色)情况较少。同时,选取了某种通用的智能视频监控领域的图像分割方法作为对比,其根据实施例所取得的结果如图5所示。可以看到,由于该方法并非针对双光子钙成像视频数据特性而设计,因此其分割出的前景与待检测目标物体不够一致,出现了大量的误检和少量的漏检。此外,还选取了某种通用面向单幅图像的静态图像分割方法作为对比,其根据实施例所取得的结果如图6所示。可以看到,该方法分割出的前景与待检测目标物体的一致性也较差,出现了大量的误检和少量的漏检。综上所述,本发明方法与上述两种通用图像分割方法的定性对比结果如表1所示。表1不同图像分割方法的对比图像分割结果定性对比本发明提出方法很好作为对比的某种通用智能视频监控领域的图像分割方法较差作为对比的某种通用面向单幅图像的静态图像分割方法较差由此结果可见,本发明能够解决缺少针对双光子钙成像视频数据特性而专门设计自适应图像分割的问题,克服了现有方法无法适应与利用双光子钙成像视频数据特性的问题,提高了图像分割的准确性,取得了突出显著的技术效果。当前第1页12