基于群体分析的网络舆论事件中社会关注热点的预测方法与流程
本发明涉及网络舆论分析、数据挖掘和深度学习技术领域,具体涉及基于群体分析的网络舆论事件中社会关注热点的预测方法、装置以及计算机存储介质。
背景技术:
网络舆论是社会舆论在互联网上的一种映射,可以反映当前社会中群众普遍关心的社会问题的程度,例如突发事件,司法问题,经济问题等,通过对网络舆论的分析可以更有效地指定解决社会问题的方案。根据目前对于社会关注度的定义,网络舆论事件的社会关注度是指人们对网络上报道的社会上发生的事件的发生、发展和善后处理等进行的关注,通过社会关注度指标来预测未来可能会发展成社会关注热点的网络舆论事件,为舆情事件的处理提供决策支持,可以更好更有针对性的解决社会问题,引导社会朝正能量方向发展。
目前针对网络舆论的社会关注度的影响因素方面,研究者主要从外部因素和内部因素两方面研究它们对关注度的促进或抑制作用,外部因素如用户关系,群体的特征等,内部因素如信息语义关系,内容长短等;针对预测关注度方面,主要是预测给定网络信息在未来的关注度值,通常使用传统数学建模或是机器学习方法。
但现有的研究通常没有考虑多源数据的关联分析,事件语义的分析主要针对事件发展过程,而经过分析研究发现,背后推动事件扩张的群体特征是驱动舆论事件的社会关注度增长的诱因之一,群体关键特征如何与事件语义发展建立联系,抽取出关键的特征对社会关注度起到重要的作用,为此,本发明旨在提供一种基于群体分析的网络舆论事件中社会关注热点的预测方法以解决目前存在的问题。
技术实现要素:
针对上述问题,本发明提供了基于群体分析的网络舆论事件中社会关注热点的预测方法、装置以及计算机存储介质,其可以预测可能会发展成社会关注热点的网络舆论事件,从而为舆情事件的处理提供决策支持。
其技术方案是这样的:基于群体分析的网络舆论事件中社会关注热点的预测方法,其特征在于,包括以下步骤:
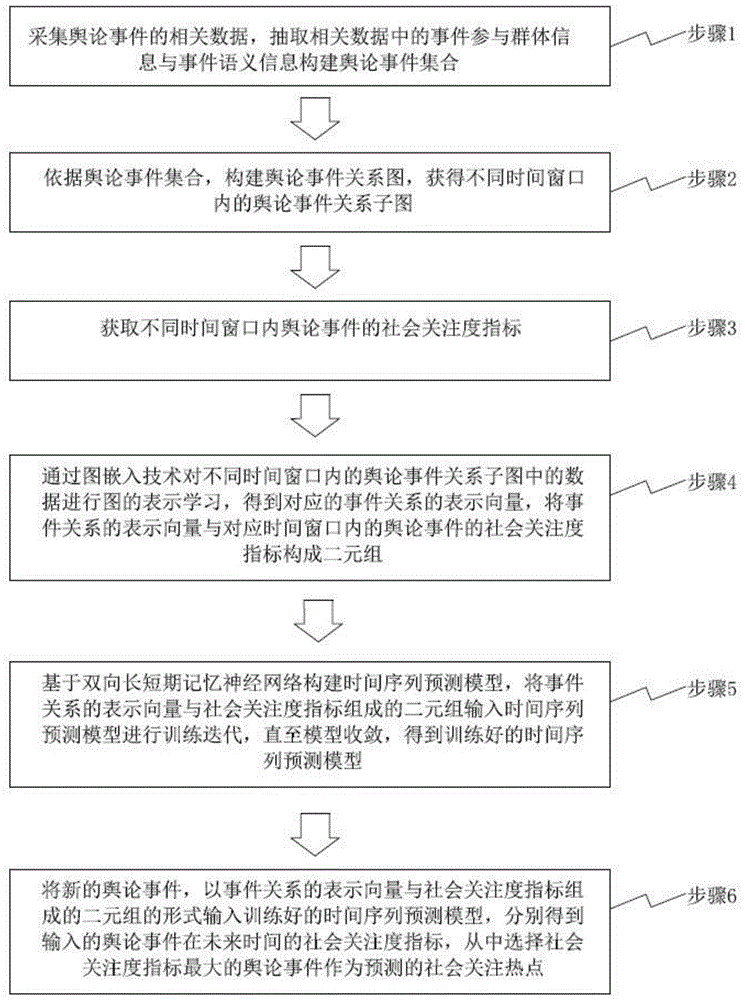
步骤1:采集舆论事件的相关数据,抽取相关数据中的事件参与群体信息与事件语义信息构建舆论事件集合;
步骤2:依据舆论事件集合,构建舆论事件关系图,获得不同时间窗口内的舆论事件关系子图;
步骤3:获取不同时间窗口内舆论事件的社会关注度指标;
步骤4:通过图嵌入技术对不同时间窗口内的舆论事件关系子图中的数据进行图的表示学习,得到对应的事件关系的特征向量,将事件关系的特征向量与对应时间窗口内的舆论事件的社会关注度指标构成二元组;
步骤5:基于双向长短期记忆神经网络构建时间序列预测模型,将事件关系的特征向量与社会关注度指标组成的二元组输入时间序列预测模型进行训练迭代,直至模型收敛,得到训练好的时间序列预测模型;
步骤6:将新的舆论事件,以事件关系的特征向量与社会关注度指标组成的二元组的形式输入训练好的时间序列预测模型,分别得到输入的舆论事件在未来时间的社会关注度指标,从中选择社会关注度指标最大的舆论事件作为预测的社会关注热点。
进一步的,在步骤1中,依据舆论事件的关键词采集舆论事件的相关数据,相关数据包括新闻数据,自媒体数据,微博数据,根据相关数据中包含的事件参与群体信息与事件语义信息,采样出自媒体文本数据集合tsm、新闻文本数据集合tmm、博主数据集合u,评论数据集合c,构建舆论事件集合ei=<tmm,tsm,u,c>,ei表示某一个舆论事件i;
其中,新闻文本数据集合表示为tmm={时间,新闻标题,新闻内容};
自媒体文本数据集合表示为tsm={时间,用户id,博文,原创/转发,来源,ci},其中ci表示评论数据集合c中的某个评论数据;
博主数据集合表示为u={用户id,关注者集合,关注者集合,用户平台};
评论数据集合表示为c={时间,评论id,原博主ui,评论博主uj,原博文,评论博文},其中,评论数据包括评论和转发的数据。
进一步的,在步骤2中,构建舆论事件关系图具体包括以下步骤:
步骤201:统计事件数据持续时长并计算时间窗口;
步骤202:基于舆论事件集合构建用户关系子图与语义关系子图;
步骤203:基于用户关系子图与语义关系子图构建舆论事件关系图,基于时间窗口对舆论事件进行时序化拆分,建立时序舆论事件关系子图。
进一步的,在步骤201中,根据其中一个舆论事件持续的总时长ti,得到单位时间窗口ti,ti=ti/m,m为时间窗口数量;
在步骤202中,在构建用户关系子图时,根据博主数据集合u中用户id与关注者集合的关系,获得具有关注关系的用户,构建用户关注关系子图r;
在构建用户关注关系子图时,根据评论数据集合c中原博主ui和评论博主uj的关系,获得具有评论转发关系的用户,构建用户评论关系子图s;
通过自媒体文本数据集合tsm、博主数据集合u中的用户id连接用户关注关系子图r和用户评论关系子图s之间的关系,构成群体关系图p;
在步骤202中,在构建语义关系子图时,根据新闻文本数据集合tmm中的<新闻内容>和自媒体文本数据集合tsm中的<博文>、<评论ci>的数据,依次通过分词、去停用词、使用tf-idf方法对舆论事件的关键词进行提取,并取出tf-idf数值top_n个的事件关键词,top_n为最大的n个,构成事件特征词集合v,并根据事件特征词集合v中各特征词在文本数据中的共现关系,通过pmi逐点互信息函数定义事件语义关系:
p(si,sj)表示主题si与主题sj共现次数,p(si)表示si的频次,构建事件特征词的语义关系子图ef,其中的语义节点的表示通过word2vec方法构造;
在步骤203中,通过群体关系图p和语义关系子图ef,构建事件关系图g,针对不同的时间窗口对舆论事件进行时序化拆分,构建出不同时间窗口内的事件关系子图gt,gt=<pt,eft>,其中pt表示时间窗口内的群体关系图,eft表示时间窗口内的语义关系子图;
进一步的,在步骤202构建用户关系子图r和用户评论关系子图s的过程中,选择评论数或转发数大于k次的关系,k为正整数,用于确保关系的稳健性。
进一步的,在步骤3中,社会关注度指标通过如下公式表示:
a(e,t)=g(e)+f′(t)
其中,a(e,t)表示社会关注度指标,e表示事件,t表示时间窗口,g(e)表示采集到的参与群体参与舆论事件的频次数量的总和,频次数量统计时包括评论量、转发量、自媒体文本数据量、新闻文本数据量;f′(t)为关于t的二阶导数,用于表示时间窗口内事件群体参与度的增速。
进一步的,步骤4具体包括以下步骤:
步骤401:使用图神经网络gcn方法,对舆论事件中的群体关系进行嵌入表示,获得事件参与群体的群体关系的特征向量
其中,
步骤402:使用图神经网络gcn方法,对舆论事件中的语义关系进行嵌入表示,获得语义关系的特征向量
其中,
步骤403:使用注意力机制进行事件关系进行嵌入表示,通过如下公式表示:
其中,
attention表示深度学习中的注意力机制,
其中,p表示事件参与群体的群体关系信息,s表示舆论事件的语义关系信息,
步骤404:将事件关系的特征向量
进一步的,在步骤5中,基于双向长短期记忆神经网络,对不同单位时间窗口t内的事件关系的特征向量与社会关注度指标的二元组
其中
其中a(e,t+1)为真实的社会关注度指标,a(e,t+1)p为时间序列预测模型预测的社会关注度指标,通过对大量的舆论事件对时间序列预测模型进行训练迭代,直至模型收敛,得到训练好的时间序列预测模型。
基于群体分析的网络舆论事件中社会关注热点的预测装置,其特征在于,包括存储器、处理器以及存储在存储器上并可在处理器上运行的程序,所述处理器执行所述程序时实现如上述的基于群体分析的网络舆论事件中社会关注热点的预测方法。
一种计算机可读存储介质,其上存储有程序,其特征在于:所述程序被处理器执行时实现如上述的基于群体分析的网络舆论事件中社会关注热点的预测方法。
本发明具有的有益效果是:
1.本发明通过对舆情事件中参与群体的群体关系与语义关系的抽取,由于语义关系可以表示事件发展过程中的语义的相关性,对应群体关系的群体分析可以表达推动舆情事件的背后群体特征,因此两种关系的融合可以更好的提高舆情事件的特征质量。
2.本发明通过采集多通道的舆情事件数据,融合社交网络自媒体,新闻、微博等多文本语义信息,全面的体现了网络事件发展过程中语义信息的演化过程。
3.本发明通过图神经网络技术对群体与语义关系进行抽取,方法具有更强的潜在关系表示能力。
4.本发明通过时序的深度学习技术对舆情事件的关注度指标进行学习预测,对不同时间窗口内的关系数据单独学习表示,优势在于数据的构造过程可以并行,同时通过深度学习技术可以获得时序关系特征,以计算更准确的预测结果,预测未来可能会发展成社会关注热点的网络舆论事件,为舆情事件的处理提供决策支持,可以更好更有针对性的解决社会问题,引导社会朝正能量方向发展。
5.本发明可以用于网络舆情事件分析,数据挖掘领域,尤其可以用于监测具有周期性规律的舆情事件的预测与监管。
附图说明
图1为本发明的基于群体分析的网络舆论事件中社会关注热点的预测方法的步骤示意图;
图2为本发明的基于群体分析的网络舆论事件中社会关注热点的预测方法的流程图。
具体实施方式
以下将结合附图及实施例来详细说明本发明的实施方式,借此对本发明如何应用技术手段来解决技术问题,并达成技术效果的实现过程能充分理解并据以实施。需要说明的是,只要不构成冲突,本发明中的各个实施例以及各实施例中的各个特征可以相互结合,所形成的技术方案均在本发明的保护范围之内。
另外,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
见图1至图2,本发明的基于群体分析的网络舆论事件中社会关注热点的预测方法,至少包括以下步骤:
步骤1:采集舆论事件的相关数据,抽取相关数据中的事件参与群体信息与事件语义信息构建舆论事件集合;
步骤2:依据舆论事件集合,构建舆论事件关系图,获得不同时间窗口内的舆论事件关系子图;
步骤3:获取不同时间窗口内舆论事件的社会关注度指标;
步骤4:通过图嵌入技术对不同时间窗口内的舆论事件关系子图中的数据进行图的表示学习,得到对应的事件关系的特征向量,将事件关系的特征向量与对应时间窗口内的舆论事件的社会关注度指标构成二元组;
步骤5:基于双向长短期记忆神经网络构建时间序列预测模型,将事件关系的特征向量与社会关注度指标组成的二元组输入时间序列预测模型进行训练迭代,直至模型收敛,得到训练好的时间序列预测模型。
步骤6:将新的舆论事件,以事件关系的特征向量与社会关注度指标组成的二元组的形式输入训练好的时间序列预测模型,分别得到输入的舆论事件在未来时间的社会关注度指标,从中选择社会关注度指标最大的舆论事件作为预测的社会关注热点。
具体在本实施例中,在步骤1中,依据舆论事件的关键词采集舆论事件的相关数据,相关数据包括新闻数据,自媒体数据,微博数据,根据相关数据中包含的事件参与群体信息与事件语义信息,采样出自媒体文本数据集合tsm、新闻文本数据集合tmm、博主数据集合u,评论数据集合c,构建舆论事件集合ei=<tmm,tsm,u,c>,ei表示某一个舆论事件i;
其中,新闻文本数据集合表示为tmm={时间,新闻标题,新闻内容};
自媒体文本数据集合表示为tsm={时间,用户id,博文,原创/转发,来源,ci},其中ci表示评论数据集合c中的某个评论数据;
博主数据集合表示为u={用户id,关注者集合,关注者集合,用户平台};
评论数据集合表示为c={时间,评论id,原博主ui,评论博主uj,原博文,评论博文},其中,评论数据包括评论和转发的数据。
新闻数据,自媒体数据,微博等数据,这些数据具有很强的关系特性,例如事件演化过程中语义信息的关联关系,以及参与事件的用户群体间的关联关系,而这些关系又是导致事件被关注的诱因。所以根据以上关系,从采集的数据中抽取出与事件相关度最高的若干个事件话题以及参与事件相关群体的集合,从这些数据中挖掘事件背后参与群体的特征,结合事件的语义信息,对舆情事件的关注度进行分析预测。
进一步的,在步骤2中,构建舆论事件关系图具体包括以下步骤:
步骤201:统计事件数据持续时长并计算时间窗口;
步骤202:基于舆论事件集合构建用户关系子图与语义关系子图;
步骤203:基于用户关系子图与语义关系子图构建舆论事件关系图,基于时间窗口对舆论事件进行时序化拆分,建立时序舆论事件关系子图。
具体的,在步骤201中,根据其中一个舆论事件持续的总时长ti,得到单位时间窗口ti,ti=ti/m,m为时间窗口数量;
在步骤202中,在构建用户关系子图时,根据博主数据集合u中用户id与关注者集合的关系,获得具有关注关系的用户,构建用户关注关系子图r;
在构建用户关注关系子图时,根据评论数据集合c中原博主ui和评论博主uj的关系,获得具有评论转发关系的用户,构建用户评论关系子图s;
在步骤202构建用户关系子图r和用户评论关系子图s的过程中,选择评论数或转发数大于k次的关系,k为正整数,用于确保关系的稳健性。
通过自媒体文本数据集合tsm、博主数据集合u中的用户id连接用户关注关系子图r和用户评论关系子图s之间的关系,构成群体关系图p,这一过程意在整合参与事件群体的用户关系与用户属性,对这样关系数据进行分析获得参与事件的群体属性;
在步骤202中,在构建语义关系子图时,根据新闻文本数据集合tmm中的<新闻内容>和自媒体文本数据集合tsm中的<博文>、<评论ci>的数据,依次通过分词、去停用词、使用tf-idf方法对舆论事件的关键词进行提取,并取出tf-idf数值top_n个的事件关键词,top_n为最大的n个,构成事件特征词集合v,并根据事件特征词集合v中各特征词在文本数据中的共现关系,通过pmi逐点互信息函数定义事件语义关系:
p(si,sj)表示主题si与主题sj共现次数,p(si)表示si的频次,构建事件特征词的语义关系子图ef,其中的语义节点的表示通过word2vec方法构造,这一过程旨在提取事件语义演化关系。
在步骤203中,通过群体关系图p和语义关系子图ef,构建事件关系图g,针对不同的时间窗口对舆论事件进行时序化拆分,构建出不同时间窗口内的事件关系子图gt,gt=<pt,eft>,其中pt表示时间窗口内的群体关系图,eft表示时间窗口内的语义关系子图。
这一步骤主要对事件参与群体与事件语义信息的关系结构以及属性特征进行数据初始化,为后续通过深度学习技术提取群体特征提供输入数据。
具体在步骤3中,社会关注度指标通过如下公式表示:
a(e,t)=g(e)+f′(t)
其中,a(e,t)表示社会关注度指标,e表示事件,t表示时间窗口,g(e)表示采集到的参与群体参与舆论事件的频次数量的总和,频次数量统计时包括评论量、转发量、自媒体文本数据量、新闻文本数据量;f′(t)为关于t的二阶导数,用于表示时间窗口内事件群体参与度的增速。
步骤4具体包括以下步骤:
步骤401:使用图神经网络gcn方法,对舆论事件中的群体关系进行嵌入表示,获得事件参与群体的群体关系的特征向量
其中,
步骤402:使用图神经网络gcn方法,对舆论事件中的语义关系进行嵌入表示,获得语义关系的特征向量
其中,
步骤403:使用注意力机制进行事件关系进行嵌入表示,通过如下公式表示:
其中,
attention表示深度学习中的注意力机制,
其中,p表示事件参与群体的群体关系信息,s表示舆论事件的语义关系信息,
步骤404:将事件关系的特征向量
进一步的,在步骤5中,基于双向长短期记忆神经网络,对不同单位时间窗口t内的事件关系的特征向量与社会关注度指标的二元组
其中
其中a(e,t+1)为真实的社会关注度指标,a(e,t+1)p为时间序列预测模型预测的社会关注度指标,通过对大量的舆论事件对时间序列预测模型进行训练迭代,直至模型收敛,得到训练好的时间序列预测模型。
在步骤6中,将新的舆论事件,以事件关系的特征向量与社会关注度指标组成的二元组的形式输入训练好的时间序列预测模型,分别得到输入的舆论事件在未来时间的社会关注度指标,从中选择社会关注度指标最大的舆论事件作为预测的社会关注热点,表达为公式:max(a(enew,t+1)),其中enew为新的舆论事件。
通过构造新的舆论事件e的事件关系图实例,作为预测模型输入后可对新事件e的未来t+1时刻的关注度指标a(t+1)进行预测计算,以直观的指标形式反映当前舆论事件的被关注程度,从中选择社会关注度指标最大的舆论事件作为预测的社会关注热点。
在本发明的实施例中,还提供了基于群体分析的网络舆论事件中社会关注热点的预测装置,包括存储器、处理器以及存储在存储器上并可在处理器上运行的程序,处理器执行程序时实现如上述的基于群体分析的网络舆论事件中社会关注热点的预测方法。
该装置可包括,但不仅限于处理器、存储器。本领域技术人员可以理解,本实施例仅仅是装置的举例,并不构成对装置的限定,可以包括比本实施例更多或更少的部件,或者组合某些部件,或者不同的部件,例如还可以包括输入输出设备、网络接入设备等。
存储器可以是,但不限于,随机存取存储器(randomaccessmemory,简称:ram),只读存储器(readonlymemory,简称:rom),可编程只读存储器(programmableread-onlymemory,简称:prom),可擦除只读存储器(erasableprogrammableread-onlymemory,简称:eprom),电可擦除只读存储器(electricerasableprogrammableread-onlymemory,简称:eeprom)等。其中,存储器用于存储程序,处理器在接收到执行指令后,执行程序。
处理器可以是一种集成电路芯片,具有信号的处理能力。上述的处理器可以是通用处理器,包括中央处理器(centralprocessingunit,简称:cpu)、网络处理器(networkprocessor,简称:np)等。该处理器还可以是其他通用处理器、数字信号处理器(digitalsignalprocessor,dsp)、专用集成电路(applicationspecificintegratedcircuit,asic)、现场可编程门阵列(field-programmablegatearray,fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。可以实现或者执行本申请实施例中的公开的各方法、步骤及逻辑框图。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等。
可以以一种或多种程序设计语言的任意组合来编写用于执行本发明操作的数据处理程序,程序设计语言包括面向对象的程序设计语言—诸如java、c++等,还包括常规的过程式程序设计语言—诸如“c”语言或类似的程序设计语言。数据处理程序可以完全地在用户计算设备上执行、部分地在用户设备上执行、作为一个独立的软件包执行、部分在用户计算设备上部分在远程计算设备上执行、或者完全在远程计算设备或服务器上执行。在涉及远程计算设备的情形中,远程计算设备可以通过任意种类的网络,包括局域网(lan)或广域网(wan),连接到用户计算设备,或者,可以连接到外部计算设备(例如利用因特网服务提供商来通过因特网连接)。
在本发明的实施例中,还提供了一种计算机可读存储介质,其上存储有程序,程序被处理器执行时实现如上述的基于群体分析的网络舆论事件中社会关注热点的预测方法。
本领域内的技术人员应明白,本发明实施例的实施例可提供为方法、装置、或计算机程序产品。因此,本发明实施例可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明实施例可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
本发明实施例是参照根据本发明实施例的方法、装置、和计算机程序产品的流程图和/或框图来描述的。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理终端设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理终端设备的处理器执行的指令产生用于实现在流程图和或中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理终端设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理终端设备上,使得在计算机或其他可编程终端设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程终端设备上执行的指令提供用于实现在流程图中指定的功能的步骤。
以上对本发明所提供的基于群体分析的网络舆论事件中社会关注热点的预测方法、基于群体分析的网络舆论事件中社会关注热点的预测装置、一种计算机可读存储介质的应用进行了详细介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!