一种基于商品卖点的商品推荐话术生成方法及系统与流程
本发明属于计算机的技术领域,具体涉及一种基于商品卖点的商品推荐话术生成方法及系统。
背景技术:
随着电商行业的急速发展,网上购物的占比越来越大,在线客服扮演着很重要的角色。和线下的导购工作一样,介绍商品也是在线客服重要的工作之一,介绍商品时,卖家通过在线对话发送合适的文案,吸引用户,推荐话术的好坏,直接影响着商品对用户的吸引力,从而也影响最终商品的购买率。从经验看,好的话术需要将商品的卖点介绍给顾客,不同商品的卖点不同,对应的话术更是可以千差万别,而且同一家店铺下常常有非常多的商品,即使卖点相同的商品,也需要不同的话术进行介绍,如果全部通过人工编辑,往往显得语言匮乏,成本较高。如何快速、准确、生动的完成推荐话术的编辑成为研究的热点。
在人工智能技术飞速发展的今天,自然语言生成技术恰好能够弥补人力的不足,而且可以大量学习业界内的优美推荐话术,用丰富的形式将卖点阐明给买家。业界内有一些生成话术的方法研究,比如:cn201811550825.5,根据问答对聚类来生成回答的话术。再比如cn201910186142.4,利用深度模型判断出问题的语义,对应到相应的推荐答案。也有一些更为激进的技术研究派,比如:cn201810751386.8,利用诗歌生成的rnn模型来生成话术。
然而,cn201811550825.5和cn201910186142.4中的问题类似,更多的面向的是通用问题,比如流程上“什么时间发货”这一类能够通用解答的问题,但如果是介绍商品,不同商品的回答并不能照搬,因此不能用这种直接相同语义的问题聚类后,取对应答案的方法。cn201810751386.8中利用了rnn来生成商品简介,还能通过传入偏重关键词的形式,达到针对卖点的目的。但是,就目前的技术来讲,仅用rnn生成的语言(排除翻译这种加了更多特殊约束的情况)很难到达语句通顺的目的,生成诗词的时候,即使语法没那么对,也能说得过去,比如“古藤老树昏鸦”,甚至还能更有意境,因此要求没那么严格,但应用到现实生活的对话中,就会显得莫名其妙。
在现实应用中,除了针对性、通顺性外,文案上其实还有其他方面的要求。比如丰富多样,即使同一个功能卖点不同,商品也希望有不同话术来描述;再如时效性,业界内新成立的一种功能说法,能够做出相应的话术引导,比如“抗初老”。结合实际应用中的具体要求,一定是要将商品的卖点介绍给用户,因此话术的生成思路一开始就需要从结合商品卖点出发。话术本身也需要切合实际,语言通顺,实事求是,因此需要尽量用本来就是人的语言。同时,也需要兼顾丰富性,时效性等问题,更完善的解决自动生成商品推荐文案的问题。
技术实现要素:
本发明的目的在于提供一种基于商品卖点的商品推荐话术生成方法,本发明以卖点为关键点进行生成推荐话术,不会显得只是语言空洞,言之无物;作为中心的卖点正是买家大概率更感兴趣的点,会更容易的触动买家,促进销售的顺利进行。
本发明的目的还在于提供一种基于商品卖点的商品推荐话术生成系统,本发明围绕卖点来展开,可以更好的贴近买家的需求,促进销售的顺利进行。
本发明主要通过以下技术方案实现:一种基于商品卖点的商品推荐话术生成方法,主要包括以下步骤:
步骤s300:卖点挖掘:从商品的基本信息中抽取直接卖点,同时按重要性对直接卖点进行排序;
步骤s400:以直接卖点为基准,在知识库中通过蕴含关系找到商品可以推理出来的卖点,并作为蕴含卖点;蕴含卖点用于过滤描述,直接卖点用于检索描述;通过直接卖点将商品和描述关联起来,随机生成商品的推荐话术。
本发明在使用过程中,描述生成环节,不一定是要用检索模式,在技术成熟的情况下,可以采用围绕关键词生成话术的方案。
为了更好地实现本发明,进一步的,所述步骤s300中抽取卖点后,按照通用排序方法或者个性化排序方法对卖点进行排序;所述通用排序方法:已知商品具体prod,采用知识库中prod和attr_value之间的共现指数,判断attr_value的特殊性,按特殊性高低对卖点进行排序;所述个性化的排序方法,则是结合商品的文本信息,采用tf-idf或者采用提取关键词的方法获得相关指数,以用来对卖点进行排序。所述共现指数是指pmi值。在通用排序方法中,按照特殊性的高低对卖点进行排序,所述特殊性即为上述的重要性。
为了更好地实现本发明,进一步的,所述步骤s400主要包括以下步骤:
步骤s401:构造描述检索库:在描述库中将每一句描述抽取卖点并建成检索库;
步骤s402:卖点检索拉取单链:然后针对每个直接卖点,拉取倒排索引,从而得到每个直接卖点的推荐话术;
步骤s403:卖点描述选择:按直接卖点的顺序,依次挑选卖点的描述,在挑选时,为了增加多样性,采用拉链topn随机的方式;另外需要去重,后续不重复已经采用的描述中包含的卖点。
为了更好地实现本发明,进一步的,所述步骤s402中单个卖点的步骤如下:
步骤s4021:单个卖点先通过知识库的信息引入同义词;
步骤s4022:对卖点及同义词拉取倒排索引;
步骤s4023:单条索引需要对里面的描述进行过滤,如果描述的卖点超出了蕴含卖点,那么过滤掉描述;
步骤s4024:将多条索引做并集,描述按参数排序,所述参数为频繁层度、话术判断模型打分、描述长度、包含蕴含卖点的个数及权重中的任意一种或多种。
为了更好地实现本发明,进一步的,从商品的基本信息中,学习出知识库,所述知识库包括prod和attr_value;除了挖掘出prod、attr_value的全集以外,还需要把他们相互间的关系挖掘出来,prod和prod,attr_value和attr_value之间的同义、蕴含关系,prod和attr_value之间的蕴含关系。
为了更好地实现本发明,进一步的,所述知识库的挖掘方法为方法a-g中的任意一种或几种:
所述方法a中挖掘商品信息本身的结构化信息,抽取字段,每个词按频次排序,人工梳理头部部分,作为知识库中准确的标准集;
所述方法b中利用ner模型将商品的文字信息通过人工标注,通过训练后能够识别出prod和attr_value,并添加到知识库中;
所述方法c采用textrank,topic-model,rake中的任意一种语言模型,找到基本信息里面的关键词,用来补充知识库;
所述方法d采用word2vector的模型将商品的文字信息学习出向量表示,再根据向量表示,挖掘出term之间的同义关系,补充知识库;
所述方法e通过共现关系来挖掘蕴含关系,以单个商品的基本信息作为一个doc,统计terma和termb之间的共现关系,并计算概率值p(a|b),p(b|a),以及两个term之间的pmi(pointwisemutualinformation)值;
所述方法f引入人工梳理的途径,进一步完善知识库;所述方法g将新词以及新的term之间的关系推往人工梳理。
为了更好地实现本发明,进一步的,从推荐文章、聊天记录中抽取描述,用于对语言进行过滤,保留推荐话术的语言作为描述,同时通过nlp的语法知识做句法调整,形成描述库。
为了更好地实现本发明,进一步的,形成描述库主要包括以下步骤:
步骤s1:话术分割:将一句长句划分成若干段,更局部的处理语料;
步骤s2:话术分类:将步骤s1得到的一个一个的短句作为待判断集合,找出里面有推荐作用的优美话术;通过深度学习来判断分类,采用bilstm+mlp的模型作为话术判断模型,同时采用word2vector的向量来迁移学习;
步骤s3:语言整理:针对切分的句子的语法上的问题,结合当前nlp的已有知识做话术整理,包括中文分词,依存分析,词性分析,需要完成的功能点包括:过滤停用词,语气词;过滤句子间连词;过滤prod级的主语。
本发明主要通过以下技术方案实现:一种基于商品卖点的商品推荐话术生成系统,包括知识库、描述库、卖点挖掘模块、描述生成模块,所述卖点挖掘模块用于从知识库、描述库中抽取卖点并进行排序;将商品的基本信息中抽取的卖点作为直接卖点,以直接卖点为基准,在知识库中通过蕴含关系找到商品可以推理出来的卖点,并作为蕴含卖点;蕴含卖点用于过滤描述,直接卖点用于检索描述;所述描述生成模块通过直接卖点将商品和描述关联起来,随机生成商品的推荐话术。
为了更好地实现本发明,进一步的,还包括描述库挖掘模块,所述描述库挖掘模块包括话术分割模块、话术分类模块、语言整理模块,所述话术分割模块用于将一句长句划分成若干段;所述话术分类模块用于筛选具有推荐作用的话术;所述语言整理模块用于整理推荐话术的语法。
本发明的目的是为了学习业界内优秀的推荐话术,通常的,在同一个类目下,商品的话术更具有通用性。因此可以按类目分别进行挖掘,比如美妆,服装,鞋子,手机,电器,家具这样的划分,简化难度,当然也可以全类目一起挖掘,但这样更加复杂,效果可能也没有这么精细。
本发明中需要的数据如下:
1.商品的基本信息,以某个商品url为唯一key,获取该商品的基本信息,包括title,图片,以及商品详情页上的一些结构化信息;
2.话术的来源数据。我们需要业界内优美的推荐话术,来源可以是商品推荐文章,客服的聊天记录等等,这些都可能包含有卖点话术的数据。
所述商品url是某个商品的唯一标识符,其相关信息包含了title,图片以及商品页上的一些结构化信息。图片信息可以通过已经比较成熟的ocr技术识别出里面的文章,当做商品的文本信息。由于图片信息比较复杂,ocr识别出的文字不一定能直接用,比如换行等问题,但可以作为语料用来表征这个商品。
产品(prod),一件商品到底是什么,比如“面膜”“爽肤水”“洗面奶”。
属性名(attr_name),用于介绍一个商品某个方向,比如“适用皮肤”“成分”“功效”。
属性值(attr_value),一个商品一个属性名下的值,比如成分“烟酰胺”,功效“美白”、“抗衰老”。
描述(disc),针对某个商品介绍的通用化的优美的话术,例如:“添加了烟酰胺的美白成分”“起到抗皱延缓衰老的效果”。
本发明的有益效果:
(1)方案中存在卖点挖掘,整体话术是围绕卖点来展开,不会显得只是语言空洞,言之无物。作为中心的卖点正是买家大概率更感兴趣的点,会更容易的触动买家;
(2)具体话术语言采用真人语言加ai组装,和纯ai生成的语言相比,在通顺性和表达含义上更有保障;
(3)数据引入的部分,采用人工智能的模型可以轻松达到及时更新的目的,在卖点以及话术上,都可以切合当下的流行趋势,给到商品的卖点;
(4)可控性高:由于有知识库的知识指导,方便人工添加已经整理好的知识;描述库也是挖掘而来,如果不够,也可根据需求人工添加;最后生成部分,句式的风格,长短都可以定制。
附图说明
图1为基于商品卖点的商品推荐话术生成方法的流程图;
图2为prod和attr_value相互间关系挖掘原理图;
图3为描述库挖掘的流程图;
图4为卖点描述生成的流程图;
图5为实施例5中描述与卖点的正排信息示意图;
图6为实施例5中描述与卖点的倒排信息示意图;
图7为实施例5中直接卖点与蕴含卖点的关系示意图。
具体实施方式
实施例1:
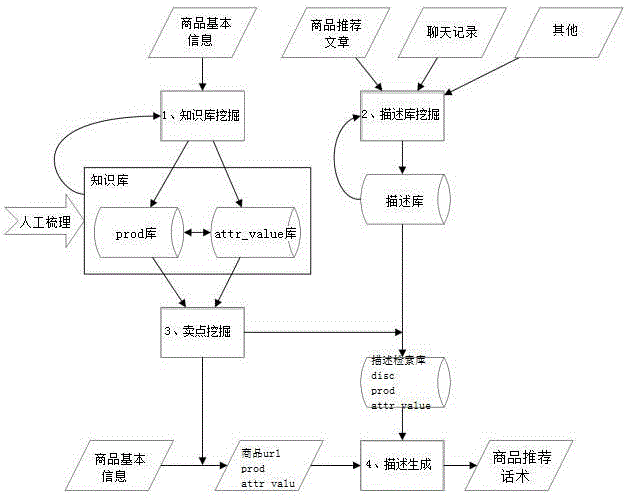
一种基于商品卖点的商品推荐话术生成方法,如图1所示,主要包括以下步骤:
第一步从商品的基本信息中,学习出prod和attr_value所组成的知识库,知识库是一些基础知识,对效果优化帮助很大。
第二步我们从推荐文章,聊天记录中抽取描述,主要功能是对语言做一个过滤,只保留是推荐话术的语言作为描述,同时通过nlp的语法知识做句法调整,形成描述库。
第三步需要形成一个卖点挖掘模型,可以从一句描述中,抽取相关卖点。也可以从商品的基本信息中抽取相关卖点,同时有一个卖点的重要性排序。
最后,通过卖点将商品和描述关联起来,随机生成商品的推荐话术。
本发明以卖点为关键点进行生成推荐话术,不会显得只是语言空洞,言之无物;作为中心的卖点正是买家大概率更感兴趣的点,会更容易的触动买家,促进销售的顺利进行。
实施例2:
本实施例是在实施例1的基础上进行优化,知识库挖掘:
本发明的目的其实是从商品信息中,抽取商品是什么,有哪些卖点。如果能对这个方面有一个系统的认识,会更好一些。因此有必要提前挖掘知识库。我们希望的知识库是有prod和attr_value的,attr_name需求较弱,在一些attr_value有重复时才需要,比如服装的attr_name是“面料材质”和“里料材质”,attr_value都可以是“纯棉”,这个时候有必要加上attr_name。如图2所示,知识库的挖掘除了挖掘出prod,attr_value的全集以外,还希望把这他们相互间的关系挖掘出来。比如prod和prod,attr_value和attr_value之间的同义、蕴含关系,prod和attr_value之间有蕴含关系。
挖掘的方法很多,举例几种方法,可以综合应用:
a.商品信息本身的结构化信息,抽取相关字段,每个词按频次排序,人工梳理头部部分,可以作为知识库中准确的标准集,
b.利用ner模型,将商品的文字信息通过人工标注,识别其中的prod和attr_value。ner模型可以采用较常规的模型(bilstm-crf),也可采用更复杂的模型。通过训练后能够识别出prod和attr_value,添加到知识库中
c.其他一些语言模型,也可以用起来,比如textrank,topic-model,rake等,找到基本信息里面的关键词,大概率会是知识库需要的词,用来补充。
d.采用word2vector的模型,将商品的文字信息学习出向量表示,再根据向量表示,挖掘出term之间的同义关系,补充知识库
e.蕴含关系,可以通过共现关系来挖掘,以单个商品的基本信息作为一个doc,统计terma和termb之间的共现关系。计算概率值p(a|b),p(b|a),以及两个term之间的pmi值。
f.由于是基础知识库的数据,可以引入人工梳理的途径,进一步完善知识库
g.最后,这个挖掘是可更新的,可以定时导入最新的商品,对于“抗初老”这样的新词汇,由于我们有ner的模型,大概率能发现这样的词汇。如果有人工梳理,可以只将新词以及新的term之间的关系推往人工梳理即可。
本实施例的其他部分与实施例1相同,故不再赘述。
实施例3:
本实施例是在实施例1或2的基础上进行优化,描述库挖掘:
这里,我们的目标是找出哪些是真正有推荐话术的语句。因此可以算是一个二分类模型。如图3所示,流程如下:
a.话术分割模块,用于将一句长句划分成几段,更局部的处理语料。可以简单的按标点符合分割,也可以应用一些算法(比如依存分析),拆分得更合理一些。
b.话术分类模块,将上面得到的一个一个的短句作为我们的待判断集合,找出里面有推荐作用的优美话术。需要先标注一批数据,然后通过深度学习来判断。这里,我们采用的是bilstm+mlp的模型,通过bilstm更能结合上下文的信息,同时,采用word2vector的向量来迁移学习,效果更好,该模型后续称为话术判断模型
c.语言整理模块,通过切分的句子会有一些语法上的问题,需要结合当前nlp的一些已有知识,做一些话术整理。包括中文分词,依存分析,词性分析等,需要完成的功能点包括:
a)过滤停用词,语气词;
b)过滤句子间连词;
c)过滤prod级的主语;
最终得到描述,描述的标准是能够直接接在主语后面,形成通顺的话。
以上措施后,得到第一批描述库。同样,也能够支持人工梳理和持续更新的功能。由于有判断模型的存在,新的语料信息导入后可以判断出是否是描述,可以将新增描述推送人工审核或者直接生效。
本实施例的其他部分与上述实施例1或2相同,故不再赘述。
实施例4:
本实施例是在实施例1-3任一个的基础上进行优化,卖点挖掘:
我们有商品信息,知识库信息,以及描述库的信息。需要从商品信息和描述库信息中,找到包含的卖点。卖点由知识库里面的元素组成。提取的方法也有很多,可以复用第一步知识库挖掘里面的ner模型以及语言模型textrank,topic-model,rake等提取关键词的方法,不同的是这里有了知识库的帮助,模型可以提取得更好,甚至可以加入切词后匹配的方法,同时需要结合一些规则判断,比如否定词等。
对商品抽取了卖点的后,需要对卖点做一个排序。排序时可以结合通用的排序方法以及个性化排序方法。
a.通用的排序方法,我们知道了商品具体prod,则可以用第一步知识库挖掘里面prod和attr_value之间的共现指数,判断attr_value的特殊性,越特殊的越重要一些。
b.个性化的排序方法,则是结合商品的文本信息,可以用tf-idf或者其他提取关键词的方式时获得的相关指数,用来对卖点进行排序。如果有条件获取该商品的聊天信息,用tf-idf时,能更准的计算出该商品的关注卖点的重要程度。
对描述抽取卖点后,更多的还是个性化的排序方法。
本实施例的其他部分与上述实施例1-3任一个相同,故不再赘述。
实施例5:
本实施例是在实施例1-4任一个的基础上进行优化,描述生成:
最后一步,是生成最终描述。我们选用的是类似检索的模式。但其实这一步也可以利用深度模型的机器学习,学习出词的分布规律,围绕卖点生成一段话。但目前技术还不能解决机器语言的句法,通顺性问题,可控性没有检索模式好。
如图4所示,生成最终描述按功能点包括以下步骤:
a.构造描述检索库
如图5-图6所示,采用倒排索引的方法使卖点与描述关联。将描述库通过描述的卖点建成检索库,可以用文本的倒排检索。如图5所示,正排信息为描述a包含卖点1、2、3,描述b包含卖点3,描述c包含卖点2、4;
需要以卖点为key,构造成倒排索引的形式。
b.卖点检索拉取单链
对于单个商品,步骤s300拿到了他的卖点,作为直接卖点。
1)通过蕴含关系找到该商品可以推理出来的卖点,组成蕴含卖点,
2)通过同义词关系,进一步扩充蕴含卖点。
直接卖点用于检索,蕴含卖点用于过滤,如图7所示,直接卖点一定是蕴含卖点的子集。
然后针对每个直接卖点,拉取倒排索引,以下是单个卖点的步骤:
①单个卖点先通过知识库的信息,引入同义词。
②对卖点及同义词拉取倒排索引。
③单条索引需要对里面的描述进行过滤,如果某描述的卖点超出了蕴含卖点,那么过滤掉该描述,这样就不会出错。
④将多条索引做并集,描述按一些参数排序,如频繁层度,话术判断模型打分,描述长度,包含蕴含卖点的个数、权重等。
⑤这样就拿到了每个直接卖点的推荐话术。
c.卖点描述选择
按步骤s300中直接卖点的顺序,依次挑选卖点的描述。这里需要注意的是去重。
挑选时,为了增加多样性,可以采用拉链topn随机的方式。
另外需要注意去重,原则是采用的描述中已经包含的卖点,后续不能重复,还是以之前的示例说明,如图6所示:
商品x先用卖点3拉取拉a,b,d,a因卖点1过滤掉,只有b,d两条结果,
卖点2拉取a,c,d,a因卖点1过滤掉,只有c,d两条结果,
如果3选了c,2只能选d,如果3选了b,2可以随机选c,d。
d.合成最终推荐话术
以上已经得到一系列可用的无重复卖点的话术,
然后可以按定制化的需求组成最终的推荐语言,
模板信息,可以指定模板,形成店铺特有的推荐语言风格,
排序方案,可以直接按attr_value重要程度排序,更加突出重要的卖点,也可以attr_value相关性更强的排一起,组织上显得更有调理等等。规则都可以定制。
本实施例的其他部分与上述实施例1-4任一个相同,故不再赘述。
实施例6:
一种基于商品卖点的商品推荐话术生成系统,包括知识库、描述库、卖点挖掘模块、描述生成模块,所述卖点挖掘模块用于从知识库、描述库中抽取卖点并进行排序;所述描述生成模块用于将通过卖点将商品和描述关联起来,并随机生成商品的推荐话术。
本发明以卖点为关键点进行生成推荐话术,不会显得只是语言空洞,言之无物;作为中心的卖点正是买家大概率更感兴趣的点,会更容易的触动买家,促进销售的顺利进行。
实施例7:
本实施例是在实施例6的基础上进行优化,如图3所示,还包括描述库挖掘模块,所述描述库挖掘模块包括话术分割模块、话术分类模块、语言整理模块,所述话术分割模块用于将一句长句划分成若干段;所述话术分类模块用于筛选具有推荐作用的话术;所述语言整理模块用于整理推荐话术的语法。
本实施例的其他部分与上述实施例6相同,故不再赘述。
以上所述,仅是本发明的较佳实施例,并非对本发明做任何形式上的限制,凡是依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化,均落入本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!