一种制作云监控指标的方法与流程
本发明涉及云监控技术,尤其涉及一种制作云监控指标的方法。
背景技术:
近年来,kubernetes作为一种容器编排管理技术已经非常的成熟了,它本身维护着大量的资源,而这些资源有时会因为一些原因导致状态异常,因此需要一种自动监控kubernetes资源并在资源状态异常时发出告警的方法。
kubernetes是一个全新的基于容器技术的分布式架构领先方案,所有的应用程序在kubernetes中都是以资源的形式存在,而这些资源有时会因为网络、环境等因素变得不可用,因此需要能够实时监控这些资源,并在这些资源状态异常时发出告警,运维人员在收到告警后根据告警内容进行迅速排查避免不必要的损失。
prometheus是一个开源的系统监控工具,可以对接kubernetes获取监控数据,这里主要想收集的监控数据是kubernetes的资源,因此需要在kubernetes中部署kube-state-metrics组件,这就基本可以获取到所以需要监控的资源信息了。
结合kubernetes和prometheus通过定时任务接收和获取资源信息,制作出需要告警的云监控指标。
kafka是一个分布式的消息队列系统,制作好的云监控指标可以通过kafka推送到监控告警平台。
总之,kubernetes本身的资源出现状态异常时不会发出告警,当生产环境出现状况时很可能带来损失,需要一个制作云监控指标的方法去减小这种损失。
技术实现要素:
为了解决以上技术问题,本发明提供了一种制作云监控指标的方法。可以实时监控到kubernetes的资源状况,推送到监控告警平台之后可以出发告警。
本发明的技术方案是:
一种制作云监控指标的方法,
包括如下步骤:
1)使用定时任务推送和拉取云监控指标元数据;
2)使用缓存保存集群元数据;
3)使用配置文件模板动态配置不同集群的监控指标;
4)云监控指标制作程序的高可用部署。
进一步的,
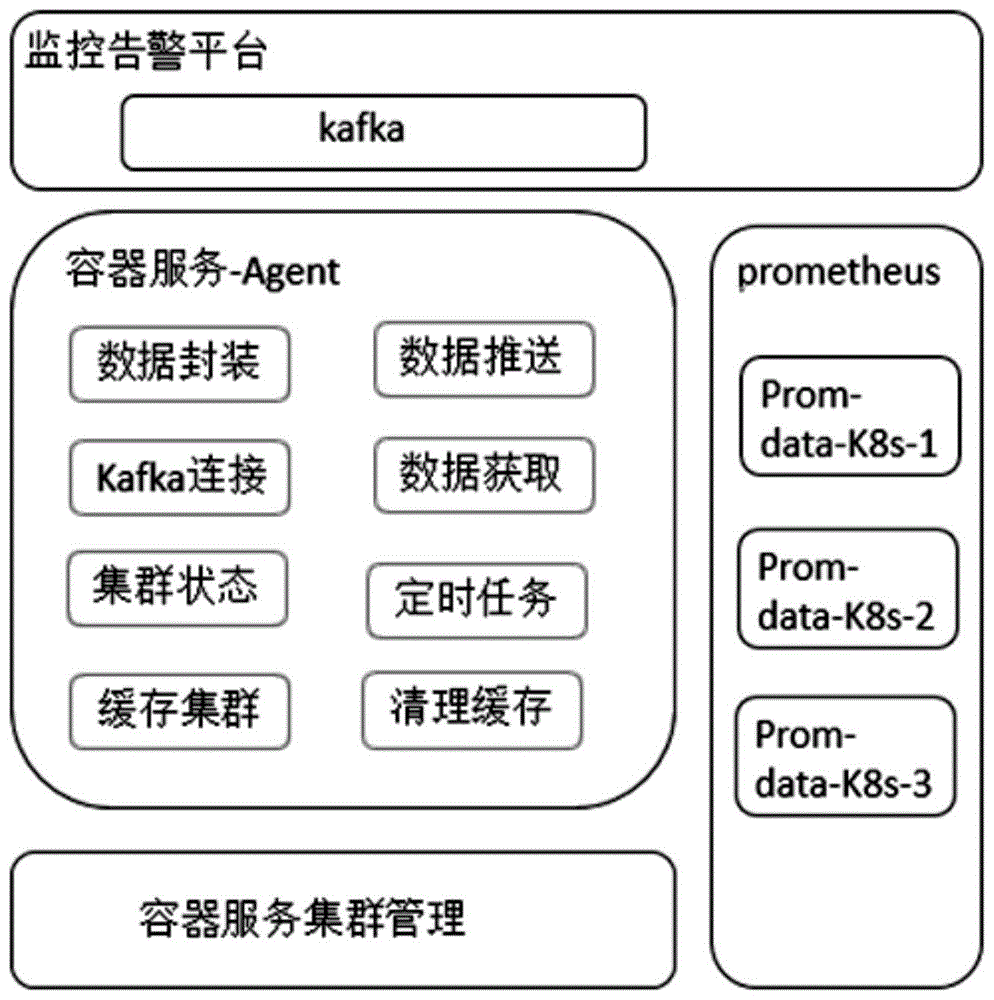
a)容器服务集群管理程序定时向云监控指标agent程序推送集群元数据;
b)云监控指标agent程序定时从prometheus获取集群内资源状态元数据;
c)通过云监控指标agent程序将收集到的数据制作为云监控指标;
d)通过kafka将制作出的云监控指标推送到监控告警平台;
e)对于数据量大的情况,部署云监控指标为statefulset,配置service为headless,容器服务管理程序将集群元数据平均分发到指定pod。
进一步的,
集群元数据的处理
a)提供api接口供容器服务管理程序定时调用,获取到所有被管理的集群元数据;
b)设置一个集群状态的缓存,每次接收到新的集群元数据后,将原有的缓存清空,将新的元数据添加到缓存中;
c)启动一个定时任务,每隔3分钟将缓存中的集群状态制作为可推送的云监控指标;
d)将制作成功的云监控指标推送到监控告警平台。
进一步的,
集群内资源状态元数据的处理
a)编写配置文件,将从prometheus中查询资源状况的语句promeql预先准备好,将不同的集群id作为模板参数,待实际使用时进行替换填充;
b)启动一个定时任务,每隔3分钟遍历获取缓存中的集群列表,将不同的集群id填充到配置文件中的查询语句中,生成所有集群所有资源的可执行promeql;
c)根据生成的promeql访问prometheus的api接口执行查询,获取到查询结果;
d)将查询结果制作为可推送的云监控指标;
e)将制作成功的云监控指标推送到监控告警平台;
f)对于数据量大的监控指标,采用多个协程的形式进行数据的处理。
进一步的,
无论是集群状态还是集群内的资源,都需要将获取到的元数据转换为监控平台指定的数据格式。
编写一个通用的函数,将两类元数据进行格式转换,转换成最终云监控指标需要的格式。
进一步的,
推送数据到监控告警平台
a)初始化kafka的producer实例,建立与kafka的consumer之间的连接;
b)将云监控指标放入到producer的value中推送到监控告警平台。
进一步的,
将云监控指标制作程序cks-agent做成docker镜像,部署为statefulset的形式,并配置对应的service为headless。
容器服务管理程序定时向cks-agent分发数据时,可以根据配置的不同service的headless,指定分发一部分数据到指定pod上。
本发明的有益效果是
通过使用本发明,可以很好的完成云监控指标的制作,并能根据配置文件中配置的不同资源类型,有选择的动态制作不同的云监控指标,并为监控告警平台提供了根据不同状态进行告警的能力。
附图说明
图1是本发明的工作框图;
图2是本发明的工作流程图;
图3是用户使用的流程示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的一种制作云监控指标的方法,包括:
1)使用定时任务推送和拉取云监控指标元数据
2)使用缓存保存集群元数据
3)使用配置文件模板动态配置不同集群的监控指标
4)云监控指标制作程序的高可用部署
具体内容如下:
一)设计方案
a)容器服务集群管理程序定时向云监控指标agent程序推送集群元数据。
b)云监控指标agent程序定时从prometheus获取集群内资源状态元数据。
c)通过云监控指标agent程序将收集到的数据制作为云监控指标。
d)通过kafka将制作出的云监控指标推送到监控告警平台。
e)对于数据量大的情况,部署云监控指标为statefulset,配置service为headless,容器服务管理程序将集群元数据平均分发到指定pod。
二)集群元数据
a)提供api接口供容器服务管理程序定时调用,可获取到所有被管理的集群元数据。
b)设置一个集群状态的缓存,每次接收到新的集群元数据后,将原有的缓存清空,将新的元数据添加到缓存中。
c)启动一个定时任务,每隔3分钟将缓存中的集群状态制作为可推送的云监控指标。
d)将制作成功的云监控指标推送到监控告警平台。
三)集群内的资源元数据
a)编写配置文件,将从prometheus中查询资源状况的语句promeql预先准备好,将不同的集群id作为模板参数,待实际使用时进行替换填充,这样做的好处是可以随时控制要监控的资源类型。
b)启动一个定时任务,每隔3分钟遍历获取缓存中的集群列表,将不同的集群id填充到配置文件中的查询语句中,生成所有集群所有资源的可执行promeql。
c)根据生成的promeql访问prometheus的api接口执行查询,获取到查询结果。
d)将查询结果制作为可推送的云监控指标。
e)将制作成功的云监控指标推送到监控告警平台。
f)对于数据量大的监控指标,采用多个协程的形式进行数据的处理。
四)云监控指标格式转换
a)无论是集群状态还是集群内的资源,都需要将获取到的元数据转换为监控平台指定的数据格式。
b)最终的云监控指标结构格式如下(go语言描述)
c)编写一个通用的函数,将两类元数据进行格式转换,转换成最终云监控指标需要的格式。
d)集群状态的最终云监控指标格式样例
五)推送到监控告警平台
e)初始化kafka的producer实例,建立与kafka的consumer之间的连接。
f)将云监控指标放入到producer的value中推送到监控告警平台。
六)云监控指标制作程序高可用
g)将云监控指标制作程序cks-agent做成docker镜像,部署为statefulset的形式,并配置对应的service为headless。
h)容器服务管理程序定时向cks-agent分发数据时,可以根据配置的不同service的headless,指定分发某一部分数据到指定pod上,这样可以避免数据量过大单个pod处理不过来的问题。
本发明的特点如下:
a)使用定时任务推送和拉取云监控指标元数据
b)使用缓存保存集群元数据
c)使用配置文件模板动态配置不同集群的监控指标
d)对外暴露api接口供接收集群元数据
e)不同的监控指标的promeql语句的不同写法
f)统一转换元数据为监控告警平台需要的格式
g)大量数据采用多个go协程的方式进行数据的获取与推送
h)采用kafka消息队列进行大量云监控指标的推送
i)云监控指标制作程序的高可用部署
通过使用本发明,能够根据prometheus监控到的kubernetes资源制作出需要告警的云监控指标,这些监控指标在后续可以通过kafka推送到监控平台用于告警。
以上所述仅为本发明的较佳实施例,仅用于说明本发明的技术方案,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所做的任何修改、等同替换、改进等,均包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!