基于并行搜索2D-3D匹配的视觉定位方法、系统、装置与流程
本发明属于定位
技术领域:
,具体涉及了基于并行搜索2d-3d匹配的视觉定位方法、系统、装置。
背景技术:
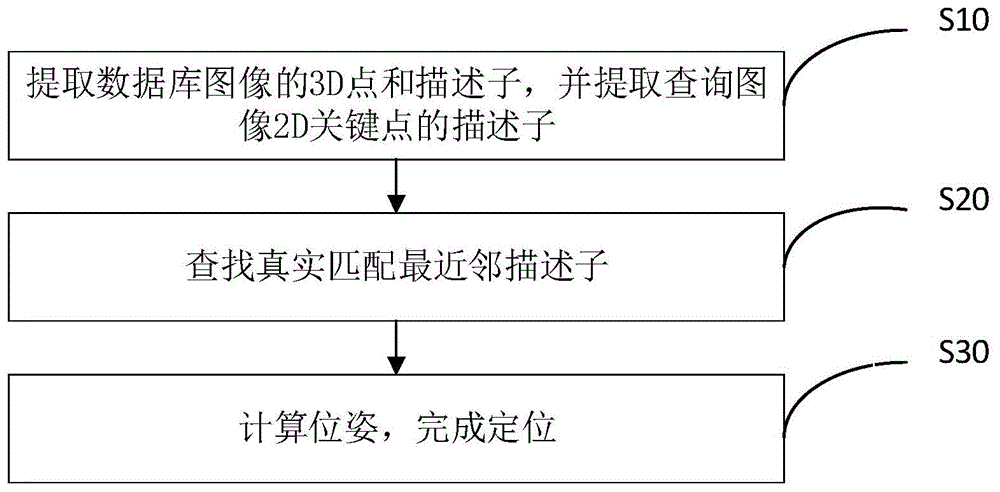
:单幅图像的视觉定位的任务是在一个已知三维模型的场景里估计出查询照片的6-dof相机位姿,在增强现实、虚拟现实、自动驾驶等领域有着广泛的应用。单幅图像定位方法可以分为端到端的方法和非端到端的方法。非端到端的方法又可分为基于图像检索的方法和基于2d-3d直接匹配的方法。端到端的方法通过训练网络模型直接回归相机的位姿。端到端的方法可以借助深度学习以及gpu的优势实现快速定位,但是泛化性能较差且在大范围场景下精度较差。基于图像检索的方法首先在数据库里查找与查询照片相似的照片,然后只在那些检索到的图像能看得到的3d点范围内搜索与2d查询特征匹配的3d点。传统方法通常要借助词袋模型来搜索相似照片。densevlad通过合成新的视角图像来检索与查询图像相似的图像。近年来出现了一些基于深度学习搜索相似图像的方法,如netvlad通过对整幅图像提取特征描述来检索相似图像。基于2d-3d匹配的方法首先将数据库中的3d点通过词汇树等方法进行聚类,然后建立查询图片中特征点与数据库中3d点的对应关系,最后通过ransac和pnp算法估算相机位姿。noahsnavely等人利用一些共视信息判断哪一部分3d点需要优先搜索。csl方法利用额外的信息,如imu等来辅助视觉定位。吴毅红等人利用随机树结构索引数据库里面的3d点,能够显著加快相机定位的速度。每种方法都有自己的优点。总体来讲,基于2d-3d直接匹配的方法在大视角变化的条件下精度较高,但是在光照变化剧烈的条件下鲁棒性不够强;基于图像检索的方法在光照变化剧烈的条件下鲁棒性较强但在大视角变化条件下精度较低。基于2d-3d直接匹配的定位方法能够成功定位视角比较大的图像,但是不能成功定位光照变化比较大的图像。基于图像检索的定位方法能够成功定位光照变化比较大的图像,但是不但能定位视角变化比较大的图像。技术实现要素:为了解决现有技术中的上述问题,即基于2d-3d直接匹配的视觉定位方法在光照变化剧烈的条件下鲁棒性不够强,基于图像检索的视觉方法在大视角变化条件下精度较低的问题,本发明的第一方面提供了基于并行搜索2d-3d匹配的视觉定位方法,所述定位方法包括以下步骤:步骤s10,根据数据库中的多个场景图像,通过预设的第一算法计算出场景3d点,并通过基于深度学习的描述子网络crbnet提取场景3d点的第一描述子和第二描述子;所述第一描述子为所述场景图像的二值描述子,所述第二描述子为所述场景图像的实值描述子;通过基于深度学习的描述子网络crbnet提取查询图像上2d关键点的查询描述子;所述查询描述子包含第三描述子和第四描述子;所述第三描述子为所述查询图像的二值描述子,所述第四描述子为所述查询图像的实值描述子;步骤s20,根据场景3d点、第一描述子和第二描述子,与第三描述子和第四描述子的匹配关系查找第六描述子;步骤s30,根据场景3d点与第六描述子的对应关系,通过预设的第二算法得到查询图像的相机位姿,通过相机位姿完成对查询图像的定位。在一些优选实施方式中,采用sfm算法计算数据库的场景图像中的3d点;在一些优选实施方式中,基于深度学习的描述子crbnet基于l2-net构建:先搭建l2-net卷积神经网络,在l2-net卷积神经网络中第一个卷积层后连续加入4个残差块,将步长为2的卷积层放在后两个残差块中,在最后一个卷积层前加入dropoutlayer,获得基于深度学习的描述子网络crbnet。所述基于深度学习的描述子网络crbnet引入设定的损失函数进行训练;所述设定的损失函数由相互匹配的描述子的欧氏距离三元损失项、二阶相似性正则项及加权汉明距离三元损失项构成:其中,表示损失函数;表示相互匹配描述子的欧氏距离三元损失函数;表示二阶相似性正则项;表示相互匹配描述子的加权汉明距离的三元损失函数;所述相互匹配的描述子可以来源于不同图像但都对应着空间中的同一个3d点。损失函数中相互匹配的描述子的欧氏距离三元损失项及加权汉明距离三元损失项为:其中,表示相互匹配的描述子,xi表示第i对匹配描述子的前一个,表示第i对匹配描述子的后一个,表示第i对匹配的描述子xi与之间的欧式距离,表示第i对匹配描述子的前一个描述子xi和第j对匹配描述子的后一个描述子之间的欧氏距离,表示第i对匹配描述子的后一个描述子和第j对匹配描述子的前一个描述子xj之间的欧氏距离。在一些优选的实施方式中,设定的损失函数中加权汉明损失项的加权汉明距离为:其中,表示相互匹配的描述子的加权汉明距离;k表示描述子的第k维;sign(a)表示取符号,如果a大于0,则sign(a)=1,否则sign(a)=0;xik表示第i对匹配描述子的前一个描述子的第k维,表示第i匹配描述子的后一个描述子的第k维。在一些优选的实施方式中,步骤s20包括:步骤s21,通过共视信息聚类将能够出现在同一幅场景图像中的场景3d点聚类生成第一聚类3d点;步骤s22,建立随机树,根据第一描述子和第三描述子训练随机树的结构,选取非叶子结点的二值测试,根据非叶子结点的二值测试结果将第一聚类3d点及第二描述子存放在随机树的叶子结点里;步骤s23,根据概率模型计算随机树叶子结点中最大概率包含查询图像的查询描述子的正确匹配的优先叶子结点;通过基于netvlad全局描述子的图像搜索方法得到数据库场景图像中有最大概率得到查询图像的查询描述子的正确匹配3d点的优先帧;所述优先叶子结点和优先帧中的3d点共同构成第五描述子;所述第五描述子为候选最近邻描述子;步骤s24,根据第四描述子、第五描述子通过预设的第三算法找出第六描述子;所述第六描述子为真实匹配最近邻描述子。在一些优选的实施方式中,步骤s23包括:步骤s231,定义所述查询描述子q与其最近邻p之间存在的扰动为△;所述△为根据图像关键点截取局部图片的时候,受光照角度和视角的变化引起的扰动;步骤s232,计算所述查询描述子q与其最近邻p处于同一个叶子结点ι中的概率:其中,m是随机树的深度,pd是查询描述子p的第d维元素值,τm(pd)是查询描述子p的第d维元素二值化后的值,ιm∈(0,1)是通往叶子结点ι路径上第m个非叶子结点测试的值,p(τm(pd)=ιm|pd=qd+δd)表示p的第d维元素二值化后的值等于ιm的概率;δd表示两个相匹配的局部图片之间的扰动;p(τ(p)=ι|p=q+δ)表示对应的叶子结点包含查询描述子的概率;步骤s233,所述概率模型中p(τ(p)=ι|p=q+δ)最大取值对应的叶子结点为最大概率包含查询描述子的正确匹配的叶子结点。在一些优选的实施方式中,“p的第d维元素二值化后的值等于ιk的概率”,其计算方法为:其中,δd~n(μd,σd)为通过带有批标准化层的神经网络转变的所述两个相匹配的局部图片之间的扰动δd,pd~n(μd+qd,σd)为p的第d维元素二值化后的值的正态分布近似。在一些优选的实施方式中,采用ratiotest算法寻找第六描述子,具体为:计算第五描述子中第四描述子的最近者及次近者与第四描述子的欧氏距离,最近者欧氏距离与次近者欧氏距离之间的比率处于预设的第一区间时的最近者视为第六描述子。在一些优选的实施方式中,通过ransac和pnp算法根据场景3d点和第五描述子的对应关系来计算查询图像的相机位姿,通过相机位姿完成对查询图像的定位。本发明的另一方面,提出了本发明的另一方面提供了基于并行搜索2d-3d匹配的视觉定位系统,该定位系统包括图像信息提取模块100、匹配模块200和最终定位模块300;所述图像信息提取模块100用于根据数据库中的多个场景图像,通过预设的第一算法计算出场景3d点,并通过基于深度学习的描述子网络crbnet提取场景3d点的第一描述子和第二描述子;所述第一描述子为所述场景图像的二值描述子,所述第二描述子为所述场景图像的实值描述子;还用于通过基于深度学习的描述子网络crbnet提取查询图像上2d关键点的查询描述子;所述查询描述子包含第三描述子和第四描述子;所述第三描述子为所述查询图像的二值描述子,所述第四描述子为所述查询图像的实值描述子;所述匹配模块200用于根据场景3d点、第一描述子和第二描述子,与第三描述子和第四描述子的匹配关系查找第六描述子;所述最终定位模块300根据场景3d点与第六描述子的对应关系,通过预设的第二算法得到查询图像的相机位姿,通过相机位姿完成对查询图像的定位。在一些优选的实施方式中,匹配模块200包括:聚类单元201,用于通过共视信息聚类将能够出现在同一幅场景图像中的场景3d点聚类生成第一聚类3d点;随机树存入单元202,用于建立随机树,根据第一描述子和第三描述子训练随机树的结构,选取非叶子结点的二值测试,根据非叶子结点的二值测试结果将第一聚类3d点及第二描述子存放在随机树的叶子结点里;查找最近邻单元203,用于根据概率模型计算随机树叶子结点中最大概率包含查询图像的查询描述子的正确匹配的优先叶子结点;还用于通过基于netvlad全局描述子的图像搜索方法得到数据库场景图像中有最大概率得到查询图像的查询描述子的正确匹配3d点的优先帧;所述优先叶子结点和优先帧中的3d点共同构成第五描述子;所述第五描述子为候选最近邻描述子;找寻匹配单元204,用于根据第四描述子、第五描述子通过预设的第三算法找出第六描述子;所述第六描述子为真实匹配最近邻描述子。本发明的第三方面,提出了一种存储装置,其中存储有多条程序,所述程序适于由处理器加载并执行以实现上述的基于并行搜索2d-3d匹配的视觉定位方法。本发明的第四方面,提出了一种处理装置,包括处理器、存储装置;所述处理器,适于执行各条程序;所述存储装置,适于存储多条程序;所述程序适于由处理器加载并执行以实现上述的基于并行搜索2d-3d匹配的视觉定位方法。本发明的有益效果:(1)本发明提出了基于深度学习的描述子网络crbnet同时具有二值和实值形式,可以根据不同条件和应用需求选择使用二值或实值,提高了定位方法的适用性。(2)本发明提出的损失函数使得crbnet与现有的描述子方法相比更为精确。(3)本发明提出的基于并行搜索视觉定位方法能够融合基于图像搜索和2d-3d直接匹配方法的优势,提高了视觉定位方法在大视角条件和光照变化条件下的定位精度和鲁棒性。附图说明通过阅读参照以下附图所作的对非限制性实施例所作的详细描述,本申请的其它特征、目的和优点将会变得更明显:图1是本发明基于并行搜索2d-3d匹配的视觉定位方法的流程示意图;图2是本发明基于并行搜索2d-3d匹配的视觉定位方法的原理示意图;图3是本发明基于并行搜索2d-3d匹配的视觉定位方法一种实施例的根据第一、第二、第三描述子的匹配关系查找第五描述子的流程示意图;图4是l2-net网络结构与本发明提出的crbnet描述子网络结构对比示意图;图5是本发明提出的crbnet描述子网络结构在brown数据集上的测试结果示意图;图6是本发明提出的crbnet描述子网络结构在hpatches数据集上的测试结果示意图;图7是本发明基于并行搜索2d-3d匹配的视觉定位方法一种实施例的在robocar数据集上的测试结果示意图;图8是本发明基于并行搜索2d-3d匹配的视觉定位方法一种实施例的在aachen数据集上的测试结果示意图;图9是本发明基于并行搜索2d-3d匹配的视觉定位方法一种实施例的速度评估结果示意图;图10是本发明基于并行搜索2d-3d匹配的视觉定位方法的定位效果实例。具体实施方式下面结合附图和实施例对本申请作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅用于解释相关发明,而非对该发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与有关发明相关的部分。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本申请。本发明提供基于并行搜索2d-3d匹配的视觉定位方法,本方法能够融合基于图像搜索和2d-3d直接匹配方法的优势,提高了视觉定位方法在大视角条件和光照变化条件下的定位精度和鲁棒性。基于图像检索的方法采用基于深度神经网络的描述子提取数据库中图像与查询图像的全局特征。然后计算数据库中图像与查询图像描述子之间的欧式距离。欧氏距离越小,图像就越相似。然后将在检索到的图像上看到的3d点作为局部描述子的候选最近邻。这种方法很依赖图像检索的结果,因此,当查询图像与数据库中图像有很大的视角变化,或者并不是同一个地方的图像但整体特征比较相似时,检索到的图像很可能不对,进而影响基于图像检索的定位精度。基于随机树的方法属于2d-3d直接匹配的定位方法。首先将3d点依据一定的规则聚类到叶子结点里,同一个叶子结点里的3d点能够被不同的数据库图像看到。所以通常来讲,这种方法对大视角变化更加鲁棒,然而,当光照变化比较剧烈时,即使同一个局部块图像表观上也会有很大的不同,所以这种情况下仅仅依赖局部描述子是不可靠的。为了更清晰地对本发明基于分析方法进行说明,下面结合图1对被发明第一实施例展开详述。本发明的基于并行搜索2d-3d匹配的视觉定位方法,该定位方法包括以下步骤:步骤s10,根据数据库中的多个场景图像,通过预设的第一算法计算出场景3d点,并通过基于深度学习的描述子网络crbnet提取场景3d点的第一描述子和第二描述子;所述第一描述子为所述场景图像的二值描述子,所述第二描述子为所述场景图像的实值描述子;通过基于深度学习的描述子网络crbnet提取查询图像上2d关键点的查询描述子;所述查询描述子包含第三描述子和第四描述子;所述第三描述子为所述查询图像的二值描述子,所述第四描述子为所述查询图像的实值描述子;步骤s20,根据场景3d点、第一描述子和第二描述子,与第三描述子和第四描述子的匹配关系查找第六描述子;步骤s30,根据场景3d点与第六描述子的对应关系,通过预设的第二算法得到查询图像的相机位姿,通过相机位姿完成对查询图像的定位。本发明提出的基于并行搜索视觉定位方法能够融合基于图像搜索和2d-3d直接匹配方法的优势,提高了视觉定位方法在大视角条件和光照变化条件下的定位精度和鲁棒性。为了更清晰地对本发明基于分析方法进行说明,下面结合图1图2对本发明方法实施例中各步骤展开详述。本发明第二实施例的基于并行搜索2d-3d匹配的视觉定位方法,包括步骤s10-步骤s30,各步骤详细描述如下:步骤s10,根据数据库中的多个场景图像,通过sfm算法计算出场景3d点,并通过基于深度学习的描述子网络crbnet提取场景3d点的第一描述子和第二描述子;第一描述子是场景3d点的二值描述子,第二描述子是场景3d点的实值描述子;并通过基于深度学习的描述子网络crbnet提取查询图像中的2d关键点的第三描述子和第四描述子;第三描述子是查询图像的二值描述子,第四描述子是查询图像的实值描述子。基于深度学习的描述子网络crbnet是基于l2-net网络结构修改的,如图4所示,为本发明提出的crbnet描述子网络结构与l2-net网络结构的对比示意图,l2-net网络结构如图4左边部分所示,l2-net网络结构里没有池化层(poolinglayer),用步长为2的卷积层(convolutionallayer)来实现下采样。除了最后一个卷积层,其他卷积层后面都有一个批标准化层(batchnormalization)。在最后一个卷积层前,采用了丢弃正则化(dropoutregularization)以防止过拟合。crbnet在l2-net的基础上加入了4个残差块,并且考虑到网络输入图像相对较小(32×32),将步长为2的卷积层放在了后两个残差块中。crbnet的网络结构示意图如图4右边部分所示。本发明提出的crbnet网络结构同时具有二值和实值形式,可以根据不同条件和应用需求选择使用二值或实值,提高了定位方法的适用性。本发明提出基于深度学习的描述子网络crbnet,其训练中采用的损失函数的如公式(1)所示:其中,表示损失函数;表示相互匹配描述子的欧氏距离三元损失函数;表示二阶相似性正则项;表示相互匹配描述子的加权汉明距离的三元损失函数;所述相互匹配的描述子可以来源于不同图像但都对应着空间中的同一个3d点。欧氏距离三元损失项及加权汉明距离三元损失项如公式(2)、(3)所示:其中,表示相互匹配的描述子,xi表示第i对匹配描述子的前一个,表示第i对匹配描述子的后一个,表示第i对匹配的描述子xi与之间的欧式距离,表示第i对匹配描述子的前一个描述子xi和第j对匹配描述子的后一个描述子之间的欧氏距离,表示第i对匹配描述子的后一个描述子和第j对匹配描述子的前一个描述子xj之间的欧氏距离。加权汉明距离如公式(4)所示:其中,表示相互匹配的描述子的加权汉明距离;k表示描述子的第k维;sign(a)表示取符号,如果a大于0,则sign(a)=1,否则sign(a)=0;xik表示第i对匹配描述子的前一个描述子的第k维,表示第i匹配描述子的后一个描述子的第k维。通过设计的网络架构和损失函数,在brown数据集以及hpatches数据集上分别对crbnet与现有的一些描述子方法进行对比,如图5和图6所示,分别为本发明提出的crbnet描述子网络结构在brown数据集和hpatches数据集上的测试结果示意图,从表中的测试结果可以看出,本发明crbnet与现有的描述子方法相比取得了很好的效果。步骤s20,根据场景3d点、第一描述子和第二描述子,与第三描述子和第四描述子的匹配关系查找第六描述子;如图3所示,为本发明基于并行搜索2d-3d匹配的视觉定位方法一种实施例的根据场景根据场景3d点、第一描述子和第二描述子,与第三描述子和第四描述子的匹配关系查找第六描述子流程示意图,具体包括:步骤s21,通过共视信息聚类将能够出现在同一幅场景图像中的场景3d点聚类生成第一聚类3d点;步骤s22,建立随机树,根据第一描述子和第三描述子训练随机树的结构,选取非叶子结点的二值测试,根据非叶子结点的二值测试结果将第一聚类3d点及第二描述子存放在随机树的叶子结点里;步骤s23,根据概率模型计算随机树叶子结点中最大概率包含查询图像的查询描述子的正确匹配的优先叶子结点;通过基于netvlad全局描述子的图像搜索方法得到数据库场景图像中有最大概率得到查询图像的查询描述子的正确匹配3d点的优先帧;所述优先叶子结点和优先帧中的3d点共同构成第五描述子;所述第五描述子为候选最近邻描述子;步骤s23具体包括:步骤s231,定义所述查询描述子q与其最近邻p之间存在的扰动为△;所述△为根据图像关键点截取局部图片的时候,受光照角度和视角的变化引起的扰动;步骤s232,计算所述查询描述子q与其最近邻p处于同一个叶子结点ι中的概率,如公式(5)所示:其中,m是随机树的深度,pd是查询描述子p的第d维元素值,τm(pd)是查询描述子p的第d维元素二值化后的值,ιm∈(0,1)是通往叶子结点ι路径上第m个非叶子结点测试的值,p(τm(pd)=ιm|pd=qd+δd)表示p的第d维元素二值化后的值等于ιm的概率;δd表示两个相匹配的局部图片之间的扰动;p(τ(p)=ι|p=q+δ)表示对应的叶子结点包含查询描述子的概率;步骤s233,所述概率模型中p(τ(p)=ι|p=q+δ)最大取值对应的叶子结点为最大概率包含查询描述子的正确匹配的叶子结点。要计算概率p(τm(pd)=ιm|od=qd+δd),需先求得δd的分布,由于数据库中一般包含描述子的数据量非常大,所以用正态分布可以很好的逼近这个扰动的真实分布,即:δd~n(μd,σd)。“p的第d维元素二值化后的值等于ιk的概率”,其计算方法如公式(6)所示:其中,δd~n(μd,σd)为通过带有批标准化层的神经网络转变的所述两个相匹配的局部图片之间的扰动δd,pd~n(μd+qd,σd)为p的第d维元素二值化后的值的正态分布近似。基于以上的分析,即可得出叶子结点包含查询描述子匹配的概率。步骤s24,根据第四描述子、第五描述子通过预设的第三算法找出第六描述子;第三算法为ratiotest算法,具体为计算第五描述子中第四描述子的最近者及次近者与第四描述子的欧氏距离,最近者欧氏距离与次近者欧氏距离之间的比率处于预设的第一区间时的最近者视为第六描述子。在一些实施方式中,第一区间通常的取值范围可以为0.6-0.8;所述第六描述子为真实匹配最近邻描述子。步骤s30,根据场景3d点与第六描述子的对应关系,通过预设的第二算法得到查询图像的相机位姿,通过相机位姿完成对查询图像的定位。第二算法为ransac和pnp算法,可根据查询图像生成查询图像的6dof位姿。如图7所示,为本发明基于并行搜索2d-3d匹配的视觉定位方法一种实施例的在robocar数据集上的测试结果示意图,第一列为各定位方法名称,rt_ap_ir+crbnet代表本发明方法,黑色加粗数据代表在各定位方法中效果最好,从表中的数据可以看出,本发明所提出的基于并行搜索的方法结果明显优于其他方法。如图8所示,为本发明基于并行搜索2d-3d匹配的视觉定位方法一种实施例的在aachen数据集上的测试结果示意图,对比了基于图像检索的方法、基于2d-3d直接匹配的方法以及本发明所提出的基于并行搜索的定位方法的效果,rt_ap+crbnet表示基于随机树的方法,ir+crbnet表示基于图像检索的方法,rt_ap_ir+crbnet表示本发明所提出的基于并行搜索的定位方法,rt_ap+hardnet表示基于随机树和hardnet描述子方法。可以看出本发明所提出的并行搜索方法明显好于其他方法,另外对比rt_ap_ir+crbnet与rt_ap+hardnet也可以看出,本发明所提出的crbnet相对于hardnet描述子,在定位任务中有更好的表现。同时对所提出的并行搜索方法的速度进行评估,主要统计每个查询描述子候选最近邻的个数,候选最近邻的个数意味着计算欧氏距离的次数,直接影响着定位的速度,如图9所示,为本发明基于并行搜索2d-3d匹配的视觉定位方法一种实施例的速度评估结果示意图,左边是基于随机树的方法,右边是基于图像检索的方法。基于图像检索的方法得到查询描述子的正确匹配,平均要计算3.6×104次欧氏距离,基于随机树的方法得到查询描述子的正确匹配大概需要计算770次欧式距离。基于随机树的方法计算欧氏距离的次数远远小于基于图像检索的方法所计算欧氏距离的次数。所以基于并行搜索的定位方法耗时仅仅略高于基于图像检索的方法。基于图像检索的方法采用基于深度神经网络的描述子提取数据库中图像与查询图像的全局特征。然后计算数据库中图像与查询图像描述子之间的欧式距离。欧氏距离越小,图像就越相似。然后将在检索到的图像上看到的3d点作为局部描述子的候选最近邻。这种方法很依赖图像检索的结果,因此,当查询图像与数据库中图像有很大的视角变化,或者并不是同一个地方的图像但整体特征比较相似时,检索到的图像很可能不对,进而影响基于图像检索的定位精度。基于随机树的方法属于2d-3d直接匹配的定位方法。首先将3d点依据一定的规则聚类到叶子结点里,同一个叶子结点里的3d点能够被不同的数据库图像看到。所以通常来讲,这种方法对大视角变化更加鲁棒,然而,当光照变化比较剧烈时,即使同一个局部块图像表观上也会有很大的不同,所以这种情况下仅仅依赖局部描述子是不可靠的。相反,全局描述子是一个不错的选择。基于图像检索和基于2d-3d直接匹配的定位方法的优点如下表所示:表1:基于随机树方法、图像检索方法以及并行搜索方法优点对比光照季节地方不同但总体特征相似视角模糊随机树方法√√图像检索方法√√√并行搜索方法√√√√√基于以上分析,我们提出了并行搜索特征匹配的视觉定位方法,这种方法能够融合基于图像搜索和2d-3d直接匹配方法的优势。同时,本发明提出一个能够同时训练实值和二值的基于学习的描述子,使得系统更加鲁棒。如图10所示,为本发明基于并行搜索2d-3d匹配的视觉定位方法的定位效果实例,本发明提出的定位方法能够在各种场景下精确定位图像。本发明的另一方面,提出了基于并行搜索2d-3d匹配的视觉定位系统,该视觉定位系统包括图像信息提取模块100、匹配模块200和最终定位模块300;所述图像信息提取模块100用于根据数据库中的多个场景图像,通过预设的第一算法计算出场景3d点,并通过基于深度学习的描述子网络crbnet提取场景3d点的第一描述子和第二描述子;所述第一描述子为所述场景图像的二值描述子,所述第二描述子为所述场景图像的实值描述子;还用于通过基于深度学习的描述子网络crbnet提取查询图像上2d关键点的查询描述子;所述查询描述子包含第三描述子和第四描述子;所述第三描述子为所述查询图像的二值描述子,所述第四描述子为所述查询图像的实值描述子;所述匹配模块200用于根据场景3d点、第一描述子和第二描述子,与第三描述子和第四描述子的匹配关系查找第六描述子;所述最终定位模块300根据场景3d点与第六描述子的对应关系,通过预设的第二算法得到查询图像的相机位姿,通过相机位姿完成对查询图像的定位。所属
技术领域:
的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的系统的具体工作过程及有关说明,可以参考前述方法实施例中的对应过程,在此不再赘述。需要说明的是,上述实施例提供的基于并行搜索2d-3d匹配的视觉定位系统,仅以上述各功能模块的划分进行举例说明,在实际应用中,可以根据需要而将上述功能分配由不同的功能模块来完成,即将本发明实施例中的模块或者步骤再分解或者组合,例如,上述实施例的模块可以合并为一个模块,也可以进一步拆分成多个子模块,以完成以上描述的全部或者部分功能。对于本发明实施例中涉及的模块、步骤的名称,仅仅是为了区分各个模块或者步骤,不视为对本发明的不当限定。本发明第三实施例的一种存储装置,其中存储有多条程序,所述程序适于由处理器加载并执行以实现上述的基于并行搜索2d-3d匹配的视觉定位方法。本发明第四实施例的一种处理装置,包括处理器、存储装置;处理器,适于执行各条程序;存储装置,适于存储多条程序;所述程序适于由处理器加载并执行以实现上述的基于并行搜索2d-3d匹配的视觉定位方法。所属
技术领域:
的技术人员可以清楚地了解到,为描述的方便和简洁,上述描述的存储装置、处理装置的具体工作过程及有关说明,可以参考前述方法实施例中的对应过程,在此不再赘述。本领域技术人员应该能够意识到,结合本文中所公开的实施例描述的各示例的模块、方法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,软件模块、方法步骤对应的程序可以置于随机存储器(ram)、内存、只读存储器(rom)、电可编程rom、电可擦除可编程rom、寄存器、硬盘、可移动磁盘、cd-rom、或
技术领域:
内所公知的任意其它形式的存储介质中。为了清楚地说明电子硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以电子硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。本领域技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。术语“第一”、“第二”等是用于区别类似的对象,而不是用于描述或表示特定的顺序或先后次序。术语“包括”或者任何其它类似用语旨在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备/装置不仅包括那些要素,而且还包括没有明确列出的其它要素,或者还包括这些过程、方法、物品或者设备/装置所固有的要素。至此,已经结合附图所示的优选实施方式描述了本发明的技术方案,但是,本领域技术人员容易理解的是,本发明的保护范围显然不局限于这些具体实施方式。在不偏离本发明的原理的前提下,本领域技术人员可以对相关技术特征做出等同的更改或替换,这些更改或替换之后的技术方案都将落入本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1