一种基于SSD-MobileNet的实时手势检测和识别方法及系统与流程
本发明涉及图像识别的技术领域,具体涉及一种基于ssd-mobilenet的实时手势检测和识别方法及系统。
背景技术:
随着目标检测技术的不断发展和深入,现代检测仪器精度的不断提升,各种先进的检测算法广泛应用于当下的智能设备中,其中手势检测和识别分析一直以来都是人机交互领域研究的重点。可以从不同的手部特征开始利用检测算法对手的表面纹理及外部姿态进行深入分析,达到检测和识别的目的。
目前,针对实时手势检测与识别相结合的研究在确保高精度的情况下往往是借助较高端的外部硬件设备实现,如leap公司制造的leapmotion体感控制器,微软推出的kinect体感周边外设,谷歌设计的projectsoli雷达芯片以及cyberglove系统公司提供的数据手套设备等,能够达到良好的识别速度和精度,但不具备普适性。15年mintol,zanuttighp.等人在exploitingsilhouettedescriptorsandsyntheticdataforhandgesturerecognition一文提出了一种实时手势识别方案,针对的是深度相机设备得到深度数据,从采集到的数据中提取出手部轮廓特征,然后输入到多类别支持向量机中,进行手势识别。
检测技术的完备随之而来的是检测类别的丰富和完善,越来越多手势数据集的开源,为手势的检测和识别任务提供了很好的数据基础。然而目前对手势数据的整理和利用不是很充分,在检测速度和检测精度上还存在不足,严重制约了实时手势检测和识别的工作效率。
技术实现要素:
本发明的目的在于克服现有技术中的缺点,提供一种基于ssd-mobilenet的实时手势检测和识别方法及系统,引入ssd-mobilenet和改进的cnn的手势识别模型相结合,具有提高手势检测和识别的工作效率的优点。
本发明的目的是通过以下技术方案来实现的:一种基于ssd-mobilenet的实时手势检测和识别方法,包括以下步骤:
s1:获取原始egohands视频数据集,所述原始egohands视频数据集包括多帧原始数据集图像,对多帧原始数据集图像进行扩充处理,建立扩充数据集,执行s2;
s2:建立ssd-mobilenet手部数据检测模型,所述ssd-mobilenet手部数据检测模型用于提取手势图像,所述ssd-mobilenet手部数据检测模型包括ssd网络及mobilenet网络,对ssd-mobilenet手部数据检测模型进行训练并优化,执行s3;
s3:使用ssd-mobilenet手部数据检测模型对自建的复杂背景下的数字手势数据集中的图像进行手势图像提取,获取手势识别数据集,执行s4;
s4:建立改进的cnn的手势识别模型,使用手势识别数据集训练并优化改进的cnn的手势识别模型,执行s5;
s5:获取待检测视频数据集,使用ssd-mobilenet手部数据检测模型对待检测视频数据集中的图像进行手势图像提取,使用改进的cnn的手势识别模型对手势图像进行手势识别,输出识别结果。
本发明的有益效果是,在进行实时检测之前,先建立ssd-mobilenet手部数据检测模型及改进的cnn的手势识别模型,训练及优化ssd-mobilenet手部数据检测模型及改进的cnn的手势识别模型。在实时检测时,接收实时视频数据,将实时视频数据中的帧图像处理成一定大小,ssd-mobilenet手部数据检测模型对实时视频数据进行手势提取,按照周期提取手势图并分类别保存,去除所有不完整和模糊的手势图片,将处理好的手势图按照一定大小进行缩放,统一尺寸。改进的cnn的手势识别模型识别手势图中的手势,测试过程中的帧率符合实时检测和识别的要求,达到提高手势检测和识别的工作效率的效果。
进一步,所述s1中对多帧原始数据集图像进行扩充处理具体包括,
对多帧原始数据集图像进行随机翻转和/或平移和/或剪裁和/或亮度调整和/或对比度调整和/或加噪声和/或高斯模糊,获得不同对比度的手势数据,建立扩充数据集。
采用上述进一步方案的有益效果是,对原始数据集中的图像进行随机翻转、平移、剪裁、亮度调整、对比度调整、加噪声、高斯模糊操作中的一种或多种,扩充多次,获得不同对比度的手势数据,减少了原始数据获取的工作量。
进一步,所述s2中对ssd-mobilenet手部数据检测模型进行训练并优化具体包括,
s231:按照比例,将扩充数据集分为训练集及测试集,抽取训练集中一部分验证集,执行s232;
s232:使用训练集训练ssd-mobilenet手部数据检测模型,使用验证集调节ssd-mobilenet手部数据检测模型参数,执行s233;
s233:使用测试集判断ssd-mobilenet手部数据检测模型是否完成优化,若否,执行s232,若是,执行s3。
采用上述进一步方案的有益效果是,使用训练集训练ssd-mobilenet手部数据检测模型,使用验证集调节ssd-mobilenet手部数据检测模型参数,测试集判断ssd-mobilenet手部数据检测模型的优化程度,有效降低了数据的偶然性。
进一步,所述s4具体包括以下步骤,
s41:建立改进的cnn的手势识别模型,执行s42;
s42:使用手势识别数据集训练并优化改进的cnn的手势识别模型,执行s42;
s43:获取改进的cnn的手势识别模型的优化评价参数,所述优化评价参数包括正类预测为正类结果参数tp、负类预测为正类结果参数fp、负类预测为正类结果参数fn、负类预测为负类结果参数tn,执行s44;
s44:根据优化评价参数计算改进的cnn的手势识别模型的评价指标,所述评价指标包括准确率、精确率及召回率,执行s45;
s45:根据改进的cnn的手势识别模型的评价指标判断改进的cnn的手势识别模型是否优化成功,若否,执行s42,若是执行s5。
进一步,所述改进的cnn的手势识别模型用ghost模块层代替传统卷积层,所述改进的cnn的手势识别模型的损失函数为categorical_crossentropy损失函数,优化函数为adam优化算法。
采用上述进一步方案的有益效果是,ghost模块层生成特征图操作简单高效,与传统卷积层相比,在同样精度下,计算量明显减少。adam优化算法是在自适应梯度算法adagrad和均方根传播rmsprop两种算法的基础上提出的,其优点是简单高效,梯度变换对参数影响小,适合梯度稀疏和很大噪声问题。
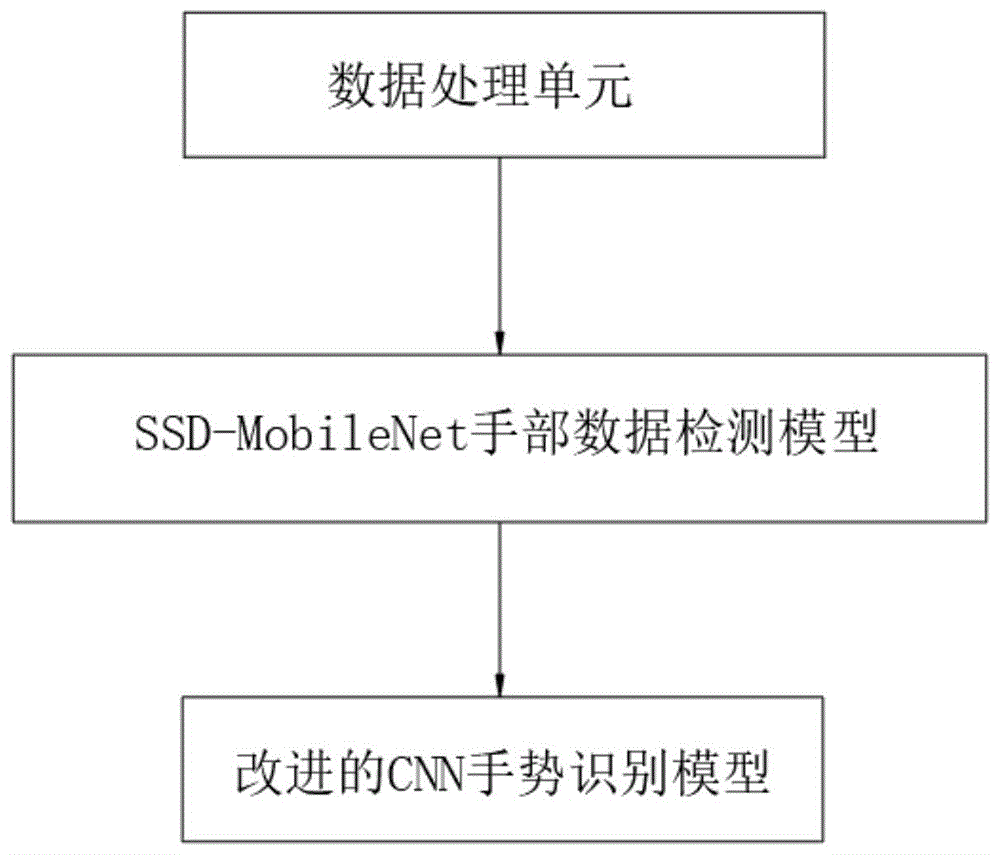
一种基于ssd-mobilenet的实时手势检测和识别系统,包括,
数据处理单元,用于接收原始egohands视频数据集,所述原始egohands视频数据集包括多帧原始数据集图像,还用于对多帧原始数据集图像进行扩充处理,建立扩充数据集;
ssd-mobilenet手部数据检测模型,包括ssd网络及mobilenet网络,用于手势图像提取,使用扩充数据集进行训练及优化,还用于对自建的复杂背景下的数字手势数据集中的图像进行手势图像提取,获取手势识别数据集,还用于对待测试视频数据集中的图像进行手势图像提取;
改进的cnn的手势识别模型,用于对手势图像进行手势识别,使用手势识别数据集进行训练及优化,还用于从待测试视频数据集中提取的手势图像进行手势识别,输出识别结果。
本发明的有益效果是,在进行实时检测之前,先建立ssd-mobilenet手部数据检测模型及改进的cnn的手势识别模型,训练及优化ssd-mobilenet手部数据检测模型及改进的cnn的手势识别模型。在实时检测时,数据处理单元接收实时视频数据,将实时视频数据中的帧图像处理成一定大小,ssd-mobilenet手部数据检测模型对实时视频数据进行手势提取,按照周期提取手势图并分类别保存,去除所有不完整和模糊的手势图片,将处理好的手势图按照一定大小进行缩放,统一尺寸。改进的cnn的手势识别模型识别手势图中的手势,达到提高手势检测和识别的工作效率的效果。
进一步,所述数据处理单元对多帧原始数据集图像进行随机翻转和/或平移和/或剪裁和/或亮度调整和/或对比度调整和/或加噪声和/或高斯模糊,获得不同对比度的手势数据,建立扩充数据集。
采用上述进一步方案的有益效果是,数据处理单元对原始数据集中的图像进行随机翻转、平移、剪裁、亮度调整、对比度调整、加噪声、高斯模糊操作中的一种或多种,扩充多次,获得不同对比度的手势数据,减少了原始数据获取的工作量。
进一步,所述数据处理处理单元还用于将扩充数据集分为训练集及测试集,抽取训练集中一部分验证集,所述ssd-mobilenet手部数据检测模型使用扩充数据集进行训练及优化具体包括以下步骤,
所述s2中对ssd-mobilenet手部数据检测模型进行训练并优化具体包括,
s31:按照比例,将扩充数据集分为训练集及测试集,抽取训练集中一部分验证集,执行s32;
s32:使用训练集训练ssd-mobilenet手部数据检测模型,使用验证集调节ssd-mobilenet手部数据检测模型参数,执行s33;
s33:使用测试集判断ssd-mobilenet手部数据检测模型是否完成优化,若否,执行s32,若是,完成优化。
采用上述进一步方案的有益效果是,使用训练集训练ssd-mobilenet手部数据检测模型,使用验证集调节ssd-mobilenet手部数据检测模型参数,测试集判断ssd-mobilenet手部数据检测模型的优化程度,有效降低了数据的偶然性。
进一步,所述改进的cnn的手势识别模型包括输入层、三层ghost模块层、三层池化层、两层全连接层及输出层,损失函数为categorical_crossentropy损失函数,优化函数为adam优化算法。
采用上述进一步方案的有益效果是,ghost模块层生成特征图操作简单高效,与传统卷积层相比,在同样精度下,计算量明显减少。adam优化算法是在自适应梯度算法adagrad和均方根传播rmsprop两种算法的基础上提出的,其优点是简单高效,梯度变换对参数影响小,适合梯度稀疏和很大噪声问题。
本发明中各个名词解释如下:
附图说明
图1为本发明的实施例1的结构示意图;
图2为本发明用于展示扩充数据集的部分图像的示意图;
图3为本发明用于展示ssd-mobilenet模型训练的map曲线图;
图4为本发明用于展示ssd-mobilenet手部数据检测模型提取的部分的手势图像的示意图;
图5为本发明用于展示改进的cnn的手势识别模型的结构示意图;
图6为本发明用于展示改进的cnn的手势识别模型训练和优化过程中accuracy变化的示意图;
图7为本发明用于展示改进的cnn的手势识别模型训练和优化过程中loss变化的示意图;
图8为本发明的实施例2的一种基于ssd-mobilenet的实时手势检测和识别方法的流程示意图。
具体实施方式
下面结合附图进一步详细描述本发明的技术方案,但本发明的保护范围不局限于以下。
实施例1
参照图1,一种基于ssd-mobilenet的实时手势检测和识别系统,包括,
数据处理单元,用于接收原始egohands视频数据集,原始egohands视频数据集包括多帧原始数据集图像,还用于对多帧原始数据集图像进行扩充处理,建立扩充数据集;
ssd-mobilenet手部数据检测模型,包括ssd网络及mobilenet网络,用于手势图像提取,使用扩充数据集进行训练及优化,还用于对扩充数据集中的图像进行手势图像提取,获取手势识别数据集,还用于对待测试视频数据集中的图像进行手势图像提取;
改进的cnn的手势识别模型,用ghost模块层代替传统卷积层,用于对手势图像进行手势识别,使用手势识别数据集进行训练及优化,还用于从待测试视频数据集中提取的手势图像进行手势识别,输出识别结果。
下面依次对每个部分进行详细说明。
本实施例中,数据处理单元接收的原始egohands视频数据集包括48段两人互动视频,48段视频中的每个视频都有100个带标签的帧,均为jpeg文件(720x1280px),总计4,800个帧,数据处理单元标记原始egohands视频数据集中所有带标签的帧。值得说明的是,为了提高训练速度,数据处理单元将原始egohands视频数据集中所有带标签的帧处理成300*300px,标签大小按比例缩小。
数据处理单元包括imgaug数据增强库,使用imgaug数据增强库中的flipud,fliplr,multiply,additivegaussiannoise,gaussianblur等离线数据增强工具对原始egohands视频数据集进行扩充。
参照图2,对带标签的帧进行随机翻转和/或平移和/或剪裁和/或亮度调整和/或对比度调整和/或加噪声和/或高斯模糊,扩充两次,获得不同对比度的手势数据,建立扩充数据集,扩充数据集包含9564张图片。得到扩充数据集后,以9:1的比例将扩充数据集划分训练集和测试集。其中训练集包括8608张图片,测试集包括956张图片,抽取训练集中一部分验证集。其中训练集用于训练模型,验证集用于调节模型参数,而测试集只用来衡量模型的好坏,有效降低了数据的偶然性。
ssd-mobilenet手部数据检测模型,包括ssd网络及mobilenet网络。其中,mobilenet网络模型的优势是使用深度可分离卷积将标准卷积核分解成深度卷积核和点卷积核,减少计算量。
假设卷积核大小为dk*dk,输入特征图的大小为df*df,通道数为m,输出特征图的大小为dg*dg,通道数为n,则与标准卷积核的计算量的比值为:
mobilenet网络引入宽度乘数α和分辨率乘数β后总的计算量为:
dk·dk·αm·βdf·βdf+αm·αn·βdf·βdf。
宽度乘数α和分辨率乘数β也影响着ssd-mobilenet手部数据检测模型的准确度、参数量以及参数的计算量。
ssd网络的损失函数计算由定位损失和分类损失两个部分组成,总的损失函数表达式为:
其中,n为所有匹配到真实框的defaultbox数目,lconf为置信损失,lloc为定位损失。
参照图3,ssd-mobilenet手部数据检测模型的训练过程如下,
s1:修改label_map.pbtxt文件内容,检测类别为1,name为hand;
s2:ssd-mobilenet手部数据检测模型配置文件选择ssd_mobilenet_v1_coco.config文件,修改检测类别数,训练集和测试集的tfrecords地址以及config文件的位置;
s3:开始训练,学习率设置为0.004,迭代步数设置为180000次,使用tensorboard进行监测,得到训练过程图的map;
s4:将完成训练后的ssd-mobilenet手部数据检测模型导出,生成frozen_inference_graph.pb文件。
参照图4,使用训练后的ssd-mobilenet手部数据检测模型对原始egohands视频数据集进行手势提取,建立手势识别原始数据集。手势识别原始数据集包含六种不同的手势,每种手势包含十段左右15s~20s的手势视频。ssd-mobilenet手部数据检测模型对手势识别数据集按照每5帧为一个周期提取手势图并分类别保存,去除所有不完整和模糊的手势图片,将处理好的数据图按照60*60px大小进行缩放,统一尺寸,建立手势识别数据集。手势识别数据集将得到的手势数据分成六种类别,标签分别为“fist”、“one”、“two”、“three”、“four”、“five”,每种手势的数据量在3000张左右,取总数据集的85%作为训练集,训练集包括15471张图片,测试集包括2731张图片。
参照图5,改进的cnn的手势识别模型包括输入层、三层ghost模块层、三层池化层、两层全连接层及输出层,具体结构如下:
输入层,手势图片的输入大小缩放成60*60px,通道数为3;
ghost模块层,使用32个3*3大小的卷积核对输入图像进行卷积和深度卷积操作,填充方式是‘same’,用0填充,输出大小为60*60*32;
池化层,对得到的特征图进行核大小为2*2的最大池化操作,输出大小为30*30*32;
ghost模块层,使用64个3*3大小的卷积核对输入的特征图进行卷积和深度卷积操作,填充方式是‘same’,用0填充,输出大小为30*30*64;
池化层,对得到的特征图进行核大小为2*2的最大池化操作,输出大小为15*15*64;
ghost模块层,使用128个3*3大小的卷积核对输入的特征图进行卷积和深度卷积操作,填充方式是‘same’,用0填充,输出大小为15*15*128;
池化层,对得到的特征图进行核大小为2*2的最大池化操作,输出大小为7*7*128;
全连接层,将7*7*128的特征图展开成6272维的向量,节点个数设为64;
全连接层,输入的节点数为64,输出节点数为64;
输出层,输入节点数为64,输出节点数为6,有六个标签。
用ghost模块层代替传统卷积层来提取图像特征,生成中间特征图,优化传统卷积层在计算特征图存在的大量冗余,减少计算成本。ghost模块将传统的卷积操作分成两步实现,首先用卷积生成通道数较少的特征图,再用深度卷积生成特征图,两组特征图进行拼接得到最终输出特征图。ghost模块使用一个恒等映射和n(s-1)个线性运算,其中n为卷积核数量,s为幻影特征图数量。每个线性运算的内核大小为d*d,在实验中选择内核大小为3*3来实现。ghost模块层生成特征图操作简单高效,和传统卷积层相比,在同样精度下,计算量明显减少。
改进的cnn的手势识别模型的一次训练所选取的样本数batchsize设置为32,学习率lr设为0.001,迭代次数epoch设为31,损失函数选择categorical_crossentropy损失函数,其中优化算法选择adam优化算法。
adam优化算法是在自适应梯度算法adagrad和均方根传播rmsprop两种算法的基础上提出的,其优点是简单高效,梯度变换对参数影响小,适合梯度稀疏和很大噪声问题。优化算法使用的计算函数如下:
vdw=β1vdw+(1-β1)dw
vdb=β1vdb+(1-β1)db
sdw=β2sdw+(1-β2)dw2
sdb=β2sdb+(1-β2)db2
其中,t为迭代次数,β1是指数衰减率,控制动量和当前梯度的权重分配,通常将β1设为0.9,β2则是控制梯度平方的影响,通常将β2设为0.999,默认参数更新的学习率α为0.001,vdw和vdb是损失函数迭代过程中用指数加权平均累积的梯度动量;w是权重,b是偏置;dw和db是损失函数反向传播求得的梯度;sdw和sdb是损失函数迭代过程中累积的梯度平方动量;
参照图6、7,本实施例中,改进的cnn的手势识别模型经过31个epoch训练后,训练和测试的准确率稳定在99%左右,loss值降到0.04左右,完成训练及优化。
在实时检测时,数据处理单元接收实时视频数据,将实时视频数据中的帧图像处理成300*300px,ssd-mobilenet手部数据检测模型对实时视频数据进行手势提取,按照每5帧为一个周期提取手势图并分类别保存,去除所有不完整和模糊的手势图片,将处理好的手势图按照60*60px大小进行缩放,统一尺寸。改进的cnn的手势识别模型识别手势图中的手势,测试过程中的帧率符合实时检测和识别的要求,符合实时检测和识别的要求,且识别效果良好。针对复杂背景下的数字手势能够做到准确的识别在人机交互领域有着重要的意义。根据用户的使用习惯和操作自然便捷性,可以给不同手势预先设定指令内容,利用手势动作对不同设备进行控制,拓宽交互体验空间和范围。
实施例2
参照图8,一种基于ssd-mobilenet的实时手势检测和识别方法,包括以下步骤:
s1:获取原始egohands视频数据集,原始egohands视频数据集包括多帧原始数据集图像,对多帧原始数据集图像进行扩充处理,建立扩充数据集,执行s2;
s2:建立ssd-mobilenet手部数据检测模型,ssd-mobilenet手部数据检测模型用于提取手势图像,ssd-mobilenet手部数据检测模型包括ssd网络及mobilenet网络,对ssd-mobilenet手部数据检测模型进行训练并优化,执行s3;
s3:使用ssd-mobilenet手部数据检测模型对自建的复杂背景下的数字手势数据集中的图像进行手势图像提取,获取手势识别数据集,执行s4;
s4:建立改进的cnn的手势识别模型,用ghost模块层代替传统卷积层,使用手势识别数据集训练并优化改进的cnn的手势识别模型,执行s5;
s5:获取待检测视频数据集,使用ssd-mobilenet手部数据检测模型对待检测视频数据集中的图像进行手势图像提取,使用改进的cnn的手势识别模型对手势图像进行手势识别,输出识别结果。
下面依次对每个步骤进行详细说明。
s1:获取原始egohands视频数据集,原始egohands视频数据集包括多帧原始数据集图像,对多帧原始数据集图像进行扩充处理,建立扩充数据集,执行s2。
原始egohands视频数据集包括48段两人互动视频,48段视频中的每个视频都有100个带标签的帧,均为jpeg文件(720x1280px),总计4,800个帧,数据处理单元标记原始egohands视频数据集中所有带标签的帧。值得说明的是,为了提高训练速度,先将原始egohands视频数据集中所有带标签的帧处理成300*300px,标签大小按比例缩小。
s1中对多帧原始数据集图像进行扩充处理具体包括,
参照图2,对多帧原始数据集图像进行随机翻转和/或平移和/或剪裁和/或亮度调整和/或对比度调整和/或加噪声和/或高斯模糊,扩充两次,获得不同对比度的手势数据,建立扩充数据集。扩充数据集包含9564张图片,得到扩充数据集后,以9:1的比例将扩充数据集划分训练集和测试集。其中训练集包括8608张图片,测试集包括956张图片,抽取训练集中一部分验证集。其中训练集用于训练模型,验证集用于调节模型参数,而测试集只用来衡量模型的好坏,有效降低了数据的偶然性。
s2:建立ssd-mobilenet手部数据检测模型,ssd-mobilenet手部数据检测模型用于提取手势图像,ssd-mobilenet手部数据检测模型包括ssd网络及mobilenet网络,对ssd-mobilenet手部数据检测模型进行训练并优化,执行s3。
ssd-mobilenet手部数据检测模型,包括ssd网络及mobilenet网络。其中,mobilenet网络模型的优势是使用深度可分离卷积将标准卷积核分解成深度卷积核和点卷积核,减少计算量。
假设卷积核大小为dk*dk,输入特征图的大小为df*df,通道数为m,输出特征图的大小为dg*dg,通道数为n,则与标准卷积核的计算量的比值为:
mobilenet网络引入宽度乘数α和分辨率乘数β后总的计算量为:
dk·dk·αm·βdf·βdf+αm·αn·βdf·βdf。
宽度乘数α和分辨率乘数β也影响着ssd-mobilenet手部数据检测模型的准确度、参数量以及参数的计算量。
ssd网络的损失函数计算由定位损失和分类损失两个部分组成,总的损失函数表达式为:
其中,n为所有匹配到真实框的defaultbox数目,lconf为置信损失,lloc为定位损失。
参照图3,ssd-mobilenet手部数据检测模型的训练过程如下,
s21:修改label_map.pbtxt文件内容,检测类别为1,name为hand;
s22:ssd-mobilenet手部数据检测模型配置文件选择ssd_mobilenet_v1_coco.config文件,修改检测类别数,训练集和测试集的tfrecords地址以及config文件的位置;
s23:开始训练,学习率设置为0.004,迭代步数设置为180000次,使用tensorboard进行监测,得到训练过程图的map;
s23具体包括以下步骤;
s231:以9:1的比例将扩充数据集划分训练集和测试集,其中训练集包括8608张图片,测试集包括956张图片,抽取训练集中一部分验证集,执行s232;
s232:使用训练集训练ssd-mobilenet手部数据检测模型,使用验证集调节ssd-mobilenet手部数据检测模型参数,执行s233;
s233:使用测试集判断ssd-mobilenet手部数据检测模型是否完成优化,即,通过ssd-mobilenet手部数据检测模型进行测试集的手势图像提取,计算正确率,根据正确率判断ssd-mobilenet手部数据检测模型是否完成优化,若否,执行s232,若是,执行s24;
s24:将完成训练后的ssd-mobilenet手部数据检测模型导出,生成frozen_inference_graph.pb文件。
s3:使用ssd-mobilenet手部数据检测模型对自建的复杂背景下的数字手势数据集中的图像进行手势图像提取,获取手势识别数据集,执行s4。
参照图4,使用训练后的ssd-mobilenet手部数据检测模型对原始egohands视频数据集进行手势提取,建立手势识别原始数据集。手势识别原始数据集包含六种不同的手势,每种手势包含十段左右15s~20s的手势视频。ssd-mobilenet手部数据检测模型对手势识别数据集按照每5帧为一个周期提取手势图并分类别保存,去除所有不完整和模糊的手势图片,将处理好的数据图按照60*60px大小进行缩放,统一尺寸,建立手势识别数据集。手势识别数据集将得到的手势数据分成六种类别,标签分别为“fist”、“one”、“two”、“three”、“four”、“five”,每种手势的数据量在3000张左右。
s4:建立改进的cnn的手势识别模型,用ghost模块层代替传统卷积层,使用手势识别数据集训练并优化改进的cnn的手势识别模型,执行s5。
参照图5,改进的cnn的手势识别模型包括输入层、三层ghost模块层、三层池化层、两层全连接层及输出层,具体结构如下:
输入层,手势图片的输入大小缩放成60*60px,通道数为3;
ghost模块层,使用32个3*3大小的卷积核对输入图像进行卷积和深度卷积操作,填充方式是‘same’,用0填充,输出大小为60*60*32;
池化层,对得到的特征图进行核大小为2*2的最大池化操作,输出大小为30*30*32;
ghost模块层,使用64个3*3大小的卷积核对输入的特征图进行卷积和深度卷积操作,填充方式是‘same’,用0填充,输出大小为30*30*64;
池化层,对得到的特征图进行核大小为2*2的最大池化操作,输出大小为15*15*64;
ghost模块层,使用128个3*3大小的卷积核对输入的特征图进行卷积和深度卷积操作,填充方式是‘same’,用0填充,输出大小为15*15*128;
池化层,对得到的特征图进行核大小为2*2的最大池化操作,输出大小为7*7*128;
全连接层,将7*7*128的特征图展开成6272维的向量,节点个数设为64;
全连接层,输入的节点数为64,输出节点数为64;
输出层,输入节点数为64,输出节点数为6,有六个标签。
用ghost模块层代替传统卷积层来提取图像特征,生成中间特征图,优化传统卷积层在计算特征图存在的大量冗余,减少计算成本。ghost模块将传统的卷积操作分成两步实现,首先用卷积生成通道数较少的特征图,再用深度卷积生成特征图,两组特征图进行拼接得到最终输出特征图。ghost模块使用一个恒等映射和n(s-1)个线性运算,其中n为卷积核数量,s为幻影特征图数量。每个线性运算的内核大小为d*d,在实验中选择内核大小为3*3来实现。ghost模块层生成特征图操作简单高效,和传统卷积层相比,在同样精度下,计算量明显减少。
改进的cnn的手势识别模型的一次训练所选取的样本数batchsize设置为32,学习率lr设为0.001,迭代次数epoch设为31,损失函数选择categorical_crossentropy损失函数,其中优化算法选择adam优化算法。
adam优化算法是在自适应梯度算法adagrad和均方根传播rmsprop两种算法的基础上提出的,其优点是简单高效,梯度变换对参数影响小,适合梯度稀疏和很大噪声问题。优化算法使用的计算函数如下:
vdw=β1vdw+(1-β1)dw
vdb=β1vdb+(1-β1)db
sdw=β2sdw+(1-β2)dw2
sdb=β2sdb+(1-β2)db2
其中,t为迭代次数,β1是指数衰减率,控制动量和当前梯度的权重分配,通常将β1设为0.9,β2则是控制梯度平方的影响,通常将β2设为0.999,默认参数更新的学习率α为0.001,vdw和vdb是损失函数迭代过程中用指数加权平均累积的梯度动量;w是权重,b是偏置;dw和db是损失函数反向传播求得的梯度;sdw和sdb是损失函数迭代过程中累积的梯度平方动量;
s4具体包括以下步骤,
s41:建立改进的cnn的手势识别模型,执行s42;
s42:使用手势识别数据集训练并优化改进的cnn的手势识别模型,执行s42;
s43:获取改进的cnn的手势识别模型的优化评价参数,优化评价参数包括正类预测为正类结果参数tp、负类预测为正类结果参数fp、负类预测为正类结果参数fn、负类预测为负类结果参数tn,执行s44;
s44:根据优化评价参数计算改进的cnn的手势识别模型的评价指标,评价指标包括准确率、精确率及召回率,执行s45;
值得说明的是,准确率accuracy用于衡量预测正确的概率;
accuracy=(tp+tn)/(tp+fp+fn+tn)
精确率precision衡量预测为正类中真正的正类的概率:
precision=tp/(tp+fp)
召回率recall衡量在正类中正类预测正确的概率:
recall=tp/(tp+fn);
s45:根据改进的cnn的手势识别模型的评价指标判断改进的cnn的手势识别模型是否优化成功,若否,执行s42,若是执行s5
参照图6、7,本实施例中,改进的cnn的手势识别模型经过31个epoch训练后,训练和测试的准确率稳定在99%左右,loss值降到0.04左右,完成训练及优化。
s5:获取待检测视频数据集,使用ssd-mobilenet手部数据检测模型对待检测视频数据集中的图像进行手势图像提取,使用改进的cnn的手势识别模型对手势图像进行手势识别,输出识别结果。
在实时检测时,接收实时视频数据,将实时视频数据中的帧图像处理成300*300px,ssd-mobilenet手部数据检测模型对实时视频数据进行手势提取,按照每5帧为一个周期提取手势图并分类别保存,去除所有不完整和模糊的手势图片,将处理好的手势图按照60*60px大小进行缩放,统一尺寸。改进的cnn的手势识别模型识别手势图中的手势,测试过程中的帧率符合实时检测和识别的要求,符合实时检测和识别的要求,且识别效果良好。针对复杂背景下的数字手势能够做到准确的识别在人机交互领域有着重要的意义。根据用户的使用习惯和操作自然便捷性,可以给不同手势预先设定指令内容,利用手势动作对不同设备进行控制,拓宽交互体验空间和范围。
值得说明的是,经过与传统卷积网络结构进行对比识别测试,本发明的识别模型在相同精度的条件下,模型参数大小减少10%左右,参数的冗余计算明显减少。利用rgb摄像头进行实时手势检测和识别的实验中,在复杂背景和光照下,本发明的识别模型正确识别出手势的正确率在92%左右,每种手势的置信度高于98%。用传统人工提取手势特征加svm分类器模型做对比实验,本发明的识别模型测试识别正确率在92%左右,传统人工提取手势特征加svm分类器模型测试识别正确率在90%左右,本发明的识别模型测试识别准确度较高,具有较强的鲁棒性和泛化能力。
以上仅是本发明的优选实施方式,应当理解本发明并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本发明的精神和范围,则都应在本发明所附权利要求的保护。
- 还没有人留言评论。精彩留言会获得点赞!