非概率混合可靠度指数的去嵌套分析方法与流程
本发明属于结构工程可靠性领域,特别是涉及非概率变量和传统概率变量混合情况下的结构可靠性分析技术,非概率混合可靠度指数的去嵌套分析方法。
技术背景
基于传统概率模型建立结构可靠性模型,在此基础上进行可靠性分析和优化的方法已经比较成熟。大样本数据是获取不确定变量的精确分布的前提,但实际工程中无论是从成本上还是从时间上,要获取所有不确定性变量的大量样本数据都是不可能的。考虑到这种情况,研究人员结合传统概率理论,提出了多种非概率模型,用以描述影响结构可靠性的认知不确变量。在利用传统的概率模型和非概率模型建立结构的非概率混合可靠度模型后,需要进行非概率模型与概率模型相混合的结构可靠性分析。
p-box理论作为一种新型的非概率模型理论,通过一个累积分布函数的上下限包络的概率盒描述认知确定变量。无论是未知不确定变量的分布形式或已知变量的分布形式,p-box均可对认知不确定变量进行描述。此外,p-box理论对其他常见的非概率理论具有良好的包容性,即其他非概率模型在一定程度上可以转化到p-box模型上,因此可以采用p-box理论建立更广泛意义的非概率模型,用于含有认知不确定变量的结构可靠性分析。
目前大部分非概率混合可靠度指数分析方法都需要建立双层嵌套的优化模型,其外层为传统的结构可靠性优化模型,而内层为以认知不确定变量为优化向量的结构功能函数极限值的优化模型。这种嵌套式的优化结构,由于存在内层结构,需要大量调用结构的功能函数,计算效率很低。
技术实现要素:
本发明的目的是提供一种基于函数近似模型的非概率混合可靠度指数的去嵌套分析方法,它包括:
步骤一、确定结构的功能函数与变量:
1.1根据设计和分析需求,确定影响结构可靠性的变量,包含n个随机变量x=(x1,x2,…,xn)和m个p-box变量y=(y1,y2,…,ym);
1.2利用力学理论或者有限元仿真方法途径获取所需分析结构的功能函数g(x,y);
步骤二、结构功能函数变量空间的转换:
2.1步骤一所得到的结构功能函数g(x,y),通过概率转换,ux=φ-1(fx(x))和uy=φ-1(fy(y)),可以得到标准正态空间下结构的功能函数g(ux,uy),即g(ux,uy)=g(x,y);
其中:fx(x)为随机变量x的累积分布函数,fy(y)为p-box变量y的累积分布函数,φ-1表示为标准正态分布反函数;
2.2初始化参数(1),s=1,
其中,s用于记录外层迭代次数,
2.3变量转换,标准正态空间的变量u=(ux,uy)通过概率转换
步骤三、利用线性近似模型与两点自适应模型对功能函数进行近似:
3.1在任意点(x,y),利用线性近似方法,将结构功能函数g(x,y)近似表示为关于p-box变量y的近似表达式,即
其中j=1,2,3,…,m,
3.2根据非线性指数rs,在点
其中:
而且,i=1,2,3,…,n,xi∈x,xi,s∈xs-1,
3.3组合3.1的线性近似和3.2的两点自适应非线性近似的模型,近似表示结构的功能函数,有
3.4区间理论近似获取功能函数在任意点(x,y)处响应的上下限,具体有:
下限:
上限:
步骤四、利用hl-rf方法进行内层迭代:
4.1初始化参数(2),参数(2)为k,
其中,k用于记录内层迭代次数,
4.2迭代计算获取当前非线性指数rs的结构可靠度指数的上(下)限
1)结合hl-rf方法获取在外层第s次迭代中,内层第k次迭代结构的可靠度指数的上(下)限
其中,
2)收敛条件(1)设定为
3)判断是否符合收敛条件(1);如果符合收敛条件(1),则获取当前非线性指数rs的最优的
4.3设置收敛条件(2),当s≥2时,
如果不符合或者s=1时,则进行下一步;
进行外层迭代参数的更新:
4.4通过步骤四中4.3所计算得到的
4.5更新迭代次数s=s+1;
4.6对非线性指数rs进行更新,从而获取进行第s次迭代时近似模型的相关参数,更新的优化公式为:
并回到步骤三开始下一轮迭代计算;
步骤五、判别符号并获取最终可靠度指数β∈[βl,βr]与βr(l)对应的最大可能失效点
5.1利用公式βr(l)=sgn(gr(l)(0,0))βr(l)=sgn(gr(l)(μx,μy))βr(l)对所获得非概率混合可靠度指数βr(l)进行正负号的辨别,获取最终的βr(l);其中sgn(·)表示为符号函数,当输入值为正数时为1,输入值为负数时为-1,(μx,μy)表示为在功能函数在原始空间的变量的均值点;
5.2综合步骤三以及5.1所得结果,最终获取所分析结构的非概率混合可靠度指数β∈[βl,βr]与非概率混合可靠度指数上(下)限βr(l)对应的最大可能失效点
本发明提供了非概率混合可靠度指数的去嵌套分析方法,它包括:1、确定结构的功能函数与变量,2、结构功能函数变量空间的转换,3、利用线性近似模型与两点自适应模型对功能函数进行近似,4、利用hl-rf方法进行内层迭代和进行外层迭代参数的更新,5、利用hl-rf方法进行内层迭代和进行外层迭代参数的更新。
相比于传统的嵌套式方法,本发明所提方法有以下的显著优点:
1、本发明所提方法的迭代收敛速度相比传统一阶可靠性方法有较大提高:采用两点自适应非线性近似模型构造近似函数,计算的收敛速度不再局限于传统一阶可靠性方法的线性近似精度;
2、本发明所提方法高效减少分析计算所需的资源与时间:通过函数近似方法近似获取极限状态函数的响应极值,无需进行嵌套的函数响应值的极值分析过程,每一次迭代步的主要工作量只是通过少数几次真实函数的计算实现,有效减少了计算所需的资源和时间;
3、本发明所提方法在减少函数调用次数的同时保证了计算精度。
附图说明
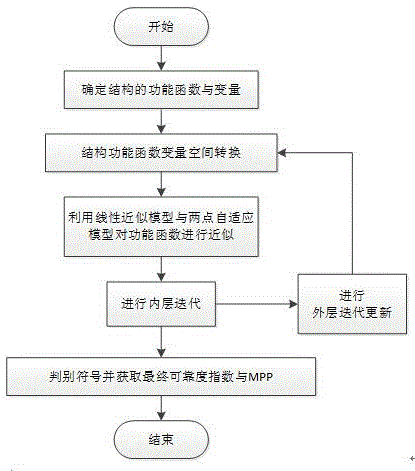
图1是本发明的非概率混合可靠度指数的去嵌套分析方法流程简图;
图2是本发明的非概率混合可靠度指数的去嵌套分析方法计算流程图;
图3是p-box变量的累积概率分布函数示意图;
图4是非概率混合极限状态函数曲面的示意图;
图5是实施例中的需要分析结构的示意图;
图6是实施例中采用本发明所提方法与传统的嵌套方法的迭代收敛图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
如图1到图3所示,本发明的基于函数近似模型的非概率混合可靠度指数的去嵌套分析方法,主要包括以下步骤:
步骤一、确定结构的功能函数与变量:
1.1根据设计和分析需求,确定影响结构可靠性的变量,包含n个随机变量x=(x1,x2,…,xn)和m个p-box变量y=(y1,y2,…,ym);
1.2利用力学理论或者有限元仿真方法途径获取所需分析结构的功能函数g(x,y);
步骤二、结构功能函数变量空间的转换:
2.1步骤一所得到的结构功能函数g(x,y),通过概率转换,ux=φ-1(fx(x))和uy=φ-1(fy(y)),可以得到标准正态空间下结构的功能函数g(ux,uy),即g(ux,uy)=g(x,y);
其中:fx(x)为随机变量x的累积分布函数,fy(y)为p-box变量y的累积分布函数,φ-1表示为标准正态分布反函数;
2.2初始化参数(1),s=1,
其中,s用于记录外层迭代次数,
2.3变量转换,标准正态空间的变量u=(ux,uy)通过概率转换
步骤三、利用线性近似模型与两点自适应模型对功能函数进行近似:
3.1在任意点(x,y),利用线性近似方法,将结构功能函数g(x,y)近似表示为关于p-box变量y的近似表达式,即
其中j=1,2,3,…,m,
3.2根据非线性指数rs,在点
其中:
而且,i=1,2,3,…,n,xi∈x,xi,s∈xs-1,
3.3组合3.1的线性近似和3.2的两点自适应非线性近似的模型,近似表示结构的功能函数,有
3.4区间理论近似获取功能函数在任意点(x,y)处响应的上下限,具体有:
下限:
上限:
步骤四、利用hl-rf方法进行内层迭代:
4.1初始化参数(2),参数(2)为k,
其中,k用于记录内层迭代次数,
4.2迭代计算获取当前非线性指数rs的结构可靠度指数的上(下)限
1)结合hl-rf方法获取在外层第s次迭代中,内层第k次迭代结构的可靠度指数的上(下)限
其中,
2)收敛条件(1)设定为
3)判断是否符合收敛条件(1);如果符合收敛条件(1),则获取当前非线性指数rs的最优的
4.3设置收敛条件(2),当s≥2时,
如果不符合或者s=1时,则进行下一步;
进行外层迭代参数的更新:
4.4通过步骤四中4.3所计算得到的
4.5更新迭代次数s=s+1;
4.6对非线性指数rs进行更新,从而获取进行第s次迭代时近似模型的相关参数,更新的优化公式为:
并回到步骤三开始下一轮迭代计算;
步骤五、判别符号并获取最终可靠度指数β∈[βl,βr]与βr(l)对应的最大可能失效点
5.1利用公式βr(l)=sgn(gr(l)(0,0))βr(l)=sgn(gr(l)(μx,μy))βr(l)对所获得非概率混合可靠度指数βr(l)进行正负号的辨别,获取最终的βr(l);其中sgn(·)表示为符号函数,当输入值为正数时为1,输入值为负数时为-1,(μx,μy)表示为在功能函数在原始空间的变量的均值点;
5.2综合步骤三以及5.1所得结果,最终获取所分析结构的非概率混合可靠度指数β∈[βl,βr]与非概率混合可靠度指数上(下)限βr(l)对应的最大可能失效点
以下为本发明的具体实施例,该具体实施例并不用于限定本发明。结合附图4与附图5,对实施例进行说明。
步骤一、确定结构的功能函数与变量:
1.1根据设计和分析需求,确定影响结构可靠性的变量,包含n个随机变量x=(x1,x2,…,xn)和m个p-box变量y=(y1,y2,…,ym)。
本实施例为一振子系统,随机变量个数为4个,p-box变量个数为2个,所以n=4,m=2。
在本实施例中,随机变量表示为x=(x1,x2,x3,x4),而p-box变量表示为y=(y1,y2)。其中x1表示振子系统滑块的质量,x2表示振子系统的抵抗能力,x3表示振子系统的所受力的大小,x4表示振子系统的所受力的时间,y1与y2表示为振子系统的弹簧的弹性刚度。
在本实施例中,所有变量的具体信息如下表1:
表1本实施例的振子系统各变量分布情况
1.2利用力学理论或者有限元仿真方法等途径获取所需分析结构的功能函数。
在本实施例中,结构的功能函数的具体公式如下:
其中,
步骤二、结构功能函数变量空间的转换:
2.1步骤一所得到的结构功能函数g(x,y),通过概率转换,ux=φ-1(fx(x))和uy=φ-1(fy(y)),可以得到标准正态空间下结构的功能函数g(ux,uy),即g(ux,uy)=g(x,y);
其中:fx(x)为随机变量x的累积分布函数,fy(y)为p-box变量y的累积分布函数,φ-1表示为标准正态分布反函数;
2.2初始化参数(1),s=1,
其中,s用于记录外层迭代次数,
2.3变量转换,标准正态空间的变量u=(ux,uy)通过概率转换
步骤三、利用线性近似模型与两点自适应模型对功能函数进行近似:
3.1在任意点(x,y),利用线性近似方法,将结构功能函数g(x,y)近似表示为关于p-box变量y的近似表达式,即
其中j=1,2,3,…,m,
3.2根据非线性指数rs,在点
其中:
而且,i=1,2,3,…,n,xi∈x,xi,s∈xs-1,
3.3组合3.1的线性近似和3.2的两点自适应非线性近似的模型,近似表示结构的功能函数,有
3.4区间理论近似获取功能函数在任意点(x,y)处响应的上下限,具体有:
下限:
上限:
步骤四、利用hl-rf方法进行内层迭代:
4.1初始化参数(2),参数(2)为k,
其中,k用于记录内层迭代次数,
4.2迭代计算获取当前非线性指数rs的结构可靠度指数的上(下)限
1)结合hl-rf方法获取在外层第s次迭代中,内层第k次迭代结构的可靠度指数的上(下)限
其中,
2)收敛条件(1)设定为
3)判断是否符合收敛条件(1);如果符合收敛条件(1),则获取当前非线性指数rs的最优的
4.3设置收敛条件(2),当s≥2时,
如果不符合或者s=1时,则进行下一步;
进行外层迭代参数的更新:
4.4通过步骤四中4.3所计算得到的
4.5更新迭代次数s=s+1;
4.6对非线性指数rs进行更新,从而获取进行第s次迭代时近似模型的相关参数,更新的优化公式为:
并回到步骤三开始下一轮迭代计算;
步骤五、判别符号并获取最终可靠度指数β∈[βl,βr]与βr(l)对应的最大可能失效点
5.1利用公式βr(l)=sgn(gr(l)(0,0))βr(l)=sgn(gr(l)(μx,μy))βr(l)对所获得非概率混合可靠度指数βr(l)进行正负号的辨别,获取最终的βr(l);其中sgn(·)表示为符号函数,当输入值为正数时为1,输入值为负数时为-1,(μx,μy)表示为在功能函数在原始空间的变量的均值点;
5.2综合步骤三以及5.1所得结果,最终获取所分析结构的非概率混合可靠度指数β∈[βl,βr]与非概率混合可靠度指数上(下)限βr(l)对应的最大可能失效点
本实施例中,本发明在求解非概率混合可靠度指数上限βr时,经过三次迭代,非线性指数rs在三次迭代过程中分别为[1,2.115,0.081],最终得到βr=1.745,
本实施例中,本发明在求解非概率混合可靠度指数下限βl时,非线性指数rs分别为[1,2.043,4.99],最终得到βl=1.634,
作为本实施例的对比,采用传统嵌套式优化方法进行分析。该方法无论是求解非概率混合可靠度指数上限或者下限均经过4次迭代计算,得到β∈[βl,βr]=[1.634,1.745]。本发明方法与传统方法在本实施例中的具体信息在表2和表3。
表2求解可靠度指数下限时本发明方法与传统嵌套式方法的对比
表3求解可靠度指数上限时本发明方法与传统嵌套式方法的对比
在本实施例中,从表2与表3可以看出,与现有技术相比,本发明在保证精度的前提下,能有效减少结构的功能函数调用次数,具有明显的效率优势。
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!