一种基于半监督学习的信号识别方法和装置与流程
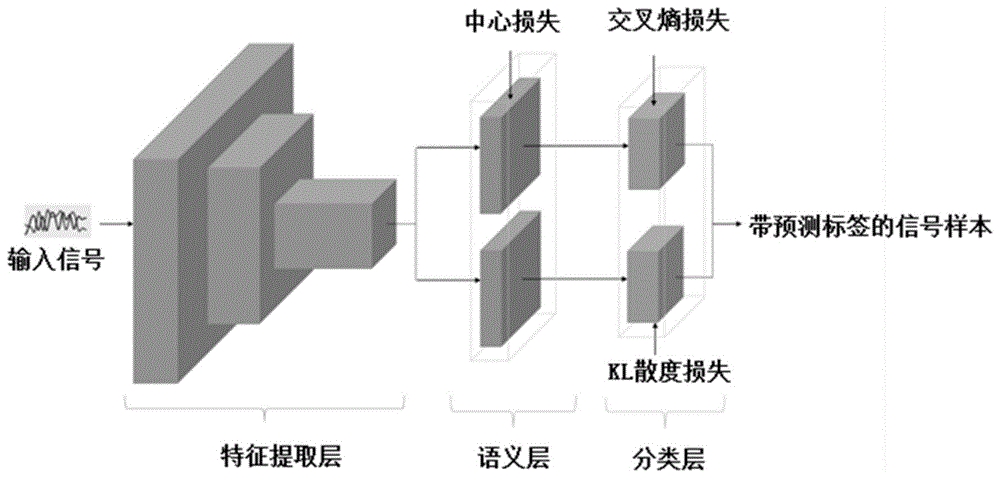
本发明涉及无线信号识别领域,尤其是涉及一种基于半监督学习的信号识别方法和装置。
背景技术:
无线电波调制信号在实际生活中运用广泛,接收器通过对接收的无线电波调制信号进行识别、分类,解调出所含信号,无线信号传播无疑大大提高了信息传递的速率,但是无论是实际应用还是在理论研究,经常遇到数据采集困难、样本标注代价高等问题,导致有标签样本非常有限,不足以为每类信号提供充足的有标签数据,从而使训练得到的深度学习网络模型容易过拟合。而对于数量较多的无标签样本的使用率却较少,半监督学习可以有效利用无标签样本,以减少深度cnn模型中的过度拟合。
现有技术公开了一种基于卷积神经网络的古字体分类方法,基于分类任务的目标函数将中心损失函数与传统的交叉熵损失函数配合使用,增大类间距离并减小类内距离,在一定程度上提高了特征的分辨能力,但是进行训练的样本均为有标签样本,仍未有效利用无标签样本。
技术实现要素:
本发明的目的就是为了克服上述现有技术存在的有标签样本有限导致深度学习网络模型容易过拟合、无标签样本的使用率不足的缺陷而提供一种基于半监督学习的信号识别方法和装置。
本发明的目的可以通过以下技术方案来实现:
一种基于半监督学习的信号识别方法,对无线电波调制信号进行识别,具体包括以下步骤:
步骤s1:创建包括特征提取层、语义层和分类层的神经网络模型,获取信号样本和待分类调制类别,判断所述信号样本的类型,若为有标签样本则转至步骤s2,若为无标签样本则转至步骤s3;
步骤s2:所述有标签样本输入神经网络模型进行训练,所述神经网络模型提取特征后在语义层根据有标签样本的语义向量计算有标签样本的中心损失值,并在分类层根据有标签样本的输出向量计算有标签样本的交叉熵损失值;
步骤s3:所述无标签样本与随机噪声结合获得无标签噪声副本,所述无标签样本和无标签噪声副本同时输入神经网络模型进行训练,在分类层根据无标签样本和无标签噪声副本的输出向量计算无标签样本和无标签噪声副本之间的kl散度损失值;
步骤s4:根据所述中心损失值、交叉熵损失值和kl散度损失值生成总损失函数,根据所述总损失函数对神经网络模型的参数进行优化,直到中心损失值、交叉熵损失值和kl散度损失值收敛;
步骤s5:输入带预测标签的信号样本至步骤s4中完成优化的神经网络模型,在分类层获取所述带预测标签的信号样本的输出向量组,以所述输出向量组中最大值的输出向量作为预测结果进行输出。
所述特征提取层包括最大池化层和卷积层,所述卷积层的数量为3层。
所述语义层包括一层全连接层。
所述分类层包括一层全连接层。
所述中心损失值的计算公式如下所示:
其中,lct为中心损失值,yj为有标签样本的调制类别,zj为有标签样本的语义向量,
进一步地,所述步骤s2中计算出标签样本的中心损失值后,待分类调制类别通过梯度下降进行更新,具体更新方式为:
其中,
其中,δ为指示函数,当所述指示函数内的测试条件为真时,指示函数的函数值为1,否则为0。
所述交叉熵损失值的计算公式如下所示:
其中,lce为交叉熵损失值,xj为有标签样本,f(xj)为有标签样本的输出向量。
所述kl散度损失值的计算公式如下所示:
其中,lkl为kl散度损失值,xi为无标签样本,xi′为无标签噪声副本,f(xi)为无标签样本的输出向量,f(xi′)为无标签噪声副本的输出向量,s为无标签样本的数量。
所述总损失函数具体如下:
l=lce+λctlct+λkllkl
其中,l为样本总损失,λct和λkl为中心损失值和kl散度损失值所占权重的超参数。
所述步骤s4中神经网络模型的参数优化方法包括反向传播和梯度下降算法。
一种使用所述基于半监督学习的信号识别方法的装置,包括存储器和处理器,所述方法以计算机程序的形式存储于存储器中,由处理器执行,执行时实现以下步骤:
步骤s1:创建包括特征提取层、语义层和分类层的神经网络模型,获取信号样本和待分类调制类别,判断所述信号样本的类型,若为有标签样本则转至步骤s2,若为无标签样本则转至步骤s3;
步骤s2:所述有标签样本输入神经网络模型进行训练,所述神经网络模型提取特征后在语义层根据有标签样本的语义向量计算有标签样本的中心损失值,并在分类层根据有标签样本的输出向量计算有标签样本的交叉熵损失值;
步骤s3:所述无标签样本与随机噪声结合获得无标签噪声副本,所述无标签样本和无标签噪声副本同时输入神经网络模型进行训练,在分类层根据无标签样本和无标签噪声副本的输出向量计算无标签样本和无标签噪声副本之间的kl散度损失值;
步骤s4:根据所述中心损失值、交叉熵损失值和kl散度损失值生成总损失函数,根据所述总损失函数对神经网络模型的参数进行优化,直到中心损失值、交叉熵损失值和kl散度损失值收敛;
步骤s5:输入带预测标签的信号样本至步骤s4中完成优化的神经网络模型,在分类层获取所述带预测标签的信号样本的输出向量组,以所述输出向量组中最大值的输出向量作为预测结果进行输出。
与现有技术相比,本发明对有标签样本和无标签样本进行训练,结合中心损失值、交叉熵损失值和kl散度损失值生产总损失函数,然后进行反向传递来更新神经网络模型的参数,能够大幅度减少训练模型所需要的有标签样本数量,在无线电波调制信号的有标签样本不足的情况下具有较好的性能,并且在实际场景下具有较好的鲁棒性,能有效地提高信号识别的准确率。
附图说明
图1为本发明的结构示意图;
图2为本发明的流程示意图;
图3为本发明语义层的t-sne降维可视化效果图;
图4为本发明准确率、交叉熵损失、中心损失和kl散度损失与训练次数的关系图。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
如图2所示,一种基于半监督学习的信号识别方法,大幅度减少训练模型所需要的有标签样本数量,在无线电波调制信号识别存在有标签样本不足的情况下仍具有较好的性能,具体包括以下步骤:
步骤s1:创建包括特征提取层、语义层和分类层的神经网络模型,如图1所示,获取信号样本和待分类调制类别,判断信号样本的类型,若为有标签样本则转至步骤s2,若为无标签样本则转至步骤s3;
步骤s2:有标签样本输入神经网络模型进行训练,神经网络模型提取特征后在语义层根据有标签样本的语义向量计算有标签样本的中心损失值,并在分类层根据有标签样本的输出向量计算有标签样本的交叉熵损失值;
步骤s3:无标签样本与随机噪声结合获得无标签噪声副本,无标签样本和无标签噪声副本同时输入神经网络模型进行训练,在分类层根据无标签样本和无标签噪声副本的输出向量计算无标签样本和无标签噪声副本之间的kl散度损失值;
步骤s4:根据中心损失值、交叉熵损失值和kl散度损失值生成总损失函数,根据总损失函数对神经网络模型的参数进行优化,直到中心损失值、交叉熵损失值和kl散度损失值收敛;
步骤s5:输入带预测标签的信号样本至步骤s4中完成优化的神经网络模型,在分类层获取带预测标签的信号样本的输出向量组,以输出向量组中最大值的输出向量作为预测结果进行输出。
特征提取层包括最大池化层和卷积层,卷积层的数量为3层。
语义层包括一层全连接层,分类层包括一层全连接层。
中心损失值的计算公式如下所示:
其中,lct为中心损失值,yj为有标签样本的调制类别,zj为有标签样本的语义向量,
步骤s2中计算出标签样本的中心损失值后,待分类调制类别通过梯度下降进行更新,具体更新方式为:
其中,
其中,δ为指示函数,当指示函数内的测试条件为真时,指示函数的函数值为1,否则为0。
交叉熵损失值的计算公式如下所示:
其中,lce为交叉熵损失值,xj为有标签样本,f(xj)为有标签样本的输出向量。
kl散度损失值的计算公式如下所示:
其中,lkl为kl散度损失值,xi为无标签样本,xi′为无标签噪声副本,f(xi)为无标签样本的输出向量,f(xi′)为无标签噪声副本的输出向量,s为无标签样本的数量。
总损失函数具体如下:
l=lce+λctlct+λkllkl
其中,l为样本总损失,λct和λkl为中心损失值和kl散度损失值所占权重的超参数。
步骤s4中神经网络模型的参数优化方法包括反向传播和梯度下降算法。
一种使用基于半监督学习的信号识别方法的装置,包括存储器和处理器,方法以计算机程序的形式存储于存储器中,由处理器执行,执行时实现以下步骤:
步骤s1:创建包括特征提取层、语义层和分类层的神经网络模型,获取信号样本和待分类调制类别,判断信号样本的类型,若为有标签样本则转至步骤s2,若为无标签样本则转至步骤s3;
步骤s2:有标签样本输入神经网络模型进行训练,神经网络模型提取特征后在语义层根据有标签样本的语义向量计算有标签样本的中心损失值,并在分类层根据有标签样本的输出向量计算有标签样本的交叉熵损失值;
步骤s3:无标签样本与随机噪声结合获得无标签噪声副本,无标签样本和无标签噪声副本同时输入神经网络模型进行训练,在分类层根据无标签样本和无标签噪声副本的输出向量计算无标签样本和无标签噪声副本之间的kl散度损失值;
步骤s4:根据中心损失值、交叉熵损失值和kl散度损失值生成总损失函数,根据总损失函数对神经网络模型的参数进行优化,直到中心损失值、交叉熵损失值和kl散度损失值收敛;
步骤s5:输入带预测标签的信号样本至步骤s4中完成优化的神经网络模型,在分类层获取带预测标签的信号样本的输出向量组,以输出向量组中最大值的输出向量作为预测结果进行输出。
如图3所示,语义层使用t-sne降维可视化后,在不同的类别有了明显的区分,可以较好的辨别不同的类别,对有标签样本进行更好地分类。
如图4所示,神经网络模型根据总损失函数训练更新的过程中,准确率、交叉熵损失、中心损失和kl散度损失之间成反相关,随着交叉熵损失、中心损失和kl散度损失的下降,模型信号识别的准确率逐步提升,说明了三种损失函数都是有作用的,且能够提高信号识别的准确率。
此外,需要说明的是,本说明书中所描述的具体实施例,所取名称可以不同,本说明书中所描述的以上内容仅仅是对本发明结构所做的举例说明。凡依据本发明构思的构造、特征及原理所做的等小变化或者简单变化,均包括于本发明的保护范围内。本发明所属技术领域的技术人员可以对所描述的具体实例做各种各样的修改或补充或采用类似的方法,只要不偏离本发明的结构或者超越本权利要求书所定义的范围,均应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!