针对MySQLGalera集群故障的检测和恢复方法及系统与流程
本发明涉及云计算技术,尤其涉及一种针对mysqlgalera集群故障的检测和恢复方法及系统。
背景技术:
mysql在互联网时代,是深受世人瞩目的明星数据库软件。给社会创造了无限价值,随之而来的是,在mysql基础之上,产生了形形色色的使用方法、架构及周边产品,比如mha、mmm等传统架构模式。然而mysql的主从模式,天生的不能完全保证数据一致性,很多公司会花很大人力物力去解决这个问题,而效果却一般,可以说,只能是通过牺牲性能,来获得数据一致性,但也只是在降低数据不一致性的可能性而已。所以现在就急需一种新型架构,从根本上解决这样的问题,天生的摆脱掉主从复制模式这样的“美中不足”之处了。galeracluster的出现就是来解决以上描述的问题;galera解决的最核心问题是,在三个实例(节点)之间(奇数节点扩展),它们的关系是对等的,multi-master架构的,在多节点同时写入的时候,能够保证整个集群数据的一致性、完整性与正确性。
数据库服务无论是在云计算时代还是在传统的it系统中都是一项基本核心功能服务,负责业务数据的存储服务。mysql是最流行的关系型数据库管理系统之一,且开源免费,大量web应用选择其作为数据存储应用软件。mysqlgalera集群的多主对等架构,在多节点同时写入的时候,能够保证整个集群数据的一致性、完整性与正确性,此种架构得到广泛应用。因此,确保mysqlgalera数据库集群的异常及时发现和异常恢复,对保障应用持续提供服务有现实意义。
mysqlgaleracluster在网络抖动、网卡mtu不一致、节点选举异常等情况下会引起集群数据的不一致性,且存在不能自动恢复正常的问题。出现此情形时,依赖mysql数据库的业务应用会出现连接数据库异常,无法进行数据读写。
技术实现要素:
为了解决以上技术问题,本发明提供了一种针对mysqlgalera集群故障的检测和恢复方法,通过检测程序自动发现mysqlgalera集群异常并能进行自修复,保障数据库服务的业务连续性。
本发明的技术方案是:
针对mysqlgalera集群故障的检测和恢复方法,包括以下步骤:
(1)mysqlgalera集群节点运行监测采集程序,同时监测服务端有针对mysql集群各节点的数据网连通探测。
(2)每3秒采集周期采集监测指标数据上报监控服务端。
(3)通过对采集数据分析判断出故障类型并触发告警。
(4)通过restfulapi调用传递到故障分类处理模块,判断出对节点的处理动作包括网络持续丢包或不通,告警运维人员;集群数据不一致则根据判定出的节点进行逐步处理。若mysql数据库节点系统异常则进行节点的机器的重启。
(5)在故障处理完成后,对mysqlgalera集群的可用性进行验证,包括:wsrep_cluster_size=3、wsrep_cluster_status=primary、wsrep_ready=on数据值是否正常,集群节点间uuid、seqno是否一致。
(6)验证服务组件连接数据库是否正常,包括对数据库进行查询及测试数据写入验证。
进一步的,所述步骤(1)中代理程序特指针对mysqlgalera集群节点关键指标数据的采集程序。
进一步的,所述步骤(2)采集数据特指针对mysqlgalera集群状态参数及可用性的关键指标(mysql服务状态、网络连通性、mysql进程状态、wsrep_cluster_size、wsrep_cluster_status、wsrep_readyuuid、seqno)。
进一步的,所述步骤(3)异常检测,包括:mysql服务是否正常、进程id是否存在、wsrep_cluster_size、wsrep_cluster_status、wsrep_ready数据值是否正常、集群各节点uuid、seqno是否一致。
进一步的,所述步骤(4)故障分类处理,对运行mysqlgalera服务的节点进行重启、集群不一致时按照恢复程序进行节点重启操作(程序主要实现步骤:停止集群所有mysql服务;备份seqno的值最大的节点的my.cnf文件;修改seqno的值最大的节点的my.cnf的wsrep_cluster_address="gcomm://"值,启动seqno值最大的节点mysql服务,启动正常后逐个启动剩余节点;最后关闭seqno的值最大的节点,恢复my.cnf文件,启动mysql服务。)。
进一步的,所述步骤(5)恢复检测,指对mysqlgalera集群的mysql数据库状态、集群数据的一致性进行检测,确保mysqlgalera集群恢复正常且可用。
进一步的,所述步骤(6)服务检测验证,指对使用mysql作为数据库存储系统的业务应用进行数据库查询及数据写入操作,保障业务应用持续可用。
本发明还提供了一种云计算环境下云管理平台使用的mysqlgalera集群故障时的自动检测和恢复系统,具体包括采集代理模块、异常检测判定模块、告警接收模块、故障处理模块、恢复核查模块。
1、信息采集代理模块运行在各个mysql节点,周期性(3s)采集mysql服务状态、集群指标数据(网络连通性、mysql进程状态、wsrep_cluster_size、wsrep_cluster_status、uuid、seqno),上报监控服务端。
2、异常检测判定模块分析采集的mysqlgalera的指标数据,来判定mysqlgalera集群是否发生脑裂、数据不一致。
3、异常检测模块对分析的异常结果产生告警并发送到告警接收模块。
4、故障处理模块根据分析告警信息来判定对mysqlgalera集群的故障处理:若节点丢包率高,告警通知运维人员排查丢包原因;若运行的mysqlgalera节点系统crash则重启mysql节点;若数据库数据不一致则根据seqno的值最大的节点为最新数据节点进行数据库的恢复操作,具体为:停止集群所有mysql服务;修改seqno的值最大的节点的my.cnf的wsrep_cluster_address="gcomm://"值,启动seqno值最大的节点mysql服务,启动正常后逐个启动剩余节点;最后关闭seqno的值最大的节点,恢复my.cnf,启动mysql服务。
5、故障处理后调用恢复核查模块检查mysqlgalera集群状态是否正常,数据是否一致,业务应用连接数据库是否正常、数据是否可正常读写。
在上述1、2、4阶段是mysqlgalera集群故障检测及恢复的核心部分,本发明具体实现了:对mysqlgalera集群关键服务指标进行采集存储,检测分析模块对数据进行加工处理判定出集群是否异常,故障处理模块会根据告警类型进行对应处理,特别是当数据库集群节点间数据不一致时,可在5分钟内对集群进行恢复(网络恢复正常的前提下,数据量少于)。
本发明的有益效果是
本发明进一步完善了mysqlgalera集群异常时靠集群自身的恢复机制不能恢复到正常状态的监控及处理,增强了mysqlgalera集群服务可用性的能力。mysqlgalera集群本身有一定的恢复能力,但在网络异常后也存在数据的不一致性,导致数据库服务不能提供服务。本发明增强了mysqlgalera集群的故障检测及恢复方法,是对mysqlgalera集群故障恢复的补充完善。具体益处:1)准实时性的进行mysqlgalera集群数据一致的检测,能及时发现数据不一致的异常并进行相应的告警及自动处理。2)把传统的手动修复模式转化为处理程序,提高了处理的及时性和效率,也避免的人为手动处理误操作的风险。3)关键服务连接数据库状态监测能有效发现是否由于数据库异常导致的服务异常。
附图说明
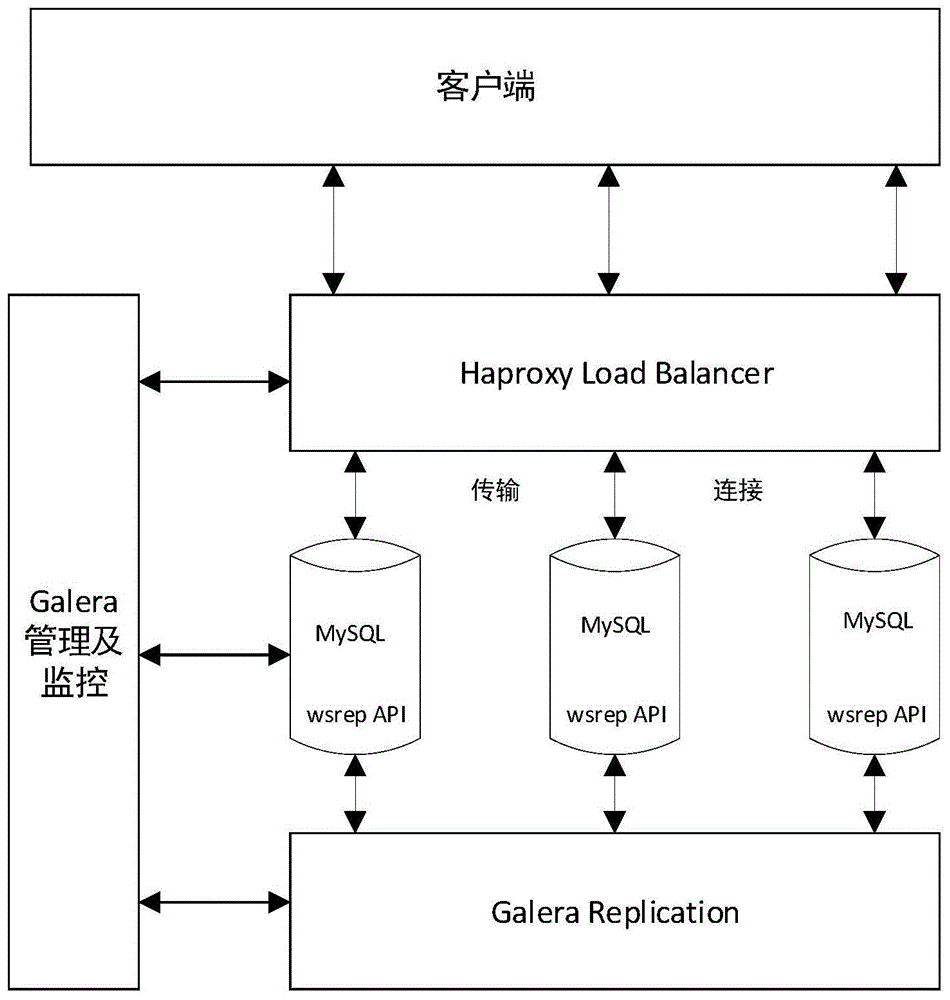
图1是mysqlgalera集群逻辑架构图;
图2是针对mysqlgalera集群故障的检测和恢复方法逻辑结构图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
galeracluster是mysql封装了具有高一致性,支持多点写入的同步通信模块galera而做的,它是建立在mysql同步基础之上的,使用galeracluster时,应用程序可以直接读、写某个节点的最新数据,并且可以在不影响应用程序读写的情况下,下线某个节点,因为支持多点写入,使得failover变得非常简单。
所有的galeracluster,都是对galera所提供的接口api做了封装,这些api为上层提供了丰富的状态信息及回调函数,通过这些回调函数,做到了真正的多主集群,多点写入及同步复制,这些api被称作是write-setreplicationapi,简称为wsrepapi。
通过这些api,galeracluster提供了基于验证的复制,是一种乐观的同步复制机制,一个将要被复制的事务(称为写集),不仅包括被修改的数据库行,还包括了这个事务产生的所有binlog,每一个节点在复制事务时,都会拿这些写集与正在apply队列的写集做比对,如果没有冲突的话,这个事务就可以继续提交,或者是apply,这个时候,这个事务就被认为是提交了,然后在数据库层面,还需要继续做事务上的提交操作。
这种方式的复制,也被称为是虚拟同步复制,实际上是一种逻辑上的同步,因为每个节点的写入和提交操作还是独立的,更准确的说是异步的,galeracluster是建立在一种乐观复制的基础上的,假设集群中的每个节点都是同步的,那么加上在写入时,都会做验证,那么理论上是不会出现不一致的,当然也不能这么乐观,如果出现不一致了,比如主库(相对)插入成功,而从库则出现主键冲突,那说明此时数据库已经不一致,这种时候galeracluster采取的方式是将出现不一致数据的节点踢出集群,其实是自己shutdown了。
而通过使用galera,它在里面通过判断键值的冲突方式实现了真正意义上的multi-master,galeracluster在mysql生态中,在高可用方面实现了非常重要的提升,目前galeracluster具备的功能包括如下几个方面:
多主架构:真正的多点读写的集群,在任何时候读写数据,都是最新的。
同步复制:集群不同节点之间数据同步,没有延迟,在数据库挂掉之后,数据不会丢失。
并发复制:从节点在apply数据时,支持并行执行,有更好的性能表现。
故障切换:在出现数据库故障时,因为支持多点写入,切的非常容易。
热插拔:在服务期间,如果数据库挂了,只要监控程序发现的够快,不可用服务时间就会非常少。在节点故障期间,节点本身对集群的影响非常小。
自动节点克隆:在新增节点,或者停机维护时,增量数据或者基础数据不需要人工手动备份提供,galeracluster会自动拉取在线节点数据,最终集群会变为一致。
对应用透明:集群的维护,对应用程序是透明的,几乎感觉不到。以上几点,足以说明galeracluster是一个既稳健,又在数据一致性、完整性及高性能方面有出色表现的高可用解决方案,因此应用非常广泛。
mysqlgaleracluster自身虽有较好的故障切换及恢复能力,但在实际使用中也存在由于网络异常导致的mysql数据库服务不可用,因此通过对mysqlgaleracluster涉及的关键指标进行监控,及时发现问题,并通过恢复程序恢复mysql服务可用性,对保障业务持续运行有着现实意义。
本发明借助分析grastate.dat文件及wsrep_cluster_size参数值的变化来判定集群是否正常;并通过恢复程序恢复数据库集群,保证mysqlgalera集群的服务可用性。主要通过以下步骤:
(1)mysqlgalera集群节点运行监测采集程序,同时监测服务端有针对mysql集群各节点的数据网连通探测。
(2)每3秒采集周期采集监测指标数据(mysql服务状态、网络连通性、mysql进程状态、wsrep_cluster_size、wsrep_cluster_status、wsrep_readyuuid、seqno)上报监控服务端。
(3)异常检测模块通过对采集数据分析判断出故障类型并触发告警。
(4)告警模块通过restfulapi调用传递到故障分类处理模块,判断出对节点的处理动作包括网络持续丢包或不通,告警运维人员;集群数据不一致则根据判定出的节点进行逐步处理;若mysql数据库节点系统异常则进行节点的机器的重启。
(5)恢复检测模块会在故障处理完成后,对mysqlgalera集群的可用性进行验证,包括:wsrep_cluster_size=3、wsrep_cluster_status=primary、wsrep_ready=on数据值是否正常,集群节点间uuid、seqno是否一致。
(6)集群检测模块验证服务组件连接数据库是否正常,包括对数据库进行查询及测试数据写入验证。
图1展现了mysqlgalera集群的总体结构。当一个事务在当前写入的节点提交后,通过wsrepapi(writesetreplicationapi)将这个事务变成写集(writeset)广播到同集群的其他节点中,其他节点收到写集事务后,对这个事务进行可行性检查,并返回结果给wsrepapi。若大多数节点都预估自己可以成功执行这个事务,则wsrepapi会做出仲裁,通知所有可以成功执行这个事务的节点提交这个事务,并将事务成功提交的消息返回给客户端,同时根据需要剔除没有成功执行事务的节点。
如图2所示,信息采集代理模块运行在各个mysql节点,周期性(3s)采集mysql服务状态、集群指标数据(网络连通性、mysql进程状态、wsrep_cluster_size、wsrep_cluster_status、uuid、seqno),上报监控服务端。
异常检测判定模块分析采集的mysqlgalera的指标数据,来判定mysqlgalera集群是否发生脑裂、数据不一致。
异常检测模块对分析的异常结果产生告警并发送到告警接收模块。
故障处理模块根据分析告警信息来判定对mysqlgalera集群的故障处理:若节点丢包率高,告警通知运维人员排查丢包原因;若运行的mysqlgalera节点系统crash则重启mysql节点;若数据库数据不一致则根据seqno的值最大的节点为最新数据节点进行数据库的恢复操作,具体为:停止集群所有mysql服务;修改seqno的值最大的节点的my.cnf的wsrep_cluster_address="gcomm://"值,启动seqno值最大的节点mysql服务,启动正常后逐个启动剩余节点;最后关闭seqno的值最大的节点,恢复my.cnf,启动mysql服务。
故障处理后调用恢复核查模块检查mysqlgalera集群状态是否正常,数据是否一致,业务应用连接数据库是否正常、数据是否可正常读写。
图2展示了针对mysqlgalera集群故障,特别由于网络异常导致的集群数据不一致问题的检测和恢复;通过监测数据采集、监控端采集数据存储、异常检测判定、故障分类处理、恢复核查来实现对mysqlgalera集群故障的判定及处理,相比人工运维对mysqlgalera集群故障的判定和恢复,本发明对mysqlgalera集群故障的检测和恢复方法有较好的处理及时性,提高运维自动化水平。
以上所述仅为本发明的较佳实施例,仅用于说明本发明的技术方案,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所做的任何修改、等同替换、改进等,均包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!