一种基于关联性层级残差的多实例自然场景文本检测方法与流程
本发明属于深度学习、计算机视觉和文本检测领域,具体涉及一种基于关联性层级残差的多实例自然场景文本检测方法。
背景技术:
文字作为信息传递的一种主要方式,它在我们的日常生活中扮演着不可或缺的角色,而随着大数据时代的到来,如何获取海量图像中的文本信息成为了一个亟需解决的问题。由此,再基于深度学习的发展,自然场景文本检测技术成为了计算机视觉领域一个非常热门的研究方向,其对于图像检索和场景理解等具有重要意义。
目前,大量研究成果的问世使得自然场景文本检测广泛应用于各行业各领域。比如:许多互联网公司基于自然场景文本检测技术开发了图像检索、街景导航等相关业务和应用。而一些云服务商也相继提供了图像文本检测服务,其中各项服务面向教育、物流、视频、电商、旅游等多个领域,为用户提供直接的文本检测服务、间接的文本检测模型、或定制化ai服务系统集成等。虽然到现在为止自然场景文本检测技术成果显著,但是由于自然场景文本检测处理的文本图像具有背景复杂以及文本多样的特点,目前相关技术仍然存在检测精度不够等技术难题。
经过调查与研究,我们发现现有自然场景文本检测方法存在以下两点不足:一方面,文本检测使用的特征提取网络虽然借鉴sppnet、u-net、fpnnet等多尺度特征提取网络开始采用多尺度特征提取及融合的思想,但是这种方式在相邻不同尺度特征的提取过程中一般只采用一种尺寸的卷积核,因此这样的特征提取是粗粒度的。考虑到自然场景文本图像中的文本实例通常比自然背景要小得多,而且现有方法对于小文本区域的检测效果不好的问题,需要提取更加细粒度的特征才能与文本检测任务适配,所以这种粗粒度的多尺度特征提取方式仍然存在改进和提升空间。另一方面,文本检测方法中目前常用的回归损失函数为iouloss,它计算的是预测文本检测框与真值文本检测框之间的交并比,但是在交并比相同的情况下预测框和真值框的位置情况、交叠情况都可能有所不同,所以直接用交并比来评估文本检测框回归情况的好坏也是存在缺陷的,因此损失函数的设计也有待改进。
技术实现要素:
本发明的目的在于提供一种基于关联性层级残差的多实例自然场景文本检测方法,以解决当前文本检测方法对于小文本区域的检测效果不好,以及文本检测通常使用的损失函数不能很好评估文本检测框实际回归情况的问题。
为了达到上述目的,本发明采用以下技术方案:
步骤一,采用基于关联性层级残差的特征提取网络对原始输入图像进行特征提取,从而得到从低级到高级的包含丰富文本信息的不同尺度特征图;
步骤二,对步骤一中提取的不同尺度特征图进行反向逐级特征融合,从而得到多尺度融合特征图;
步骤三,对步骤二输出的多尺度融合特征图采用特征映射进行文本区域检测,输出一个像素级的文本分数特征图以及一个文本区域几何特征图,以此可以表征候选预测文本区域;
步骤四,对步骤三中生成的所有候选预测文本区域,根据每个候选预测文本区域的分数先预先进行简单的筛选和剔除;
步骤五,使用局部感知非极大值抑制算法对步骤四剩余候选预测文本区域进行合并和筛选,从而得到准预测文本区域;
步骤六,对步骤五得到的所有准预测文本区域计算其区域平均分数,对区域平均分数低于一定阈值的区域进行剔除,从而得到最终的预测文本区域,及检测结果。
并且包含一个训练过程,使用若干公开的常用文本检测数据集对方法模型进行训练;
训练过程中使用反向传播,当损失较大时,不断更新模型参数,直到损失收敛到较小的值,保存模型的参数;
步骤七,使用保存的模型的结构和参数构成多实例自然场景文本检测模型。
进一步的,步骤一中,基于关联性层级残差的特征提取网络基于resnet-50的骨干网络引入了关联性层级残差结构,这样能够提取粗粒度与细粒度相结合的精确且完备的多尺度文本特征。在特征提取环节,原始输入图像通过5个卷积层conv1-conv5逐步获取了从低级到高级的不同尺度的粗粒度特征信息,经过每个卷积层之后的特征图尺寸依次变为原图的的1/2、1/4、1/8、1/16和1/32;另外conv2-conv5中引入了关联性层级残差结构用于相邻不同尺度特征图之间的细粒度特征提取;这样提取过程中生成的不同尺度特征图f1、f2、f3、f4就同时包含了粗粒度与细粒度相结合的多尺度特征信息。
进一步的,基于关联性层级残差的特征提取网络,conv1采用7×7的卷积核,后面跟一个maxpool层采用3×3的卷积核来进行下采样。conv2-conv5构成为1×1卷积、3×3卷积组和1×1卷积,并附带残差连接以便简化深度神经网络的学习目标和难度。其中3×3卷积组是实现细粒度特征提取的关键,它首先将1x1卷积生成的特征图沿通道维度平均分为4个子特征图,第1个子特征图x1直接被输出作为y1;之后的每个子特征图xi在经过一个3×3卷积操作ki后才得到输出yi;而且从第3个子特征图开始,xi会加上前一个子特征图的输出yi-1,然后再进行3×3卷积操作;最后将4个子特征图的输出沿通道维度合并即得到总输出y。
进一步的,步骤二中反向逐级特征融合从conv5生成的特征图f1开始,先对f1进行上采样并输出尺寸为原特征图2倍的特征图,这样输出后的特征图尺寸和conv4生成的特征图f2一致,可以直接沿通道维度将两者进行合并;另外在特征图合并之后,还附加了1×1,3×3的两个卷积操作用于降低通道维度和减少参数计算量;这样按此方式依次进行,最终不同尺度的特征图f1、f2、f3和f4逐级融合完成,融合后的特征图尺寸为1/4原始输入图像大小;此外还添加了一个3×3的卷积层来生成最终的多尺度融合特征图。
进一步的,步骤三中对多尺度融合特征图进行特征映射采用的是1×1卷积操作;然后输出的像素级的文本分数特征图以及文本区域几何特征图分别表示特征图中每个像素点是否在文本区域内,以及每个像素点到所属文本区域的边界距离和像素点所属文本区域倾斜角度,以此可以表征候选预测文本区域。
进一步的,步骤四中对候选预测文本区域预先进行简单筛选和剔除的分数阈值设定为0.5。
进一步的,步骤五中局部感知非极大抑制算法首先对剩余的候选预测文本区域逐行进行合并,当两个候选预测文本区域相交面积大于设定阈值0.2,则满足可以合并的要求;合并时,原先两个文本区域的顶点坐标进行加权平均得到合并后的文本区域的顶点坐标,其中所用的权重为原先两个文本区域的分数,而原先两个文本区域的分数相加得到合并后的新的文本区域的得分。然后合并后的候选预测文本区域再经过标准的非极大抑制算法进行筛选,得到准预测文本区域。
进一步的,步骤六中根据准预测文本区域的区域平均分数进行区域筛选的阈值设定为0.1。
进一步的,步骤六中训练过程中使用损失函数,并在损失反向传播时进行参数调整。
进一步的,损失函数由两部分组成,其中文本分类损失用于指导文本区域的正确分类;而检测框回归损失用于指导文本检测框的正确回归。总的损失函数计算公式为:
l=lcls+λlreg
其中l为检测总损失;lcls为文本分类损失,lreg为检测框回归损失,λ为权衡两个损失重要性的参数,其值为1。
文本分类损失计算公式为:
其中lcls表示文本分类损失;|y|表示真实文本分数特征图中所有正样本区域;|y*|表示预测文本分数特征图中所有正样本区域;|y∩y*|表示预测文本分数特征图中正样本区域与真实文本分数特征图中正样本区域相交的部分。
检测框回归损失计算公式为:
lreg=lg+λθlθ
其中lreg为检测框回归损失;lg为不考虑角度的文本检测框几何回归损失;lθ为文本检测框角度损失;λθ为两个损失的权衡参数,其值为20。
进一步的,检测框回归损失中不考虑角度的文本检测框几何回归损失为ciouloss,其计算公式为:
lg=1-iou+r(a,b)
其中lg表示文本检测框几何回归损失;
其中a,b分别表示预测框a与真实框b的区域中心;ρ(.)表示欧式距离;c表示能够包含a,b区域的最小外接矩形的对角线距离;
其中wb,hb为真实框b的宽和高;wa,ha为预测框a的宽和高。
进一步的,检测框回归损失中文本检测框角度损失计算公式为:
lθ=1-cos(θ*-θ)
其中lθ表示文本检测框角度损失;θ*为文本区域的预测角度;θ表示文本区域的真实角度。
与现有技术相比,本发明有以下技术效果:
本发明采用的特征提取网络利用关联性层级残差以及反向逐级特征融合提取了粗粒度与细粒度相结合的多尺度特征,其中包含了更精确更完备的文本信息,进一步增强了网络的特征表达能力,从而可以提高文本检测精度;
本发明使用的文本检测框回归损失由ciouloss和角度损失两部分构成,尤其是ciouloss的使用考虑了预测文本检测框与真实文本检测框之间的重叠面积、中心距离、长宽比等因素,能够更加精准的评估文本检测框的实际回归情况,从而可以提高文本检测方法的性能;
本发明在多个步骤中采用适当的方式减轻了硬件计算压力,比如:在网络设计中多处使用1×1,3×3的小卷积以及特征拆分再拼接等来降低特征维度并减少参数计算量;还有对候选预测文本区域的预先简单阈值筛选等;
本发明对于常规文本区域检测精度很高,另外对小文本区域的检测也比较敏感,其在自然场景文本检测领域有较高的应用价值。
附图说明
图1是本发明的流程图;
图2是本发明的特征提取及特征融合网络结构图;
图3是本发明特征提取网络conv2-conv5使用的关联性层级残差基本结构图;
图4是本发明的部分检测结果图。
具体实施方式
以下结合附图,对本发明进一步说明:
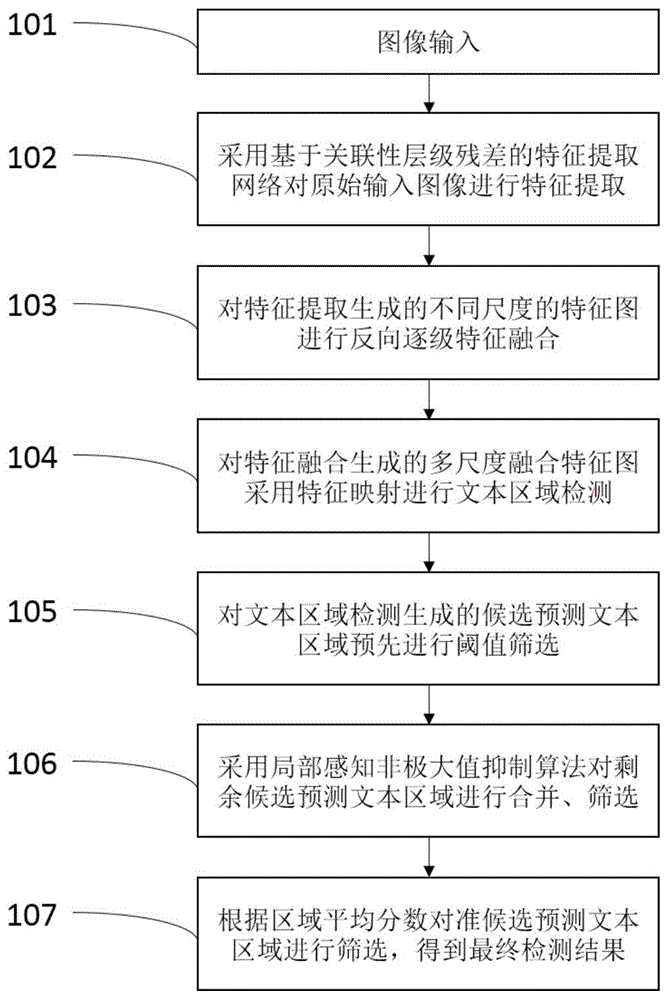
参见图1,本发明包括以下步骤:
步骤101,使用摄像头获取图像数据或者直接上传图像数据作为图像输入。
步骤102,采用基于关联性残差的特征提取网络对原始输入图像进行特征提取,获得粗粒度与细粒度相结合的尺寸分别为原始输入图像尺寸1/32、1/16、1/8、1/4的特征图f1、f2、f3、f4,这些多尺度特征图分别表征了由低级到高级的丰富特征信息。
步骤103,反向逐级特征融合从特征图f1开始,依次对f1、f2、f3、f4进行上采样及特征拼接,最终生成了尺寸为原始输入图像1/4大小的多尺度融合特征图。
步骤104,通过对多尺度融合特征图进行特征映射进行文本区域检测,输出像素级的文本分数特征图以及文本区域几何特征图,它们分别表示特征图中每个像素点是否在文本区域内,以及每个像素点到所属文本区域的边界距离和像素点所属文本区域倾斜角度,以此可以表征候选预测文本区域。
步骤105,对候选预测文本区域根据其区域分数预先进行简单筛选和剔除,筛选分数阈值设定为0.5。
步骤106,采用局部感知非极大抑制算法首先对剩余的候选预测文本区域逐行进行合并,当两个候选预测文本区域相交面积大于设定阈值0.2,则满足可以合并的要求;合并时,原先两个文本区域的顶点坐标进行加权平均得到合并后的文本区域的顶点坐标,其中所用的权重为原先两个文本区域的分数,而原先两个文本区域的分数相加得到合并后的新的文本区域的得分。然后合并后的候选预测文本区域再经过标准的非极大抑制算法进行筛选,得到准预测文本区域。
步骤107,根据准预测文本区域的区域平均分数进行区域筛选得到最终的预测文本区域(即文本检测结果),该筛选阈值设定为0.1。
另外,如大多数深度学习方法一样,方法模型的建立首先需要使用大量的已标记的图像数据进行训练,而训练过程中的反向传播和参数优化需要构建损失函数。损失函数由两部分组成,其中文本分类损失用于指导文本区域的正确分类;而检测框回归损失用于指导文本检测框的正确回归。总的损失函数计算公式为:
l=lcls+λlreg
其中l为检测总损失;lcls为文本分类损失,lreg为检测框回归损失,λ为权衡两个损失重要性的参数,其值为1。
文本分类损失计算公式为:
其中lcls表示文本分类损失;|y|表示真实文本分数特征图中所有正样本区域;|y*|表示预测文本分数特征图中所有正样本区域;|y∩y*|表示预测文本分数特征图中正样本区域与真实文本分数特征图中正样本区域相交的部分。
检测框回归损失计算公式为:
lreg=lg+λθlθ
其中lreg为检测框回归损失;lg为不考虑角度的文本检测框几何回归损失;lθ为文本检测框角度损失;λθ为两个损失的权衡参数,其值为20。
检测框回归损失中不考虑角度的文本检测框几何回归损失为ciouloss,其计算公式为:
lg=1-iou+r(a,b)
其中lg表示文本检测框几何回归损失;
其中a,b分别表示预测框a与真实框b的区域中心;ρ(.)表示欧式距离;c表示能够包含a,b区域的最小外接矩形的对角线距离;
其中wb,hb为真实框b的宽和高;wa,ha为预测框a的宽和高。
检测框回归损失中文本检测框角度损失计算公式为:
lθ=1-cos(θ*-θ)
其中lθ表示文本检测框角度损失;θ*为文本区域的预测角度;θ表示文本区域的真实角度。
参见图2,其描绘了本发明的特征提取及特征融合网络结构图,包括以下部分:
步骤201,使用摄像头获取图像数据或者直接上传图像数据作为图像输入。
步骤202,采用基于关联性层级残差的特征提取网络对原始输入图像进行特征提取,特征提取网络中的5个卷积层conv1-conv5逐步获取了从低级到高级的不同尺度的粗粒度特征信息,经过每个卷积层之后的特征图尺寸依次变为原图的的1/2、1/4、1/8、1/16和1/32;另外conv2-conv5中引入了关联性层级残差结构用于相邻不同尺度特征图之间的细粒度特征提取;这样提取过程中生成的不同尺度特征图f1、f2、f3、f4就同时包含了粗粒度与细粒度相结合的多尺度特征信息。conv1采用7×7的卷积核,后面跟一个maxpool层采用3×3的卷积核来进行下采样。conv2-conv5构成为1×1卷积、3×3卷积组和1×1卷积,并附带残差连接以便简化深度神经网络的学习目标和难度。
步骤203,反向逐级特征融合从conv5生成的特征图f1开始,先对f1进行上采样并输出尺寸为原特征图2倍的特征图,这样输出后的特征图尺寸和conv4生成的特征图f2一致,可以直接沿通道维度将两者进行合并;另外在特征图合并之后,还附加了1×1,3×3的两个卷积操作用于降低通道维度和减少参数计算量;这样按此方式依次进行,最终不同尺度的特征图f1、f2、f3和f4逐级融合完成,融合后的特征图尺寸为1/4原始输入图像大小;此外还添加了一个3×3的卷积层来生成最终的多尺度特征融合图。
参见图3,其描绘了本发明特征提取网络conv2-conv5使用的关联性层级残差基本结构图,包括以下部分:
步骤301,特征图1经过1x1卷积来减少参数计算量。
步骤302,经过1x1卷积生成的特征图沿通道维度平均分为4个子特征图,第1个子特征图x1直接被输出作为y1;之后的每个子特征图xi在经过一个3×3卷积操作ki后才得到输出yi;而且从第3个子特征图开始,xi会加上前一个子特征图的输出yi-1,然后再进行3×3卷积操作;最后将4个子特征图的输出沿通道维度合并即得到总输出y。
步骤303,特征图y再经过1x1卷积来还原特征维度,最终生成特征图2。
同时,conv2-conv5使用残差连接以便简化深度神经网络的学习目标和难度。
参见图4,其展示了该方法的部分检测结果,结果表明该方法对于水平方向文本的检测比较精确,对于小文本区域检测比较敏感,对于多实例的实例区分比较准确,而且还能够排除文本类似物体的干扰。
以上结合附图对本发明的具体实施方式进行了描述。本行业的技术人员应该了解,本发明不受上述实施例的限制。在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!